数据采集作业2 102302111 海米沙
第二次作业
作业一
1)题目:要求在中国气象网(http://www.weather.com.cn)给定城市集的7日天气预报,并保存在数据库。
– 输出信息:
Gitee文件夹链接
1.1 代码
`
import requests
import sqlite3
import re
from bs4 import BeautifulSoup
class WeatherCrawler:
def init(self, database_name='weather_data.db'):
self.database_name = database_name
self.base_url = "http://www.weather.com.cn"
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,/;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
}
self.init_database()
def init_database(self):
"""初始化数据库"""
conn = sqlite3.connect(self.database_name)
cursor = conn.cursor()
# 创建天气数据表
cursor.execute('''
CREATE TABLE IF NOT EXISTS weather_forecast (
id INTEGER PRIMARY KEY AUTOINCREMENT,
city_name TEXT NOT NULL,
date_str TEXT NOT NULL,
date_desc TEXT,
weather_info TEXT,
temperature TEXT,
crawl_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP
)
''')
conn.commit()
conn.close()
print("数据库初始化完成")
def get_city_code(self, city_name):
"""获取城市代码"""
city_codes = {
'北京': '101010100',
'上海': '101020100',
'广州': '101280101',
'深圳': '101280601',
'杭州': '101210101',
'南京': '101190101',
'武汉': '101200101',
'成都': '101270101',
'西安': '101110101',
'天津': '101030100'
}
return city_codes.get(city_name, '101010100') # 默认返回北京代码
def crawl_weather_data(self, city_name):
"""爬取指定城市的7日天气预报"""
city_code = self.get_city_code(city_name)
url = f"{self.base_url}/weather/{city_code}.shtml"
try:
response = requests.get(url, headers=self.headers, timeout=10)
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text, 'html.parser')
# 解析7日天气预报数据
weather_data = []
# 方法1: 通过CSS选择器获取天气数据
weather_items = soup.select('.tqtongji1 ul li, .t clearfix li')
if not weather_items:
# 方法2: 尝试其他选择器
weather_items = soup.select('li[class^="sky"]')
if not weather_items:
print("未找到天气数据,尝试解析HTML结构...")
# 打印部分HTML用于调试
print(response.text[:1000])
return []
for i, item in enumerate(weather_items[:7]): # 只取前7天
try:
# 提取日期
date_elem = item.select_one('h1')
date_str = date_elem.get_text().strip() if date_elem else f"第{i+1}天"
# 提取天气信息
weather_elem = item.select_one('.wea')
weather_info = weather_elem.get_text().strip() if weather_elem else "未知"
# 提取温度
temp_elem = item.select_one('.tem')
temperature = temp_elem.get_text().strip() if temp_elem else "未知"
# 清理数据
temperature = re.sub(r'\s+', '', temperature)
weather_data.append({
'city_name': city_name,
'date_str': date_str,
'weather_info': weather_info,
'temperature': temperature
})
except Exception as e:
print(f"解析第{i+1}天数据时出错: {e}")
continue
return weather_data
except Exception as e:
print(f"爬取{city_name}天气数据时出错: {e}")
return []
def save_to_database(self, weather_data):
"""将天气数据保存到数据库"""
if not weather_data:
print("没有数据可保存")
return False
conn = sqlite3.connect(self.database_name)
cursor = conn.cursor()
try:
for data in weather_data:
cursor.execute('''
INSERT INTO weather_forecast (city_name, date_str, weather_info, temperature)
VALUES (?, ?, ?, ?)
''', (data['city_name'], data['date_str'], data['weather_info'], data['temperature']))
conn.commit()
print(f"成功保存 {len(weather_data)} 条天气数据到数据库")
return True
except Exception as e:
print(f"保存到数据库时出错: {e}")
conn.rollback()
return False
finally:
conn.close()
def query_weather_data(self, city_name=None):
"""从数据库查询天气数据"""
conn = sqlite3.connect(self.database_name)
cursor = conn.cursor()
if city_name:
cursor.execute('''
SELECT city_name, date_str, weather_info, temperature, crawl_time
FROM weather_forecast
WHERE city_name = ?
ORDER BY crawl_time DESC, id ASC
''', (city_name,))
else:
cursor.execute('''
SELECT city_name, date_str, weather_info, temperature, crawl_time
FROM weather_forecast
ORDER BY crawl_time DESC, city_name, id ASC
''')
results = cursor.fetchall()
conn.close()
return results
def print_weather_table(self, weather_data):
"""以表格形式打印天气数据"""
if not weather_data:
print("没有天气数据可显示")
return
print("\n" + "="*80)
print(f"{'序号':<4} {'地区':<8} {'日期':<15} {'天气信息':<30} {'温度':<15}")
print("-"*80)
for i, (city, date_str, weather, temp, crawl_time) in enumerate(weather_data, 1):
print(f"{i:<4} {city:<8} {date_str:<15} {weather:<30} {temp:<15}")
print("="*80)
def main():
"""主函数"""
# 城市列表
cities = ['北京', '上海', '广州', '深圳', '杭州']
# 创建爬虫
crawler = WeatherCrawler()
print("开始爬取天气数据...")
print("目标网站: 中国气象网 (weather.com.cn)")
print("目标城市:", ", ".join(cities))
print("-" * 50)
all_weather_data = []
# 爬取每个城市的天气数据
for city in cities:
print(f"正在爬取 {city} 的天气数据...")
