链路追踪(一)-分布式链路追踪系统的介绍
一、分布式链路追踪可以做什么?
1.1:简单集群架构&微服务架构
先来看下最简单的网站集群架构图:
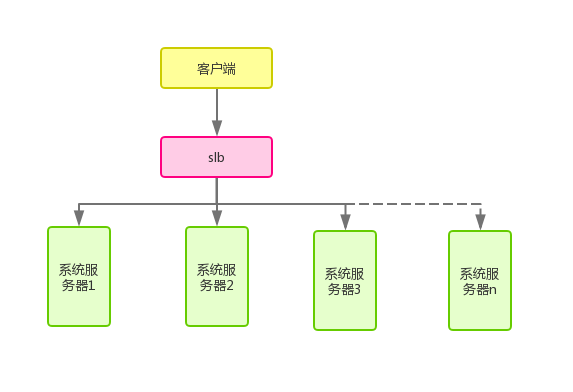
图1
在这个图里,存在从1~n个服务器,通过负载均衡器SLB进行请求分发,在每个服务器里,都做同一件事情。
现在来看下这个系统的具体业务逻辑(就是图1中每台服务器执行的逻辑,这里是假设其中一个业务接口的处理,真实系统中可能存在n多业务接口):
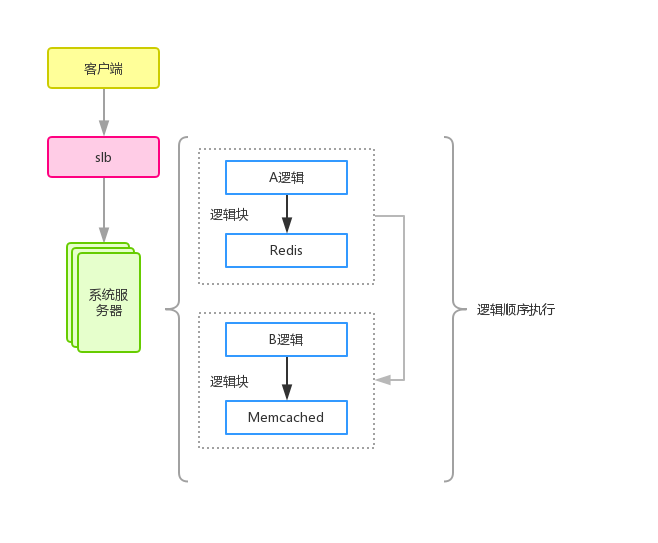
图2
图2是对系统中某一个接口(API)的逻辑做了描述,假设处理流程就是请求一次Redis服务,然后做下处理,然后再请求下Memecached服务,在做下业务处理,后续可能还有其他各种业务逻辑,我们统称为逻辑块。
现在假设这个接口存在性能问题,那么找对应开发负责人排查是比较容易的,因为服务器只执行一套逻辑,瓶颈点一定发生在当前接口对应代码里的某个点,那么就找接口对应的负责人去排查优化即可。
但是当业务发展到一定的程度,比如上述单系统逻辑越来越复杂(业务接口越来越多,逻辑越来越复杂),就会造成很多我们不愿意看到的问题发生:
①每一次微小的改动都需要整体走一次打包、发版的流程,对测试也是种负担,因为n多个人如果同时开发不同的功能,这时候就会对测试和发布流程造成很大的困扰。
②如果因为做某次活动,某一个接口可能引入大量请求,需要紧急扩容,那么只能对整体扩容(因为该接口与其他接口都处于同一个系统中)。
③系统各模块高度耦合,不适合多人开发和维护。
