大数据项目实战---电商埋点日志分析(第一部分,往hdfs中写入埋点日志的数据)
https://www.bilibili.com/video/BV1L4411K7hW?p=31&spm_id_from=pageDriver
架构:
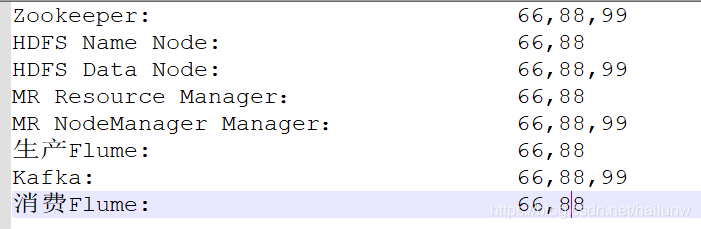
数据流
生产Flume读取日志文件做简单ETL后写入到kafka,然后消费Flume从kafka中将数据读出写入到hdfs。项目中还应用了zookeeper来协调分布式kafka和分布式Hadoop。
步骤
1)制作埋点日志dummy文件

1.1)编写Java程序生成埋点日志文件,并Maven打包(期望完成时间2021-7-2,实际完成时间2021-7-3) 
1.2)将打好的jar包传到66服务器和88服务器。
2)搭建Hadoop环境
安装Hadoop,并进行验证和调优。
<Hadoop_Home>/etc/hadoop/hdfs-site.xml
<Hadoop_Home>/etc/hadoop/core-site.xml
<Hadoop_Home>/etc/hadoop/yarn-site.xml
<Hadoop_Home>/etc/hadoop/mapred-site.xml
<Hadoop_Home>/etc/hadoop/hadoop-env.sh
<Hadoop_Home>/etc/hadoop/mapred-env.sh
<Hadoop_Home>/etc/hadoop/yarn-env.sh
<Hadoop_Home>/etc/hadoop/workers
zkServer.sh start
/home/user/hadoop-3.2.2/sbin/hadoop-daemon.sh start zkfc
/home/user/hadoop-3.2.2/sbin/start-dfs.sh
/home/user/hadoop-3.2.2/sbin/start-yarn.sh
3)安装配置Flume。
安装Flume,并进行验证和调优。
4)配置生产Flume,从日志文件中读取数据,写入到kafka。
4.1)在66服务器上配置文件file-flume-kafka.conf如下,然后分发到88和99服务器。
[user@NewBieMaster ~]$ vi /home/user/flume-1.9/conf/file-flume-kafka.conf
a1.source=r1 a1.channels= c1 c2 #configure source a1.sources.r1.type=TAILDIR a1.sources.r1.positionFile=/home/user/flume-1.9/test/log_position_json a1.sources.r1.filegroups=f1 a1.sources.r1.filegroups.f1=/tmp/debug.