
kubernetes 存储
前面我们有通过 hostPath 或者 emptyDir 的方式来持久化我们的数据,但是显然我们还需要更加可靠的存储来保存应用的持久化数据,这样容器在重建后,依然可以使用之前的数据。但是存储资源和 CPU 资源以及内存资源有很大不同,为了屏蔽底层的技术实现细节,让用户更加方便的使用,Kubernetes 便引入了 PV 和 PVC 两个重要的资源对象来实现对存储的管理。
概念
PV 的全称是:PersistentVolume(持久化卷),是对底层共享存储的一种抽象,PV 由管理员进行创建和配置,它和具体的底层的共享存储技术的实现方式有关,比如 Ceph、GlusterFS、NFS、hostPath 等,都是通过插件机制完成与共享存储的对接。
PVC 的全称是:PersistentVolumeClaim(持久化卷声明),PVC 是用户存储的一种声明,PVC 和 Pod 比较类似,Pod 消耗的是节点,PVC 消耗的是 PV 资源,Pod 可以请求 CPU 和内存,而 PVC 可以请求特定的存储空间和访问模式。对于真正使用存储的用户不需要关心底层的存储实现细节,只需要直接使用 PVC 即可。
但是通过 PVC 请求到一定的存储空间也很有可能不足以满足应用对于存储设备的各种需求,而且不同的应用程序对于存储性能的要求可能也不尽相同,比如读写速度、并发性能等,为了解决这一问题,Kubernetes 又为我们引入了一个新的资源对象:StorageClass,通过 StorageClass 的定义,管理员可以将存储资源定义为某种类型的资源,比如快速存储、慢速存储等,用户根据 StorageClass 的描述就可以非常直观的知道各种存储资源的具体特性了,这样就可以根据应用的特性去申请合适的存储资源了,此外 StorageClass 还可以为我们自动生成 PV,免去了每次手动创建的麻烦。
Local 存储
hostPath
上面提到了 PV 是对底层存储技术的一种抽象,PV 一般都是由管理员来创建和配置的,我们首先来创建一个 hostPath 类型的 PersistentVolume。Kubernetes 支持 hostPath 类型的 PersistentVolume 使用节点上的文件或目录来模拟附带网络的存储,但是需要注意的是在生产集群中,我们不会使用 hostPath,集群管理员会提供网络存储资源,比如 NFS 共享卷或 Ceph 存储卷,集群管理员还可以使用 StorageClasses 来设置动态提供存储。因为 Pod 并不是始终固定在某个节点上面的,所以要使用 hostPath 的话我们就需要将 Pod 固定在某个节点上,这样显然就大大降低了应用的容错性。
比如我们这里将测试的应用固定在节点 ydzs-node1 上面,首先在该节点上面创建一个 /data/k8s/test/hostpath 的目录,然后在该目录中创建一个 index.html 的文件:
$ echo 'Hello from Kubernetes hostpath storage' > /data/k8s/test/hostpath/index.html
然后接下来创建一个 hostPath 类型的 PV 资源对象:(pv-hostpath.yaml)
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv-hostpath
labels:
type: local
spec:
storageClassName: manual
capacity:
storage: 10Gi
accessModes:
- ReadWriteOnce
hostPath:
path: "/data/k8s/test/hostpath"
配置文件中指定了该卷位于集群节点上的 /data/k8s/test/hostpath 目录,还指定了 10G 大小的空间和 ReadWriteOnce 的访问模式,这意味着该卷可以在单个节点上以读写方式挂载,另外还定义了名称为 manual 的 StorageClass,该名称用来将 PersistentVolumeClaim 请求绑定到该 PersistentVolum。下面是关于 PV 的这些配置属性的一些说明:
- Capacity(存储能力):一般来说,一个 PV 对象都要指定一个存储能力,通过 PV 的 capacity 属性来设置的,目前只支持存储空间的设置,就是我们这里的 storage=10Gi,不过未来可能会加入 IOPS、吞吐量等指标的配置。
- AccessModes(访问模式):用来对 PV 进行访问模式的设置,用于描述用户应用对存储资源的访问权限,访问权限包括下面几种方式:
- ReadWriteOnce(RWO):读写权限,但是只能被单个节点挂载
- ReadOnlyMany(ROX):只读权限,可以被多个节点挂载
- ReadWriteMany(RWX):读写权限,可以被多个节点挂载
注意: 一些 PV 可能支持多种访问模式,但是在挂载的时候只能使用一种访问模式,多种访问模式是不会生效的。
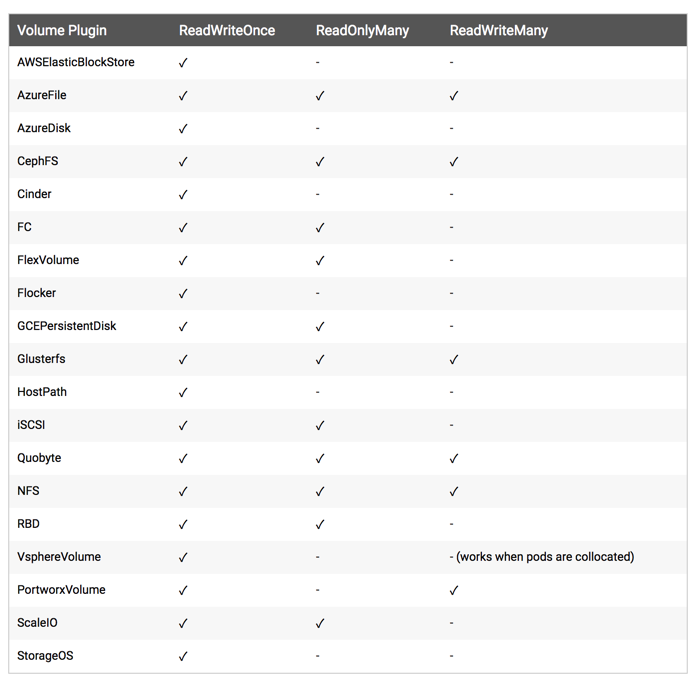
下图是一些常用的 Volume 插件支持的访问模式:
直接创建上面的资源对象:
$ kubectl apply -f pv-hostpath.yaml
persistentvolume/pv-hostpath created
创建完成后查看 PersistentVolume 的信息,输出结果显示该 PersistentVolume 的状态(STATUS) 为 Available。 这意味着它还没有被绑定给 PersistentVolumeClaim:
$ kubectl get pv pv-hostpath
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pv-hostpath 10Gi RWO Retain Available manual 58s
其中有一项 RECLAIM POLICY 的配置,同样我们可以通过 PV 的 persistentVolumeReclaimPolicy(回收策略)属性来进行配置,目前 PV 支持的策略有三种:
- Retain(保留):保留数据,需要管理员手工清理数据
- Recycle(回收):清除 PV 中的数据,效果相当于执行 rm -rf /thevoluem/*
- Delete(删除):与 PV 相连的后端存储完成 volume 的删除操作,当然这常见于云服务商的存储服务,比如 ASW EBS。
不过需要注意的是,目前只有 NFS 和 HostPath 两种类型支持回收策略,当然一般来说还是设置为 Retain 这种策略保险一点。
注意: Recycle 策略会通过运行一个 busybox 容器来执行数据删除命令,默认定义的 busybox 镜像是:gcr.io/google_containers/busybox:latest,并且 imagePullPolicy: Always,如果需要调整配置,需要增加kube-controller-manager 启动参数:--pv-recycler-pod-template-filepath-hostpath 来进行配置。
关于 PV 的状态,实际上描述的是 PV 的生命周期的某个阶段,一个 PV 的生命周期中,可能会处于4种不同的阶段:
- Available(可用):表示可用状态,还未被任何 PVC 绑定
- Bound(已绑定):表示 PVC 已经被 PVC 绑定
- Released(已释放):PVC 被删除,但是资源还未被集群重新声明
- Failed(失败): 表示该 PV 的自动回收失败
现在我们创建完成了 PV,如果我们需要使用这个 PV 的话,就需要创建一个对应的 PVC 来和他进行绑定了,就类似于我们的服务是通过 Pod 来运行的,而不是 Node,只是 Pod 跑在 Node 上而已。
现在我们来创建一个 PersistentVolumeClaim,Pod 使用 PVC 来请求物理存储,我们这里创建的 PVC 请求至少 3G 容量的卷,该卷至少可以为一个节点提供读写访问,下面是 PVC 的配置文件:(pvc-hostpath.yaml)
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-hostpath
spec:
storageClassName: manual
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 3Gi
同样我们可以直接创建这个 PVC 对象:
$ kubectl create -f pvc-hostpath.yaml
persistentvolumeclaim/pvc-hostpath created
创建 PVC 之后,Kubernetes 就会去查找满足我们声明要求的 PV,比如 storageClassName、accessModes 以及容量这些是否满足要求,如果满足要求就会将 PV 和 PVC 绑定在一起。
注意: 需要注意的是目前 PV 和 PVC 之间是一对一绑定的关系,也就是说一个 PV 只能被一个 PVC 绑定。
我们现在再次查看 PV 的信息:
$ kubectl get pv -l type=local
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pv-hostpath 10Gi RWO Retain Bound default/pvc-hostpath manual 81m
现在输出的 STATUS 为 Bound,查看 PVC 的信息:
$ kubectl get pvc pvc-hostpath
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
pvc-hostpath Bound pv-hostpath 10Gi RWO manual 6m47s
输出结果表明该 PVC 绑定了到了上面我们创建的 pv-hostpath 这个 PV 上面了,我们这里虽然声明的3G的容量,但是由于 PV 里面是 10G,所以显然也是满足要求的。
apiVersion: v1
kind: Pod
metadata:
name: pv-hostpath-pod
spec:
volumes:
- name: pv-hostpath
persistentVolumeClaim:
claimName: pvc-hostpath
nodeSelector:
kubernetes.io/hostname: ydzs-node1
containers:
- name: task-pv-container
image: nginx
ports:
- containerPort: 80
volumeMounts:
- mountPath: "/usr/share/nginx/html"
name: pv-hostpath
这里需要注意的是,由于我们创建的 PV 真正的存储在节点 ydzs-node1 上面,所以我们这里必须把 Pod 固定在这个节点下面,另外可以注意到 Pod 的配置文件指定了 PersistentVolumeClaim,但没有指定 PersistentVolume,对 Pod 而言,PVC 就是一个存储卷。直接创建这个 Pod 对象即可:
$ kubectl create -f pv-hostpath-pod.yaml
pod/pv-hostpath-pod created
$ kubectl get pod pv-hostpath-pod
NAME READY STATUS RESTARTS AGE
pv-hostpath-pod 1/1 Running 0 105s
运行成功后,我们可以打开一个 shell 访问 Pod 中的容器:
$ kubectl exec -it pv-hostpath-pod -- /bin/bash
