

处理数据中的缺失值
数据集:
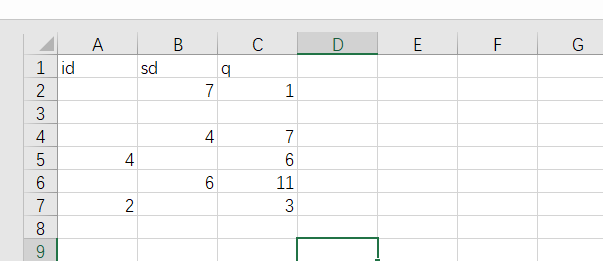
train=pd.read_csv('./1.csv')//用代码读取数据
print(train)//并对其输出
输出结果:
id sd q
0 NaN 7.0 1.0
1 NaN NaN NaN
2 NaN 4.0 7.0
3 4.0 NaN 6.0
4 NaN 6.0 11.0
5 2.0 NaN 3.0
补充缺失值的几种方法。
1、将所有缺失值补为0。
2、用缺失值上面的值,对其进行补充。
3、用缺失值下面的值,对其进行补充。
4、用该列的中位数填充缺失值。
5、用该列的众数填充缺失值。
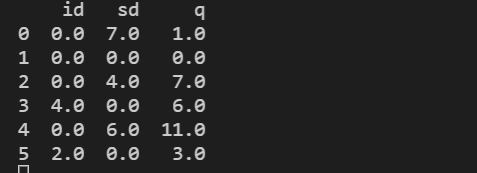
1:
用0补充缺失值用fillna(0)

fillna的返回值是被填充好的框架。
代码:
train=pd.read_csv('./1.csv')
train=train.fillna(0)
print(train)
输出结果:
2:
用缺失值上面的值对其进行代替用函数
data = data.fillna(axis=0,method='ffill')
print(data)
输出结果:
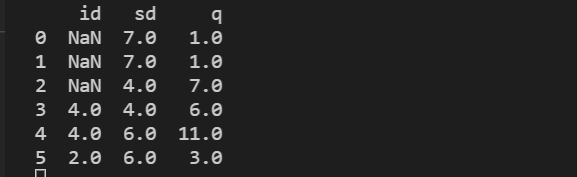
得出结论边界为Nan时,采用上边界值补全缺失值不会报错,但不会处理上边界的缺失值。
method参数:

ffill参数其翻译过来就是取前一个数对缺失值进行填充。
axis表示取填充值的方向0为竖轴方向,1为横向。

如果加上limit代表能连续填充多少个值:
比如
1
Nan
Nan
Nan
如果limit=2
就会变为
1
1
1
Nan
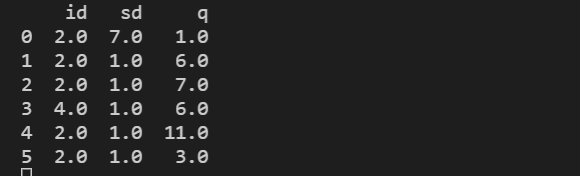
4.中位数填充缺失值
4.1选出连续的值。
通过选出列属性为非object的值在调用columns函数即可得出列名。
代码:
column=train.select_dtypes(exclude=['object']).columns
print(column)
输出:
Index(['id', 'sd', 'q'], dtype='object')
之后在指定列调用fillna函数,填写该列空缺值用该列的中位数。
for i in column:
train[i]=train[i].fillna(train[i].median())
print(train)
输出值:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号