weather_data = crawler.crawl_weather_data(city)
if weather_data:
# 添加日期描述
for i, data in enumerate(weather_data):
if i == 0:
data['date_desc'] = '今天'
elif i == 1:
data['date_desc'] = '明天'
elif i == 2:
data['date_desc'] = '后天'
else:
data['date_desc'] = f'第{i+1}天'
# 保存到数据库
crawler.save_to_database(weather_data)
all_weather_data.extend(weather_data)
print(f" {city}: 成功获取 {len(weather_data)} 天天气预报")
else:
print(f" {city}: 爬取失败")
# 从数据库查询并显示结果
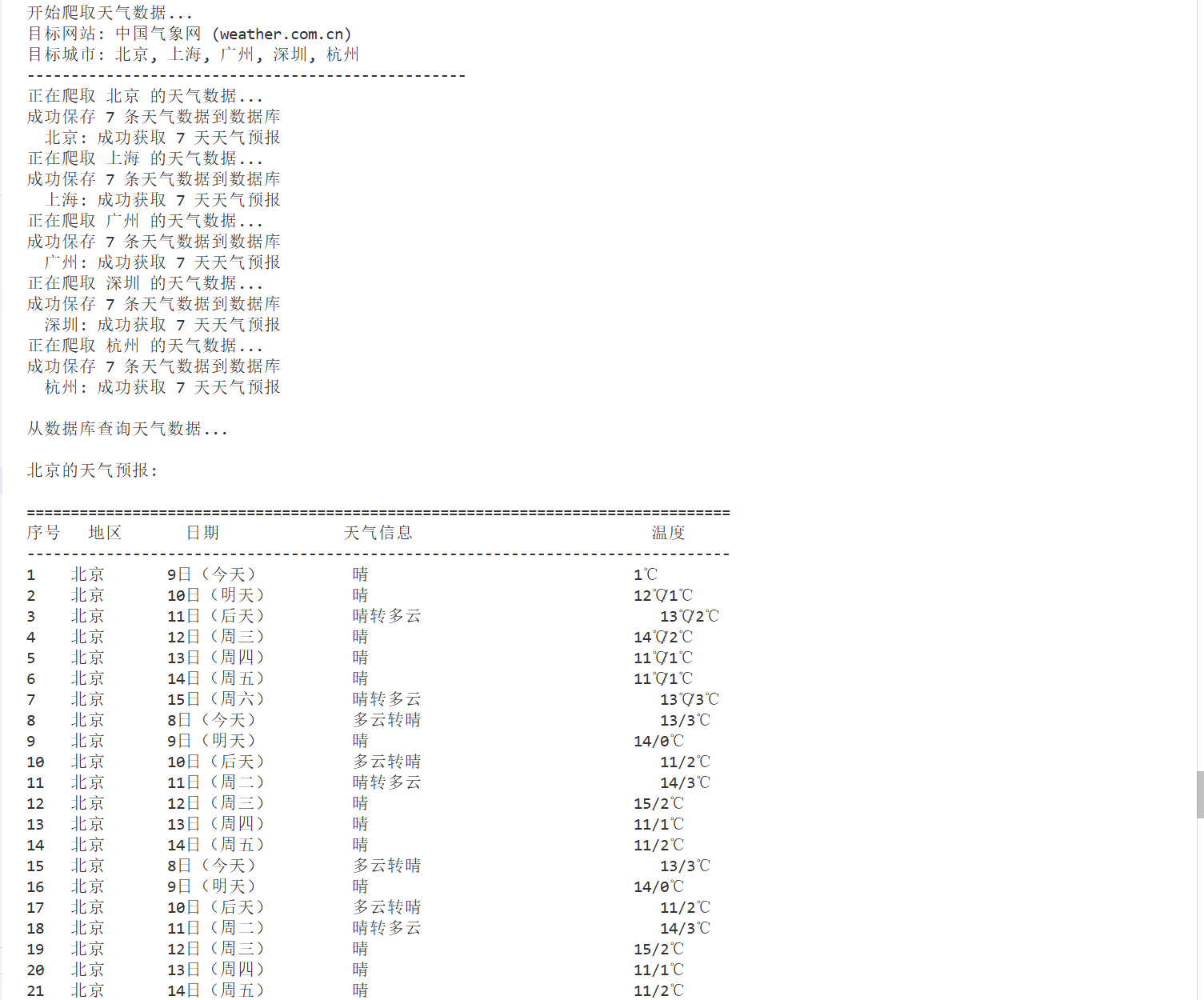
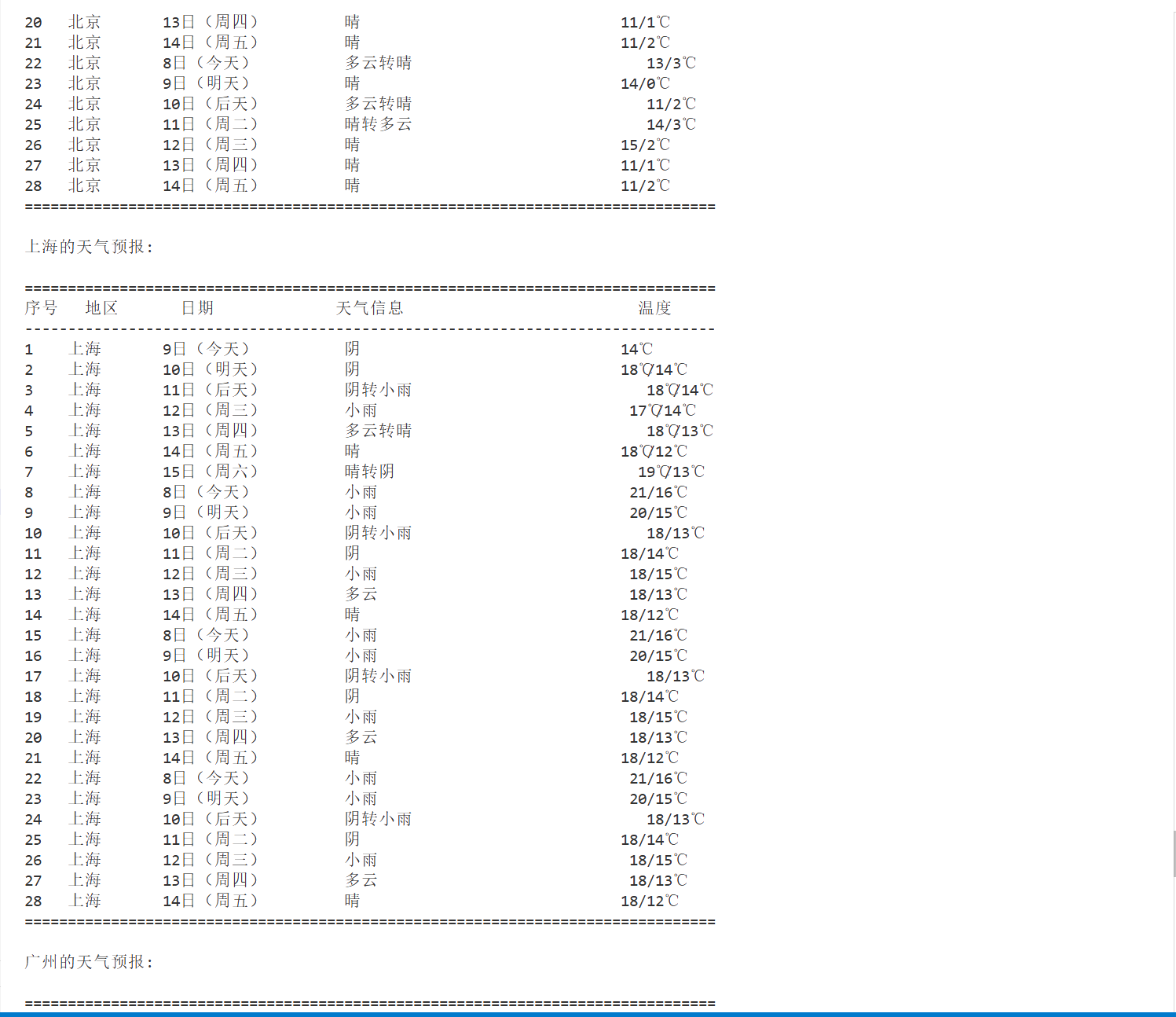
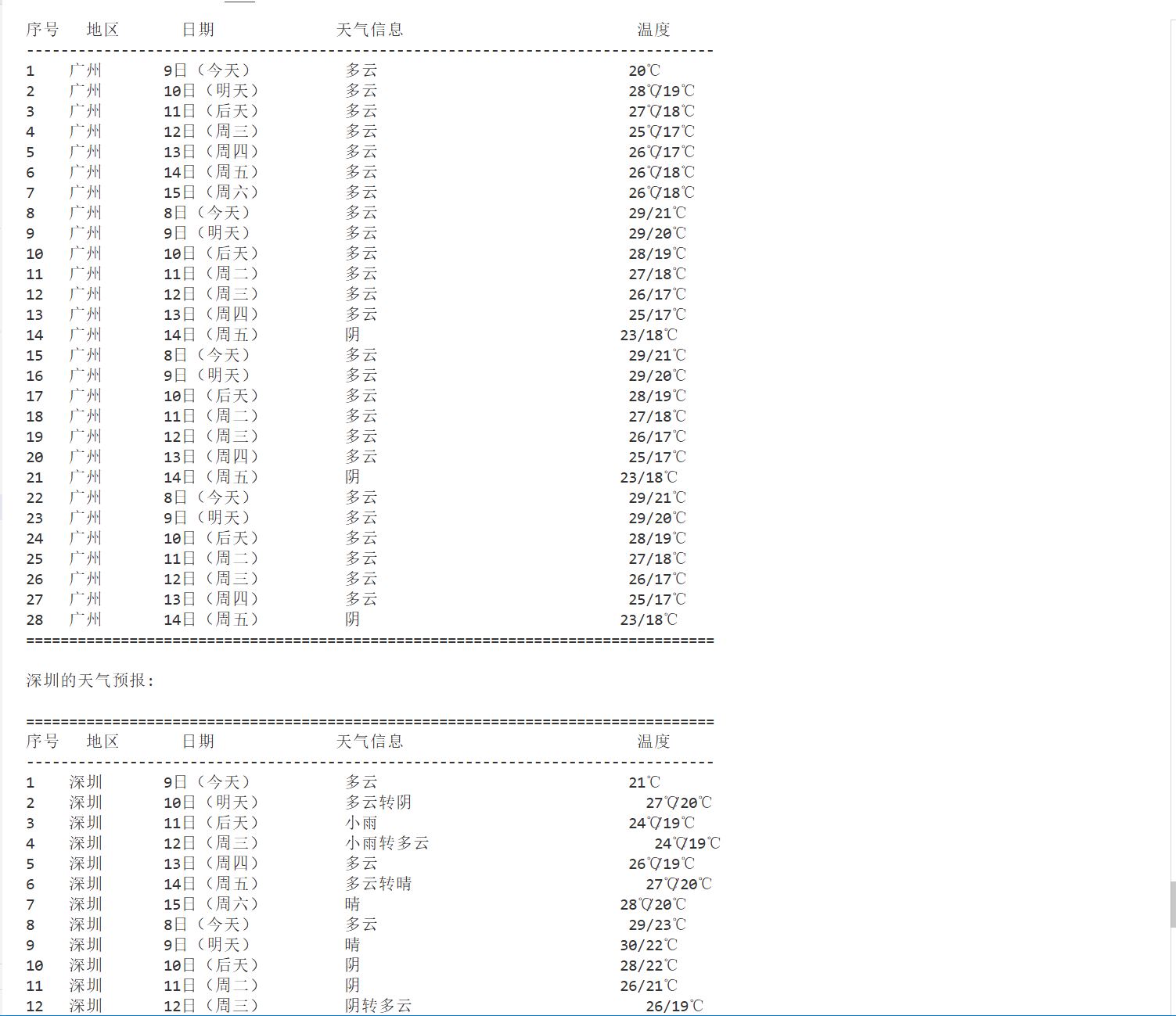
print("\n从数据库查询天气数据...")