在 shell 中,我们可以验证 nginx 的数据 是否正在从 hostPath 卷提供 index.html 文件:
root@pv-hostpath-pod:/# apt-get update
root@pv-hostpath-pod:/# apt-get install curl -y
root@pv-hostpath-pod:/# curl localhost
Hello from Kubernetes hostpath storage
我们可以看到输出结果是我们前面写到 hostPath 卷种的 index.html 文件中的内容,同样我们可以把 Pod 删除,然后再次重建再测试一次,可以发现内容还是我们在 hostPath 种设置的内容。
我们在持久化容器数据的时候使用 PV/PVC 有什么好处呢?比如我们这里之前直接在 Pod 下面也可以使用 hostPath 来持久化数据,为什么还要费劲去创建 PV、PVC 对象来引用呢?PVC 和 PV 的设计,其实跟“面向对象”的思想完全一致,PVC 可以理解为持久化存储的“接口”,它提供了对某种持久化存储的描述,但不提供具体的实现;而这个持久化存储的实现部分则由 PV 负责完成。这样做的好处是,作为应用开发者,我们只需要跟 PVC 这个“接口”打交道,而不必关心具体的实现是 hostPath、NFS 还是 Ceph。毕竟这些存储相关的知识太专业了,应该交给专业的人去做,这样对于我们的 Pod 来说就不用管具体的细节了,你只需要给我一个可用的 PVC 即可了,这样是不是就完全屏蔽了细节和解耦了啊,所以我们更应该使用 PV、PVC 这种方式。
PVC 准备好过后,接下来我们就可以来创建 Pod 了,该 Pod 使用上面我们声明的 PVC 作为存储卷:(pv-hostpath-pod.yaml)
Local PV
上面我们创建了后端是 hostPath 类型的 PV 资源对象,我们也提到了,使用 hostPath 有一个局限性就是,我们的 Pod 不能随便漂移,需要固定到一个节点上,因为一旦漂移到其他节点上去了宿主机上面就没有对应的数据了,所以我们在使用 hostPath 的时候都会搭配 nodeSelector 来进行使用。但是使用 hostPath 明显也有一些好处的,因为 PV 直接使用的是本地磁盘,尤其是 SSD 盘,它的读写性能相比于大多数远程存储来说,要好得多,所以对于一些对磁盘 IO 要求比较高的应用比如 etcd 就非常实用了。不过呢,相比于正常的 PV 来说,使用了 hostPath 的这些节点一旦宕机数据就可能丢失,所以这就要求使用 hostPath 的应用必须具备数据备份和恢复的能力,允许你把这些数据定时备份在其他位置。
所以在 hostPath 的基础上,Kubernetes 依靠 PV、PVC 实现了一个新的特性,这个特性的名字叫作:Local Persistent Volume,也就是我们说的 Local PV。
其实 Local PV 实现的功能就非常类似于 hostPath 加上 nodeAffinity,比如,一个 Pod 可以声明使用类型为 Local 的 PV,而这个 PV 其实就是一个 hostPath 类型的 Volume。如果这个 hostPath 对应的目录,已经在节点 A 上被事先创建好了,那么,我只需要再给这个 Pod 加上一个 nodeAffinity=nodeA,不就可以使用这个 Volume 了吗?理论上确实是可行的,但是事实上,我们绝不应该把一个宿主机上的目录当作 PV 来使用,因为本地目录的存储行为是完全不可控,它所在的磁盘随时都可能被应用写满,甚至造成整个宿主机宕机。所以,一般来说 Local PV 对应的存储介质是一块额外挂载在宿主机的磁盘或者块设备,我们可以认为就是“一个 PV 一块盘”。
另外一个 Local PV 和普通的 PV 有一个很大的不同在于 Local PV 可以保证 Pod 始终能够被正确地调度到它所请求的 Local PV 所在的节点上面,对于普通的 PV 来说,Kubernetes 都是先调度 Pod 到某个节点上,然后再持久化节点上的 Volume 目录,进而完成 Volume 目录与容器的绑定挂载,但是对于 Local PV 来说,节点上可供使用的磁盘必须是提前准备好的,因为它们在不同节点上的挂载情况可能完全不同,甚至有的节点可以没这种磁盘,所以,这时候,调度器就必须能够知道所有节点与 Local PV 对应的磁盘的关联关系,然后根据这个信息来调度 Pod,实际上就是在调度的时候考虑 Volume 的分布。
接下来我们来测试下 Local PV 的使用,当然按照上面我们的分析我们应该给宿主机挂载并格式化一个可用的磁盘,我们这里就暂时将 ydzs-node1 节点上的 /data/k8s/localpv 这个目录看成是挂载的一个独立的磁盘。现在我们来声明一个 Local PV 类型的 PV,如下所示:(pv-local.yaml)
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv-local
spec:
capacity:
storage: 5Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Delete
storageClassName: local-storage
local:
path: /data/k8s/localpv # ydzs-node1节点上的目录
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- ydzs-node1
和前面我们定义的 PV 不同,我们这里定义了一个 local 字段,表明它是一个 Local PV,而 path 字段,指定的正是这个 PV 对应的本地磁盘的路径,即:/data/k8s/localpv,这也就意味着如果 Pod 要想使用这个 PV,那它就必须运行在 ydzs-node1 节点上。所以,在这个 PV 的定义里,添加了一个节点亲和性 nodeAffinity 字段指定 ydzs-node1 这个节点。这样,调度器在调度 Pod 的时候,就能够知道一个 PV 与节点的对应关系,从而做出正确的选择。
直接创建上面的资源对象:
$ kubectl apply -f pv-local.yaml
persistentvolume/pv-local created
$ kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pv-local 5Gi RWO Delete Available local-storage 24s
可以看到,这个 PV 创建后,进入了 Available(可用)状态。这个时候如果按照前面提到的,我们要使用这个 Local PV 的话就需要去创建一个 PVC 和他进行绑定:(pvc-local.yaml)
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: pvc-local
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5Gi
storageClassName: local-storage
同样要注意声明的这些属性需要和上面的 PV 对应,直接创建这个资源对象:
$ kubectl apply -f pvc-local.yaml
persistentvolumeclaim/pvc-local created
$ kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
pvc-local Bound pv-local 5Gi RWO local-storage 38s
可以看到现在 PVC 和 PV 已经处于 Bound 绑定状态了。但实际上这是不符合我们的需求的,比如现在我们的 Pod 声明使用这个 pvc-local,并且我们也明确规定,这个 Pod 只能运行在 ydzs-node2 这个节点上,如果按照上面我们这里的操作,这个 pvc-local 是不是就和我们这里的 pv-local 这个 Local PV 绑定在一起了,但是这个 PV 的存储券又在 ydzs-node1 这个节点上,显然就会出现冲突了,那么这个 Pod 的调度肯定就会失败了,所以我们在使用 Local PV 的时候,必须想办法延迟这个“绑定”操作。
要怎么来实现这个延迟绑定呢?我们可以通过创建 StorageClass 来指定这个动作,在 StorageClass 种有一个 volumeBindingMode=WaitForFirstConsumer 的属性,就是告诉 Kubernetes 在发现这个 StorageClass 关联的 PVC 与 PV 可以绑定在一起,但不要现在就立刻执行绑定操作(即:设置 PVC 的 VolumeName 字段),而是要等到第一个声明使用该 PVC 的 Pod 出现在调度器之后,调度器再综合考虑所有的调度规则,当然也包括每个 PV 所在的节点位置,来统一决定,这个 Pod 声明的 PVC,到底应该跟哪个 PV 进行绑定。通过这个延迟绑定机制,原本实时发生的 PVC 和 PV 的绑定过程,就被延迟到了 Pod 第一次调度的时候在调度器中进行,从而保证了这个绑定结果不会影响 Pod 的正常调度。
所以我们需要创建对应的 StorageClass 对象:(local-storageclass.yaml)
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: local-storage
provisioner: kubernetes.io/no-provisioner
volumeBindingMode: WaitForFirstConsumer
这个 StorageClass 的名字,叫作 local-storage,也就是我们在 PV 中声明的,需要注意的是,在它的 provisioner 字段,我们指定的是 no-provisioner。这是因为我们这里是手动创建的 PV,所以不需要动态来生成 PV,另外这个 StorageClass 还定义了一个 volumeBindingMode=WaitForFirstConsumer 的属性,它是 Local PV 里一个非常重要的特性,即:延迟绑定。通过这个延迟绑定机制,原本实时发生的 PVC 和 PV 的绑定过程,就被延迟到了 Pod 第一次调度的时候在调度器中进行,从而保证了这个绑定结果不会影响 Pod 的正常调度。
现在我们来创建这个 StorageClass 资源对象:
$ kubectl apply -f local-storageclass.yaml
storageclass.storage.k8s.io/local-storage created
现在我们重新删除上面声明的 PVC 对象,重新创建:
$ kubectl delete -f pvc-local.yaml
persistentvolumeclaim "pvc-local" deleted
$ kubectl create -f pvc-local.yaml
persistentvolumeclaim/pvc-local created
$ kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
pvc-local Pending local-storage 3s
我们可以发现这个时候,集群中即使已经存在了一个可以与 PVC 匹配的 PV 了,但这个 PVC 依然处于 Pending 状态,也就是等待绑定的状态,这就是因为上面我们配置的是延迟绑定,需要在真正的 Pod 使用的时候才会来做绑定。
同样我们声明一个 Pod 来使用这里的 pvc-local 这个 PVC,资源对象如下所示:(pv-local-pod.yaml)
apiVersion: v1
kind: Pod
metadata:
name: pv-local-pod
