Python爬取豆瓣书籍信息及分析
一、选题背景
从古至今,喜爱阅读-直是中华民族的优良传统。自新中国以来,随着社 从古至今,喜爱阅读-直是中华民族的优良传统.自新中国以来,随着社
会的稳定,经济的发展,科学的进步,人民物质生活水平和精神生活水平的提高,国民阅读量和阅读效率也有了一定的上升提高,国民阅读量和阅读效率也有了一定的上升。
数据来源:豆瓣读书https://book.douban.com/tag/?view=type&icn=index-sorttags-hot
二、主题式网络爬虫设计方案
1、爬虫名称
豆瓣书籍信息爬取及可视化分析
2、爬虫爬取的内容与数据特征分析
内容包括:书名、基本信息、评价方面的数据、星级、评分、评价人数、内容描述
数据皆由文字与数字组成
3、方案概述
对网站页面结构进行分析,选中页面中css节点的数据进行精准抓取,获取自己需要的数据信息,然后保存为xlsx文件并对文件进行数据清洗和可视化分析。
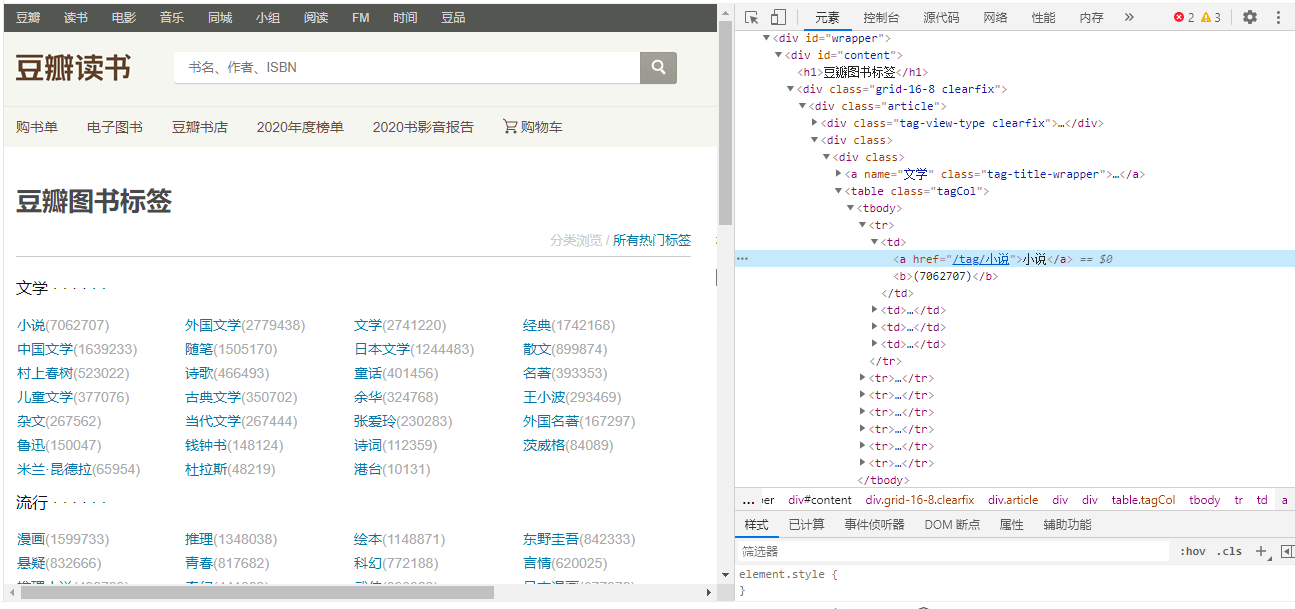
三、主题页面的结构特征分析
右键单击选择查看,找到要爬取的布局结构页面标签
四、爬虫程序设计
1、数据爬取与采集
导入需要用到的库
1 #导入requests模块 2 import requests 3 import pandas as pd 4 from bs4 import BeautifulSoup 5 import re
由于书籍类别多样,对类别进行分类
1 # 类别选择 2 def choice_category(cookies): 3 headers = { 4 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3298.4 Safari/537.36' 5 } 6 url = 'https://book.douban.com/tag/?view=type&icn=index-sorttags-hot' 7 category_list = [] 8 res = requests.get(url, cookies=cookies, headers=headers) 9 soup = bs4.BeautifulSoup(res.text, 'html.parser') 10 # 找到所有分类列表 11 soup_list = soup.find('div', attrs={'class': 'article'}) 12 # 大类 13 first_class = soup_list.findAll('a', attrs={'class': 'tag-title-wrapper'}) 14 # 小类 15 second_class = soup_list.findAll('table', attrs={'class': 'tagCol'}) 16 # 进一步提取 17 first_class_list = [] 18 for fc in first_class: 19 first_class_list.append(fc.attrs['name']) 20 num = 0 21 for sc in second_class: 22 second_class_list = [] 23 sc = sc.findAll('a') 24 for sc_i in sc: 25 second_class_list.append(sc_i.string.strip()) 26 category_list.append([first_class_list[num], second_class_list]) 27 num += 1 28 return category_list
开始对想要爬取的内容进行爬虫
1 # 书籍信息爬虫 2 def book_spider(book_tag, cookies): 3 headers = { 4 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3298.4 Safari/537.36' 5 } 6 books_list = [] 7 page_num = 0 8 url = 'https://book.douban.com/tag/' + urllib.parse.quote(book_tag) + '?start=' + str(page_num*20) + '&type=T' 9 res = requests.get(url, cookies=cookies, headers=headers) 10 soup = bs4.BeautifulSoup(res.text, 'html.parser') 11 # 找到一共有多少页 12 page_num_max = soup.find('div', attrs={'class': 'paginator'}) 13 page_num_max = page_num_max.findAll('a') 14 page_num_max = page_num_max[-2].string.strip() 15 page_num_max = int(page_num_max) 16 while True: 17 url = 'https://book.douban.com/tag/' + urllib.parse.quote(book_tag) + '?start=' + str(page_num*20) + '&type=T' 18 res = requests.get(url, cookies=cookies, headers=headers) 19 soup = bs4.BeautifulSoup(res.text, 'html.parser') 20 # 找到该页所有书 21 soup_list = soup.findAll('li', attrs={'class': 'subject-item'}) 22 for book_info in soup_list: 23 # 书名 24 title = book_info.find('a', attrs={'title': True}) 25 book_url = title.attrs['href'] 26 title = title.attrs['title'] 27 # 基本信息 28 basic_info = book_info.find('div', attrs={'class': 'pub'}).string.strip() 29 basic_info_list = basic_info.split('/') 30 try: 31 author_info = '/'.join(basic_info_list[0: -3]) 32 except: 33 author_info = '暂无' 34 try: 35 pub_info = '/'.join(basic_info_list[-3: ]) 36 except: 37 pub_info = '暂无' 38 # 评价方面的数据 39 evaluate_info = book_info.find('div', attrs={'class': 'star clearfix'}) 40 # 星级 41 try: 42 allstar = evaluate_info.find('span', attrs={'class': True}) 43 if (allstar.attrs['class'])[0][-1] == '1': 44 allstar = (allstar.attrs['class'])[0][-1] 45 else: 46 allstar = (allstar.attrs['class'])[0][-2] + '.' + (allstar.attrs['class'])[0][-1] 47 except: 48 allstar = '0.0' 49 # 评分 50 try: 51 rating_nums = evaluate_info.find('span', attrs={'class': 'rating_nums'}).string.strip() 52 except: 53 rating_nums = '0.0' 54 # 评价人数 55 try: 56 people_num = evaluate_info.find('span', attrs={'class': 'pl'}).string.strip() 57 people_num = people_num[1: -4] 58 except: 59 people_num = '0' 60 # 内容描述 61 try: 62 description = book_info.find('p').string.strip() 63 except: 64 description = '暂无' 65 # 信息整理 66 books_list.append([title, author_info, pub_info, allstar, rating_nums, people_num, description, book_url]) 67 print('第%d页信息采集完毕,共%d页' % (page_num+1, page_num_max)) 68 time.sleep(0.5) 69 page_num += 1 70 if page_num == page_num_max: 71 break 72 return books_list
将数据保存到excel中