for city in cities:
data = crawler.query_weather_data(city)
if data:
print(f"\n{city}的天气预报:")
crawler.print_weather_table(data)
print(f"\n任务完成!数据已保存到数据库: {crawler.database_name}")
print("Gitee文件夹链接:https://gitee.com/haimisha/2025_creat_project/tree/master/%E4%BD%9C%E4%B8%9A%E4%BA%8C/ppt%E5%AE%9E%E9%AA%8C/%E5%AE%9E%E9%AA%8C2.1")
if name == "main":
main()
`
1.2 结果
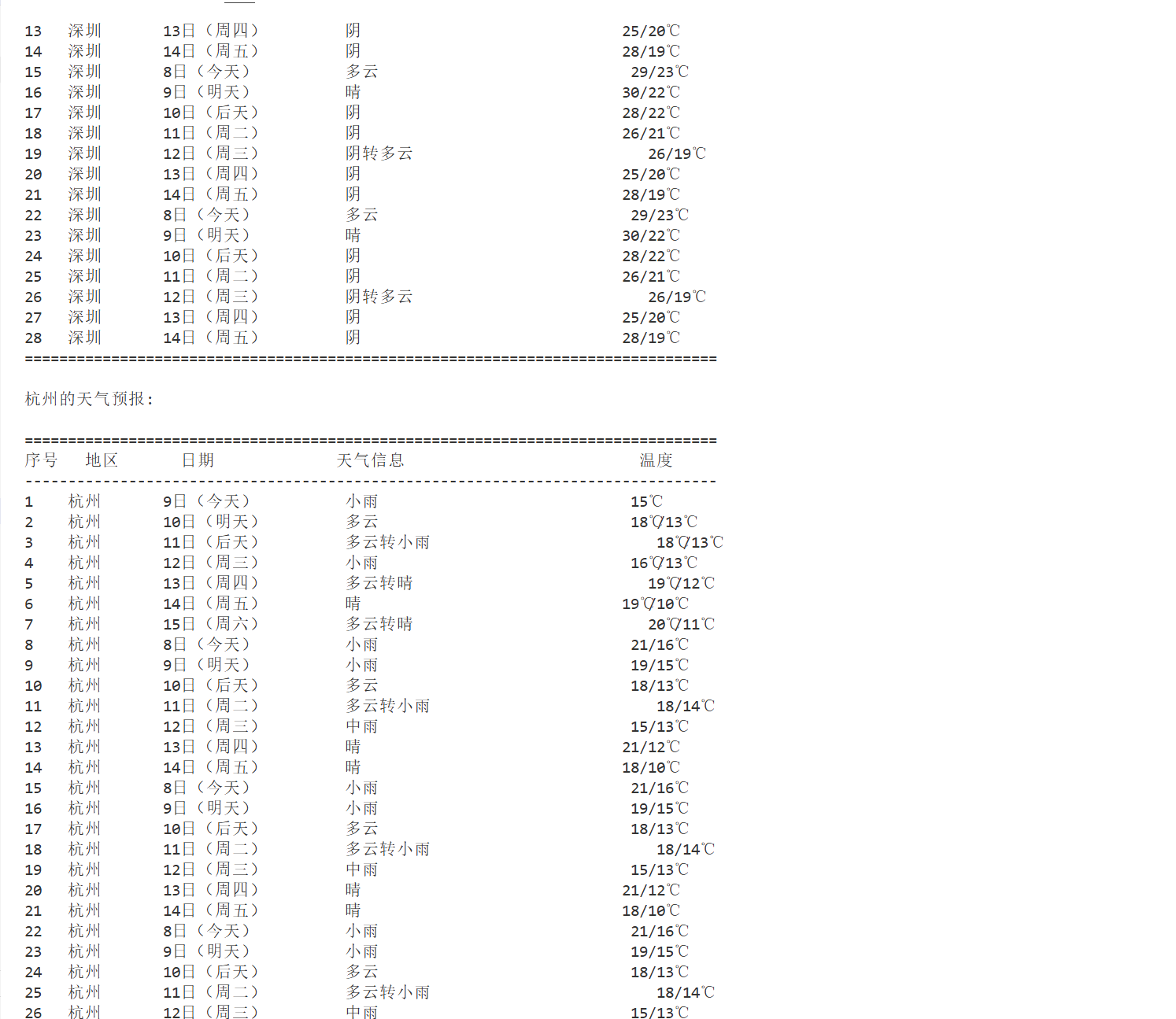

2)心得体会
一开始我总是提取不到正确的天气描述或温度,后来发现是我选错了 HTML 标签或者 class 名称。通过反复查看网页源码,我才慢慢找到了正确的元素路径。我用了 SQLite 数据库,把每一天的天气存为一条记录。刚开始不太熟悉 SQL 语句,比如 INSERT INTO怎么写、字段名是否匹配等,后来通过查资料和模仿示例,慢慢搞定了。我最大的感受是:看似简单的功能,背后也需要耐心和细致的操作,尤其是定位数据和处理异常的时候。另外,我也意识到,数据库虽然看起来“高大上”,但用 Python 操作起来其实也挺简单,是存储数据的好帮手。
作业二
1)题目:要求用requests和BeautifulSoup库方法定向爬取股票相关信息,并存储在数据库中。
候选网站:东方财富网:https://www.eastmoney.com/
新浪股票:http://finance.sina.com.cn/stock/
技巧:在谷歌浏览器中进入F12调试模式进行抓包,查找股票列表加载使用的url,并分析api返回的值,并根据所要求的参数可适当更改api的请求参数。根据URL可观察请求的参数f1、f2可获取不同的数值,根据情况可删减请求的参数。
参考链接:https://zhuanlan.zhihu.com/p/50099084
输出信息:
Gitee文件夹链接
1.1 代码
`
def get_total_stock_count() -> Tuple[int, int]:
"""
获取股票总数量和每页数据量,用于计算总页数
返回: (总数据量, 每页数据量)
"""
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36',
'Referer': 'http://quote.eastmoney.com/center/gridlist.html',
'Accept': 'application/json, text/javascript, /; q=0.01'
}
url = "http://82.push2.eastmoney.com/api/qt/clist/get"
# 先获取第一页数据,从中提取总数据量
params = {
'pn': '1',
'pz': '20', # 先设置一个较小的值,快速获取总数量
'po': '1',
'np': '1',
'fltt': '2',
'invt': '2',
'fid': 'f3',
'fs': 'm:0 t:6,m:0 t:80,m:1 t:2,m:1 t:23',
'fields': 'f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152',
'_': str(int(time.time() * 1000))
}
try:
response = requests.get(url, headers=headers, params=params, timeout=10)
response.raise_for_status()
data = response.json()
if data['data'] is None:
print("无法获取股票数据总数")
return 0, 20
total = data['data']['total'] # 总数据量
# 实际每页数据量可能小于请求的pz,这里我们使用实际返回的数据量
actual_size = len(data['data']['diff']) if data['data']['diff'] else 20
print(f"检测到总共有 {total} 只股票,每页显示 {actual_size} 只")
return total, actual_size
except Exception as e:
print(f"获取总数据量失败: {e}")
return 0, 20 # 默认值