spec:
volumes:
- name: example-pv-local
persistentVolumeClaim:
claimName: pvc-local
containers:
- name: example-pv-local
image: nginx
ports:
- containerPort: 80
volumeMounts:
- mountPath: /usr/share/nginx/html
name: example-pv-local
直接创建这个 Pod:
$ kubectl apply -f pv-local-pod.yaml
pod/pv-local-pod created
创建完成后我们这个时候去查看前面我们声明的 PVC,会立刻变成 Bound 状态,与前面定义的 PV 绑定在了一起:
$ kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
pvc-local Bound pv-local 5Gi RWO local-storage 4m59s
这时候,我们可以尝试在这个 Pod 的 Volume 目录里,创建一个测试文件,比如:
$ kubectl exec -it pv-local-pod /bin/sh
# cd /usr/share/nginx/html
# echo "Hello from Kubernetes local pv storage" > test.txt
#
然后,登录到 ydzs-node1 这台机器上,查看一下它的 /data/k8s/localpv 目录下的内容,你就可以看到刚刚创建的这个文件:
# 在ydzs-node1节点上
$ ls /data/k8s/localpv
test.txt
$ cat /data/k8s/localpv/test.txt
Hello from Kubernetes local pv storage
如果重新创建这个 Pod 的话,就会发现,我们之前创建的测试文件,依然被保存在这个持久化 Volume 当中:
$ kubectl delete -f pv-local-pod.yaml
$ kubectl apply -f pv-local-pod.yaml
$ kubectl exec -it pv-local-pod /bin/sh
# ls /usr/share/nginx/html
test.txt
# cat /usr/share/nginx/html/test.txt
Hello from Kubernetes local pv storage
#
到这里就说明基于本地存储的 Volume 是完全可以提供容器持久化存储功能的,对于 StatefulSet 这样的有状态的资源对象,也完全可以通过声明 Local 类型的 PV 和 PVC,来管理应用的存储状态。
需要注意的是,我们上面手动创建 PV 的方式,即静态的 PV 管理方式,在删除 PV 时需要按如下流程执行操作:
- 删除使用这个 PV 的 Pod
- 从宿主机移除本地磁盘
- 删除 PVC
- 删除 PV
如果不按照这个流程的话,这个 PV 的删除就会失败。
Ceph存储
Ceph 是一个统一的分布式存储系统,提供较好的性能、可靠性和可扩展性。最早起源于 Sage 博士期间的工作,随后贡献给开源社区。
简介

架构
支持三种接口
- Object:有原生 API,而且也兼容 Swift 和 S3 的 API
- Block:支持精简配置、快照、克隆
- File:Posix 接口,支持快照
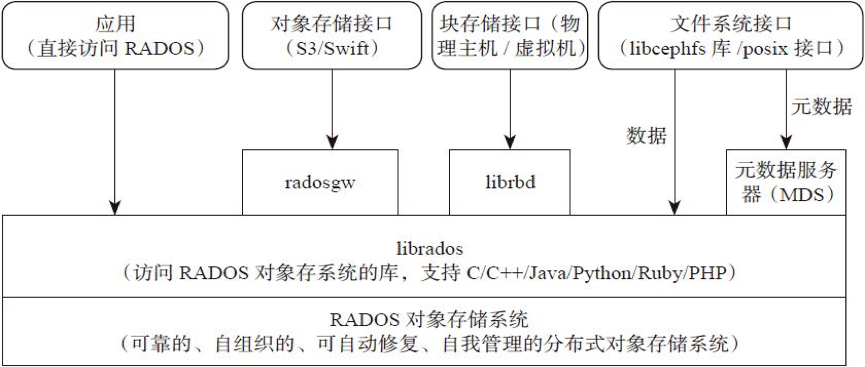
组件
Monitor:一个 Ceph 集群需要多个 Monitor 组成的小集群,它们通过 Paxos 同步数据,用来保存 OSD 的元数据。
OSD:全称 Object Storage Device,也就是负责响应客户端请求返回具体数据的进程,一个 Ceph 集群一般都有很多个 OSD。主要功能用于数据的存储,当直接使用硬盘作为存储目标时,一块硬盘称之为 OSD,当使用一个目录作为存储目标的时候,这个目录也被称为 OSD。
MDS:全称 Ceph Metadata Server,是 CephFS 服务依赖的元数据服务,对象存储和块设备存储不需要该服务。
Object:Ceph 最底层的存储单元是 Object 对象,一条数据、一个配置都是一个对象,每个 Object 包含 ID、元数据和原始数据。
Pool:Pool 是一个存储对象的逻辑分区,它通常规定了数据冗余的类型与副本数,默认为3副本。对于不同类型的存储,需要单独的 Pool,如 RBD。
PG:全称 Placement Grouops,是一个逻辑概念,一个 OSD 包含多个 PG。引入 PG 这一层其实是为了更好的分配数据和定位数据。每个 Pool 内包含很多个 PG,它是一个对象的集合,服务端数据均衡和恢复的最小单位就是 PG。
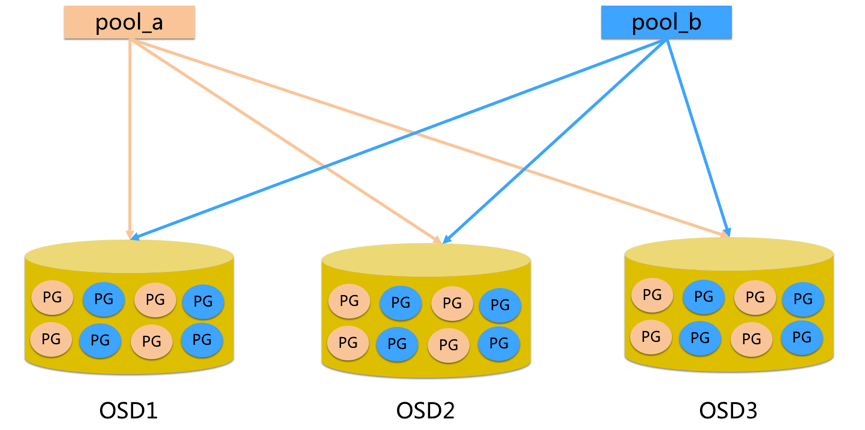
- pool 是 ceph 存储数据时的逻辑分区,它起到 namespace 的作用
- 每个 pool 包含一定数量(可配置)的 PG
- PG 里的对象被映射到不同的 Object 上
- pool 是分布到整个集群的
FileStore与BlueStore:FileStore 是老版本默认使用的后端存储引擎,如果使用 FileStore,建议使用 xfs 文件系统。BlueStore 是一个新的后端存储引擎,可以直接管理裸硬盘,抛弃了 ext4 与 xfs 等本地文件系统。可以直接对物理硬盘进行操作,同时效率也高出很多。
RADOS:全称 Reliable Autonomic Distributed Object Store,是 Ceph 集群的精华,用于实现数据分配、Failover 等集群操作。
Librados:Librados 是 Rados 提供库,因为 RADOS 是协议很难直接访问,因此上层的 RBD、RGW 和 CephFS 都是通过 librados 访问的,目前提供 PHP、Ruby、Java、Python、C 和 C++ 支持。
CRUSH:CRUSH 是 Ceph 使用的数据分布算法,类似一致性哈希,让数据分配到预期的地方。
RBD:全称 RADOS Block Device,是 Ceph 对外提供的块设备服务,如虚拟机硬盘,支持快照功能。
RGW:全称是 RADOS Gateway,是 Ceph 对外提供的对象存储服务,接口与 S3 和 Swift 兼容。
CephFS:全称 Ceph File System,是 Ceph 对外提供的文件系统服务。
块存储

部署
由于我们这里在 Kubernetes 集群中使用,也为了方便管理,我们这里使用 Rook 来部署 Ceph 集群,Rook 是一个开源的云原生存储编排工具,提供平台、框架和对各种存储解决方案的支持,以和云原生环境进行本地集成。
Rook 将存储软件转变成自我管理、自我扩展和自我修复的存储服务,通过自动化部署、启动、配置、供应、扩展、升级、迁移、灾难恢复、监控和资源管理来实现。Rook 底层使用云原生容器管理、调度和编排平台提供的能力来提供这些功能,其实就是我们平常说的 Operator。Rook 利用扩展功能将其深度集成到云原生环境中,并为调度、生命周期管理、资源管理、安全性、监控等提供了无缝的体验。有关 Rook 当前支持的存储解决方案的状态的更多详细信息,可以参考 Rook 仓库 的项目介绍。
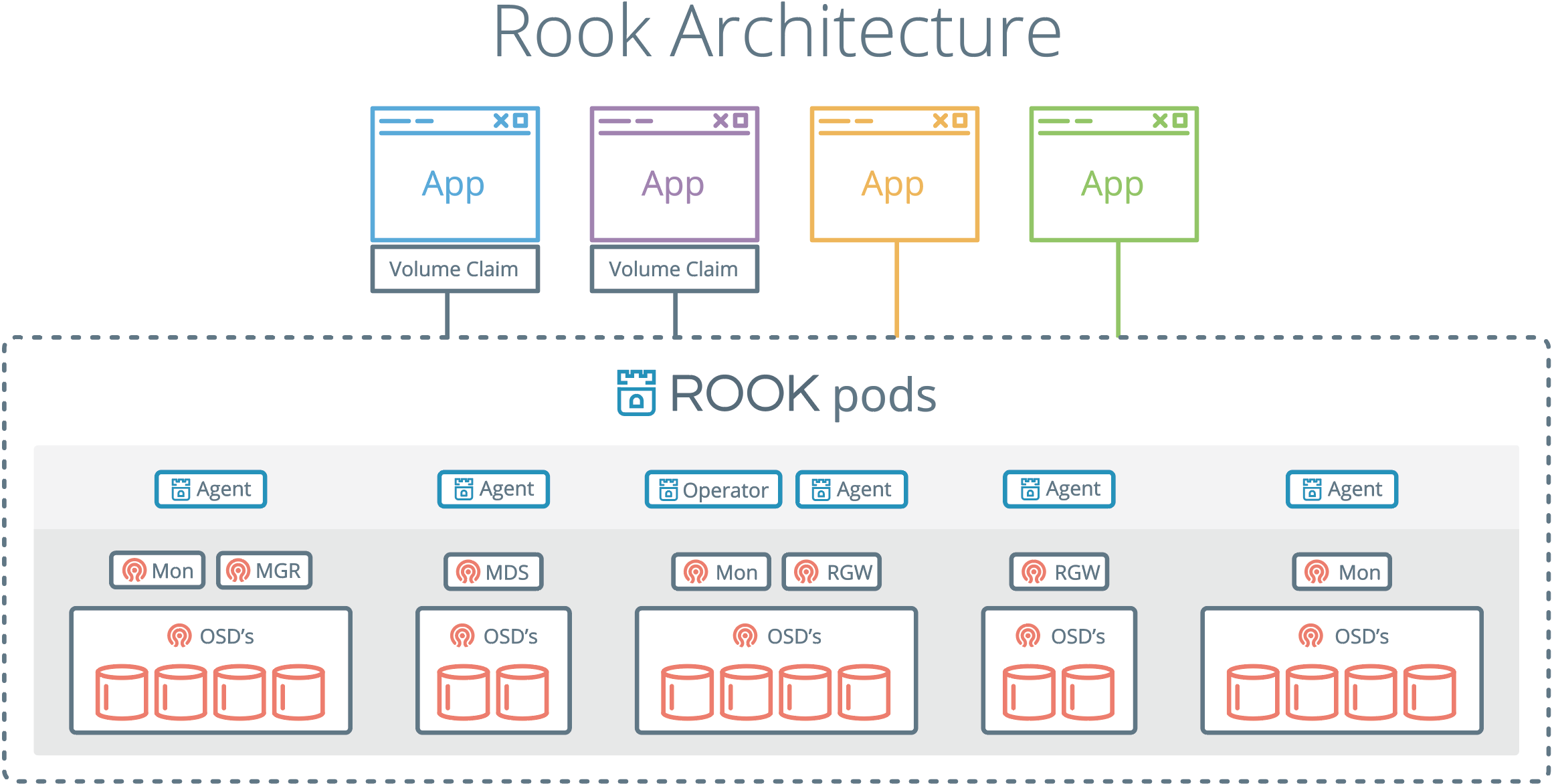
Rook 包含多个组件:
- Rook Operator:Rook 的核心组件,Rook Operator 是一个简单的容器,自动启动存储集群,并监控存储守护进程,来确保存储集群的健康。
- Rook Agent:在每个存储节点上运行,并配置一个 FlexVolume 或者 CSI 插件,和 Kubernetes 的存储卷控制框架进行集成。Agent 处理所有的存储操作,例如挂接网络存储设备、在主机上加载存储卷以及格式化文件系统等。
- Rook Discovers:检测挂接到存储节点上的存储设备。
Rook 还会用 Kubernetes Pod 的形式,部署 Ceph 的 MON、OSD 以及 MGR 守护进程。Rook Operator 让用户可以通过 CRD 来创建和管理存储集群。每种资源都定义了自己的 CRD:
- RookCluster:提供了对存储机群的配置能力,用来提供块存储、对象存储以及共享文件系统。每个集群都有多个 Pool。
- Pool:为块存储提供支持,Pool 也是给文件和对象存储提供内部支持。
- Object Store:用 S3 兼容接口开放存储服务。
- File System:为多个 Kubernetes Pod 提供共享存储。
环境
Rook Ceph 需要使用 RBD 内核模块,我们可以通过运行 modprobe rbd 来测试 Kubernetes 节点是否有该模块,如果没有,则需要更新下内核版本。
另外需要在节点上安装 lvm2 软件包:
# Centos
sudo yum install -y lvm2
# Ubuntu
sudo apt-get install -y lvm2
安装
我们这里部署最新的 release-1.2 版本的 Rook,部署清单文件地址:https://github.com/rook/rook/tree/release-1.2/cluster/examples/kubernetes/ceph。
从上面链接中下载 common.yaml 与 operator.yaml 两个资源清单文件:
# 会安装crd、rbac相关资源对象
$ kubectl apply -f common.yaml
# 安装 rook operator
$ kubectl apply -f operator.yaml
在继续操作之前,验证 rook-ceph-operator 是否处于“Running”状态:
$ kubectl get pods -n rook-ceph
NAME READY STATUS RESTARTS AGE
rook-ceph-operator-6d8fb9498b-jxdwx 1/1 Running 0 34s
rook-discover-7wpsl 1/1 Running 0 32s
rook-discover-8t8lv 1/1 Running 0 32s
rook-discover-9t497 1/1 Running 0 32s
rook-discover-v57rd 1/1 Running 0 32s
我们可以看到 Operator 运行成功后,还会有一个 DaemonSet 控制器运行得 rook-discover 应用,当 Rook Operator 处于 Running 状态,我们就可以创建 Ceph 集群了。为了使集群在重启后不受影响,请确保设置的 dataDirHostPath 属性值为有效得主机路径。更多相关设置,可以查看集群配置相关文档。
创建如下的资源清单文件:(cluster.yaml)
apiVersion: ceph.rook.io/v1
kind: CephCluster
metadata:
name: rook-ceph
namespace: rook-ceph
spec:
cephVersion:
# 最新得 ceph 镜像, 可以查看 https://hub.docker.com/r/ceph/ceph/tags
image: ceph/ceph:v14.2.5
dataDirHostPath: /var/lib/rook # 主机有效目录
mon:
count: 3
dashboard:
enabled: true
storage:
useAllNodes: true
useAllDevices: false
# 重要: Directories 应该只在预生产环境中使用
directories:
- path: /data/rook
其中有几个比较重要的字段:
- dataDirHostPath:宿主机上的目录,用于每个服务存储配置和数据。如果目录不存在,会自动创建该目录。由于此目录在主机上保留,因此在删除 Pod 后将保留该目录,另外不得使用以下路径及其任何子路径:/etc/ceph、/rook 或 /var/log/ceph。
- useAllNodes:用于表示是否使用集群中的所有节点进行存储,如果在 nodes 字段下指定了各个节点,则必须将useAllNodes设置为 false。
- useAllDevices:表示 OSD 是否自动使用节点上的所有设备,一般设置为 false,这样可控性较高
- directories:一般来说应该使用一块裸盘来做存储,有时为了测试方便,使用一个目录也是可以的,当然生成环境不推荐使用目录。
除了上面这些字段属性之外还有很多其他可以细粒度控制得参数,可以查看集群配置相关文档。
现在直接创建上面的 CephCluster 对象即可:
$ kubectl apply -f cluster.yaml
cephcluster.ceph.rook.io/rook-ceph created
创建完成后,Rook Operator 就会根据我们的描述信息去自动创建 Ceph 集群了。
验证
要验证集群是否处于正常状态,我们可以使用 Rook 工具箱 来运行 ceph status 命令查看。
Rook 工具箱是一个用于调试和测试 Rook 的常用工具容器,该工具基于 CentOS 镜像,所以可以使用 yum 来轻松安装更多的工具包。我们这里用 Deployment 控制器来部署 Rook 工具箱,部署的资源清单文件如下所示:(toolbox.yaml)
apiVersion: apps/v1
kind: Deployment
metadata:
name: rook-ceph-tools
namespace: rook-ceph
labels:
app: rook-ceph-tools
spec:
replicas: 1
selector:
matchLabels:
app: rook-ceph-tools
template:
metadata:
labels:
app: rook-ceph-tools
spec:
dnsPolicy: ClusterFirstWithHostNet
containers:
- name: rook-ceph-tools
image: rook/ceph:v1.2.1
command: ["/tini"]
args: ["-g", "--", "/usr/local/bin/toolbox.sh"]
imagePullPolicy: IfNotPresent
env:
- name: ROOK_ADMIN_SECRET
valueFrom:
secretKeyRef:
name: rook-ceph-mon
key: admin-secret
securityContext:
privileged: true
volumeMounts:
- mountPath: /dev
name: dev
- mountPath: /sys/bus
name: sysbus
- mountPath: /lib/modules
name: libmodules
- name: mon-endpoint-volume
mountPath: /etc/rook
# 如果设置 hostNetwork: false, "rbd map" 命令会被 hang 住, 参考 https://github.com/rook/rook/issues/2021
hostNetwork: true
volumes:
- name: dev
hostPath:
path: /dev
- name: sysbus
hostPath:
path: /sys/bus
- name: libmodules
hostPath:
path: /lib/modules
- name: mon-endpoint-volume
configMap:
name: rook-ceph-mon-endpoints
items:
- key: data
path: mon-endpoints
然后直接创建这个 Pod:
$ kubectl apply -f toolbox.yaml
deployment.apps/rook-ceph-tools created
一旦 toolbox 的 Pod 运行成功后,我们就可以使用下面的命令进入到工具箱内部进行操作:
$ kubectl -n rook-ceph exec -it $(kubectl -n rook-ceph get pod -l "app=rook-ceph-tools" -o jsonpath='{.items[0].metadata.name}') bash
工具箱中的所有可用工具命令均已准备就绪,可满足您的故障排除需求。例如:
ceph status
ceph osd status
ceph df
rados df
比如现在我们要查看集群的状态,需要满足下面的条件才认为是健康的:
- 所有 mons 应该达到法定数量
- mgr 应该是激活状态
- 至少有一个 OSD 处于激活状态
- 如果不是 HEALTH_OK 状态,则应该查看告警或者错误信息
$ ceph status
ceph status
cluster:
id: dae083e6-8487-447b-b6ae-9eb321818439
health: HEALTH_OK
services:
mon: 3 daemons, quorum a,b,c (age 15m)
mgr: a(active, since 2m)
osd: 31 osds: 2 up (since 6m), 2 in (since 6m)
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 79 GiB used, 314 GiB / 393 GiB avail
pgs:
如果群集运行不正常,可以查看 Ceph 常见问题以了解更多详细信息和可能的解决方案。
Dashboard
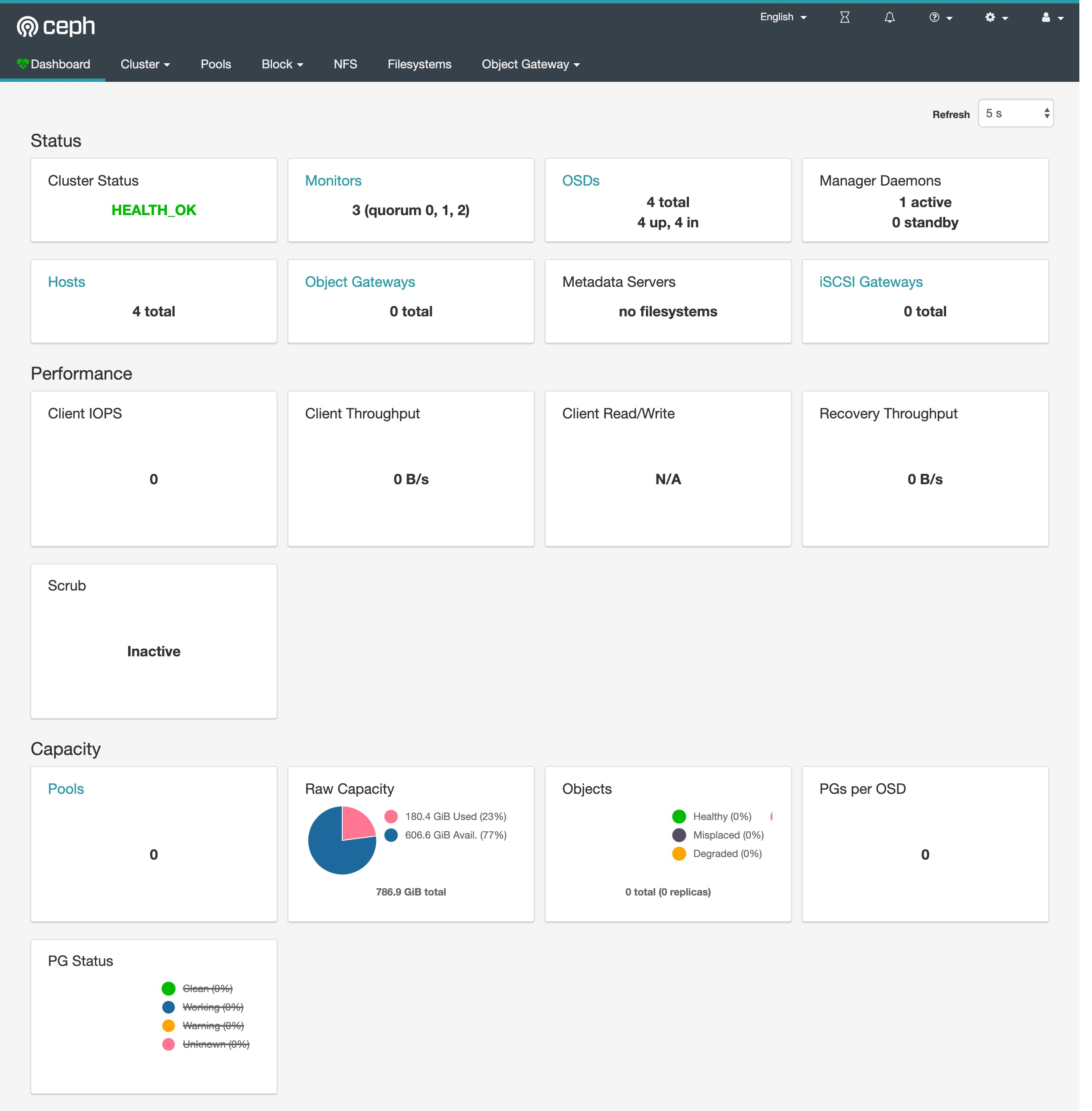
Ceph 有一个 Dashboard 工具,我们可以在上面查看集群的状态,包括总体运行状态,mgr、osd 和其他 Ceph 进程的状态,查看池和 PG 状态,以及显示守护进程的日志等等。
我们可以在上面的 cluster CRD 对象中开启 dashboard,设置dashboard.enable=true即可,这样 Rook Operator 就会启用 ceph-mgr dashboard 模块,并将创建一个 Kubernetes Service 来暴露该服务,将启用端口 7000 进行 https 访问,如果 Ceph 集群部署成功了,我们可以使用下面的命令来查看 Dashboard 的 Service:
$ kubectl get svc -n rook-ceph
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
rook-ceph-mgr ClusterIP 10.99.87.1 <none> 9283/TCP 3m6s
rook-ceph-mgr-dashboard ClusterIP 10.111.195.180 <none> 7000/TCP 3m29s
这里的 rook-ceph-mgr 服务用于报告 Prometheus metrics 指标数据的,而后面的的 rook-ceph-mgr-dashboard 服务就是我们的 Dashboard 服务,如果在集群内部我们可以通过 DNS 名称 http://rook-ceph-mgr-dashboard.rook-ceph:7000或者 CluterIP http://10.111.195.180:7000 来进行访问,但是如果要在集群外部进行访问的话,我们就需要通过 Ingress 或者 NodePort 类型的 Service 来暴露了,为了方便测试我们这里创建一个新的 NodePort 类型的服务来访问 Dashboard,资源清单如下所示:(dashboard-external.yaml)
apiVersion: v1
kind: Service
metadata:
name: rook-ceph-mgr-dashboard-external
namespace: rook-ceph
labels:
app: rook-ceph-mgr
rook_cluster: rook-ceph
spec:
ports:
- name: dashboard
port: 7000
protocol: TCP
targetPort: 7000
selector:
app: rook-ceph-mgr
rook_cluster: rook-ceph
type: NodePort
同样直接创建即可:
$ kubectl apply -f dashboard-external.yaml
创建完成后我们可以查看到新创建的 rook-ceph-mgr-dashboard-external 这个 Service 服务:
$ kubectl get svc -n rook-ceph
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
rook-ceph-mgr ClusterIP 10.96.49.29 <none> 9283/TCP 23m
rook-ceph-mgr-dashboard ClusterIP 10.109.8.98 <none> 7000/TCP 23m
rook-ceph-mgr-dashboard-external NodePort 10.109.53.223 <none> 7000:31361/TCP 14s
现在我们需要通过 http://

但是在访问的时候需要我们登录才能够访问,Rook 创建了一个默认的用户 admin,并在运行 Rook 的命名空间中生成了一个名为 rook-ceph-dashboard-admin-password 的 Secret,要获取密码,可以运行以下命令:
$ kubectl -n rook-ceph get secret rook-ceph-dashboard-password -o jsonpath="{['data']['password']}" | base64 --decode && echo
xxxx(登录密码)
用上面获得的密码和用户名 admin 就可以登录 Dashboard 了,在 Dashboard 上面可以查看到整个集群的状态:
使用
现在我们的 Ceph 集群搭建成功了,我们就可以来使用存储了。首先我们需要创建存储池,可以用 CRD 来定义 Pool。Rook 提供了两种机制来维持 OSD:
- 副本:缺省选项,每个对象都会根据 spec.replicated.size 在多个磁盘上进行复制。建议非生产环境至少 2 个副本,生产环境至少 3 个。
- Erasure Code:是一种较为节约的方式。EC 把数据拆分 n 段(spec.erasureCoded.dataChunks),再加入 k 个代码段(spec.erasureCoded.codingChunks),用分布的方式把 n+k 段数据保存在磁盘上。这种情况下 Ceph 能够隔离 k 个 OSD 的损失。
我们这里使用副本的方式,创建如下所示的 RBD 类型的存储池:(pool.yaml)
apiVersion: ceph.rook.io/v1
kind: CephBlockPool
metadata:
name: k8s-test-pool # operator会监听并创建一个pool,执行完后界面上也能看到对应的pool
namespace: rook-ceph
spec:
