

Elasticsearch中text与keyword的区别
text类型
1:支持分词,全文检索,支持模糊、精确查询,不支持聚合,排序操作;
2:test类型的最大支持的字符长度无限制,适合大字段存储;
使用场景:
存储全文搜索数据, 例如: 邮箱内容、地址、代码块、博客文章内容等。
默认结合standard analyzer(标准解析器)对文本进行分词、倒排索引。
默认结合标准分析器进行词命中、词频相关度打分。
keyword
1:不进行分词,直接索引,支持模糊、支持精确匹配,支持聚合、排序操作。
2:keyword类型的最大支持的长度为——32766个UTF-8类型的字符,可以通过设置ignore_above指定自持字符长度,超过给定长度后的数据将不被索引,无法通过term精确匹配检索返回结果。
使用场景:
存储邮箱号码、url、name、title,手机号码、主机名、状态码、邮政编码、标签、年龄、性别等数据。
用于筛选数据(例如: select * from x where status='open')、排序、聚合(统计)。
直接将完整的文本保存到倒排索引中。
Dynamic
dynamic属性:默认值为true,允许动态地向文档类型中加入新的字段。推荐设置为false,禁止向文档中添加字段,这样,文档类型的所有字段必须在索引映射的properties属性中显式定义,在properties字段中未定义的字段都将会ElasticSearch忽略。
dynamic设置为ture:默认值,新增加的字段被添加到索引映射中;
dynamic设置为false:新增加的字段会被忽略;
dynamic设置为strict:当向文档中新增字段时,ElasticSearch引擎抛出异常;
# index
index定义字段的分析类型以及检索方式,控制字段值是否被索引.他可以设置成 true 或者 false。没有被索引的字段将无法搜索
