批量AI提取图片,PDF的文字到Excel(身份证,合同发票信息等),数据安全,支持断网使用
前言
大家好,这里是“鲸闲办公”,最近公司有一个变态的需求,有一堆身份证图片,然后将每个身份证信息放到excel表格里面。单个文本是很容易操作的,但多个文件就相当耗费人力,今天老罗就是帮大家来解决这个问题的。
功能使用的是本地千问大模型,支持断网使用,联网时,支持使用DeepSeek,智谱等大模型。
视频演示
https://githubs.xyz/show/fish/excel_ai_idcard.mp4
需求描述
要提取的身份证图片,打开内容如下:


需要将信息放到excel表格里面 , 结果如下图:

如果只有一个图片,我想人工操作还是很简单的,但是我有一批图片都需要录入。
如果你想早点下班,抛开这些重复的繁琐步骤,节省更多时间充实自己,就请往下看。
解决方案
关注公众号:”老罗软件“ , 可以获取到解决方案软件下载。
这是一个专业解决excel多文件处理的方案, 主界面上找到 Excel AI批处理
打开后, 我们找到“文件AI提取” 这个智能体

软件,默认是DeepSeek模型,需要在右上角设置模型的密钥。
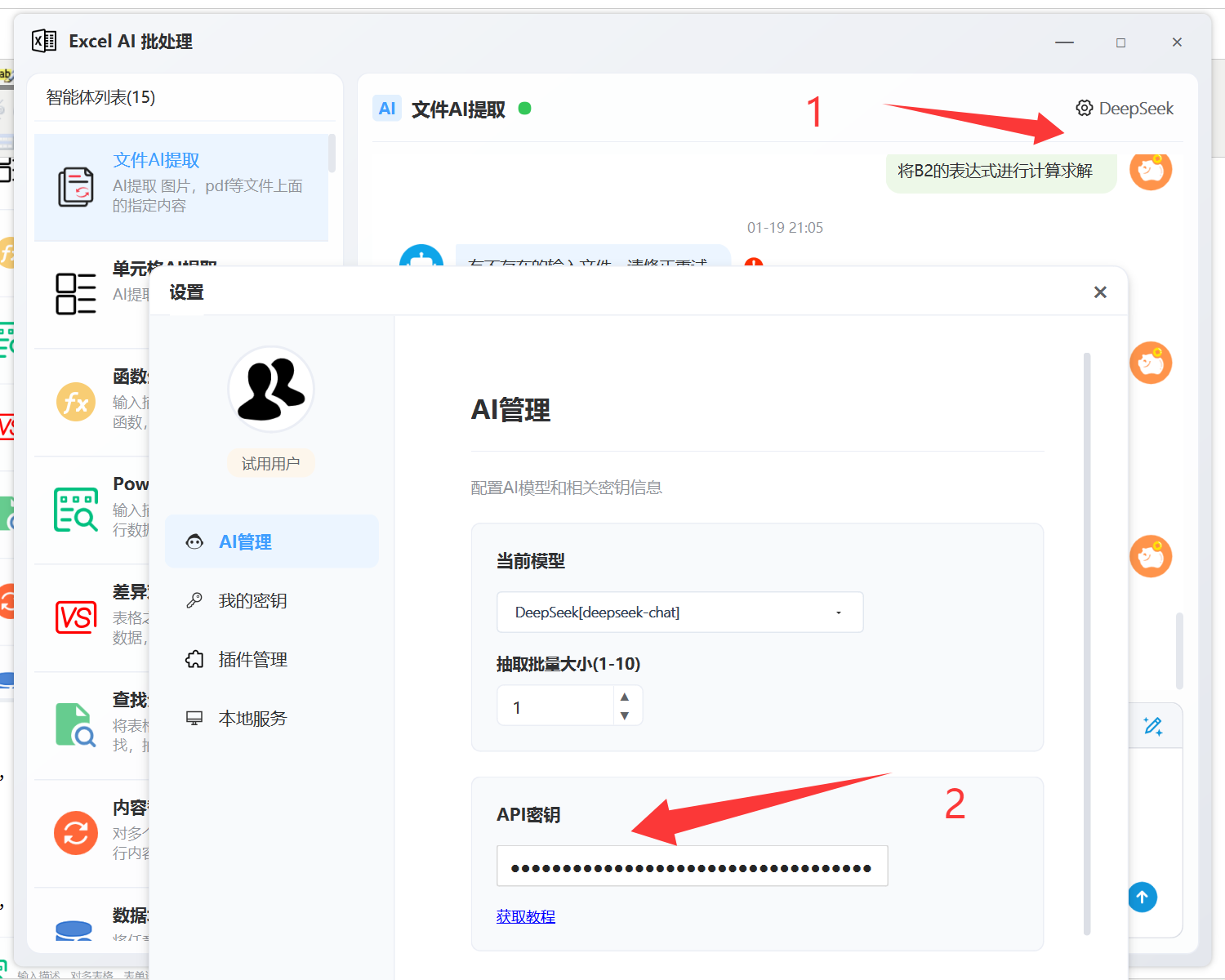
如果你想用本地模型, 断网使用的话, 就设置本地模型, 但是本地模型需要下载“模型支持文件”。模型设置好之后,我们继续。
首先,我们点击文件,输入你要处理的图片。