简单集群带来的问题会随着系统复杂度的提升,维护成本变得越来越大,基于此,便有了微服务架构(微服务是一种架构思想,简单来说就是将复杂庞大耦合度高的系统按照功能特性拆分成一个个独立的系统,通过网络互相通信,这种架构可以借助RPC框架(比如grpc、dubbo)实现拆分。当然,熟悉的HTTP框架也可以做到(比如okhttp),但是受限于HTTP协议,性能可能并没有普通RPC框架高,比如grpc采用HTTP2应用层协议进行编解码,这个协议相比HTTP1来说,支持数据流的标记,可以在一个长连接上做N多请求和接收的并发处理,属于全双工网络通信,这点放到HTTP1就很难做到)。
结合图2,我们来简单按照业务划分一下服务,可以将A代码块里的逻辑抽象成A服务,将B代码块里的逻辑抽象成B服务,当然还有可能有其他n多细化的服务,网关层API(负责聚合信息以及业务处理的模块,对应上面简单集群里的具体接口),服务注册与发现、SLB等。
下面再来看一下被拆分后的架构图:
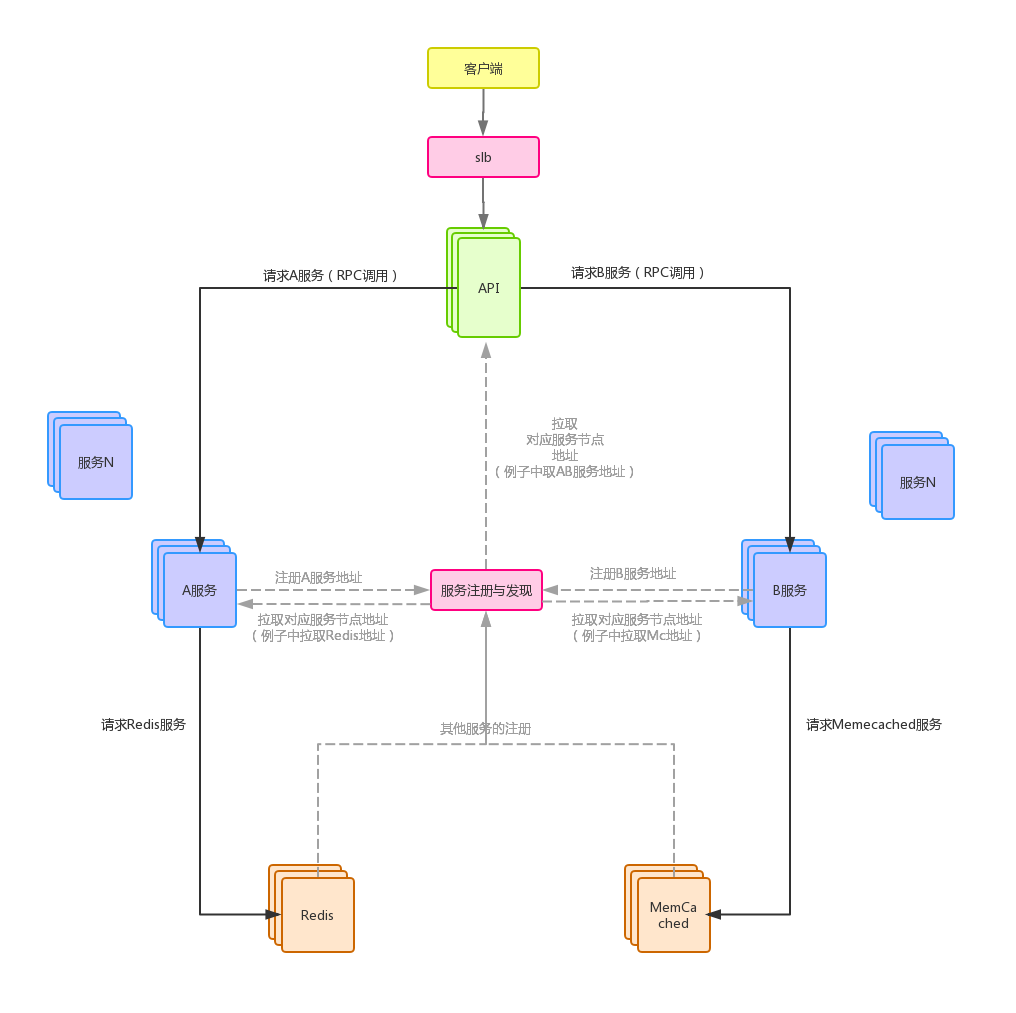
图3
这张图是一个很简单的微服务化的架构图,图中虚线部分都是在各服务启动时或者运行期发生的调用,负责注册与发现(如zookeeper、Eurake等都可以作服务注册与发现,这里不再细说,只关注实线部分即可)。
这种架构很好的解决了普通集群架构带来的问题(参考上述①、②、③),微服务架构的好处:
①降低了系统(逻辑块)间的耦合度,可以独立开发、独立部署和测试,系统间的边界明确,可以细分相关负责人,开发效率大大提升。
②如果因为做某次活动,某一个接口可能引入大量请求,需要紧急扩容,那么只需要将该接口涉及到的服务进行扩容即可,而不是像之前那样整体扩容,降低了维护成本(某种意义上的降低,维护人员要足够多,每个人去负责自己的小模块,如果一个公司只有一个维护人员,微服务反而是在加重维护人员的工作:)。