failureDomain: host # 数据块的故障域: 值为host时,每个数据块将放置在不同的主机上;值为osd时,每个数据块将放置在不同的osd上
replicated:
size: 3 # 池中数据的副本数,1就是不保存任何副本
直接创建上面的资源对象:
$ kubectl apply -f pool.yaml
cephblockpool.ceph.rook.io/k8s-test-pool created
存储池创建完成后我们在 Dashboard 上面的确可以看到新增了一个 pool,但是会发现集群健康状态变成了 WARN,我们可以查看到有如下日志出现:
Health check update: too few PGs per OSD (6 < min 30) (TOO_FEW_PGS)
这是因为每个 osd 上的 pg 数量小于最小的数目30个。pgs 为8,因为是3副本的配置,所以当有4个 osd 的时候,每个 osd 上均分了8/4 *3=6个pgs,也就是出现了如上的错误小于最小配置30个,集群这种状态如果进行数据的存储和操作,集群会卡死,无法响应io,同时会导致大面积的 osd down。
我们可以进入 toolbox 的容器中查看上面存储的 pg 数量:
$ ceph osd pool get k8s-test-pool pg_num
pg_num: 8
我们可以通过增加 pg_num 来解决这个问题:
$ ceph osd pool set k8s-test-pool pg_num 64
set pool 1 pg_num to 64
$ ceph -s
cluster:
id: 7851387c-5d18-489a-8c04-b699fb9764c0
health: HEALTH_OK
services:
mon: 3 daemons, quorum a,b,c (age 33m)
mgr: a(active, since 32m)
osd: 4 osds: 4 up (since 32m), 4 in (since 32m)
data:
pools: 1 pools, 64 pgs
objects: 0 objects, 0 B
usage: 182 GiB used, 605 GiB / 787 GiB avail
pgs: 64 active+clean
这个时候我们再查看就可以看到现在就是健康状态了。不过需要注意的是我们这里的 pool 上没有数据,所以修改 pg 影响并不大,但是如果是生产环境重新修改 pg 数,会对生产环境产生较大影响。因为 pg 数变了,就会导致整个集群的数据重新均衡和迁移,数据越大响应 io 的时间会越长。所以,最好在一开始就设置好 pg 数。
现在我们来创建一个 StorageClass 来进行动态存储配置,如下所示我们定义一个 Ceph 的块存储的 StorageClass:(storageclass.yaml)
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: rook-ceph-block
provisioner: rook-ceph.rbd.csi.ceph.com
parameters:
# clusterID 是 rook 集群运行的命名空间
clusterID: rook-ceph
# 指定存储池
pool: k8s-test-pool
# RBD image (实际的存储介质) 格式. 默认为 "2".
imageFormat: "2"
# RBD image 特性. CSI RBD 现在只支持 `layering` .
imageFeatures: layering
# Ceph 管理员认证信息,这些都是在 clusterID 命名空间下面自动生成的
csi.storage.k8s.io/provisioner-secret-name: rook-csi-rbd-provisioner
csi.storage.k8s.io/provisioner-secret-namespace: rook-ceph
csi.storage.k8s.io/node-stage-secret-name: rook-csi-rbd-node
csi.storage.k8s.io/node-stage-secret-namespace: rook-ceph
# 指定 volume 的文件系统格式,如果不指定, csi-provisioner 会默认设置为 `ext4`
csi.storage.k8s.io/fstype: ext4
# uncomment the following to use rbd-nbd as mounter on supported nodes
# **IMPORTANT**: If you are using rbd-nbd as the mounter, during upgrade you will be hit a ceph-csi
# issue that causes the mount to be disconnected. You will need to follow special upgrade steps
# to restart your application pods. Therefore, this option is not recommended.
#mounter: rbd-nbd
reclaimPolicy: Delete
直接创建上面的 StorageClass 资源对象:
$ kubectl apply -f storageclass.yaml
storageclass.storage.k8s.io/rook-ceph-block created
$ kubectl get storageclass
NAME PROVISIONER AGE
rook-ceph-block rook-ceph.rbd.csi.ceph.com 35s
然后创建一个 PVC 来使用上面的 StorageClass 对象:(pvc.yaml)
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mysql-pv-claim
labels:
app: wordpress
spec:
storageClassName: rook-ceph-block
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 20Gi
同样直接创建上面的 PVC 资源对象:
$ kubectl apply -f pvc.yaml
persistentvolumeclaim/mysql-pv-claim created
$ kubectl get pvc -l app=wordpress
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
mysql-pv-claim Bound pvc-1eab82e3-d214-4d8e-8fcc-ed379c24e0e3 20Gi RWO rook-ceph-block 32m
创建完成后我们可以看到我们的 PVC 对象已经是 Bound 状态了,自动创建了对应的 PV,然后我们就可以直接使用这个 PVC 对象来做数据持久化操作了。
这个时候可能集群还会出现如下的健康提示:
$ ceph health detail
HEALTH_WARN application not enabled on 1 pool(s)
POOL_APP_NOT_ENABLED application not enabled on 1 pool(s)
application not enabled on pool 'k8s-test-pool'
use 'ceph osd pool application enable <pool-name> <app-name>', where <app-name> is 'cephfs', 'rbd', 'rgw', or freeform for custom applications.
$ ceph osd pool application enable k8s-test-pool k8srbd
enabled application 'k8srbd' on pool 'k8s-test-pool'
根据提示启用一个 application 即可。
在官方仓库 cluster/examples/kubernetes 目录下,官方给了个 wordpress 的例子,可以直接运行测试即可:
$ kubectl apply -f mysql.yaml
$ kubectl apply -f wordpress.yaml
官方的这个示例里面的 wordpress 用的 Loadbalancer 类型,我们可以改成 NodePort:
$ kubectl get pvc -l app=wordpress
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
mysql-pv-claim Bound pvc-1eab82e3-d214-4d8e-8fcc-ed379c24e0e3 20Gi RWO rook-ceph-block 12h
wp-pv-claim Bound pvc-237932ed-5ca7-468c-bd16-220ebb2a1ce3 20Gi RWO rook-ceph-block 25s
$ kubectl get pods -l app=wordpress
NAME READY STATUS RESTARTS AGE
wordpress-5b886cf59b-4xwn8 1/1 Running 0 24m
wordpress-mysql-b9ddd6d4c-qhjd4 1/1 Running 0 24m
$ kubectl get svc -l app=wordpress
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
wordpress NodePort 10.106.253.225 <none> 80:30307/TCP 80s
wordpress-mysql ClusterIP None <none> 3306/TCP 87s
当应用都处于 Running 状态后,我们可以通过 http://<任意节点IP>:30307 去访问 wordpress 应用:

比如我们在第一篇文章中更改下内容,然后我们将应用 Pod 全部删除重建:
$ kubectl delete pod wordpress-mysql-b9ddd6d4c-qhjd4 wordpress-5b886cf59b-4xwn8
pod "wordpress-mysql-b9ddd6d4c-qhjd4" deleted
pod "wordpress-5b886cf59b-4xwn8" deleted
$ kubectl get pods -l app=wordpress
NAME READY STATUS RESTARTS AGE
wordpress-5b886cf59b-kwxk4 1/1 Running 0 2m52s
wordpress-mysql-b9ddd6d4c-kkcr7 1/1 Running 0 2m52s
当 Pod 重建完成后再次访问 wordpress 应用的主页我们可以发现之前我们添加的数据仍然存在,这就证明我们的数据持久化是正确的。
存储原理
Kubernetes 默认情况下就提供了主流的存储卷接入方案,我们可以执行命令 kubectl explain pod.spec.volumes 查看到支持的各种存储卷,另外也提供了插件机制,允许其他类型的存储服务接入到 Kubernetes 系统中来,在 Kubernetes 中就对应 In-Tree 和 Out-Of-Tree 两种方式,In-Tree 就是在 Kubernetes 源码内部实现的,和 Kubernetes 一起发布、管理的,但是更新迭代慢、灵活性比较差,Out-Of-Tree 是独立于 Kubernetes 的,目前主要有 CSI 和 FlexVolume 两种机制,开发者可以根据自己的存储类型实现不同的存储插件接入到 Kubernetes 中去,其中 CSI 是现在也是以后主流的方式,所以当然我们的重点也会是 CSI 的使用介绍。
