
深入理解python(二)python基础知识之数据结构
数据结构
Python中的内置数据结构(Built-in Data Structure):列表list、元组tuple、字典dict、集合set,这里只着重说前三个
>>> d=dict(zip(('e','r'),(1,2)))
>>> d.keys()
dict_keys(['e', 'r'])
>>> d.values()
dict_values([1, 2])
>>> d.items()
dict_items([('e', 1), ('r', 2)])
列表
列表是Python中内置可变序列,是若干元素的有序集合。列表中的每一个数据称为元素,列表的所有元素放在一对中括号 [ 和 ] 中,并使用逗号分隔开
关于列表的一些重要操作函数汇总
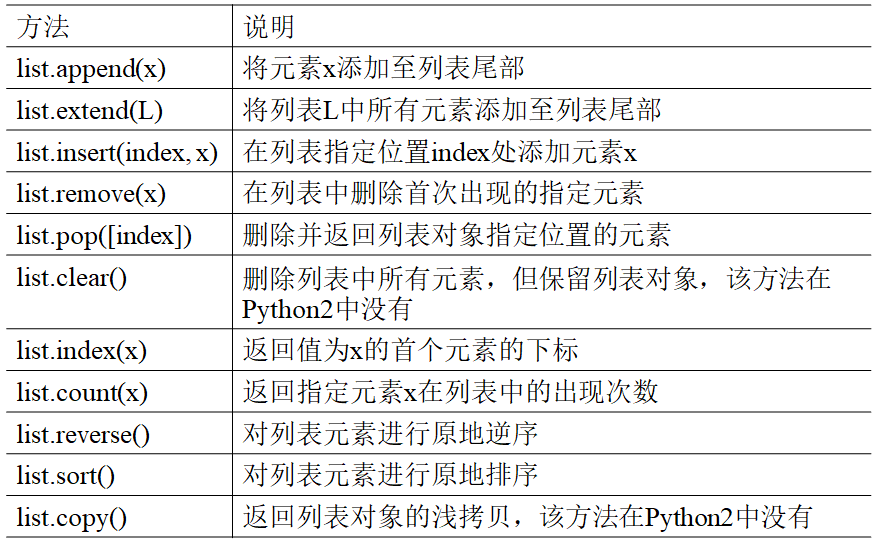
接下来是几个列表涉及的重要知识点
1.extend()和append()
extend()是将加入对象中的元素拼接到列表对象的后面,而append()则是将加入对象直接加入列表末尾。
例:
>>> a=[1,2,3] >>> a.append([2,3]) #使用append >>> a [1, 2, 3, [2, 3]] >>> a=[1,2,3] >>> a.extend([2,3]) #使用extend >>> a [1, 2, 3, 2, 3]
2.列表的删除
一般想到列表的删除会想到循环+remove()的方法,但是在python中这种方法可能会产生想不到的错误。
例:
>>> a=[1,2,1,1,2,3,1] >>> for x in a: ... if x==1: #寻找出等于1的元素并删除 ... a.remove(x) ... >>> a [2, 2, 3, 1]
可以看到并没有完全删除等于1的元素,原因在于python删除列表中的元素后,元素后面的索引会跟着每个加一,而遍历到的索引值不变,这就会造成一些元素被跳过的情况。
解决这个问题我们可以使用列表的浅拷贝或者使用while循环进行删除,但这两种办法并不是高效的,这里给出两种较为高效率的办法。
a.将列表倒序
>>> a=[1,2,1,1,2,3,1] >>> for x in a[::-1]: ... if x==1: ... a.remove(x) ... >>> a [2, 2, 3]
b.使用列表生成式将不删除的元素筛选出来
[val for val in my_list if val != 1]
3.切片操作和range()函数
切片返回的是对象的浅拷贝,切片使用2个冒号分隔的3个数字来完成,第一个数字表示切片开始位置(默认为0),第二个数字表示切片截止(但不包含)位置(默认为列表长度),第三个数字表示切片的步长(默认为1),当步长省略时可以顺便省略最后一个冒号。
给出几个例子:
>>> a=[2,4,6,2,1,4,7,3] >>> a[1:3] #注意结尾是不算在给出的列表之中 [4, 6] >>> a[:7:2] #将步长设置为2 [2, 6, 1, 7] >>> a[::-1] #步长为-1则为逆序 [3, 7, 4, 1, 2, 6, 4, 2] >>> a[:-2] #尾项为负数代表从最后一项相减开始 [2, 4, 6, 2, 1, 4] >>> a[3:0:-1] #逆序切片时需注意首尾的颠倒 [2, 6, 4]
关于range()函数,这里借我们老师的一个说法来说明
内置函数range()的语法为:
range([start,] stop[, step])
其接收3个参数,第一个参数表示起始值(默认为0),第二个参数表示终止值(结果中不包括这个值),第三个参数表示步长(默认为1)
该函数在Python 3中返回一个range可迭代对象,在Python 2中返回一个包含若干整数的列表。另外,Python 2还提供了一个内置函数xrange()(Python 3中不提供该函数),语法与range()函数一样,但是返回xrange可迭代对象,类似于Python 3的range()函数,其特点为惰性求值,而不是像range()函数一样返回列表。例如下面的Python 2.7代码:
>>> range(10) [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] >>> xrange(10) xrange(10) >>> list(xrange(10)) [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
关于惰性求值:
大意延迟求值,即返回时不给定数据结构,根据需要来进行转化,以便于节省计算机资源,这个思路在python3中很常见。
5.zip()函数和enumerate()函数
zip(列表1,列表2,…) 将多个列表对应位置元素组合为元组,并返回包含这些元组的列表
>>> a = [1,2,3] >>> b = [4,5,6] >>> c = [7,8,9] >>> d = zip(a, b, c) >>> d [(1, 4, 7), (2, 5, 8), (3, 6, 9)] #而在Python 3中则需要这样使用: >>> a = [1, 2, 3] >>> b = [4, 5, 6] >>> c = zip(a, b) >>> c <zip object at 0x0000000003728908> >>> list(c) [(1, 4), (2, 5), (3, 6)]
同样,python3采用了惰性求值的思路
enumerate()函数:
enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
例:
>>>i = 0 >>> seq = ['one', 'two', 'three'] >>> for element in seq: ... print i, seq[i] ... i +=1 ... 0 one 1 two 2 thre
6.列表推导式
例:
>>> a = [x*x for x in range(10)] >>> a [0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