+ a1.sources.r1.fileHeader = true a1.sources.channels = c1 c2 #interceptor a1.sources.r1.interceptors= i1 i2 a1.sources.r1.interceptors.i1.type=com.example.flume.interceptor.LogETLInterceptor$Builder a1.sources.r1.interceptors.i2.type=com.example.flume.interceptor.LogTypeInterceptor$Builder a1.sources.r1.selector.type=multiplexing a1.sources.r1.selector.header=topic a1.sources.r1.selector.mapping.topic_start=c1 a1.sources.r1.selector.mapping.topic_event=c2 #configure channel a1.channels.c1.type=org.apache.flume.channel.kafka.KafkaChannel a1.channels.c1.kafka.bootstrap.servers=192.168.1.66:9092,192.168.1.88:9092,192.168.1.99:9092 a1.channels.c1.kafka.topic=topic_start a1.channels.c1.parseAsFlumeEvent = false a1.channels.c1.kafka.consumer.groupd.id=flume-consumer a1.channels.c2.type=org.apache.flume.channel.kafka.KafkaChannel a1.channels.c2.kafka.bootstrap.servers=192.168.1.66:9092,192.168.1.88:9092,192.168.1.99:9092 a1.channels.c2.kafka.topic=topic_event a1.channels.c2.parseAsFlumeEvent = false a1.channels.c2.kafka.consumer.groupd.id=flume-consumer
4.2)创建Java Maven工程,制作拦截器com.example.flume.interceptor.LogETLInterceptor$Builder和com.example.flume.interceptor.LogTypeInterceptor$Builder。
5)安装kafka
安装Kafka,并进行验证和调优
6)在66服务器上启动flume agent,查看kafka队列
~/flume-1.9/bin/flume-ng agent --name a1 -con-file ./conf/file-flume-kafka.conf -Dlume.root.logger=FINEST &
kafka-topics.sh --zookeeper 192.168.1.66:2181,192.168.1.88:2181,192.168.1.99:2181 --list
