换根dp
换根dp是树形dp的一种变形,通常用于解决一下两种问题
- 题目中有明显的换根操作
- 子节点的信息更新需要父节点的信息,要二次扫描
换根dp的思考方式也很固定,一般从二次扫描需要的信息出发,然后通过第一次dfs维护出相应的信息,后续二次dfs更新答案。需要注意的是,虽然涉及到换根操作,但是都是从以1为根节点的树中的相关信息更新来的,因为固定的根节点是没有父节点的,因此它二次扫描一开始的信息是明确的,然后通过这个1号节点不断去更新新的后续节点。
这个时候换根dp的难点就是第一次扫描需要维护什么信息以及第二次扫描如何更新答案,我做题的过程中发现,真正的代码难点在于第二次扫描更新信息的诸多细节问题。
明显的换根操作
题目描述:给定一个n个节点的树,求出以每一个根节点为根的所有节点的深度和。
在这道题目中,有明显的换根字眼,因此考察的是换根dp。
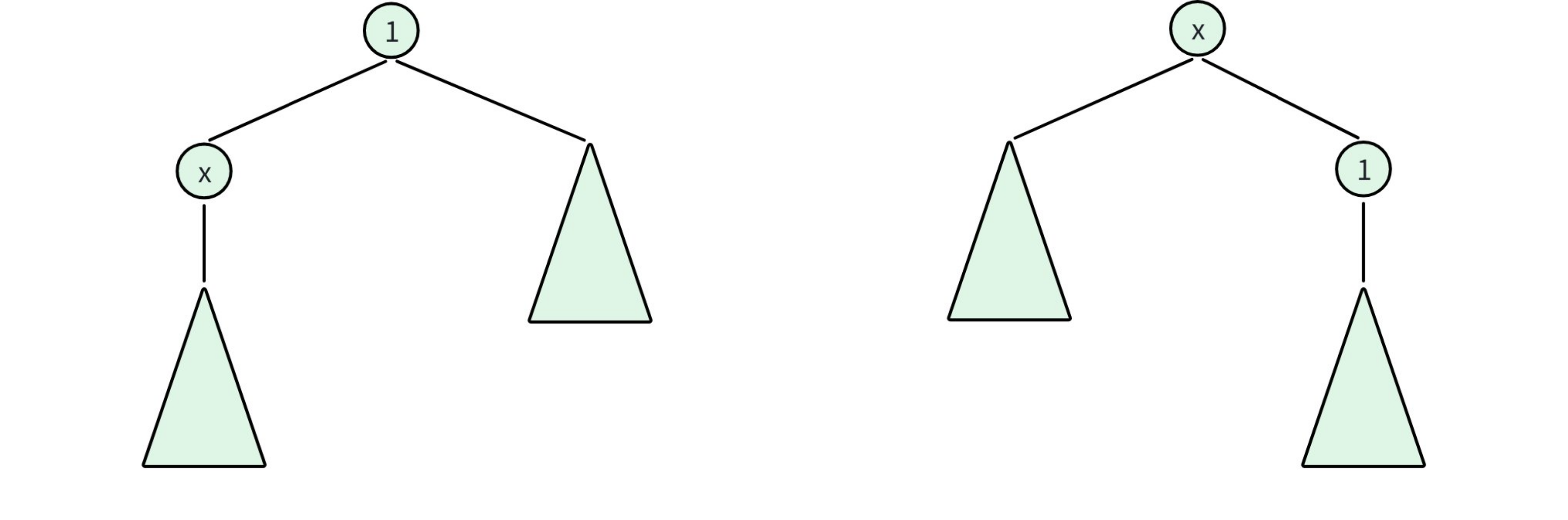
- 令\(dp_x\)表示以x节点为根所有节点的深度和,x为y节点的父节点,\(sz_x\)表示x子树的大小
- 注意到如果将y节点提到根节点的位置,x节点作为根时除去y子树的部分节点的深度统一+1,而节点x的子树部分的深度统一-1,这就启发我们维护子树大小信息。(
- \(dp_y={dp_x+n-sz_y-sz_y }\)
- 所以第一次dfs需要维护的信息是sz,sum(以1为根的情况下,x子树的所有节点的深度和)
code:
void dfs1(int x, int fa)
{
dep[x] = dep[fa] + 1;
sz[x] = 1;
sum[1] += dep[x];
for (auto y : edges[x])
{
if (y == fa)
continue;
dfs1(y, x);
sz[x] += sz[y];
}
}
void dfs2(int x, int fa)
{
for (auto y : edges[x])
{
if (y == fa)
continue;
sum[y] = sum[x] + n - sz[y] - sz[y];
dfs2(y, x);
}
}
与树形dp的不同:
- 树形dp通过一次dfs,采用自底向上的更新方式完成答案的更新、
- 换根dp通过两次dfs,第二次dfs采用自顶上下的更新方式完成对答案的更新
时间复杂度:O(n)
#include <iostream>
#include <vector>
using namespace std;
typedef long long LL;
const int N = 1e6 + 10;
LL sz[N], dep[N], sum[N];
int n;
vector<int> edges[N];
int main()
{
cin.tie(0); cout.tie(0);
ios::sync_with_stdio(false);
cin >> n;
for(int i = 1; i <= n - 1; i++)
{
int x, y; cin >> x >> y;
edges[x].push_back(y);
edges[y].push_back(x);
}