存储架构
前面我们了解到了 PV、PVC、StorgeClass 的使用,但是他们是如何和我们的 Pod 关联起来使用的呢?这就需要从 Volume 的处理流程和原理说起了。
如下所示,我们创建了一个 nfs 类型的 PV 资源对象:(volume.yaml)
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfs-pv
spec:
storageClassName: manual
capacity:
storage: 1Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
nfs:
path: /data/k8s # 指定nfs的挂载点
server: 10.151.30.11 # 指定nfs服务地址
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: nfs-pvc
spec:
storageClassName: manual
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
我们知道用户真正使用的是 PVC,而要使用 PVC 的前提就是必须要先和某个符合条件的 PV 进行一一绑定,比如存储容器、访问模式,以及 PV 和 PVC 的 storageClassName 字段必须一样,这样才能够进行绑定,当 PVC 和 PV 绑定成功后就可以直接使用这个 PVC 对象了:(pod.yaml)
apiVersion: v1
kind: Pod
metadata:
name: test-volumes
spec:
volumes:
- name: nfs
persistentVolumeClaim:
claimName: nfs-pvc
containers:
- name: web
image: nginx
ports:
- name: web
containerPort: 80
volumeMounts:
- name: nfs
subPath: test-volumes
mountPath: "/usr/share/nginx/html"
直接创建上面的资源对象即可:
$ kubectl apply -f volume.yaml
$ kubectl apply -f pod.yaml
我们只是在 volumes 中指定了我们上面创建的 PVC 对象,当这个 Pod 被创建之后, kubelet 就会把这个 PVC 对应的这个 NFS 类型的 Volume(PV)挂载到这个 Pod 容器中的目录中去。前面我们也提到了这样的话对于普通用户来说完全就不用关心后面的具体存储在 NFS 还是 Ceph 或者其他了,只需要直接使用 PVC 就可以了,因为真正的存储是需要很多相关的专业知识的,这样就完全职责分离解耦了。
普通用户直接使用 PVC 没有问题,但是也会出现一个问题,那就是当普通用户创建一个 PVC 对象的时候,这个时候系统里面并没有合适的 PV 来和它进行绑定,因为 PV 大多数情况下是管理员给我们创建的,这个时候启动 Pod 肯定就会失败了,如果现在管理员如果去创建一个对应的 PV 的话,PVC 和 PV 当然就可以绑定了,然后 Pod 也会自动的启动成功,这是因为在 Kubernetes 中有一个专门处理持久化存储的控制器 Volume Controller,这个控制器下面有很多个控制循环,其中一个就是用于 PV 和 PVC 绑定的 PersistentVolumeController。
PersistentVolumeController 会不断地循环去查看每一个 PVC,是不是已经处于 Bound(已绑定)状态。如果不是,那它就会遍历所有的、可用的 PV,并尝试将其与未绑定的 PVC 进行绑定,这样,Kubernetes 就可以保证用户提交的每一个 PVC,只要有合适的 PV 出现,它就能够很快进入绑定状态。而所谓将一个 PV 与 PVC 进行“绑定”,其实就是将这个 PV 对象的名字,填在了 PVC 对象的 spec.volumeName 字段上。
PV 和 PVC 绑定上了,那么又是如何将容器里面的数据进行持久化的呢,前面我们学习过 Docker 的 Volume 挂载,其实就是将一个宿主机上的目录和一个容器里的目录绑定挂载在了一起,具有持久化功能当然就是指的宿主机上面的这个目录了,当容器被删除或者在其他节点上重建出来以后,这个目录里面的内容依然存在,所以一般情况下实现持久化是需要一个远程存储的,比如 NFS、Ceph 或者云厂商提供的磁盘等等。所以接下来需要做的就是持久化宿主机目录这个过程。
当 Pod 被调度到一个节点上后,节点上的 kubelet 组件就会为这个 Pod 创建它的 Volume 目录,默认情况下 kubelet 为 Volume 创建的目录在 kubelet 工作目录下面:
/var/lib/kubelet/pods/<Pod的ID>/volumes/kubernetes.io~<Volume类型>/<Volume名字>
比如上面我们创建的 Pod 对应的 Volume 目录完整路径为:
/var/lib/kubelet/pods/d4fcdb11-baf7-43d9-8d7d-3ede24118e08/volumes/kubernetes.io~nfs/nfs-pv
提示: 要获取 Pod 的唯一标识 uid,可通过命令 kubectl get pod pod名 -o jsonpath={.metadata.uid} 获取。
然后就需要根据我们的 Volume 类型来决定需要做什么操作了,比如上节课我们用的 Ceph RBD,那么 kubelet 就需要先将 Ceph 提供的 RBD 挂载到 Pod 所在的宿主机上面,这个阶段在 Kubernetes 中被称为 Attach 阶段。Attach 阶段完成后,为了能够使用这个块设备,kubelet 还要进行第二个操作,即:格式化这个块设备,然后将它挂载到宿主机指定的挂载点上。这个挂载点,也就是上面我们提到的 Volume 的宿主机的目录。将块设备格式化并挂载到 Volume 宿主机目录的操作,在 Kubernetes 中被称为 Mount 阶段。上节课我们使用 Ceph RBD 持久化的 Wordpress 的 MySQL 数据,我们可以查看对应的 Volume 信息:
$ kubectl get pods -o wide -l app=wordpress
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
wordpress-5b886cf59b-dv2zt 1/1 Running 0 20d 10.244.1.158 ydzs-node1 <none> <none>
wordpress-mysql-b9ddd6d4c-pjhbt 1/1 Running 0 20d 10.244.4.70 ydzs-node4 <none> <none>
我们可以看到 MySQL 运行在 node4 节点上,然后可以在该节点上查看 Volume 信息,Pod 对应的 uid 可以通过如下命令获取:
$ kubectl get pod wordpress-mysql-b9ddd6d4c-pjhbt -o jsonpath={.metadata.uid}
3f84af87-9f58-4c69-9e38-5ef234498133
$ ls /var/lib/kubelet/pods/3f84af87-9f58-4c69-9e38-5ef234498133/volumes/kubernetes.io~csi/pvc-c8861c23-c03d-47aa-96f6-73c4d4093109/
mount vol_data.json
然后通过如下命令可以查看 Volume 的持久化信息:
$ findmnt /var/lib/kubelet/pods/3f84af87-9f58-4c69-9e38-5ef234498133/volumes/kubernetes.io~csi/pvc-c8861c23-c03d-47aa-96f6-73c4d4093109/mount
TARGET SOURCE FSTYPE OPTIONS
/var/lib/kubelet/pods/3f84af87-9f58-4c69-9e38-5ef234498133/volumes/kubernetes.io~csi/pvc-c8861c23-c03d-47aa-96f6-73c4d4093109/mount /dev/rbd0 ext4 rw,relatime,
可以看到这里的 Volume 是挂载到 /dev/rbd0 这个设备上面的,通过 df 命令也是可以看到的:
$ df -h |grep dev
devtmpfs 3.9G 0 3.9G 0% /dev
tmpfs 3.9G 0 3.9G 0% /dev/shm
/dev/vda3 18G 4.7G 13G 27% /
/dev/vda1 497M 158M 340M 32% /boot
/dev/vdb1 197G 24G 164G 13% /data
/dev/rbd0 20G 160M 20G 1% /var/lib/kubelet/pods/3f84af87-9f58-4c69-9e38-5ef234498133/volumes/kubernetes.io~csi/pvc-c8861c23-c03d-47aa-96f6-73c4d4093109/mount
这里我们就经过了 Attach 和 Mount 两个阶段完成了 Volume 的持久化。但是对于上面我们使用的 NFS 就更加简单了, 因为 NFS 存储并没有一个设备需要挂载到宿主机上面,所以这个时候 kubelet 就会直接进入第二个 Mount 阶段,相当于直接在宿主机上面执行如下的命令:
$ mount -t nfs 10.151.30.11:/data/k8s /var/lib/kubelet/pods/d4fcdb11-baf7-43d9-8d7d-3ede24118e08/volumes/kubernetes.io~nfs/nfs-pv
同样可以在测试的 Pod 所在节点查看 Volume 的挂载信息:
$ findmnt /var/lib/kubelet/pods/d4fcdb11-baf7-43d9-8d7d-3ede24118e08/volumes/kubernetes.io~nfs/nfs-pv
TARGET SOURCE FSTYPE OPTIONS
/var/lib/kubelet/pods/d4fcdb11-baf7-43d9-8d7d-3ede24118e08/volumes/kubernetes.io~nfs/nfs-pv
10.151.30.11:/data/k8s nfs4 rw,relatime,
我们可以看到这个 Volume 被挂载到了 NFS(10.151.30.11:/data/k8s)下面,以后我们在这个目录里写入的所有文件,都会被保存在远程 NFS 服务器上。
这样在经过了上面的两个阶段过后,我们就得到了一个持久化的宿主机上面的 Volume 目录了,接下来 kubelet 只需要把这个 Volume 目录挂载到容器中对应的目录即可,这样就可以为 Pod 里的容器挂载这个持久化的 Volume 了,这一步其实也就相当于执行了如下所示的命令:
$ docker run -v /var/lib/kubelet/pods/<Pod的ID>/volumes/kubernetes.io~<Volume类型>/<Volume名字>:/<容器内的目标目录> 我的镜像 ...