def get_all_pages_stock_data(max_pages=1000, delay=1):
"""
爬取全部页面的股票数据
Args:
max_pages: 最大爬取页数限制,防止意外情况
delay: 请求间隔时间(秒),避免被封IP
"""
# 先获取总数据量和每页数据量
total_count, page_size = get_total_stock_count()
if total_count == 0:
print("无法获取股票数据总数,将使用默认设置爬取前50页")
total_pages = min(50, max_pages)
page_size = 20
else:
# 计算总页数: 总数据量/每页数据量,向上取整
total_pages = (total_count + page_size - 1) // page_size
total_pages = min(total_pages, max_pages) # 不超过最大限制
print(f"开始爬取全部 {total_pages} 页数据,预计耗时约 {total_pages * delay} 秒...")
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36',
'Referer': 'http://quote.eastmoney.com/center/gridlist.html',
'Accept': 'application/json, text/javascript, */*; q=0.01'
}
url = "http://82.push2.eastmoney.com/api/qt/clist/get"
all_stocks = []
current_index = 1
for page in range(1, total_pages + 1):
print(f"正在爬取第 {page}/{total_pages} 页...", end=" ")
params = {
'pn': str(page),
'pz': str(page_size),
'po': '1',
'np': '1',
'fltt': '2',
'invt': '2',
'fid': 'f3',
'fs': 'm:0 t:6,m:0 t:80,m:1 t:2,m:1 t:23',
'fields': 'f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152',
'_': str(int(time.time() * 1000))
}
try:
response = requests.get(url, headers=headers, params=params, timeout=15)
response.raise_for_status()
data = response.json()
if data['data'] is None or not data['data']['diff']:
print(f"第 {page} 页没有数据,可能已到达末尾")
break
stock_data = data['data']['diff']
# 解析当前页数据
page_stocks = []
for stock in stock_data:
stock_info = {
'序号': current_index,
'代码': stock.get('f12', ''),
'名称': stock.get('f14', ''),
'最新价': round(stock.get('f2', 0), 2),
'涨跌幅': f"{stock.get('f3', 0)}%",
'涨跌额': round(stock.get('f4', 0), 2),
'成交量': format_volume(stock.get('f5', 0)),
'成交额': format_amount(stock.get('f6', 0)),
'振幅': f"{stock.get('f7', 0)}%",
'换手率': f"{stock.get('f8', 0)}%" if stock.get('f8') else "0%",
'页码': page
}
page_stocks.append(stock_info)
current_index += 1
all_stocks.extend(page_stocks)
print(f"成功获取 {len(page_stocks)} 条数据")
# 添加延时,避免请求过于频繁
if page < total_pages: # 最后一页不需要延时
time.sleep(delay)
except requests.exceptions.Timeout:
print(f"第 {page} 页请求超时,跳过...")