auto dfs1 = [](auto dfs1, int x, int fa)->void{
sz[x] = 1;
dep[x] = dep[fa] + 1;
sum[x] = dep[x];
for(auto& y : edges[x])
{
if(y == fa) continue;
dfs1(dfs1, y, x);
sz[x] += sz[y];
sum[x] += sum[y];
}
};
auto dfs2 = [](auto dfs2, int x, int fa)->void{
for(auto& y : edges[x])
{
if(y == fa) continue;
sum[y] = sum[x] + n - sz[y] - sz[y];
dfs2(dfs2, y, x);
}
};
dfs1(dfs1, 1, 0); dfs2(dfs2, 1, 0);
LL id = -1, ret = 0;
for(int i = 1; i <= n; i++)
{
if(sum[i] > ret)
{
ret = sum[i];
id = i;
}
}
cout << id << endl;
return 0;
}
需要二次扫描维护信息
题目描述:某学校在一段时间前购买了第一台计算机(因此这台计算机的编号是 1)。在最近几年中,学校又购买了 N−1 台新计算机。每台新计算机都连接到之前已经安装的计算机之一。学校的管理人员对网络运行缓慢感到担忧,想知道每台计算机需要发送信号的最大距离 Si(即到最远计算机的电缆长度)。你需要提供这些信息。
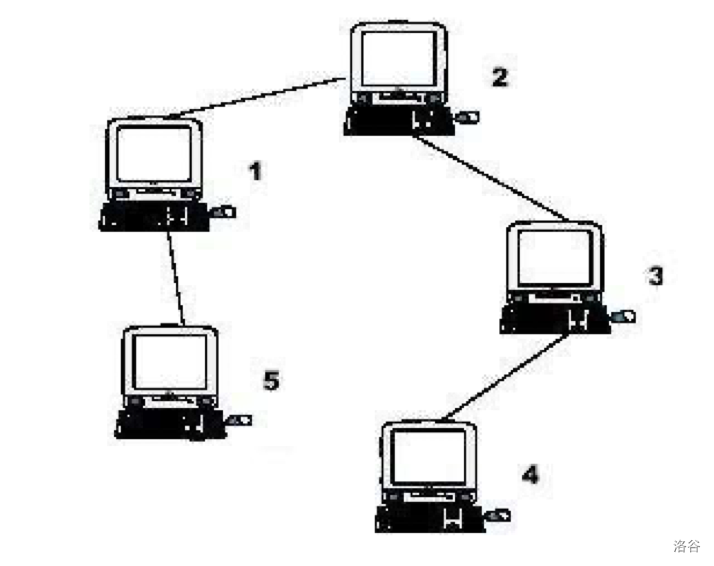
提示:示例输入对应于此图。从图中可以看到,计算机 4 是距离计算机 1 最远的,因此 S1=3。计算机 4 和 5 是距离计算机 2 最远的,因此 S2=2。计算机 5 是距离计算机 3 最远的,因此 S3=3。我们还得到 S4=4,S5=4。
【题解】:
本题求的是某个节点x到其他所有节点的最远距离,换句话说就是以x为根节点时,x节点到其子树中所以的节点的最大距离,所以用换根dp来解决。
比较容易想到的是需要维护\(f_x\)以x为根的子树中,x节点到其余节点的最远距离,现在来考虑二次扫描维护从x结点往上距离x的最远距离\(up_x\),从1号节点开始,其答案为\(f_1\),在更新其子节点y的up时候,可以分为两部分,一部分是从1节点往上走到的最大距离\(up_1\),另一部分是从1的子树中除去y的子树的最大距离,这一部分的距离统一加上\(len_{1->y}\)。
对于第二部分,1号的f把y的子树算在了里面,但实际上把y提到根节点的时候,y到子树的最大距离在\(f_y\)里面存着,\(f_y\)并不需要加上\(len_{1->y}\),为例避免这种情况,我们需要判断\(f_x\)是不是由\(f_y\)更新来的,及\(f_x=f_y+len_{x->y}\),如果这个条件满足,我们需要从\(f_x\)中找一条次大的变来更新\(up_y\),\(g_x\)表示以1为根的,x的子树中所有节点到x节点的次大距离。
下面是状态转移:
- \(f_x= \max_{y}f_y+len_{x->y}\),令\(f_y+len_{x->y}\)为\(val\)
