

联合分布(一):什么是概率分布
1)基础知识预备:概率分布
1.1)定义:
广义地,它指称随机变量的概率性质,即一个随机变量在概率空间的分布状况
狭义地,它是指随机变量的概率分布函数,定义如下:
对于任意实数a,有: FX(a) = P(X≤a) ,FX(a)即是a的概率分布函数,而 P(X≤a) 则是在随机变量X取值≤a时的所有的概率之和,所以概率分布函数又称为累计概率函数。
ps:个人认为叫做累计概率函数更好理解一些啊!!!更详细的剖解请参考 https://www.jianshu.com/p/b570b1ba92bb
但是对于离散分布,再用FX(a) = P(X≤a) 这个公式表达就不准确了,因为FX(a)表示的是随机变量X≤a的概率值之和,但是当X是离散随机变量的话,X≤a显然就不合理了。所以对于离散分布:
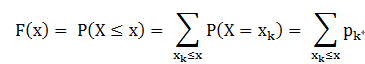
用语言来描述的话,就是:把所有小于等于x的概率值相加,所以本质上还是概率的累积值,只不过在表达上比上式更为严谨。
1.2)研究的意义:
说完了概率分布的定义,接下来我们当然要了解这个概率分布它到底有什么用,为什么我们要去研究它?这样以便我们能够更好的理解它。
举个例子吧:将每一天的降雨量设为X,显然,这个X是一个随机变量,那么你如果要研究降雨量,你是会选择研究当X等于某一特定值得概率还是会选择研究X落在实数域上某一区间上的概率呢?
显而易见,肯定是后者啦。你看天气预报有把每个降雨量的概率告诉你吗(当然这个也不可能。。。),还不是告诉你明天是小雨还是中雨或者是大雨用这样的区间的形式。而概率分布就是描述一个随机变量在某一个区间上的概率。
下面是从各处引用(ctrl+c、ctrl+v)来的我们经常会听到的一些随机分布。因为本文的重点是为了引出联合分布这个知识点,所以对下面的各种分布就不多说了。
ps:以上都是一些不成熟的个人见解,如果有误,还烦请指出!
1.3)常见的几种分布:
#二项分布:详细请参考:https://zh.wikipedia.org/wiki/%E4%BA%8C%E9%A0%85%E5%88%86%E4%BD%88
二项分布是一种离散型的概率分布。故明思义,二项代表这个随机变量只有两种可能的结果。
掷硬币就是一个典型的二项分布。当我们要计算抛硬币n次,恰巧有x次正面朝上的概率,可以使用二项分布的公式:
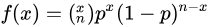
其中,p为正面朝上的概率
#泊松分布:
泊松分布适合于描述单位时间内随机事件发生的次数的概率分布。如某一服务设施在一定时间内受到的服务请求的次数
泊松分布的概率质量函数为:

泊松分布的参数λ是单位时间(或单位面积)内随机事件的平均发生率。
#正态分布:
又名高斯分布,是一个非常常见的连续概率分布。正态分布在统计学上十分重要,经常用在自然和社会科学来代表一个不明的随机变量。
若随机变量



有几种不同的方法用来说明一个随机变量。最直观的方法是概率密度函数,这种方法能够表示随机变量每个取值有多大的可能性。
累积分布函数是一种概率上更加清楚的方法,请看下边的例子。
正态分布的概率密度函数:
![]()
正态分布的累计概率函数(由密度函数表示的):
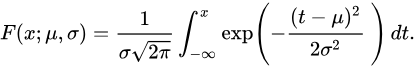
正态分布的累积分布函数能够由一个叫做误差函数的特殊函数表示:
![\Phi (z)={\frac 12}\left[1+\operatorname {erf}\left({\frac {z-\mu }{\sigma {\sqrt 2}}}\right)\right].](https://wikimedia.org/api/rest_v1/media/math/render/svg/bbbfb0d7d4f08fe1c4d0e13a840838636797a3c2)
标准正态分布的累积分布函数习惯上记为



将一般正态分布用误差函数表示的公式简化,可得:
![\Phi(z)
=
\frac{1}{2} \left[ 1 + \operatorname{erf} \left( \frac{z}{\sqrt{2}} \right) \right]
.](https://wikimedia.org/api/rest_v1/media/math/render/svg/bc207a97dbcecd9eac86cabd73cf457bbade004e)
关于正态分布的几个特征:
a.密度函数关于平均值对称
b.平均值与它的众数(statistical mode)以及中位数(median)同一数值。
c.函数曲线下68.268949%的面积在平均数左右的一个标准差范围内。
d.95.449974%的面积在平均数左右两个标准差
e.99.730020%的面积在平均数左右三个标准差
f.99.993666%的面积在平均数左右四个标准差
g.函数曲线的拐点为离平均数一个标准差距离的位置。
关于正态分布的几个性质:
- 如果
且
与
是实数,那么
- 如果
与
是统计独立的正态随机变量,那么:
- 它们的和也满足正态分布
- 它们的差也满足正态分布
.
与
两者是相互独立的。(要求X与Y的方差相等)
- 它们的和也满足正态分布
- 如果
和
是独立正态随机变量,那么:如果
为独立标准正态随机变量,那么
服从自由度为n的卡方分布。
- 它们的积
服从概率密度函数为
的分布
其中
是修正贝塞尔函数(modified Bessel function)
- 它们的比符合柯西分布,满足
.
- 它们的积
 且
且 与
与 是实数,那么
是实数,那么
 与
与 是统计独立的正态随机变量,那么:
是统计独立的正态随机变量,那么:
 .
. 与
与 两者是相互独立的。(要求X与Y的方差相等)
两者是相互独立的。(要求X与Y的方差相等) 和
和 是独立正态随机变量,那么:
是独立正态随机变量,那么: 为独立标准正态随机变量,那么
为独立标准正态随机变量,那么 服从自由度为n的卡方分布。
服从自由度为n的卡方分布。 服从概率密度函数为
服从概率密度函数为 的分布
的分布 其中
其中 是修正贝塞尔函数(modified Bessel function)
是修正贝塞尔函数(modified Bessel function) .
.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号