整个存储的架构可以用下图来说明:
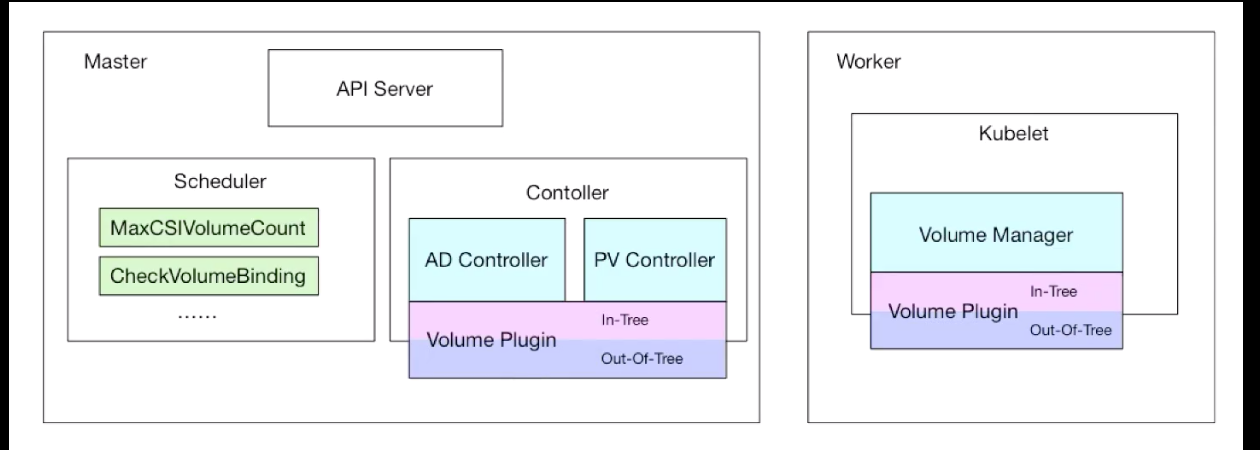
- PV Controller:负责 PV/PVC 的绑定,并根据需求进行数据卷的 Provision/Delete 操作
- AD Controller:负责存储设备的 Attach/Detach 操作,将设备挂载到目标节点
- Volume Manager:管理卷的 Mount/Unmount 操作、卷设备的格式化等操作
- Volume Plugin:扩展各种存储类型的卷管理能力,实现第三方存储的各种操作能力和 Kubernetes 存储系统结合
我们上面使用的 NFS 就属于 In-Tree 这种方式,而上节课使用的 Ceph RBD 就是 Out-Of-Tree 的方式,而且是使用的是 CSI 插件。下面我们再来了解下 FlexVolume 和 CSI 两种插件方式。
FlexVolume
FlexVolume 提供了一种扩展 Kubernetes 存储插件的方式,用户可以自定义自己的存储插件。要使用 FlexVolume 需要在每个节点上安装存储插件二进制文件,该二进制需要实现 FlexVolume 的相关接口,默认存储插件的存放路径为/usr/libexec/kubernetes/kubelet-plugins/volume/exec/<vendor~driver>/
其中 vendor~driver 的名字需要和 Pod 中flexVolume.driver 的字段名字匹配,例如:
/usr/libexec/kubernetes/kubelet-plugins/volume/exec/foo~cifs/cifs
对应的 Pod 中的 flexVolume.driver 属性为:foo/cifs。
在我们实现自定义存储插件的时候,需要实现 FlexVolume 的部分接口,因为要看实际需求,并不一定所有接口都需要实现。比如对于类似于 NFS 这样的存储就没必要实现 attach/detach 这些接口了,因为不需要,只需要实现 init/mount/umount 3个接口即可。
- init:
init - kubelet/kube-controller-manager 初始化存储插件时调用,插件需要返回是否需要要 attach 和 detach 操作 - attach:
attach - 将存储卷挂载到 Node 节点上 - detach:
detach - 将存储卷从 Node 上卸载 - waitforattach:
waitforattach - 等待 attach 操作成功(超时时间为 10 分钟) - isattached:
isattached - 检查存储卷是否已经挂载 - mountdevice:
mountdevice - 将设备挂载到指定目录中以便后续 bind mount 使用 - unmountdevice:
unmountdevice - 将设备取消挂载 - mount:
mount - 将存储卷挂载到指定目录中 - unmount:
unmount - 将存储卷取消挂载
实现上面的这些接口需要返回如下所示的 JSON 格式的数据:
{
"status": "<Success/Failure/Not supported>",
"message": "<Reason for success/failure>",
"device": "<Path to the device attached. This field is valid only for attach & waitforattach call-outs>"
"volumeName": "<Cluster wide unique name of the volume. Valid only for getvolumename call-out>"
"attached": <True/False (Return true if volume is attached on the node. Valid only for isattached call-out)>
"capabilities": <Only included as part of the Init response>
{
"attach": <True/False (Return true if the driver implements attach and detach)>
}
}
比如我们来实现一个 NFS 的 FlexVolume 插件,最简单的方式就是写一个脚本,然后实现 init、mount、unmount 3个命令即可,然后按照上面的 JSON 格式返回数据,最后把这个脚本放在节点的 FlexVolume 插件目录下面即可。
下面就是官方给出的一个 NFS 的 FlexVolume 插件示例,可以从 https://github.com/kubernetes/examples/blob/master/staging/volumes/flexvolume/nfs 获取脚本:
#!/bin/bash
# 注意:
# - 在使用插件之前需要先安装 jq。
usage() {
err "Invalid usage. Usage: "
err "\t$0 init"
err "\t$0 mount <mount dir> <json params>"
err "\t$0 unmount <mount dir>"
exit 1
}
err() {
echo -ne $* 1>&2
}
log() {
echo -ne $* >&1
}
ismounted() {
MOUNT=`findmnt -n ${MNTPATH} 2>/dev/null | cut -d' ' -f1`
if [ "${MOUNT}" == "${MNTPATH}" ]; then
echo "1"
else
echo "0"
fi
}
domount() {
MNTPATH=$1
NFS_SERVER=$(echo $2 | jq -r '.server')
SHARE=$(echo $2 | jq -r '.share')
if [ $(ismounted) -eq 1 ] ; then
log '{"status": "Success"}'
exit 0
fi
mkdir -p ${MNTPATH} &> /dev/null
mount -t nfs ${NFS_SERVER}:/${SHARE} ${MNTPATH} &> /dev/null
if [ $? -ne 0 ]; then
err "{ \"status\": \"Failure\", \"message\": \"Failed to mount ${NFS_SERVER}:${SHARE} at ${MNTPATH}\"}"
exit 1
fi
log '{"status": "Success"}'
exit 0
}
unmount() {
MNTPATH=$1
if [ $(ismounted) -eq 0 ] ; then
log '{"status": "Success"}'
exit 0
fi
umount ${MNTPATH} &> /dev/null
if [ $? -ne 0 ]; then
err "{ \"status\": \"Failed\", \"message\": \"Failed to unmount volume at ${MNTPATH}\"}"
exit 1
fi
log '{"status": "Success"}'
exit 0
}
op=$1
if ! command -v jq >/dev/null 2>&1; then
err "{ \"status\": \"Failure\", \"message\": \"'jq' binary not found. Please install jq package before using this driver\"}"
exit 1
fi
if [ "$op" = "init" ]; then
log '{"status": "Success", "capabilities": {"attach": false}}'
exit 0
fi
if [ $# -lt 2 ]; then
usage
fi
shift
case "$op" in
mount)
domount $*
;;
unmount)
unmount $*
;;
*)
log '{"status": "Not supported"}'
exit 0
esac
exit 1
将上面脚本命名成 nfs,放置到 node1 节点对应的插件下面: /usr/libexec/kubernetes/kubelet-plugins/volume/exec/ydzs~nfs/nfs,并设置权限为 700:
$ chmod 700 /usr/libexec/kubernetes/kubelet-plugins/volume/exec/ydzs~nfs/nfs
# 安装 jq 工具
$ yum -y install https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm
$ yum install jq -y
这个时候我们部署一个应用到 node1 节点上,并用 flexVolume 来持久化容器中的数据(当然也可以通过定义 flexvolume 类型的 PV、PVC 来使用),如下所示:(test-flexvolume.yaml)
apiVersion: v1
kind: Pod
metadata:
name: test-flexvolume
spec:
nodeSelector:
kubernetes.io/hostname: ydzs-node1
volumes:
- name: test
flexVolume:
driver: "ydzs/nfs" # 定义插件类型,根据这个参数在对应的目录下面找到插件的可执行文件
fsType: "nfs" # 定义存储卷文件系统类型
options: # 定义所有与存储相关的一些具体参数
server: "10.151.30.11"
share: "data/k8s"
containers:
- name: web
image: nginx
ports:
- containerPort: 80
volumeMounts:
- name: test
subPath: testflexvolume
mountPath: /usr/share/nginx/html
其中 flexVolume.driver 就是插件目录 ydzs~nfs 对应的 ydzs/nfs 名称,flexVolume.options 中根据上面的 nfs 脚本可以得知里面配置的是 NFS 的 Server 地址和挂载目录路径,直接创建上面的资源对象:
$ kubectl apply -f test-flexvolume.yaml
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
test-flexvolume 1/1 Running 0 13h
......
$ kubectl exec -it test-flexvolume mount |grep test
10.151.30.11:/data/k8s/testflexvolume on /usr/share/nginx/html type nfs4 (rw,relatime,vers=4.1,rsize=524288,wsize=524288,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.151.30.22,local_lock=none,addr=10.151.30.11)
$ mount |grep test
10.151.30.11:/data/k8s on /var/lib/kubelet/pods/a376832a-7638-4faf-b1a0-404956e8e60a/volumes/ydzs~nfs/test type nfs4 (rw,relatime,vers=4.1,rsize=524288,wsize=524288,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.151.30.22,local_lock=none,addr=10.151.30.11)
10.151.30.11:/data/k8s/testflexvolume on /var/lib/kubelet/pods/a376832a-7638-4faf-b1a0-404956e8e60a/volume-subpaths/test/web/0 type nfs4 (rw,relatime,vers=4.1,rsize=524288,wsize=524288,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.151.30.22,local_lock=none,addr=10.151.30.11)
同样我们可以查看到 Pod 的本地持久化目录是被 mount 到了 NFS 上面,证明上面我们的 FlexVolume 插件是正常的。
调用: 当我们要去真正的 mount NFS 的时候,就是通过 kubelet 调用 VolumePlugin,然后直接执行命令/usr/libexec/kubernetes/kubelet-plugins/volume/exec/ydzs~nfs/nfs mount
来完成的,就相当于平时我们在宿主机上面手动挂载 NFS 的方式一样的,所以存储插件 nfs 是一个可执行的二进制文件或者 shell 脚本都是可以的。
CSI