kafka-topics.sh --zookeeper 192.168.1.66:2181,192.168.1.88:2181,192.168.1.99:2181 --describe topic_start
kafka-topics.sh --zookeeper 192.168.1.66:2181,192.168.1.88:2181,192.168.1.99:2181 --describe topic_event
[user@NewBieMaster tmp]$ kafka-topics.sh --zookeeper 192.168.1.66:2181,192.168.1.88:2181,192.168.1.99:2181 --list
__consumer_offsets
test
topic_event
topic_start
[user@NewBieMaster tmp]$
7)安装配置kafka manager,通过kafkamanager查看kafka
安装配置的步骤
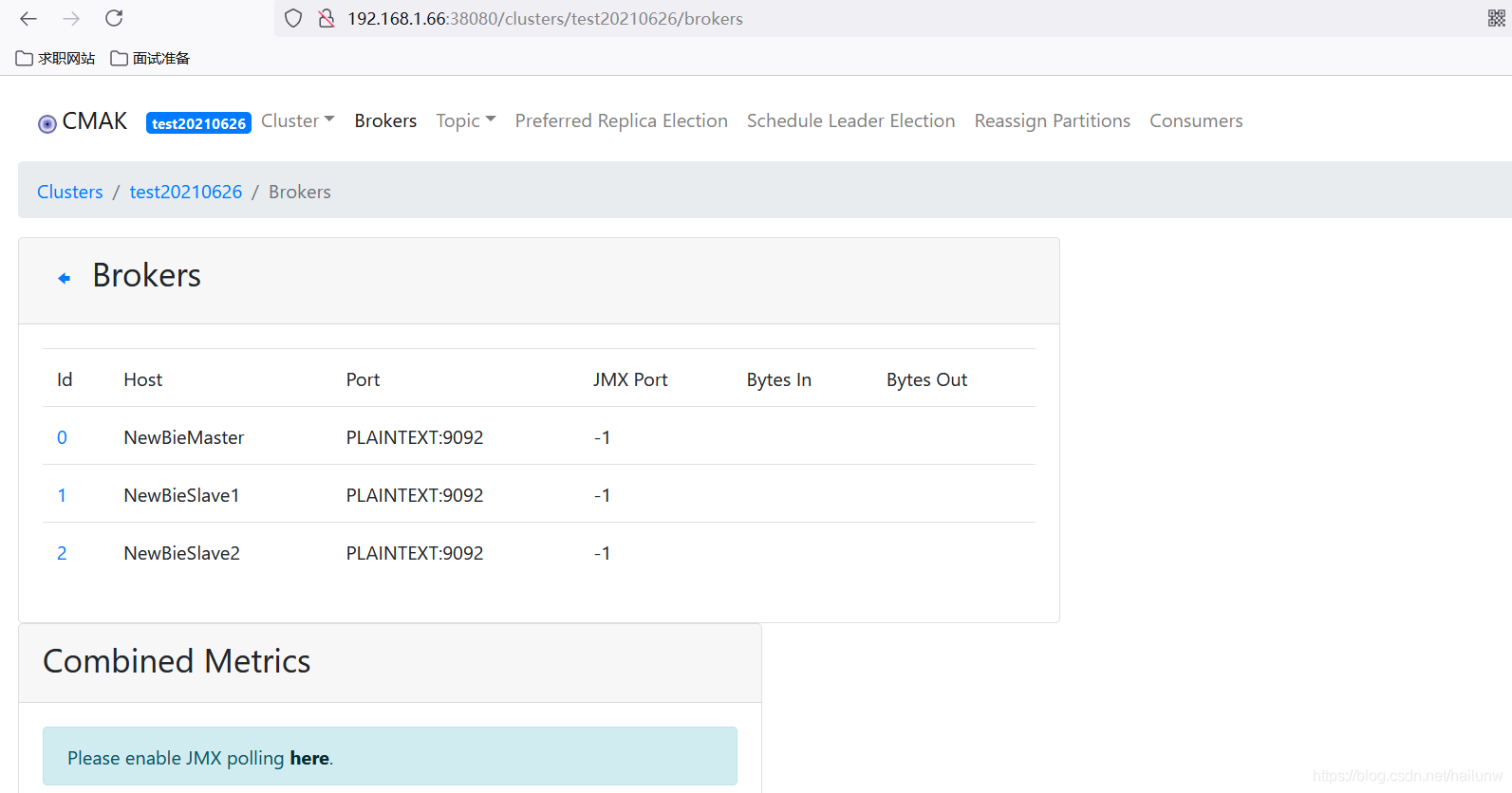
8)配置消费Flume,从kafka中读取数据,写入到hdfs。
8.1)在99服务器上配置文件kafka-flume-hdfs.conf如下,然后分发到88和66服务器。
##组件
a1.sources= r1 r2
a1.channels = c1 c2
a1.sinks = k1 k2
##source1
a1.sources.r1.type=org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.batchSize = 500
a1.sources.r1.batchDurationMillis = 200
a1.sources.r1.kafka.bootstrap.servers=192.168.1.66:9092,192.168.1.88:9092,192.168.1.99:9092
a1.sources.r1.kafka.topics=topic_start
##source2
a1.sources.r2.type=org.apache.flume.source.kafka.KafkaSource
a1.sources.r2.batchSize = 500
a1.sources.r2.batchDurationMillis = 200
a1.sources.r2.kafka.bootstrap.servers=192.168.1.66:9092,192.168.1.88:9092,192.168.1.99:9092
a1.sources.r2.kafka.topics=topic_event
##channel1
a1.channels.c1.type= file
a1.channels.c1.checkpointDir=/tmp/flumecheckpoint/behavior1
a1.channels.c1.dataDirs=/tmp/flumedata/behavior1