continue
except requests.exceptions.RequestException as e:
print(f"第 {page} 页网络错误: {e}")
# 遇到网络错误时等待更长时间
time.sleep(delay * 3)
continue
except Exception as e:
print(f"第 {page} 页处理错误: {e}")
continue
return all_stocks
def format_volume(volume: int) -> str:
"""格式化成交量"""
if volume >= 100000000:
return f"{volume/100000000:.2f}亿手"
elif volume >= 10000:
return f"{volume/10000:.2f}万手"
else:
return f"{volume}手"
def format_amount(amount: float) -> str:
"""格式化成交额"""
if amount >= 100000000:
return f"{amount/100000000:.2f}亿元"
elif amount >= 10000:
return f"{amount/10000:.2f}万元"
else:
return f"{amount:.2f}元"
def print_stock_summary(stocks: List[Dict]):
"""打印数据摘要"""
if not stocks:
print("没有获取到股票数据")
return
print(f"\n爬取完成!共获取 {len(stocks)} 只股票的数据")
# 按页码统计
pages = set(stock['页码'] for stock in stocks)
print(f"成功爬取 {len(pages)} 页数据")
# 显示前5只股票作为示例
print("\n前5只股票数据示例:")
headers = ['序号', '代码', '名称', '最新价', '涨跌幅', '涨跌额', '成交量', '成交额']
header_format = "{:<4} {:<8} {:<10} {:<8} {:<8} {:<8} {:<12} {:<12}"
print(header_format.format(*headers))
print("-" * 80)
for i, stock in enumerate(stocks[:5]):
row_format = "{:<4} {:<8} {:<10} {:<8} {:<8} {:<8} {:<12} {:<12}"
print(row_format.format(
stock['序号'],
stock['代码'],
stock['名称'][:8],
stock['最新价'],
stock['涨跌幅'],
stock['涨跌额'],
stock['成交量'],
stock['成交额']
))
def save_to_csv(stocks: List[Dict], filename: str = "all_stocks_data.csv"):
"""保存数据到CSV文件"""
if not stocks:
print("没有数据可保存")
return
df = pd.DataFrame(stocks)
df.to_csv(filename, index=False, encoding='utf-8-sig')
print(f"\n全部数据已保存到 {filename}")
def main():
"""主函数"""
print("开始爬取全部页面的股票数据...")
print("=" * 60)
start_time = time.time()
# 爬取全部页面数据
# 设置最大页数限制为200页,延时2秒
stocks = get_all_pages_stock_data(max_pages=200, delay=2)
end_time = time.time()
# 打印摘要信息
print_stock_summary(stocks)
# 保存到CSV
save_to_csv(stocks)
# 显示耗时
elapsed = end_time - start_time
print(f"\n总耗时: {elapsed:.2f} 秒")
print(f"平均每页耗时: {elapsed/len(stocks)*20 if stocks else 0:.2f} 秒")
print("Gitee文件夹链接:https://gitee.com/haimisha/2025_creat_project/tree/master/%E4%BD%9C%E4%B8%9A%E4%BA%8C/ppt%E5%AE%9E%E9%AA%8C/%E5%AE%9E%E9%AA%8C2.2")
if name == "main":
main()`
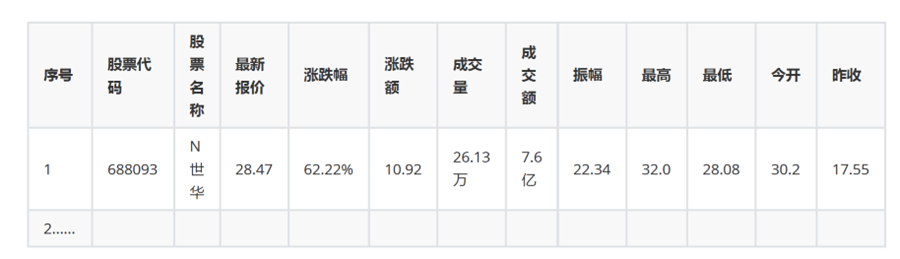
1.2 结果
2)心得体会
这个作业相比第一个难度有所提升,因为爬取的是股票信息,这网站通常数据量大、更新快,而且很多数据是通过 JavaScript 动态加载的,并不会直接出现在 HTML 源码里。一开始我一直在分析网页的 HTML,想直接从页面上提取数据,但怎么都找不到关键信息。后来经同学提醒,才想到去“Network”里找接口,才发现数据是通过 API 返回的 JSON。API 请求中有很多参数,比如 f1、f2、ut、page 等,有些是控制返回哪些字段的。我一开始不太懂这些参数含义,只能照着参考文章里的示例去设置,后来慢慢理解了一些。JSON 返回的数据结构有点复杂,比如最新价、涨跌幅等可能嵌套在某个对象里,我得仔细阅读返回结果,才能正确提取字段。通过这次实践,我不仅学会了如何找到并调用数据接口,还提升了使用 Python 处理 JSON 数据的能力,同时也加深了对数据库字段设计和数据存储流程的理解。