- 若\(val>f_x\),\(g_x=f_x,f_x=val\)
- 若\(val<f_x\),\(g_x = max(g_x,val)\)
- \(up_y = max(up_x+len_{x->y},f_x+len_{x->y}))\),\(f_y+len_{x->y}==f_x\)\(up_y = max(up_x+len_{x->y},g_x+len_{x->y}))\),\(f_y+len_{x->y}\neq f_x\)
code:
#include <iostream>
#include <vector>
using namespace std;
typedef long long LL;
typedef pair<int, LL> PII;
const int N = 1e4 + 10;
const LL INF = 1e18;
LL f[N], g[N]; // 以x为根的子树中的最大距离和次大距离
LL up[N]; // 从x结点往上的最大距离
int n;
vector<PII> edges[N];
void dfs1(int x, int fa)
{
f[x] = 0;
g[x] = -INF;
for(auto& [y, z] : edges[x])
{
if(y == fa) continue;
dfs1(y, x);
LL val = z + f[y];
if(val <= f[x]) g[x] = max(g[x], val);
else
{
swap(f[x], g[x]);
f[x] = val;
}
}
}
void dfs2(int x, int fa)
{
for(auto& [y, z] : edges[x])
{
if(y == fa) continue;
// z + x往上的最大权值
up[y] = max(up[y], z + up[x]);
// z + x往下的最大权值,但是不能是f[y]
if(f[y] + z == f[x]) up[y] = max(up[y], g[x] + z);
else up[y] = max(up[y], z + f[x]);
dfs2(y, x);
}
}
int main()
{
while(cin >> n)
{
for(int i = 1; i <= n; i++) edges[i].clear(), up[i] = 0;
for(int i = 2; i <= n; i++)
{
int x, len; cin >> x >> len;
edges[x].push_back({i, len});
edges[i].push_back({x, len});
}
dfs1(1, 0);
dfs2(1, 0);
// int x = 2;
// cout << f[x] << " " << g[x] << " " << up[x] << endl;
for(int i = 1; i <= n; i++) cout << max(up[i], f[i]) << endl;
}
return 0;
}
后续在说明的时候如果没有特定指名切换根节点,根节点都为1,及所指的子树都是以1为整棵树的根.
