Distributed Runtime
上级:https://www.cnblogs.com/hackerxiaoyon/p/12747387.html
Tasks and Operator Chains
任务和操作链
对于分布式执行器,flink将操作子任务一起放到任务中。每一个任务被一个线程执行。将操作符链接到任务中是一种有用的优化:这种方式减少了线程与线程之间的切换和缓冲开销,增加了整体的吞吐量,同时也减少了延迟。这中方式我们可以在代码中使用。https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/stream/operators/#task-chaining-and-resource-groups
如下图所示:source map 操作我们可以合并一个chain,keyby,window,apply合并一个,sink是一个。那么每一个就是一个线程,两个多个操作在一个线程内操作就体现了优化的性能。
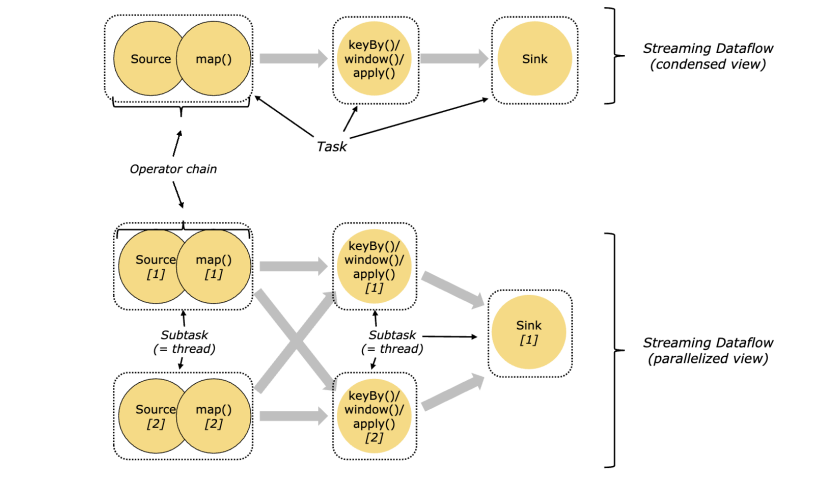
Job Managers, Task Managers, Clients
工作管理,任务管理和客户端
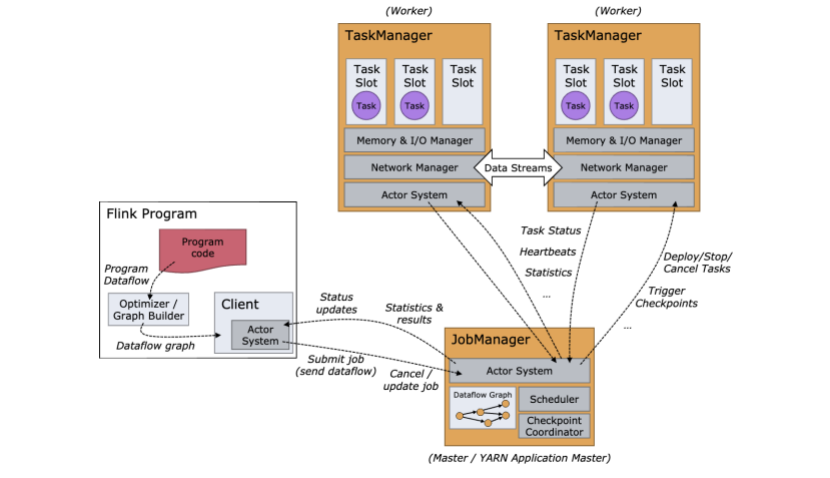
flink运行时是由两种处理类型组成:
JobManagers也叫masters协助分布式执行。JMS(jobmangers简称)定时任务,协助检查点,协助回复机制等。
通过至少有一个job manager,一般的我们高可用集群都是多个job manager,一个作为leader,另外一些作为备份节点,如果leader挂掉,那么就会通过选举策略选出来下一个leader节点。
Taskmanagers我们也叫workers,它们是用来具体执行任务的也就是具体的某个数据流的map,filer,keyby这些。所以Taskmanager至少会有一个。
JobManager 和 TaskManager 启动会有很多方式:直接在某台机器以单机的方式启动 https://ci.apache.org/projects/flink/flink-docs-release-1.10/ops/deployment/cluster_setup.html 在容器中,或者通过资源调度框架像yarn和 mesos这种。TaskManager链接JobManager,告诉JobManager它们是可用的,然后给他们分配任务,从而开始工作。
客户端并不是运行时和程序执行的一部分,但是通常用来准备和发送数据流到JobManager。之后,客户端其实就可以断掉了,或者保持链接接受程序的上报信息。客户端运行可以通过我们的程序启动,也可以通过命令来启动。
Task Slots and Resources
任务槽和资源
每一个worker就是一个jvm进程,然后会执行一个或者多个子任务在单独的线程中。通过任务槽来控制一个工作者接受多少个任务,任务槽至少一个。
每一个任务槽代表了TaskManager的一个固定的资源子集。一个TaskManager有三个槽,举例:也就是要分配1/3的内存给每一个槽。这种分配也就是不会和其他的作业抢夺内存资源而是占有一定数量的预留资源内存。注意:这里没有发生cpu隔离。当前的卡槽只是分配了任务的托管内存而已。