作业三
1)题目:要求爬取中国大学2021主榜(https://www.shanghairanking.cn/rankings/bcur/2021)所有院校信息,并存储在数据库中,同时将浏览器F12调试分析的过程录制Gif加入至博客中。
技巧:分析该网站的发包情况,分析获取数据的api
输出信息:
Gitee文件夹链接
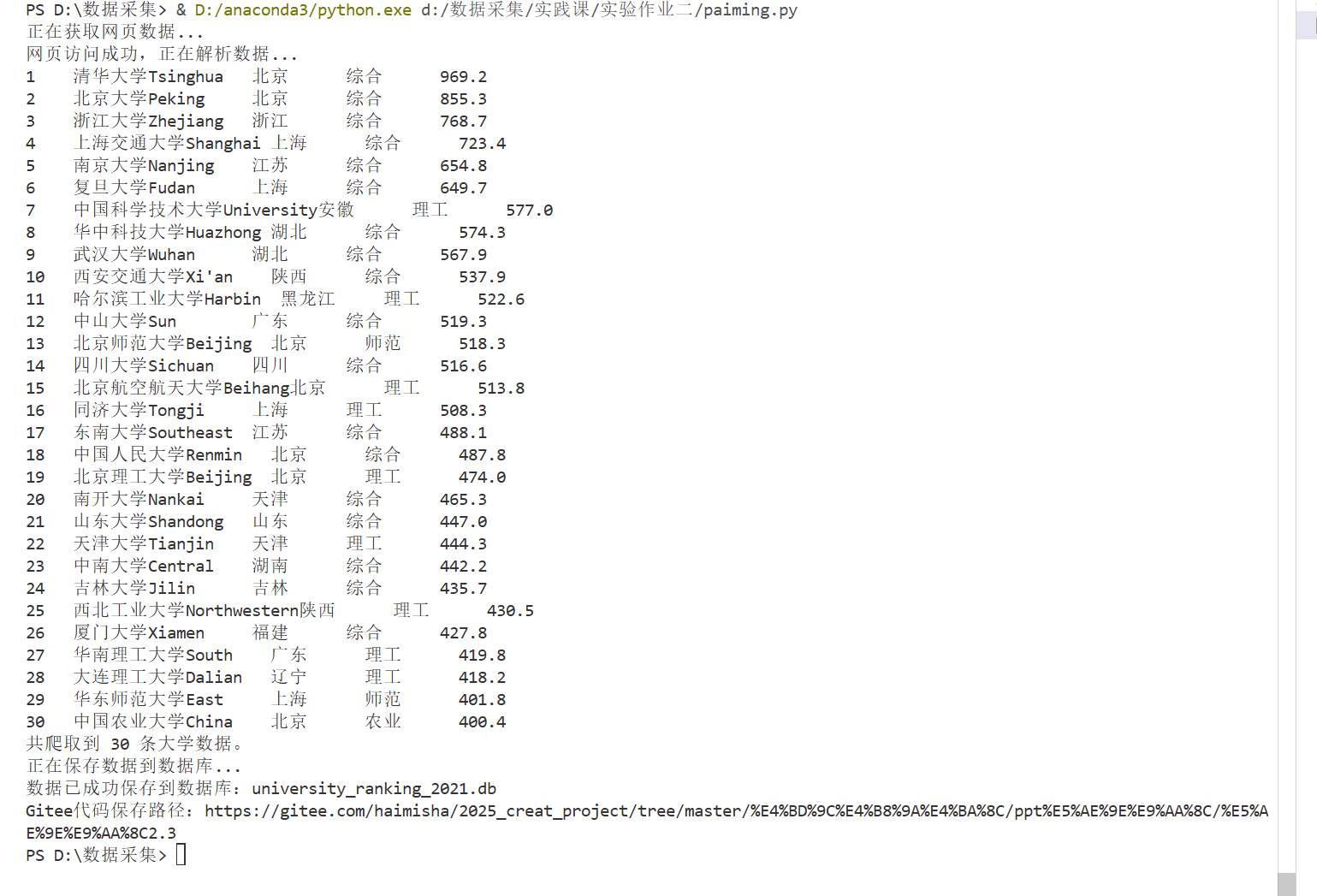
排名 学校 省市 类型 总分
1 清华大学 北京 综合 969.2
1.1 代码
`import requests
from bs4 import BeautifulSoup
import sqlite3
import re
目标网页 URL
url = "https://www.shanghairanking.cn/rankings/bcur/2021"
请求头,模拟浏览器
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0 Safari/537.36"
}
发送 GET 请求
print("正在获取网页数据...")
response = requests.get(url, headers=headers)
response.encoding ='utf-8'
if response.status_code != 200:
print(f"网页访问失败,状态码:{response.status_code}")
else:
print("网页访问成功,正在解析数据...")
# 使用 BeautifulSoup 解析 HTML
soup = BeautifulSoup(response.text, 'html.parser')
# 找到排名表格 —— 根据实际网页结构来定位,可能需要调整
table = soup.find('table', {'class': 'rk-table'})
if not table:
table = soup.find('table') #找第一个表格
universities = []
if table:
# 遍历表格行,跳过表头
rows = table.find_all('tr')[1:] # 从第二行开始,第一行是标题
for idx, row in enumerate(rows, start=1): # 从1开始计数,对应排名
cols = row.find_all('td')
if len(cols) >= 6: # 确保至少有6列数据
rank = cols[0].get_text(strip=True)
# 优先尝试获取带中文的名称(通常在第一个 <div> 或直接 td 文本)
name_elem = cols[1].find('div', recursive=False) or cols[1]
name_full = name_elem.get_text(strip=True).split('\n')[0].strip()
# 尝试提取中文名(假设中文名在前、英文在后,用空格分隔)
name_parts = re.split(r'\s+', name_full, maxsplit=1)
name = name_parts[0] if name_parts else name_full
label = cols[1].get_text(strip=True) # 双一流/985/211
location = cols[2].get_text(strip=True) # 所在地
category = cols[3].get_text(strip=True) # 学校类型(综合/理工等)
score = cols[4].get_text(strip=True) # 总分
# 洗数据,确保排名是数字
rank = int(rank) if rank.isdigit() else None
universities.append({
'排名': rank,
'学校名称': name,
'标签': label,
'所在地': location,
'学校类型': category,
'总分': score
})
# 打印当前行的关键信息,模拟示例图输出
print(f"{rank:<5}{name:<15}{location:<8}{category:<8}{score:<10}")
print(f"共爬取到 {len(universities)} 条大学数据。")
# 3. 存储到 SQLite 数据库
if universities:
print("正在保存数据到数据库...")
conn = sqlite3.connect('university_ranking_2021.db') # 创建或打开数据库
cursor = conn.cursor()
# 创建表(如果不存在)
cursor.execute('''
CREATE TABLE IF NOT EXISTS universities (
id INTEGER PRIMARY KEY AUTOINCREMENT,
排名 INTEGER,
学校名称 TEXT,
标签 TEXT,
所在地 TEXT,
学校类型 TEXT,
总分 TEXT
)
''')
# 插入数据
for uni in universities:
cursor.execute('''
INSERT INTO universities (排名, 学校名称, 标签, 所在地, 学校类型, 总分)
VALUES (?, ?, ?, ?, ?, ?)