前面的x*x可以换成任何函数
当然也可以加入嵌套循环和条件判定
例:
>>> [(x, y) for x in range(3) for y in range(3)] [(0, 0), (0, 1), (0, 2), (1, 0), (1, 1), (1, 2), (2, 0), (2, 1), (2, 2)] >>> [(x, y) for x in [1, 2, 3] for y in [3, 1, 4] if x != y] [(1, 3), (1, 4), (2, 3), (2, 1), (2, 4), (3, 1), (3, 4)]
元组
这里大概注意两点
一个是关于解包问题
首先是字典和元组的解包:
>>> a=(1,2,3) >>> b,c,d=a >>> b 1 >>> c 2 >>> d 3 >>> a={'a':1,'b':2,'c':3} >>> x,y,z=a >>> a {'a': 1, 'b': 2, 'c': 3} >>> x 'a' >>> y 'b' >>> z 'c'
作为参数传参时会使用到*,这里给出例子:
列表解包时,保持列表项数与参数数一致
#解包--list,元组,集合 def connect(ip,port,username,password): print(ip) print(port) print(username) print(password) info_list=['192.168.1.1',3309,'zhaozhao','123456'] info_tuple=('192.168.1.1',3309,'zhaozhao','123456') info_set={'192.168.1.1',3309,'zhaozhao','123456'} connect(*info_list) connect(*info_tuple) connect(*info_set)
字典解包时,使用两个**代表对值的解包,但需要参数名称和key的值一样:
dic={"name":"zhaozhao","password":"123456"}
def dic_fun(name,password):
print(name)
print(password)
dic_fun(**dic)
zhaozhao 123456
第二个是关于生成器推导式
生成器推导式和列表推导式相近,不过与列表推导式不同的是,生成器推导式的结果是一个生成器对象,而不是列表,也不是元组。使用生成器对象的元素时,可以根据需要将其转化为列表或元组,也可以使用生成器对象的next()方法(Python 2.x)或__next__()方法(Python 3.x)进行遍历,或者直接将其作为迭代器对象来使用
>>> g=((i+2)**2 for i in range(10)) >>> g <generator object <genexpr> at 0x02B15C60> >>>tuple(g) (4, 9, 16, 25, 36, 49, 64, 81, 100, 121) >>> tuple(g) () >>> g=((i+2)**2 for i in range(10)) >>> g.next() #在python 3中应改为__next__() 4 >>> g.next() 9 >>> g.next() 16 >>> g.next() 25
注意这个生成器推导式产生的对象的一个特点:一次性,如在变成一个元组后,生成的可迭代对象就变成了空值,这个和前面python3中range函数和zip函数以及map函数返回的值相近,也就是惰性求值的思想。
字典
字典其实一直是我比较烦的地方了,,,,这里借用我们老师的话对之进行一个概述
字典是键值对(key-value pair)的无序可变集合
定义字典时,每个元素的键和值用冒号分隔,元素之间用逗号分隔,所有的元素放在一对大括号{ 和 }中
字典中的每个元素包含两部分:键和值,向字典添加一个键的同时,必须为该键增添一个值
字典中的键可以为任意不可变对象,比如整数、实数、复数、字符串、元组等等
字典中的键不允许重复
这里索性就把所有关于字典的东西整理一下吧
字典的创建
#创建空字典1 d = {} print(d) #创建空字典2 d = dict() #直接赋值方式 d = {"one":1,"two":2,"three":3,"four":4} #常规字典生成式 dd = {k:v for k,v in d.items()} print(dd) #加限制条件的字典生成方式 ddd = {k:v for k,v in d.items() if v % 2 ==0} print(ddd)
访问、删除和变更
#访问字典中的数据 d = {"one":1,"two":2,"three":3,"four":4} print(d["one"]) #变更字典里面的数据 d["one"] = "eins" print(d) #删除一个数据,使用del del d["one"] print(d) #运行结果如下: {'one': 'eins', 'two': 2, 'three': 3, 'four': 4} {'two': 2, 'three': 3, 'four': 4}
还有几点:
使用字典对象的get方法获取指定键对应的值,并且可以在键不存在的时候返回指定值。如不指定,默认返回None
在Python 2.7中:
使用字典对象的items()方法可以返回字典的键、值对列表
使用字典对象的keys()方法可以返回字典的键列表
使用字典对象的values()方法可以返回字典的值列表
python3中以上几个函数返回的不再是列表,为一个可迭代的视图对象
#python3
>>> d=dict(zip(('e','r'),(1,2))) >>> d.keys() dict_keys(['e', 'r']) >>> d.values() dict_values([1, 2]) >>> d.items() dict_items([('e', 1), ('r', 2)])

 浙公网安备 33010602011771号
浙公网安备 33010602011771号