③提高了系统(逻辑块)的复用性,比如上面的服务A做自己的事情,万一以后有个API仍然需要A逻辑块,那么该API只需要再次调用A服务即可(实际应用当中的例子:用户服务)。
④服务化以后,每个服务甚至可以用不同的语言来实现(存在支持跨语言的RPC框架,比如grpc),一个公司大了以后,可能存在语言差异,有的组使用JAVA,有的组用Go,通过服务化的方式,来将两个不同语言的系统互联。
上面简单介绍了普通集群架构和微服务架构,同样的,微服务化也意味着系统调用的复杂化,有可能一次API的调用对应大批量的服务调用,服务方自己又有一堆服务调用,那么针对这种问题,我们来模拟一次复杂的API调用(注册与发现服务已隐藏),如图4所示:
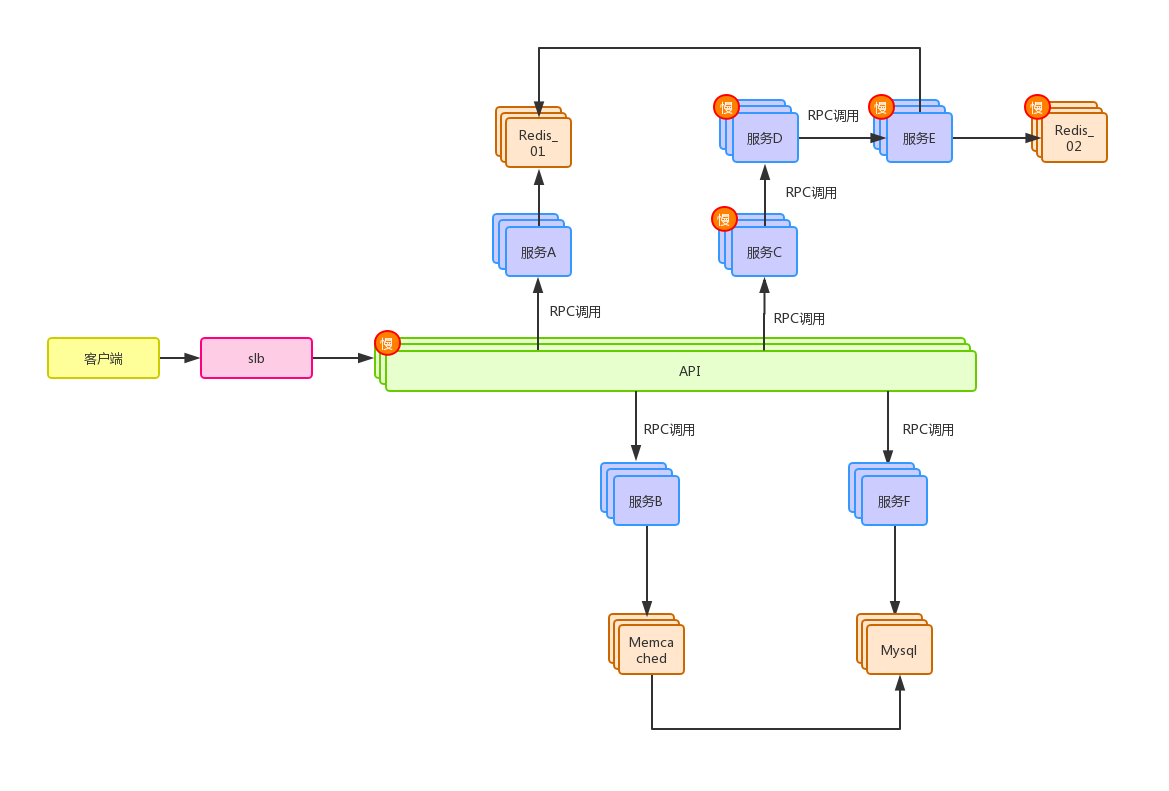
图4
这是模拟了一次微服务架构中比较复杂的系统调用。⚠️注意:图画的有点歪,微服务架构的设计目标是要高度解耦,每个独立的服务最好都有一份自己独立的资源访问,比如服务A只访问A业务相关的数据库和缓存等资源,图中针对这些资源划分做的很糙
那么现在如果这个较复杂的链路调用上的其中一环发生了性能瓶颈,拖慢了整个API的调用,比如图中的“慢”标识,现在我们再来模拟一下这个性能问题的排查过程(过程相当鬼畜):
负责API编写的同学发现API的响应时间总是达不到预期,自己debug发现导致性能问题的原因是服务C,于是找到了服务C的负责人C同学,C同学紧接着排查,发现原来是服务D的调用过慢,于是又跑去找D同学,D同学收到C同学的反