然后发送消息给智能体,就可以了。等待处理结束。
如果您有疑问可以一起来探讨,功能就介绍到 这里 ,希望能帮助大家,感谢!!!
技术实现
非技术人员不需要观看!! 这里设计到的技术复杂, 我也就就简单讲解实现原理。
软件是基于Python开发的现代化办公自动化软件,主要使用了如下技术架构:
1. PySide6 (Qt6) - 现代化GUI界面框架:
2. springboot: excel的数据脱敏是通过后端java实现的。
3. 文件处理:os.walk() - 递归遍历目录结构。
4. http请求: requests框架。
部分代码解析
项目的 开始 按钮,会开启一个QThread线程去处理,首先是获取excel目录, 然后通过os.walk遍历目录获取到所有文件,然后一个一个进行处理,处理的业务代码如下:
import logging import os import openpyxl from openpyxl.utils import get_column_letter, column_index_from_string from api.news.excel_api_new import ExcelAPINews from utils import FileUtils from utils.ai_ask_installer import AiAskInstaller from utils.ai_configure import AiConfigure from utils.paddle_installer import PaddleInstaller class AIExtractFilesService: """Excel AI分析提取服务""" def __init__(self): self.api = ExcelAPINews() def delete_temp_file(self, files): if files: for file in files: FileUtils.remove_file(file) def ocr_to_temp_file(self, input_file, out_dir, pdfContinesOCR): ## 临时文件 out_put = os.path.join(out_dir, FileUtils.get_filename_without_extension(input_file) + ".txt") self.api.fileTextOCR(input_file, out_put, { "cmd": PaddleInstaller.GS_CMD, "inputRange": "empty", "pdfContinesOCR": pdfContinesOCR }) return out_put def merge_files(self , files , output): self.api.mergeExcelsToOneSheet(output, output, { "excels": files }) def process_excel_file(self, input_file, output_file, model_name, output_config, prompt, scence, sk, ocr_file, max_tokens=200): """ 处理Excel文件 :param input_file: 输入文件路径 :param output_file: 输出文件路径 :param input_range: 输入范围(如 A1:C10) :param output_column: 输出列(如 A) :param model_name: 模型名称 :param output_config: 输出配置列表 [{"title": "姓名", "format": "TEXT"}, ...] """ print(f"Input file: {input_file}") print(f"Output file: {output_file}") ## [{'title': '姓名', 'format': 'TEXT'}, {'title': '身份证号', 'format': 'TEXT'}, {'title': '出生日期', 'format': 'DATE_SHORT'}] print(f"Output config: {output_config}") print(f"Prompt: {prompt}") print(f"Scence: {scence}") if '本地' in model_name: model_name_str = 'local' else: model_name_str = model_name # 构建输出配置参数 output_columns = [] if output_config and len(output_config) > 0: for item in output_config: output_columns.append({ "titleName": item.get('title', ''), "formatEnum": item.get('format', 'TEXT') }) params = { "inputRange": "empty", "outputColumn": "empty", "ask": { "model": model_name_str, "scene": scence, "cmd": AiAskInstaller.GS_CMD, "custom_prompt": prompt, "sk": sk, "maxTokens": AiConfigure.get_max_tokens() }, "titleCellInfos": output_columns, "ocrFile": ocr_file } self.api.aiAskFile(input_file, output_file, params)
代码没有开源噢。如果您有技术合作意向,还请联系本人。今天就介绍到 这里 ,希望能帮助大家,感谢!!!
结尾语
单个图片直接用肉眼看然后用wps这些有名的工具就可以了, 但是针对多文件批量一键处理还可以尝试我文章中的介绍方法,可以为你提高很大的工作效率,让你有时间充实自己,而不是像机器人一样做重复的工作,没有任何新的收获。 就说到这里了, 如帮助到你了,还请点个赞,感谢!!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号