练习题:
P2986 [USACO10MAR] Great Cow Gathering G
题目描述:Bessie 正在计划一年一度的奶牛大集会,来自全国各地的奶牛将来参加这一次集会。当然,她会选择最方便的地点来举办这次集会。
每个奶牛居住在 N 个农场中的一个,这些农场由 N−1 条道路连接,并且从任意一个农场都能够到达另外一个农场。道路 i 连接农场 A__i 和 B__i,长度为 L__i。集会可以在 N 个农场中的任意一个举行。另外,每个牛棚中居住着 C__i 只奶牛。
在选择集会的地点的时候,Bessie 希望最大化方便的程度(也就是最小化不方便程度)。比如选择第 X 个农场作为集会地点,它的不方便程度是其它牛棚中每只奶牛去参加集会所走的路程之和(比如,农场 i 到达农场 X 的距离是 20,那么总路程就是 Ci×20)。帮助 Bessie 找出最方便的地点来举行大集
【题解】:
这一道题很明显求的就是以x节点为根节点时其余节点到x节点的距离和,在求这个距离和的时候无非就是加权\(c_i\),令\(f_x\)为以x根节点的子树中,所以节点到x节点的距离加权和,\(up_x\)为x节点往上的距离加权和,\(f_x+up_x\)即为以把x提到根节点的距离加权和。
令y为x的子节点,更新\(up_y\)的时候分两部分,从x向上和从x向下除去y的子树,这两部分节点数量为\(sum-sz_y\),其中sum为所有节点的权值和,\(sz_y\)表示以y为根的子树的节点的权值和,这些权值统一加上\(len_{x->y}\)。
- \(sz_x=c_x+\sum_{y}sz_y\)
- \(f_x=\sum_{y}f_y+sz_y*len_{x->y}\)
- \(up_y=up_x+f_x-f_y-sz_y*len_{x->y}+(sum-sz_y)*len_{x->y}\)
code:
#include <iostream>
#include <vector>
using namespace std;
typedef long long LL;
typedef pair<int, LL> PII;
const LL INF = 2e18;
const int N = 1e5 + 10;
LL cnt[N], f[N], up[N], sz[N];
vector<PII> edges[N];
int n;
LL sum;
void dfs1(int x, int fa)
{
sz[x] = cnt[x];
f[x] = 0;
for(auto& [y, z] : edges[x])
{
if(y == fa) continue;
dfs1(y, x);
sz[x] += sz[y];
f[x] += sz[y] * z + f[y];
}
}
void dfs2(int x, int fa)
{
for(auto& [y, z] : edges[x])
{
if(y == fa) continue;
// x节点上方的最小路径 + 下方其他结点的路径
// up[y] = up[x] + (sum - sz[x]) * z +
// f[x] - f[y] - sz[y] * z + (sz[x] - sz[y]) * z;
up[y] = up[x] + f[x] - f[y] - sz[y] * z + (sum - sz[y]) * z;
dfs2(y, x);
}
}
int main()
{
cin >> n;
for(int i = 1; i <= n; i++)
{
cin >> cnt[i];
sum += cnt[i];
}
for(int i = 1; i <= n - 1; i++)
{
int x, y, len; cin >> x >> y >> len;
edges[x].push_back({y, len});
edges[y].push_back({x, len});
}
dfs1(1, 0);
dfs2(1, 0);
// int x = 3;
// cout << f[x] << ' ' << sz[x] << ' ' << up[x] << endl;
LL ans = INF;
for(int i = 1; i <= n; i++) ans = min(ans, f[i] + up[i]);
cout << ans << endl;
return 0;
}
CF219D Choosing Capital for Treeland
题目大意:Treeland 国有 n 个城市,有些城市间存在 单向 道路。这个国家一共有 n−1 条路。我们知道,如果把边视作双向的,那么从任意城市出发能到达任意城市。