如果是no,则无法通过检索查询到该字段;
如果设置为not_analyzed则会将整个字段存储为关键词,常用于汉字短语、邮箱等复杂的字符串;
如果设置为analyzed则将会通过默认的standard分析器进行分析
# 集群分片
Elasticsearch 有一个硬编码限制,单个分片内的文档总数不得超过 2147483519 个。
一般来说这个限制在日志场景下是不太会触发的,但是如果做 TSDB 用,则需要多加注意!
ES更新到5版本后,取消了 string 数据类型,代替它的是 keyword 和 text 数据类型.那么 text 和keyword有什么区别呢?
# 添加数据
使用bulk往es数据库中批量添加一些document
POST /book/novel/_bulk
{"index": {"_id": 1}}
{"name": "Gone with the Wind", "author": "Margaret Mitchell", "date": "2018-01-01"}
{"index": {"_id": 2}}
{"name": "Robinson Crusoe", "author": "Daniel Defoe", "date": "2018-01-02"}
{"index": {"_id": 3}}
{"name": "Pride and Prejudice", "author": "Jane Austen", "date": "2018-01-01"}
{"index": {"_id": 4}}
# 查看mapping
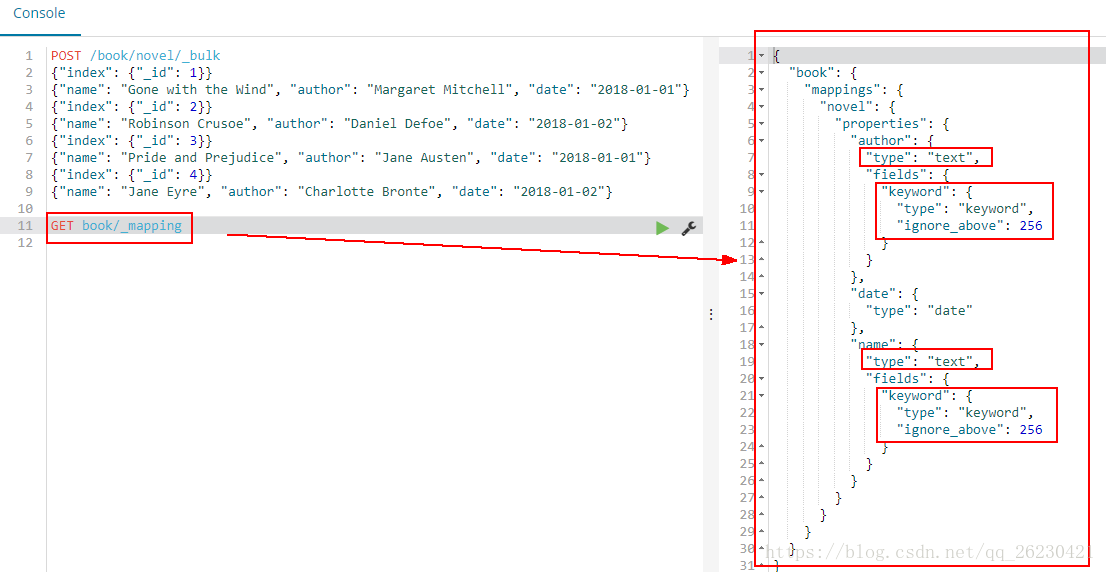
发现name、author的type是text,
还有个field是keyword,keyword的type是keyword:
# 查询
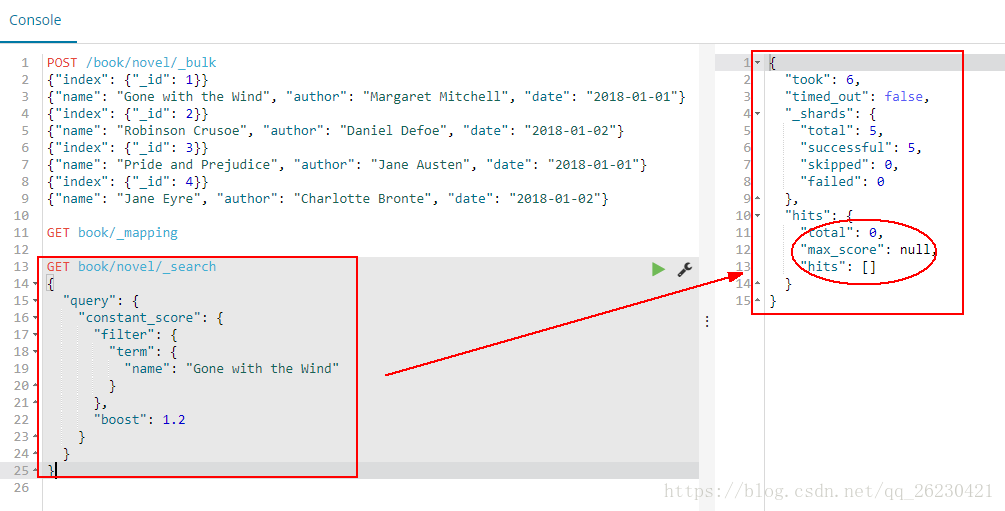
使用term查询某个小说:
GET book/novel/_search
{
"query": {
"constant_score": {
"filter": {
"term": {
"name": "Gone with the Wind"
}
},
"boost": 1.2
}
}
}
结果是什么也没有查到:
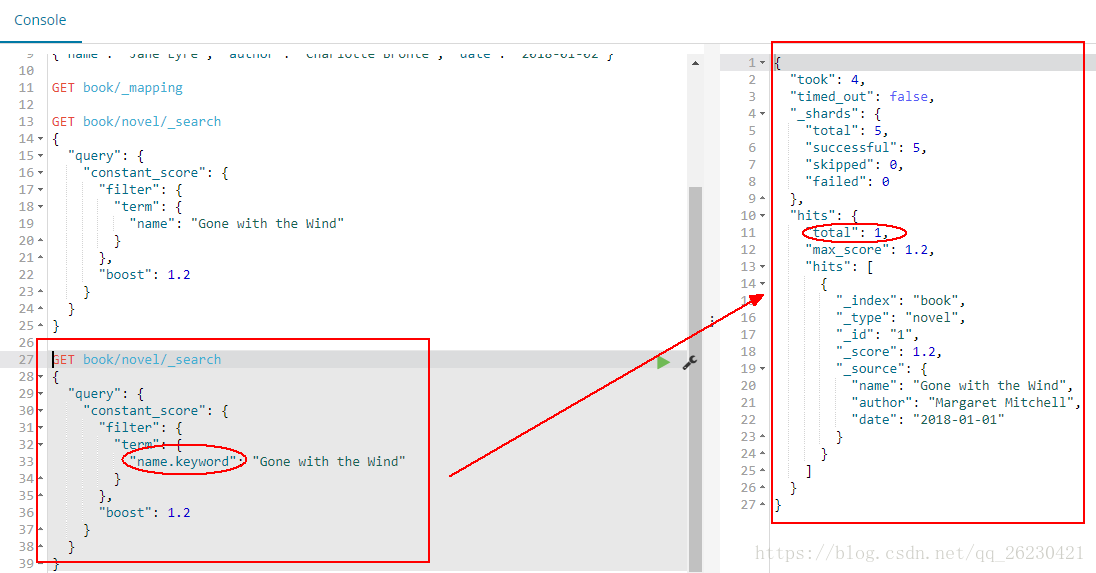
然后使用name的keyword查询:
GET book/novel/_search
{
"query": {
"constant_score": {
"filter": {
"term": {
"name.keyword": "Gone with the Wind"
}
},
"boost": 1.2
}
}
}
可以查询到一条数据:
# 实验
使用name不能查到,而使用name.keyword可以查到,我们可以通过下面的实验来判断:
使用name进行分词的时候,结果会有4个词出来:
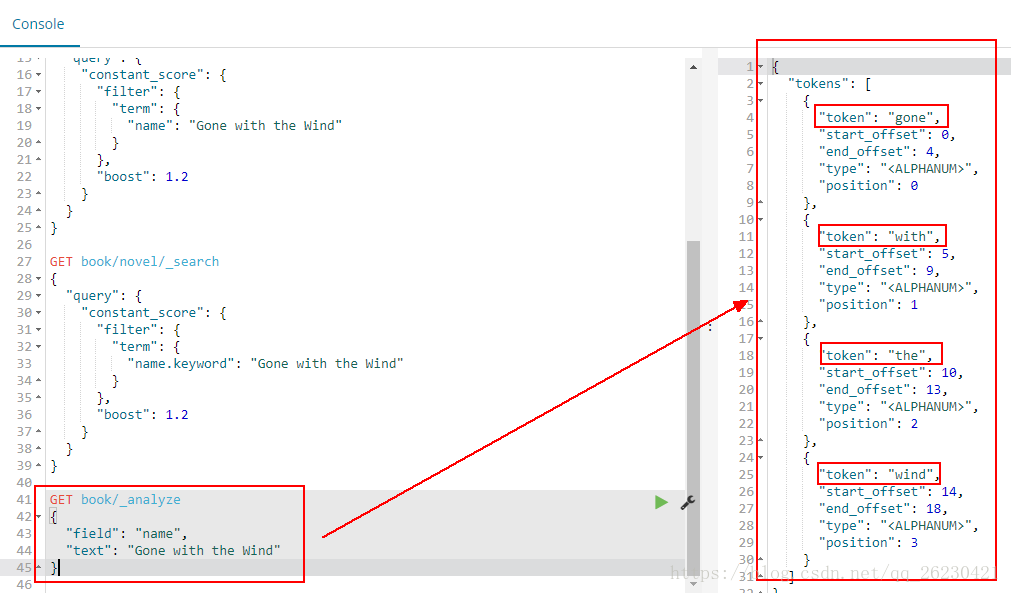
使用name.keyword进行分词的时候,结果只有一个词出来:
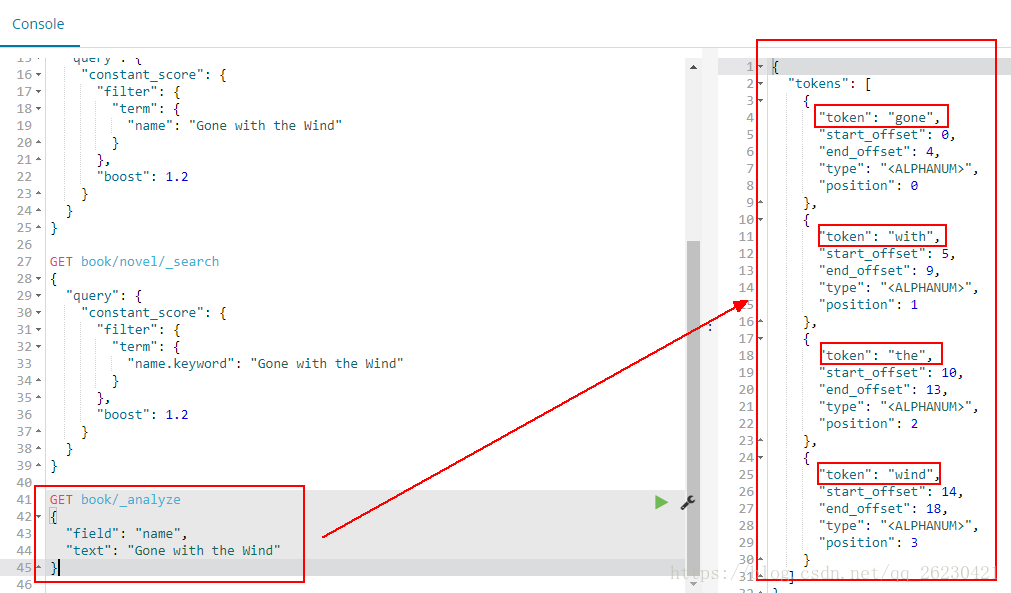
# 结论
text类型:会分词,先把对象进行分词处理,然后再再存入到es中。
当使用多个单词进行查询的时候,当然查不到已经分词过的内容!
keyword:不分词,没有把es中的对象进行分词处理,而是存入了整个对象!
这时候当然可以进行完整地查询!默认是256个字符!
作者:香山上的麻雀
链接:https://www.jianshu.com/p/1189ff372c38
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
 浙公网安备 33010602011771号
浙公网安备 33010602011771号