''', (uni['排名'], uni['学校名称'], uni['标签'], uni['所在地'], uni['学校类型'], uni['总分']))
conn.commit()
conn.close()
print("数据已成功保存到数据库:university_ranking_2021.db")
else:
print("未能提取到大学数据,请检查网页结构是否发生变化。")
print("Gitee代码保存路径:https://gitee.com/haimisha/2025_creat_project/tree/master/%E4%BD%9C%E4%B8%9A%E4%BA%8C/ppt%E5%AE%9E%E9%AA%8C/%E5%AE%9E%E9%AA%8C2.3")
`
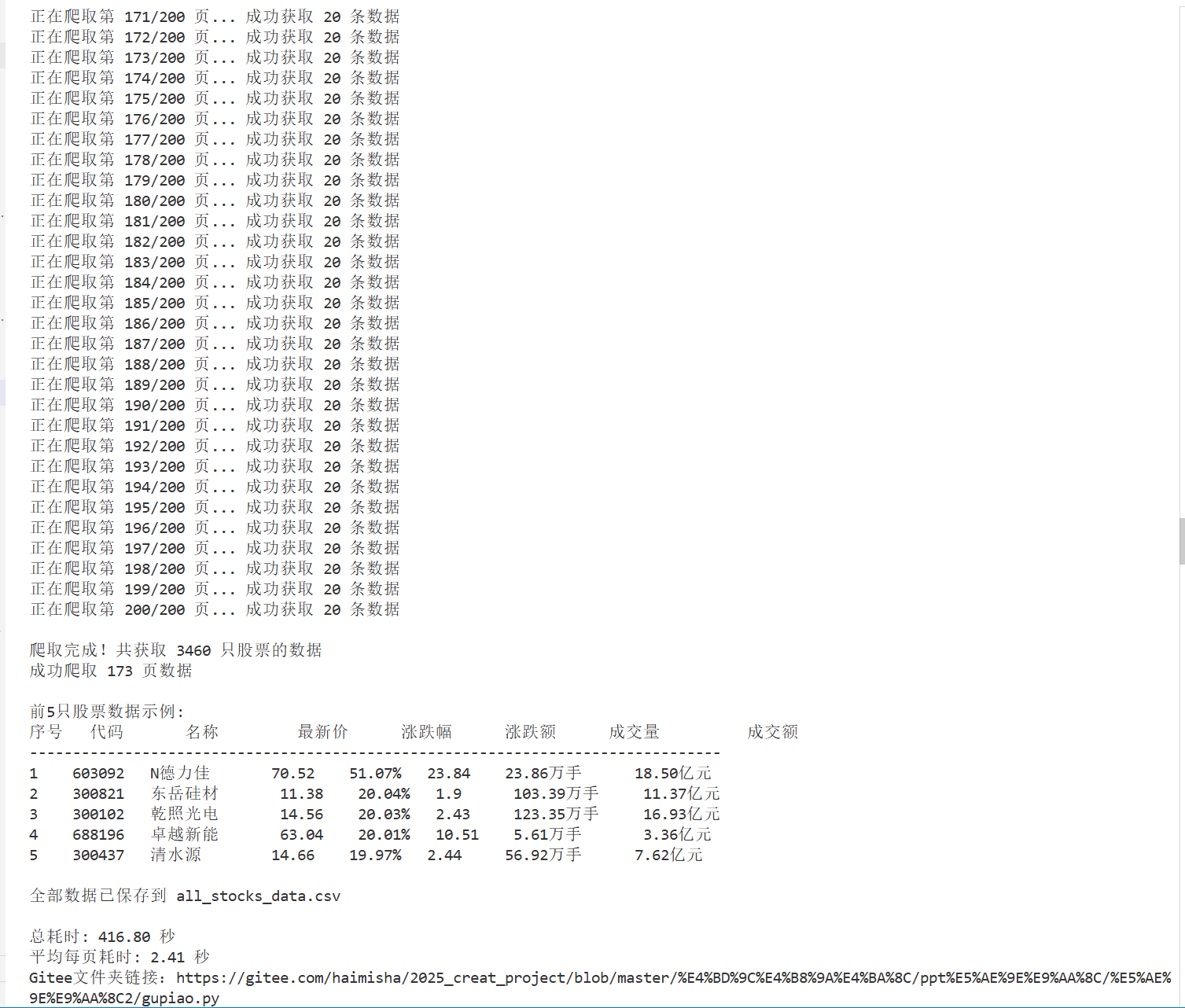
1.2 结果
1.2.1 代码运行结果
1.2.2 f12调试
屏幕录制 2025-11-09 200208.gif
2)心得体会:
这个作业是三个任务里综合难度最高的一个,因为它不仅要求我们爬取“中国大学2021主榜”的排名信息,还要求我们把 F12 分析过程录制成 GIF,并撰写一篇结构清晰、带代码和图表的博客。我打开了 F12 开发者工具,在 Network 面板中找到了返回大学排名数据的那个 JSON 格式的 API 接口。通过分析这个 API,我直接请求 JSON 数据,获取了排名、学校、省市、类型、总分等字段,然后存入数据库。:一开始我试图直接从网页 HTML 中找排名表格,但发现数据是动态加载的,HTML 里根本找不到具体排名。后来通过抓包才发现了真正的 API。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号