城市的委员会最近决定为 Treeland 国选择一个首都,显然首都会是国中的一个城市。委员会将在首都开会,并经常去其他城市(这里不考虑从其他城市回到首都)。因此,如果城市 a 被选为首都,那么所有的道路应该被定向,以使得我们能从城市 a 到达其他城市。所以,有些路可能需要反转方向。
帮助委员会选择首都使得他们需要反转道路的次数最小。
【题解】:这题很明显了,令\(cnt_x\)表示以x为根的子树中道路需要反转的次数,\(up _x\)为从x节点到达上方节点所需要的反转次数,答案为\(cnt_x+up_x\)。
- \(cnt_x=\sum_{y}cnt_y+dir_{y->x}\)
- \(up_y=up_x+f_x-f_y-dir_{y->x}+dir_{x->y}\)
- \(dir_{x->y}\)表示连接x,y的边的方向,如果是x->y则为1否则为0
#include <iostream>
#include <vector>
#include <unordered_set>
using namespace std;
const int N = 2e5 + 10;
int n;
unordered_set<int> st[N];
// cnt[i]: 从i结点的子树到i需要反转的道路个数
// up[i]: 从i结点的上方到i结点需要反转的道路的个数
int cnt[N], up[N];
vector<int> edges[N];
void dfs1(int x, int fa)
{
cnt[x] = 0;
for(auto& y : edges[x])
{
if(y == fa) continue;
dfs1(y, x);
cnt[x] += cnt[y];
// y -> x
if(st[y].count(x)) cnt[x]++;
}
}
void dfs2(int x, int fa)
{
for(auto& y : edges[x])
{
if(y == fa) continue;
up[y] += up[x] + cnt[x] - cnt[y];
// x -> y
if(st[x].count(y)) up[y]++;
else up[y]--;
dfs2(y, x);
}
}
int main()
{
int n; cin >> n;
for(int i = 1; i <= n - 1; i++)
{
int x, y; cin >> x >> y;
edges[x].push_back(y);
edges[y].push_back(x);
st[x].insert(y);
}
dfs1(1, 0);
dfs2(1, 0);
int mina = 1e9;
for(int i = 1; i <= n; i++)
mina = min(mina, up[i] + cnt[i]);
cout << mina << endl;
for(int i = 1; i <= n; i++)
if(mina == up[i] + cnt[i])
cout << i << ' ';
return 0;
}
CF1187E Tree Painting
题目描述:给定一棵包含 n 个顶点的树(无向连通无环图)。你要在这棵树上玩一个游戏。
最开始所有顶点都是白色的。在游戏的第一回合,你选择一个顶点并将其染成黑色。之后的每一回合,你都可以选择一个与任意黑色顶点相邻的白色顶点,并将其染成黑色。
每当你选择一个顶点(包括第一回合),你获得的分数等于染色前包含该顶点的、仅由白色顶点组成的连通块的大小。游戏在所有顶点都被染成黑色时结束。
顶点 1 和 4 已经被染成黑色。如果你选择顶点 2,你将获得 4 分,因为包含顶点 2,3,5,6 的连通块的大小为 4。如果你选择顶点 9,你将获得 3 分,因为包含顶点 7,8,9 的连通块的大小为 3。
你的任务是最大化你获得的分数。
【题解】:虽然本题看起来挺复杂的,但是当我们从任意一个节点开始模拟,发现当该节点被涂黑时,连通块分成了两个部分,分别是该节点的子树全部涂黑所对应的最大分数和该节点的父节点全部涂黑所对应的最大分数,这显然又是一个换根dp的过程。
然后我们发现其实子树部分全图涂黑的最大分数所对应的涂色方案是固定的,换句话说我们可以直接算出来以x为根节点的子树(不包含x节点)全部涂黑所获得的最大分数,涂色方案为dfs的过程,令其为\(f_x\)。
令y节点上方节点全部涂黑所获得的最大分数为\(up_y\)(不包含y节点),发现去其也可以分为两部分,一部分是其父节点x往上的\(up_x\),另一部分则是x的子树中除去y子树部分的最大分数\(f_x-f_y-sz_y\),最后加上涂黑x节点的贡献\(n-sz_x\)
- \(f_x=\sum_{y}f_y+sz_y\)
- \(up_y=up_x+f_x-f_y-sz_y+n-sz_x\)