馈,然后去查自己的服务,发现自己调用的服务E响应缓慢,于是D同学又跑去找E同学,E同学紧接着排查,发现原来是自己这里调用的Redis_02服务有问题,然后自己排查,如果不是自己调用方式有问题,接下来还可能去联系对应的Redis_02相关维护人员帮助检查瓶颈点。
对比简单集群方式中的单系统性能问题排查,微服务针对此类问题的排查简直是一场噩梦,这其中涉及到的人跟瓶颈节点的深度成正比,因为任何一个环节都有可能存在性能问题,而拖慢整个进度的根源未知,那么有没有一种工具可以完成跨服务跨系统的去跟踪这次的调用链路呢?
1.2:分布式链路追踪
结合上面的问题,分布式链路追踪系统就诞生了,来看下Google的这篇文章:Dapper,大规模分布式系统的跟踪系统,可以对分布式链路追踪系统有个系统的认识。
单纯的理解链路追踪,就是指一次任务的开始到结束,期间调用的所有系统及耗时(时间跨度)都可以完整记录下来,比如上面图4的例子,假设总耗时100ms,存在瓶颈链路C-->D-->E-->Redis02,如果链路追踪系统做好了,链路数据有了,借助前端解析和渲染工具,可以达到下图中的效果:

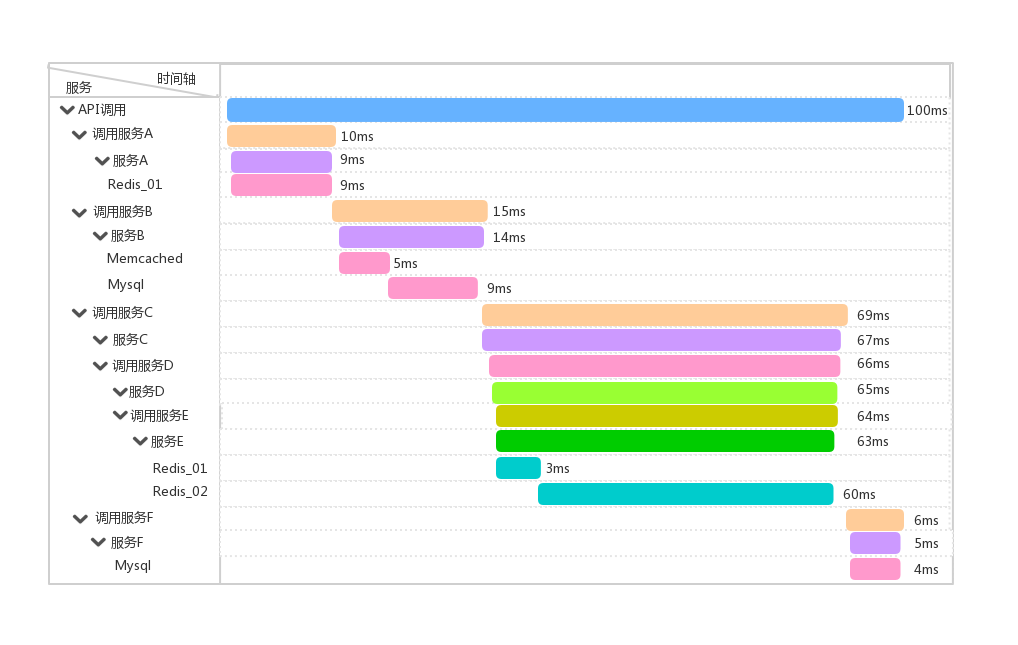
图5
可以看到从API的调用开始到每个涉及到的系统调用以及系统内部的调用链路和时间跨度被直观的展示出来了,通过上图,可以看到时间跨度最长的就是Redis_02,该服务的调用间接拖慢了E服务、D服务、C服务的响应,最后由C服务直接导致API整体响应缓慢,通过这个图,就可以直接找到对应的责任人去排查对应的问题,而不是像之前那样找一群人。
二、分布式链路追踪系统的组成
