pandas学习笔记
创建
不设置index列,默认从0开始的序号
import pandas as pd
dic = {
'name': ['张三', '李四', '王二麻子', '小淘气'],
'age': [37, 30, 50, 16],
'gender': ['男', '男', '男', '女']
}
df = pd.DataFrame(dic)
print(df.head()) # 前5行
or(笔者比较常用的)
titleList = ['name', 'age', 'gender']
dataList = [
['张三', 37, '男'],
['李四', 30, '男'],
['王二麻子', 50, '男'],
['小淘气', 16, '女'],
]
df = pd.DataFrame(dataList, columns=titleList)
print(df.head()) # 前5行
设置指定的序号
dic = {
'备注': ['不及格', '良好', '最佳', '优秀'],
'工资': [5000, 7000, 9000, 8500],
'绩效分': [60, 84, 98, 91]
}
indea_list = ['张三', '李四', '王二麻子', '小淘气']
df = pd.DataFrame(dic, indea_list)
print(df.tail()) # 最后5行
or(笔者比较常用的)
titleList = ['name', 'age', 'gender']
dataList = [
['张三', 37, '男'],
['李四', 30, '男'],
['王二麻子', 50, '男'],
['小淘气', 16, '女'],
]
indexList = ['001', '002', '003', '004']
df = pd.DataFrame(dataList, index=indexList, columns=titleList)
print(df.head()) # 前5行
数据存储
import os
os.chdir(os.path.abspath(os.path.dirname(__file__)))
df.to_csv('dataInfo.csv')
数据读取
df = pd.read_excel('dataInfo.xlsx')
df = pd.read_csv('dataInfo.csv', engine='python')
csv文件指定Python,避免报错
查看数据格式
df.info()
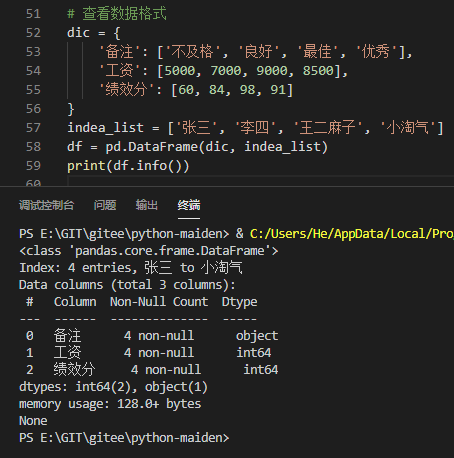
查看信息统计概览
快速计算数值型数据的关键统计指标,像平均数、中位数、标准差等等。
df.describe()
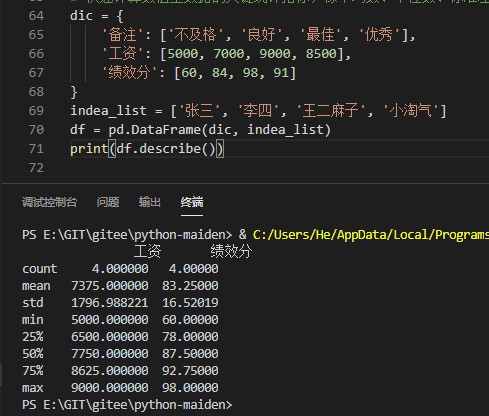
- count:非空值数
- mean:均值
- std:标准差
- min/max:最大值/最小值
- 25%/50%/75%:百分位
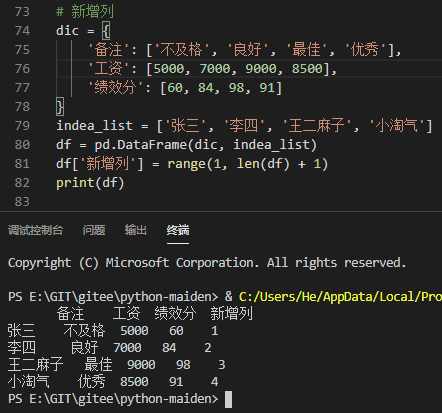
新增列
df['新增列'] = range(1, len(df) + 1)
删除列
df.drop('新增列', axis=1, inplace=True)
axis=1,表示列处理。inplace=True表示在源数据上处理
选择某一列
df['备注']
选择多列
print(df[['备注', '工资']])
修改列
df['新增列'] = "20%"
修改列类型
df['新增列'] = df['新增列'].str.replace('%', '').astype(float)
or
df['YOYEPSBasic'] = pd.to_numeric(df['YOYEPSBasic'], errors='coerce')
日期类型
df['日期'] = '2020-09-07'
print(df)
df['日期'] = pd.to_datetime(df['日期'])
print(df.info())
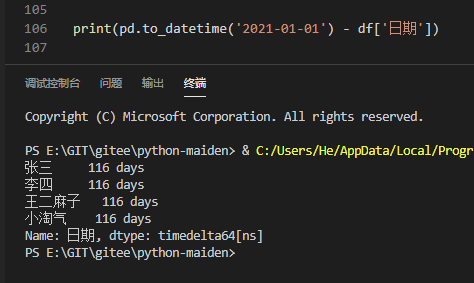
日期相减
pd.to_datetime('2021-01-01') - df['日期']
pandas比较
import datacompy
compare = datacompy.Compare(self.df1, self.df2, join_columns=['业务类型', '名称', '代码', '数据项名称', '数据项值'])
print(compare.matches()) # 最后判断是否相等,返回 bool
print(compare.report()) # 打印报告详情,返回 string
print(compare.report(sample_count=5000)) # 打印报告详情,返回 string
# 仅df1和仅df2记录(DataFrames)
print(compare.df1_unq_rows)
print(compare.df2_unq_rows)
行选取/列选取
# 选取0-11行,第0列和第5列
df.iloc[:10,[0,5]
for循环
for index in df2_unq_rows.index:
print(df2_unq_rows.loc[index, '业务类型'])
pandas应用实例
合并
纵向合并
df = pd.concat([df1, df2, df3])
横向合并
pd.merge(left=df1, right=df2, left_index=True, right_index=True, how='inner')
解释一下,这里类似数据库查询,左表为df1,右表为df2,,使用index内联.另外还有left,right,outer
如果需要根据其他的列进行匹配,则:
pd.merge(left=df1, right=df2, left_on='姓名', right_on='姓名', how='left')
删除空行
df = df.dropna()
去重
df = df.drop_duplicates()
df2_unq_rows = df2_unq_rows.drop_duplicates(subset=None, keep='first', inplace=False)
subset:指定删除某列,默认完全查重;keep:保留某一行,默认保留第一行
指定列去重
df = df.drop_duplicates(sunset='姓名', keep='last')
排序
df = df.sort_values('姓名', ascending=False)
分组
df.groupby('性别')
分组求和
df.groupby('性别').sum()
# 指定求和列
df.groupby('性别')['工资','成绩'].sum()
不指定求和列,会对所有的数值型求和
切分
df['级别'] = df.cut(x=df['访客量'], bins=[0, 100, 1000, 10000, 100000], right=False, labels=['菜鸡', '百级', '千级', '万级'])
百分数转化为小数
self.df['growthRate'] = self.df['growthRate'].str.strip('%').astype(float)/100
根据涨跌幅计算单位净值
self.df['net'] = (1 + self.df['growthRate']).cumprod()
重新编号
self.df_sz50 = self.df_sz50.reset_index(drop=True)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号