a1.channels.c1.maxFileSize=2146435071
a1.channels.c1.capacity=1000000
a1.channels.c1.keep-alive=6
##channel2
a1.channels.c2.type= file
a1.channels.c2.checkpointDir=/tmp/flumecheckpoint/behavior2
a1.channels.c2.dataDirs=/tmp/flumedata/behavior2
a1.channels.c2.maxFileSize=2146435071
a1.channels.c2.capacity=1000000
a1.channels.c2.keep-alive=6
##sink1
a1.sinks.k1.type=hdfs
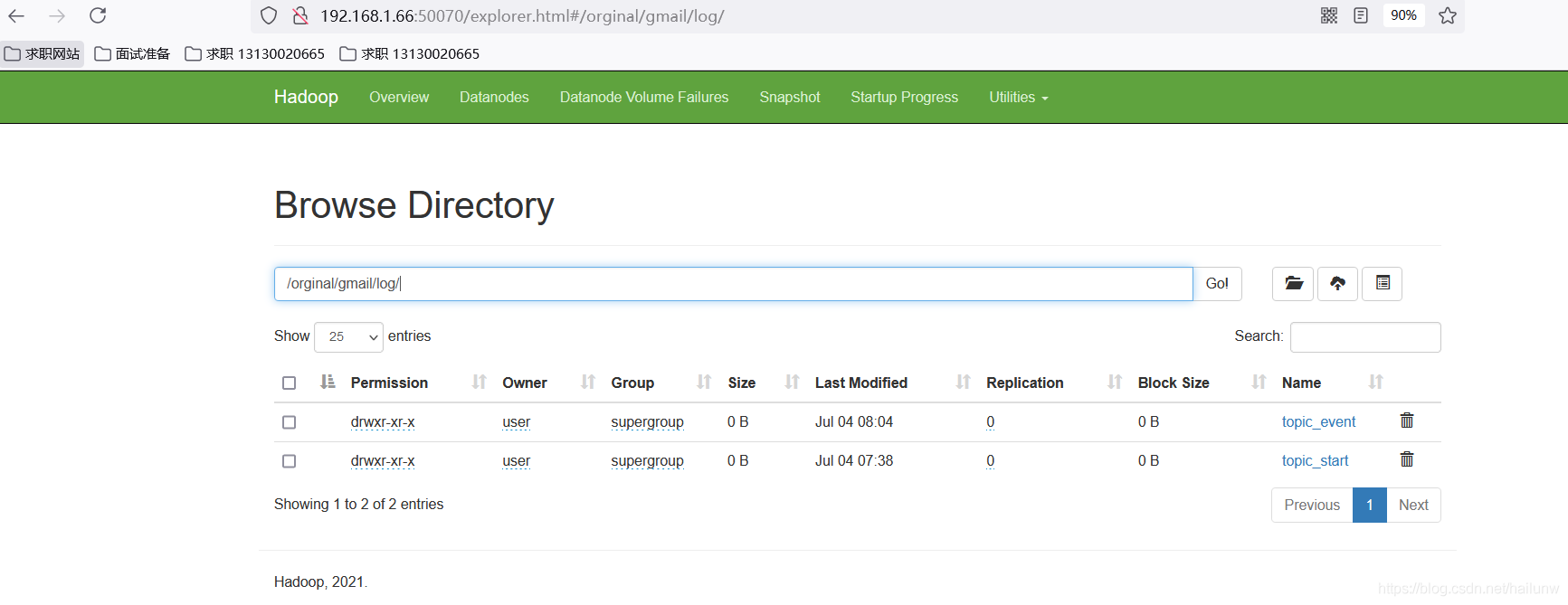
a1.sinks.k1.hdfs.path=/orginal/gmail/log/topic_start/%Y-%m-%d
a1.sinks.k1.hdfs.filePrefix=logstart-
a1.sinks.hdfs.round=true
a1.sinks.hdfs.roundValue=10
a1.sinks.hdfs.roundUnit=second
##sink2
a1.sinks.k2.type=hdfs
a1.sinks.k2.hdfs.path=/orginal/gmail/log/topic_event/%Y-%m-%d
a1.sinks.k2.hdfs.filePrefix=logstart-
a1.sinks.hdfs.round=true
a1.sinks.hdfs.roundValue=10
a1.sinks.hdfs.roundUnit=second
##不产生小文件
a1.sinks.k1.hdfs.rollInterval=10
a1.sinks.k1.hdfs.rollSize=134217728
a1.sinks.k1.hdfs.rollCount=0
a1.sinks.k2.hdfs.rollInterval=10
a1.sinks.k2.hdfs.rollSize=134217728
a1.sinks.k2.hdfs.rollCount=0
##控制数出文件是原生文件
a1.sinks.k1.hdfs.fileType=CompressedStream
a1.sinks.k2.hdfs.fileType=CompressedStream
a1.sinks.k1.hdfs.codeC=lzop
a1.sinks.k2.hdfs.codeC=lzop
##拼装
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
a1.sources.r2.channels=c2
a1.sinks.k2.channel=c2

 浙公网安备 33010602011771号
浙公网安备 33010602011771号