类似很多监控系统,该系统也分为基础数据采集+数据存储+前端展示几个部分,来看下一个分布式链路系统的基本结构:
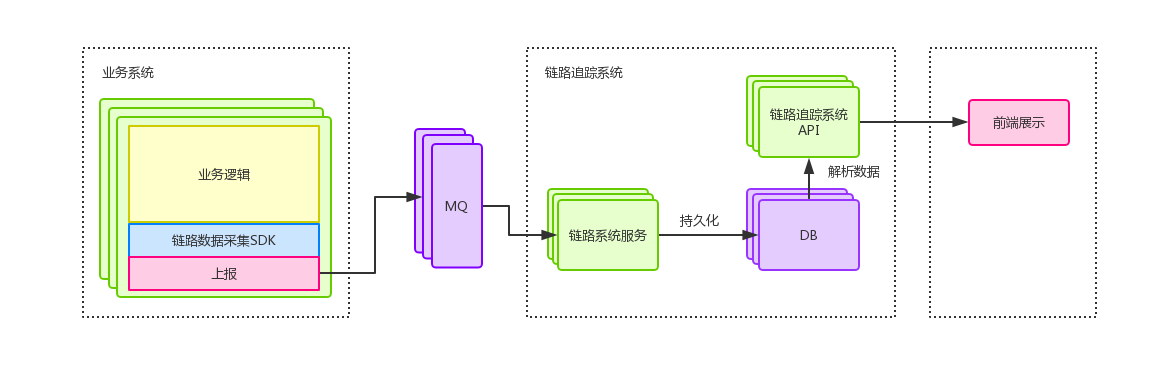
图6
上图比较粗略的展示了一个完整的链路追踪系统的结构,本篇文章不会介绍具体的链路追踪系统的实现,可以先简单将该系统理解为接收+存储链路数据的作用,前端也一样,可以先简单理解为请求链路系统API,API内部负责读取db,并将数据封装成前端需要的格式,前端负责绘制图5中的页面即可(只要数据结构约定好,对于专业的前端工程师做出图5的效果是很容易的,当然网上也有现成的前端工具)。
本篇文章主要介绍链路追踪究竟是什么,可以解决什么问题,下一篇将会详细介绍“链路数据采集SDK”,因为这一部分是跟业务组件开发人员直接挂钩的,下一篇会说明链路追踪的数据结构、如何做到链路数据的采集和上报、如何做到跨服务的链路追踪。
开始前可以先了解一个标准:OpenTracing语义标准
这里面讲了两个很重要的概念:Tracer和Span,一个Tracer认为是一次完整的链路,内部包含n多个Span,Span表示具体的一次调用,图5中就是一次完整的调用链路,里面每个耗时条都是一个Span,Tracer和Span存在一对多的关系(看到这里,图6中的链路追踪API的实现可以认为是根据Tracer的id聚合一批存在父子关系的Span封装成定义好的数据结构传给前端进行渲染的),根据图5,可以知道Span与Span之间又存在父子关系。
具体的实现方案和实现方法,下一篇会详细介绍~下一篇会围绕着图5进行展开。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号