通过适应卡槽的数量,用户可以自定义就是多少子任务然后进行彼此隔离。每个TaskManager有一个卡槽意味着每一个任务组跑在一个单独的JVM。如果TaskManager有多个卡槽意味着有多个自任务会共享一个jvm。任务在相同的jvm共性tcp链接通过多路复用(https://www.jianshu.com/p/37d132327724)和心跳机制。他们也可能共享数据集和数据结构,这样减少了每个任务的开销。

默认情况,flin是允许子任务去共享卡槽的即使他们是不同任务的子任务。只要他们是一个job作业就可以。结果就是一个卡槽可能会占用一个作业的整个管道。允许这种卡槽共享的主要好处有两点:
flink集群需要的任务槽与作业中使用的最高并行度一样。我们不需要计算一个程序总共有多少个任务。
更容易获得更多的资源利用。没有槽共享。非密集型source()/map()子任务将会阻塞与密集型窗口子任务一样多的资源。使用槽共享,在我们的例子总将基础的并行度从2提到了6,这样就可以充分利用槽资源,同时也能将繁重的自任务公平的进行分配。

同样api也提供了资源组机制(https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/stream/operators/#task-chaining-and-resource-groups)避免了一些不必要的槽共享。
作为一种检验,一个好的默认任务槽数量和CPU的核数一致,在使用超线程时候,每个槽需要2个或者更多的一件线程上下文。
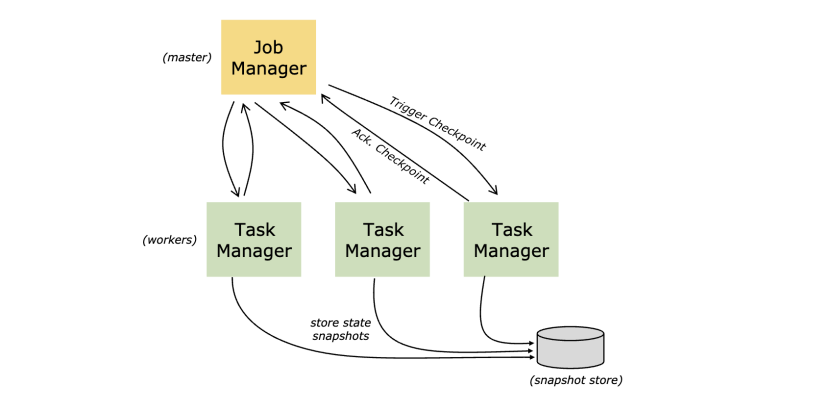
State Backends
保存状态的一种机制
存储键值索引的确切数据结构取决于所选择的状态后台(https://ci.apache.org/projects/flink/flink-docs-release-1.10/ops/state/state_backends.html)。一个状态后台存储数据在hash map,另外的状态后台使用RocksDB(https://rocksdb.org/)作为key/value存储。此外除了定义存储数据结构,这种状态后台还实现了获取key/value的时间点快照和把这个快照作为检查点一部分来存储的逻辑。
Savepoints
程序用DataStream API写的可以从保存点恢复执行。保存点允许更新你的程序并且你的flink集群不会丢失任何状态。
保存点是手动触发的检查点,通过获取程序的快照写入到状态后台,他们依赖于常规的检查点机制。恢复仅仅是在上次完成检查点的位置,老的检查点可以被丢弃当新的检查点完成的时候。
保存点类似周期性的检查点通过用户触发并且不是自动丢弃当新检查点完成。保存点可以通过命令行(https://ci.apache.org/projects/flink/flink-docs-release-1.10/ops/cli.html#savepoints)或者rest api(https://ci.apache.org/projects/flink/flink-docs-release-1.10/monitoring/rest_api.html#cancel-job-with-savepoint)来创建。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号