- 由于f和up两个状态都没有不包含x节点,最后答案需要加上第一次涂黑x节点的贡献n,及\(ans_x=up_x+f_x+n\)
code:
#include <iostream>
#include <vector>
using namespace std;
const int N = 2e5 + 10;
typedef long long LL;
vector<int> edges[N];
int n;
LL sz[N], f[N], up[N];
void dfs1(int x, int fa)
{
sz[x] = 1;
for(auto& y : edges[x])
{
if(y == fa) continue;
dfs1(y, x);
f[x] += f[y];
f[x] += sz[y];
sz[x] += sz[y];
}
}
void dfs2(int x, int fa)
{
for(auto& y : edges[x])
{
if(y == fa) continue;
up[y] = up[x] + f[x] - f[y] - sz[y] + n - sz[y];
dfs2(y, x);
}
}
int main()
{
cin >> n;
for(int i = 1; i <= n - 1; i++)
{
int x, y; cin >> x >> y;
edges[x].push_back(y);
edges[y].push_back(x);
}
dfs1(1, 0);
dfs2(1, 0);
int x = 2;
LL ans = 0;
for(int x = 1; x <= n; x++) ans = max(ans, n + up[x] + f[x]);
cout << ans << endl;
return 0;
}
P10974 Accumulation Degree
题目描述:树在许多世界神话中也扮演着亲密的角色。许多学者对树的一些特殊属性感兴趣,例如树的中心、树的计数、树的着色等。树的累积度 A(x) 就是其中的一种属性。
我们这么定义 A(x):
- 树的每一条边都有一个正容量。
- 树中度为 1 的节点被称为终端节点。
- 每条边的流量不能超过其容量。
- A(x) 是节点 x 可以流向其他终端节点的最大流量。
树的累积度是指其节点中最大累积度的值。你的任务是找到给定树的累积度。
【题解】:
A(x)可以拆分成从x节点流向子树的叶结点累积度和从x节点流向父节点中度为1的节点的累积度,所以这显然还是一个换根dp。
令\(f_x\)表示从x节点流向叶节点的累积度,从题目的描述可以知道,\(f_x\)的更新需要对\(x->y\)的边权和\(f_y\)取最小值,但是当y为叶结点的时候,\(f_y=0\),此时\(f_x\)的累加就是边权,对于这种情况可以让\(f_y\)为INF,也可以特判一下。
令\(g_y\)表示从y节点往上流向度为1节点的累积度,同样分为两部分考虑,\(g_x\)表示从y的父节点x往上的最大累积度,这一部分和上面同理,需要对x->y的边权取最小值,然后对度为1的节点特判,另一部分则为x子树中去除y子树的部分。
- \(f_x=\sum_{y}(edges[y].size() == 1 ? z:min(z, f_y))\)
-\(g_y+=z\)\(edges[x].size() ==1\),\(g_y+min(z, g_x)\)\(edges[x].size() \neq1\)
-\(g_y+=min(z, f_x-f_y-(edges[y].size()==1?z:min(z,f_y)))\)\(edges[x].size()\neq1\) - 答案为\(f_x+g_x\)
code:
#include <iostream>
#include <vector>
using namespace std;
typedef long long LL;
typedef pair<int, LL> PII;
const int N = 2e5 + 10;
vector<PII> edges[N];
LL f[N], g[N];
int n;
void dfs1(int x, int fa)
{
for (auto &[y, z] : edges[x])
{
if (y == fa)
continue;
dfs1(y, x);
if (edges[y].size() == 1)
f[x] += z;
else
f[x] += min(f[y], z);
}
}
void dfs2(int x, int fa)
{
for (auto &[y, z] : edges[x])
{
if (y == fa)
continue;
if (edges[x].size() != 1)
g[y] = f[y] + min(z, g[x] - min(z, f[y]));
