

value_count().sort_index()
数据集:
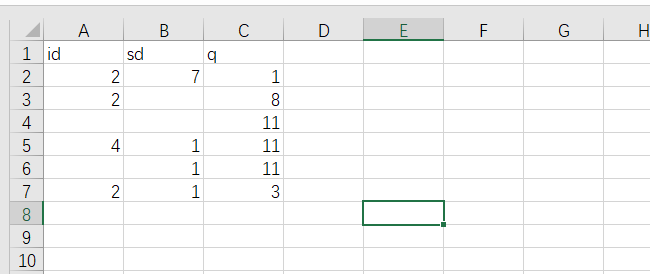
train=pd.read_csv('./1.csv')//读取内容
print(train['q'].value_counts(dropna=False))//dropna参数代表是否要舍弃Nan,False表示不舍弃
输出值:
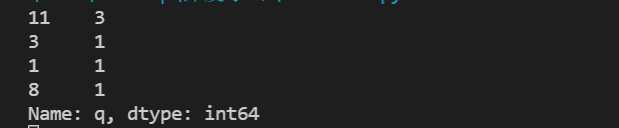
输出时将该列相同值出现的次数进行统计,按出现的次数由高到低进行排列。
这样做的缺点是不太美观
print(train['q'].value_counts(dropna=False).sort_index())
输出:(函数名为排列名)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号