既然已经有了 FlexVolume 插件了,为什么还需要 CSI 插件呢?上面我们使用 FlexVolume 插件的时候可以看出 FlexVolume 插件实际上相当于就是一个普通的 shell 命令,类似于平时我们在 Linux 下面执行的 ls 命令一样,只是返回的信息是 JSON 格式的数据,并不是我们通常认为的一个常驻内存的进程,而 CSI 是一个更加完善、编码更加方便友好的一种存储插件扩展方式。
CSI 是由来自 Kubernetes、Mesos、 Cloud Foundry 等社区成员联合制定的一个行业标准接口规范,旨在将任意存储系统暴露给容器化应用程序。CSI 规范定义了存储提供商实现 CSI 兼容插件的最小操作集合和部署建议,CSI 规范的主要焦点是声明插件必须实现的接口。
在 Kubernetes 上整合 CSI 插件的整体架构如下图所示:
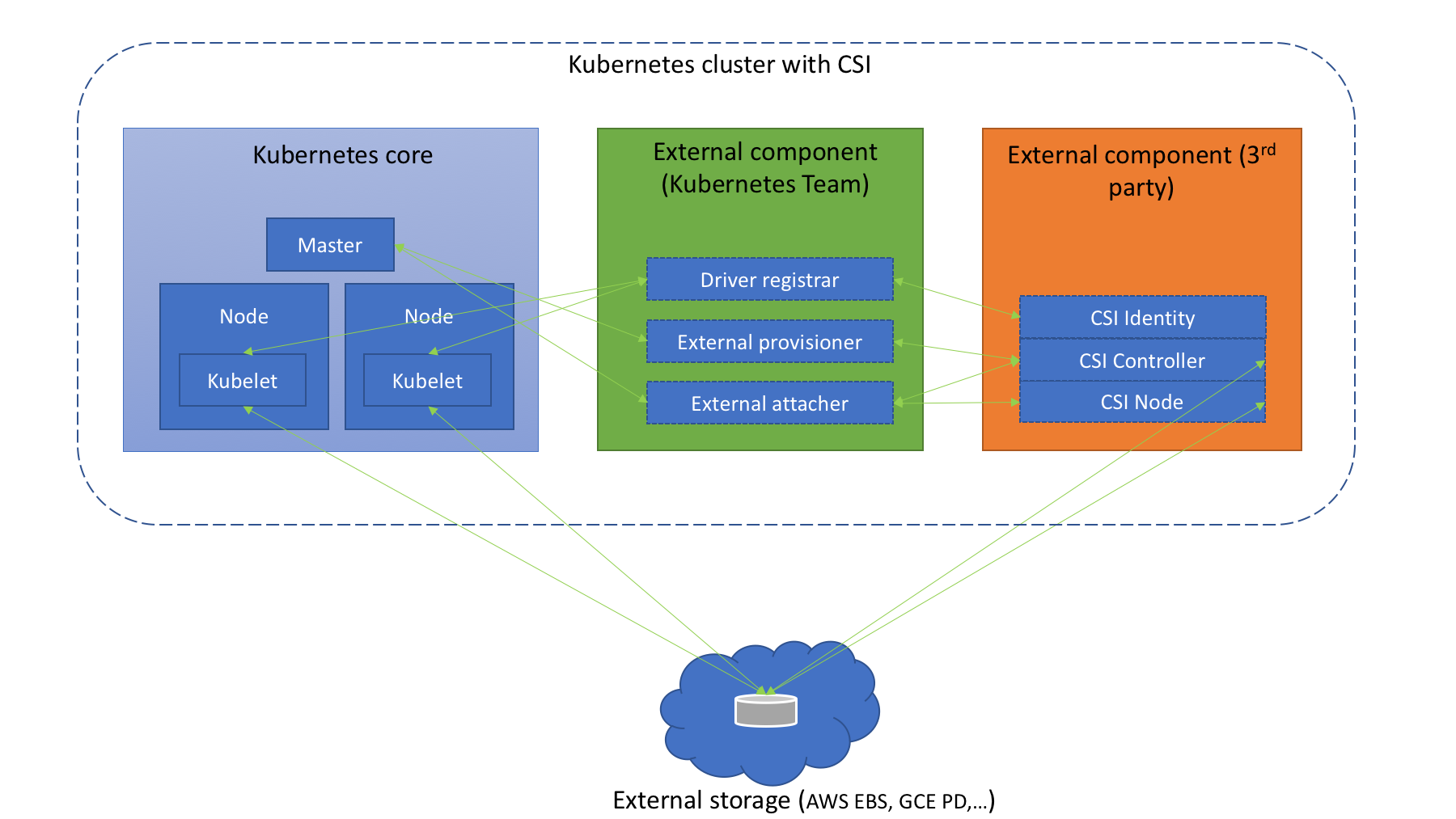
Kubernetes CSI 存储体系主要由两部分组成:
-
Kubernetes 外部组件:包含 Driver registrar、External provisioner、External attacher 三部分,这三个组件是从 Kubernetes 原本的 in-tree 存储体系中剥离出来的存储管理功能,实际上是 Kubernetes 中的一种外部 controller ,它们 watch kubernetes 的 API 资源对象,根据 watch 到的状态来调用下面提到的第二部分的 CSI 插件来实现存储的管理和操作。这部分是 Kubernetes 团队维护的,插件开发者完全不必关心其实现细节。
-
Driver registra:用于将插件注册到 kubelet 的 sidecar 容器,并将驱动程序自定义的 NodeId 添加到节点的 Annotations 上,通过与 CSI 上面的 Identity 服务进行通信调用 CSI 的 GetNodeId 方法来完成该操作。
-
External provisioner:用于 watch Kubernetes 的 PVC 对象并调用 CSI 的 CreateVolume 和 DeleteVolume 操作。
-
External attacher:用于 Attach/Detach 阶段,通过 watch Kubernetes 的 VolumeAttachment 对象并调用 CSI 的 ControllerPublish 和 ControllerUnpublish 操作来完成对应的 Volume 的 Attach/Detach。而 Volume 的 Mount/Unmount 阶段并不属于外部组件,当真正需要执行 Mount 操作的时候,kubelet 会去直接调用下面的 CSI Node 服务来完成 Volume 的 Mount/UnMount 操作。
-
CSI 存储插件: 这部分正是开发者需要实现的 CSI 插件部分,都是通过 gRPC 实现的服务,一般会用一个二进制文件对外提供服务,主要包含三部分:CSI Identity、CSI Controller、CSI Node。
- CSI Identity — 主要用于负责对外暴露这个插件本身的信息,确保插件的健康状态。
service Identity {
// 返回插件的名称和版本
rpc GetPluginInfo(GetPluginInfoRequest)
returns (GetPluginInfoResponse) {}
// 返回这个插件的包含的功能,比如非块存储类型的 CSI 插件不需要实现 Attach 功能,GetPluginCapabilities 就可以在返回中标注这个 CSI 插件不包含 Attach 功能
rpc GetPluginCapabilities(GetPluginCapabilitiesRequest)
returns (GetPluginCapabilitiesResponse) {}
// 插件插件是否正在运行
rpc Probe (ProbeRequest)
returns (ProbeResponse) {}
}
- CSI Controller - 主要实现 Volume 管理流程当中的 Provision 和 Attach 阶段,Provision 阶段是指创建和删除 Volume 的流程,而 Attach 阶段是指把存储卷附着在某个节点或脱离某个节点的流程,另外只有块存储类型的 CSI 插件才需要 Attach 功能。
service Controller {
// 创建存储卷,包括云端存储介质以及PV对象
rpc CreateVolume (CreateVolumeRequest)
returns (CreateVolumeResponse) {}
// 删除存储卷
rpc DeleteVolume (DeleteVolumeRequest)
returns (DeleteVolumeResponse) {}
// 挂载存储卷,将存储介质挂载到目标节点
rpc ControllerPublishVolume (ControllerPublishVolumeRequest)
returns (ControllerPublishVolumeResponse) {}
// 卸载存储卷
rpc ControllerUnpublishVolume (ControllerUnpublishVolumeRequest)
returns (ControllerUnpublishVolumeResponse) {}
// 例如:是否可以同时用于多个节点的读/写
rpc ValidateVolumeCapabilities (ValidateVolumeCapabilitiesRequest)
returns (ValidateVolumeCapabilitiesResponse) {}
// 返回所有可用的 volumes
rpc ListVolumes (ListVolumesRequest)
returns (ListVolumesResponse) {}
// 可用存储池的总容量
rpc GetCapacity (GetCapacityRequest)
returns (GetCapacityResponse) {}
// 例如. 插件可能未实现 GetCapacity、Snapshotting
rpc ControllerGetCapabilities (ControllerGetCapabilitiesRequest)
returns (ControllerGetCapabilitiesResponse) {}
// 创建快照
rpc CreateSnapshot (CreateSnapshotRequest)
returns (CreateSnapshotResponse) {}
// 删除指定的快照
rpc DeleteSnapshot (DeleteSnapshotRequest)
returns (DeleteSnapshotResponse) {}
// 获取所有的快照
rpc ListSnapshots (ListSnapshotsRequest)
returns (ListSnapshotsResponse) {}
}
- CSI Node — 负责控制 Kubernetes 节点上的 Volume 操作。其中 Volume 的挂载被分成了 NodeStageVolume 和 NodePublishVolume 两个阶段。NodeStageVolume 接口主要是针对块存储类型的 CSI 插件而提供的,块设备在 "Attach" 阶段被附着在 Node 上后,需要挂载至 Pod 对应目录上,但因为块设备在 linux 上只能 mount 一次,而在 kubernetes volume 的使用场景中,一个 volume 可能被挂载进同一个 Node 上的多个 Pod 实例中,所以这里提供了 NodeStageVolume 这个接口,使用这个接口把块设备格式化后先挂载至 Node 上的一个临时全局目录,然后再调用 NodePublishVolume 使用 linux 中的 bind mount 技术把这个全局目录挂载进 Pod 中对应的目录上。
service Node {
// 在节点上初始化存储卷(格式化),并执行挂载到Global目录
rpc NodeStageVolume (NodeStageVolumeRequest)
returns (NodeStageVolumeResponse) {}
// umount 存储卷在节点上的 Global 目录
rpc NodeUnstageVolume (NodeUnstageVolumeRequest)
returns (NodeUnstageVolumeResponse) {}
// 在节点上将存储卷的 Global 目录挂载到 Pod 的实际挂载目录
rpc NodePublishVolume (NodePublishVolumeRequest)
returns (NodePublishVolumeResponse) {}
// unmount 存储卷在节点上的 Pod 挂载目录
rpc NodeUnpublishVolume (NodeUnpublishVolumeRequest)
returns (NodeUnpublishVolumeResponse) {}
// 获取节点上Volume挂载文件系统统计信息(总空间、可用空间等)
rpc NodeGetVolumeStats (NodeGetVolumeStatsRequest)
returns (NodeGetVolumeStatsResponse) {}
// 获取节点的唯一 ID
rpc NodeGetId (NodeGetIdRequest)
returns (NodeGetIdResponse) {
option deprecated = true;
}
// 返回节点插件的能力
rpc NodeGetCapabilities (NodeGetCapabilitiesRequest)
returns (NodeGetCapabilitiesResponse) {}
// 获取节点的一些信息
rpc NodeGetInfo (NodeGetInfoRequest)
returns (NodeGetInfoResponse) {}
}
只需要实现上面的接口就可以实现一个 CSI 插件了。虽然 Kubernetes 并未规定 CSI 插件的打包安装,但是提供了以下建议来简化我们在 Kubernetes 上容器化 CSI Volume 驱动程序的部署方案,具体的方案介绍可以查看 CSI 规范介绍文档 https://github.com/kubernetes/community
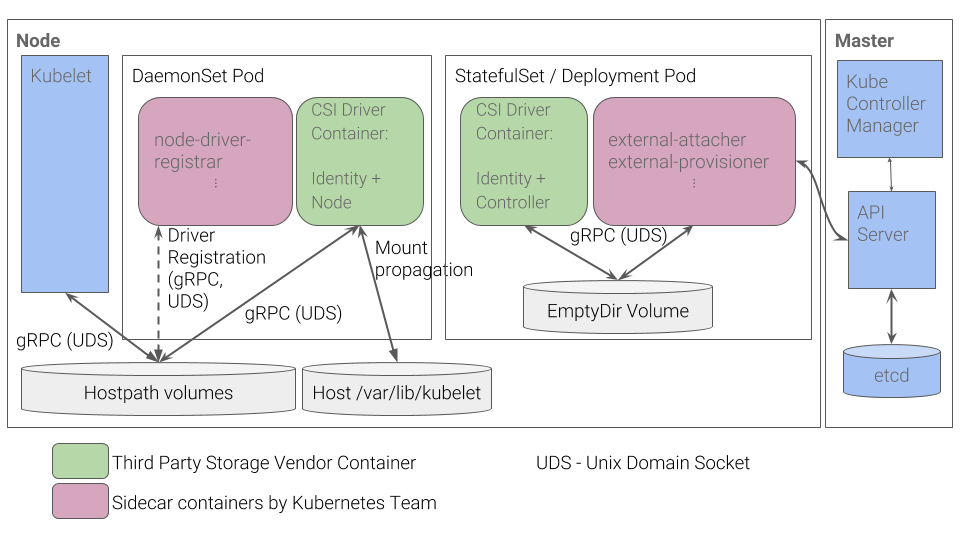
按照上图的推荐方案,CSI Controller 部分以 StatefulSet 或者 Deployment 方式部署,CSI Node 部分以 DaemonSet 方式部署。因为这两部分实现在同一个 CSI 插件程序中,因此只需要把这个 CSI 插件与 External Components 以容器方式部署在同一个 Pod中,把这个 CSI 插件与 Driver registrar 以容器方式部署在 DaemonSet 的 Pod 中,即可完成 CSI 的部署。
前面我们使用的 Rook 部署的 Ceph 集群就是实现了 CSI 插件的:
$ kubectl get pods -n rook-ceph |grep plugin
csi-cephfsplugin-2s9d5 3/3 Running 0 21d
csi-cephfsplugin-fgp4v 3/3 Running 0 17d
csi-cephfsplugin-fv5nx 3/3 Running 0 21d
csi-cephfsplugin-mn8q4 3/3 Running 0 17d
csi-cephfsplugin-nf6h8 3/3 Running 0 21d
csi-cephfsplugin-provisioner-56c8b7ddf4-68h6d 4/4 Running 0 21d
csi-cephfsplugin-provisioner-56c8b7ddf4-rq4t6 4/4 Running 0 21d
csi-cephfsplugin-xwnl4 3/3 Running 0 21d
csi-rbdplugin-7r88w 3/3 Running 0 21d
csi-rbdplugin-95g5j 3/3 Running 0 21d
csi-rbdplugin-bnzpr 3/3 Running 0 21d
csi-rbdplugin-dvftb 3/3 Running 0 21d
csi-rbdplugin-jzmj2 3/3 Running 0 17d
csi-rbdplugin-provisioner-6ff4dd4b94-bvtss 5/5 Running 0 21d
csi-rbdplugin-provisioner-6ff4dd4b94-lfn68 5/5 Running 0 21d
csi-rbdplugin-trxb4 3/3 Running 0 17d
这里其实是实现了 RBD 和 CephFS 两种 CSI,用 DaemonSet 在每个节点上运行了一个包含 Driver registra 容器的 Pod,当然和节点相关的操作比如 Mount/Unmount 也是在这个 Pod 里面执行的,其他的比如 Provision、Attach 都是在另外的 csi-rbdplugin-provisioner-xxx Pod 中执行的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号