else
g[y] = z + f[y];
dfs2(y, x);
}
}
void solve()
{
cin >> n;
for (int i = 1; i <= n; i++)
{
edges[i].clear();
f[i] = g[i] = 0;
}
for (int i = 1; i <= n - 1; i++)
{
int x, y, z;
cin >> x >> y >> z;
edges[x].push_back({y, z});
edges[y].push_back({x, z});
}
dfs1(1, 0);
g[1] = f[1];
dfs2(1, 0);
LL ans = 0;
for (int i = 1; i <= n; i++)
ans = max(ans, g[i]);
cout << ans << endl;
}
int main()
{
int T;
cin >> T;
while (T--)
solve();
return 0;
}
需要注意的是:上面代码的g为转移方程中的\(f_x+g_x\)即直接把答案算出来了,转移方程有些许变换,但也很明了,不多赘述。
P6419 [COCI 2014/2015 #1] Kamp
题目描述:一棵树 n 个点,n−1 条边,经过每条边都要花费一定的时间,任意两个点都是联通的。
有 K 个人(分布在 K 个不同的点)要集中到一个点举行聚会。
聚会结束后需要一辆车从举行聚会的这点出发,先让所有人都上车,再把这 K 个人分别送回去。
请你回答,对于 i=1∼n ,如果在第 i 个点举行聚会,司机最少需要多少时间把 K 个人都送回家。
【题解】:经典最后留一道难度唬人但实际上去却很简单的一道题。
首先对于x节点为聚会举行点,把客人送回家所需要的时间同样是涉及到x的子树和x向上的节点,也是一道换根dp,但是对于所有的客人,送客的方案并不唯一,路径选择的不同会影响最终的送客时间,好似问题是回到了路径规划或者贪心上,仔细一想 ,送客的过程可以看做把所有的客人送回家并回到x节点的时间减掉最后一个被送的客人到x节点的时间,前者可以看做一条条x到固定节点的路径和,节点之间的简单路径和根节点无关,为定值,所以答案的前者为定制,由于要求的是最短的时间后者减掉一个最大值即可,到这里这道题已经做完了,剩下的就只有一些细节问题和状态转移。
令\(f_x\)表示送完x子树中的客人并回到x节点的时间花费,\(g_x\)表示送完x节点上方的客人并回到x节点的时间花费,\(d_x\)表示x子树中距离x节点的最远客人的距离,\(up_x\)表示x节点上方距离x节点最远的客人的距离,做完上面的题这里应该会想到更新\(up_x\)的时候需要对父节点的子树和x节点的子树作差,而max对于一颗子树的作差需要次大节点,所以这里另需维护\(p_x\)表示x的子树中距离x节点次元的客人的距离。
由于本题目涉及到的状态有点多,所以这里在稍微明确一下哪些状态需要在第一次遍历维护,哪些需要在二次扫描的时候更新。
dfs1:\(f_x\)\(d_x\)\(p_x\)
对于x的子树送客时间的维护,显然需要判断x的子节点y中是否存在客人,用\(st_x\)表示x节点有客人,则这个判断变成了\(st_y||f_y\)
- \(f_x=\max_{y}f_y+2len_{x->y}(st_y||f_y)\)
- \(g_x =\max_{y}(f_y+2len_{x->y})\)
-\(p_x=\max_{y}(f_y+2len_{x->y})(f_y+2len_{x->y}\le f_x)\)
-\(p_x=\max_{y}(f_x)(f_y+2len_{x->y}>f_x)\)
dfs2:\(up_y\)\(g_y\)
对于y往上的节点的送客时间,同样需要判断一下是否可以转移,这里的判断分为两部分,
-\(x\)节点往上是否有客人要送,及\(g_x\)是否有值
-\(x\)节点的子树中,除去\(y\)节点的子树外有客人要送,\(((st_y || f_y) \&\& f_y - f_y - 2 * z)) || ((!(st_y || f_y) \&\& f_x)\)
这两个判断太长了,下面就不写了,但是下面转移是默认上述两种情况至少发生一种才会进行。
- \(g_y=g_x+f_x-f_y\),这个时候如果\(g_y\)有值,并且\(!(st_y||f_y)\)及x->y的这条边并没有被算到上面那个式子里面,\(g_y+=2*len_{x->y}\)
- \(up_y=\max_{y}(up_x+z, z+(z+d_y==d_x?p_x:d_x))\)
code:
#include <iostream>
#include <vector>
using namespace std;
typedef long long LL;
typedef pair<int, LL> PII;
const int N = 5e5 + 10;
vector<PII> edges[N];
int n, k;
bool st[N];
LL f[N], g[N], d[N], up[N], p[N];
void dfs1(int x, int fa)
{
// cout << x << " " << fa << endl;
for (auto &[y, z] : edges[x])
{
if (y == fa)
continue;
dfs1(y, x);
if (st[y] || f[y])
{
f[x] += f[y] + 2 * z;
if (d[y] + z > d[x])
{
swap(d[x], p[x]);
d[x] = d[y] + z;
}
else
p[x] = max(p[x], d[y] + z);
}
}
}
void dfs2(int x, int fa)
{
for (auto &[y, z] : edges[x])
{
if (y == fa)
continue;
if (((st[y] || f[y]) && f[x] - f[y] - 2 * z != 0) || (!(st[y] || f[y]) && f[x]) || g[x])
{
g[y] = g[x] + f[x] - f[y];
if(g[y] && !(st[y] || f[y])) g[y] += 2 * z;
up[y] = max(up[y], max(up[x] + z, z + (z + d[y] == d[x] ? p[x] : d[x])));
}
dfs2(y, x);
}
}
int main()
{
cin >> n >> k;
for (int i = 1; i <= n - 1; i++)
{
int x, y, z;
cin >> x >> y >> z;
edges[x].push_back({y, z});
edges[y].push_back({x, z});
}
for (int i = 1; i <= k; i++)
{
int x;
cin >> x;
st[x] = true;
}
dfs1(1, 0);
dfs2(1, 0);
// int x = 3;
// cout << f[x] << " " << g[x] << endl;
for (int x = 1; x <= n; x++)
cout << f[x] + g[x] - max(d[x], up[x]) << endl;
return 0;
}
总结
换根dp总的来说就是树形dp的变种,并不算特别复杂的一个篇章。
二次扫描更新相关信息是新增的内容,
这一部分信息有的时候会作为一个整体去更新,如accumulation degree这一道题目直接服用了g表把答案直接统计,这么做是可以的,但是相关的思维难度会高一点,出错率高,所以还是建议下面那一种状态表示
有的时候会分为父节点到上方节点和父节点的子树除去子节点子树的部分更新,如kamp这一题中,把整块答案分割去更新。
换根dp在二次扫描更新答案的时候,往往会需要对于第一次更新的内容做差操作,因为x作为y的节点,x的子树中除去y的子树部分同样会作为y的上方节点被更新,这个时候需要将x第一次维护的信息中y的部分剔除,这就需要第一次操作的逆操作,但是在这个剔除的操作区别于树状数组的区间作差,它仅仅是减掉一个子树,对于连续的信息来说,例如区间的和,直接减就可以,对于不连续的信息,例如区间的max或者min,这类信息是不支持区间减的操作的,但是对于子树却可以用一个次级信息来进行差操作。
在上述的基础上,换根dp二次扫描的时候,更新尝尝会分成两部分进行更新,分别为x网上的部分以及x子树除去y子树的部分,原因以方面x子树需要做差操作,另一方面有的时候这两部分的更新规则不一样。
所以去衡量一个换根dp题目的难度可以从三方面考虑:
- 本身树形dp状态定义及转移的难度。
- 二次扫描差操作是否可行,如果不行就需要更巧妙的状态表示。
- 转移分两部分进行各自的思考难度,以及各种繁琐的细节问题。
还有就是对于这类问题的调试操作,可以在两次dfs之后定义一个x变量,然后对于手操的样例信息进行信息检查,首先确保第一次dfs的信息是正确的,然后从1节点开始检查二次扫描更新出来的信息是否符合预期,然后特殊样例的构造就是对于一个单一节点来说?是否给它的父节点x上方还分配节点以及x的子树中除了y子树之外的几点是否还有?另外x是否转移的时候用到了y的信息?还是说由于一些特殊的性质y的信息并没有用到dp值本身而是别的值?...
.....

 浙公网安备 33010602011771号
浙公网安备 33010602011771号