1 # 结果保存到excel中 2 def save_to_excel(books_list, excel_name): 3 wb = Workbook() 4 ws = wb.active 5 ws.append(['序号', '书名', '作者/译者', '出版信息', '星级', '评分', '评价人数', '简介', '豆瓣链接']) 6 count = 1 7 for bl in books_list: 8 ws.append([count, bl[0], bl[1], bl[2], bl[3], bl[4], bl[5], bl[6], bl[7]]) 9 count += 1 10 wb.save('./results/' + excel_name + '.xlsx')
2、对数据进行清理和处理
导入需要用到的库
1 #数据处理 2 import pandas as pd
随机读取一个类别的书籍数据(这里我举例编程类型的书籍)
1 #读取数据 2 db_read = pd.read_excel("编程.xlsx",index_col=0)
1 #数据清理 2 #重复值的处理 3 titanic = titanic.drop_duplicates() 4 titanic.head()
3、数据分析和可视化
读取数据查看前五行信息
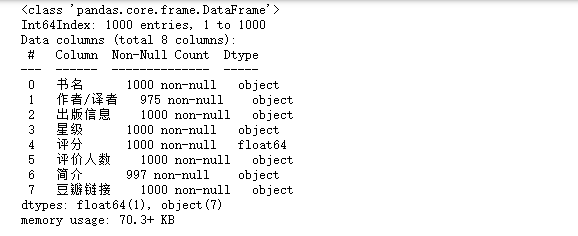
1 #可视化 2 from matplotlib import pyplot as plt 3 #可视化 4 import seaborn as sns 5 #读取数据 6 db_read = pd.read_excel("编程.xlsx",index_col=0) 7 #查看数据信息 8 db_read.info() 9 #查看前五条数据 10 db_read.head()
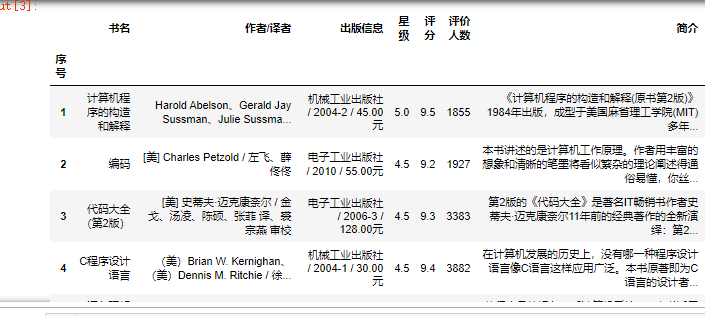
以评分来降序排序
1 #将整个数组以评分来排序 2 desc_data = db_read.sort_values(by="评分",ascending=False) 3 desc_data
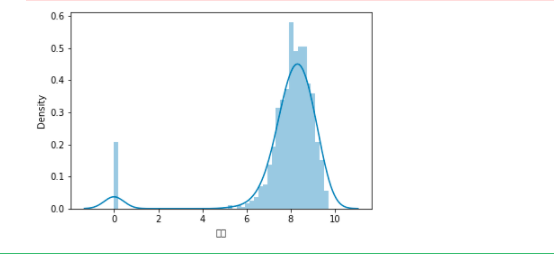
查看编程类型的书籍评分分布,可以看出主要分布在6~9.5分的范围
1 #可视化 2 #评分主要分布区域 3 sns.distplot(db_read["评分"])
取出前100条,观察星级分布
1 #取出前一百条,体现星级分布 2 top_100 = desc_data.iloc[:100,:] 3 sns.catplot(x="星级",data = top_100,kind="count",height=10) 4 plt.xticks(rotation=90) 5 plt.show()
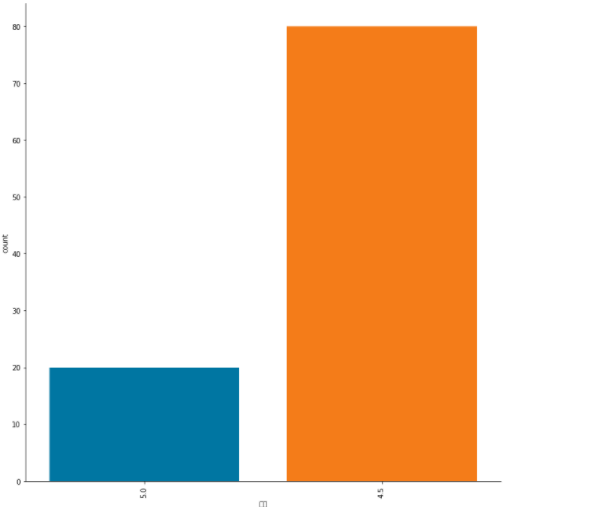
对书籍热门短评生成词云
1 # 将书籍热门短评制作为词云 2 def Book_Blurb_wordcloud(url, cookies): 3 headers = { 4 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3298.4 Safari/537.36' 5 } 6 page_num = 0 7 hot_comment_list = [] 8 while True: 9 page_num += 1 10 url = url + 'comments/hot?p={}'.format(page_num) 11 res = requests.get(url, cookies=cookies, headers=headers) 12 soup = bs4.BeautifulSoup(res.text, 'html.parser') 13 # 找到该页所有短评 14 soup_list = soup.findAll('p', attrs={'class': 'comment-content'}) 15 for com in soup_list: 16 comment = com.string.strip() 17 hot_comment_list.append(comment) 18 print('第%d页短评采集完毕' % page_num) 19 if page_num > 19: 20 print('前20页短评全部采集完毕,开始制作词云') 21 break 22 all_comments = '' 23 for hc in hot_comment_list: 24 all_comments += hc 25 all_comments = filterword(all_comments) 26 words = ' '.join(jieba.cut(all_comments)) 27 # 这里设置字体路径 28 Words_Cloud = WordCloud(font_path="simkai.ttf").generate(words) 29 Words_Cloud.to_file('Book_Blurb.jpg')

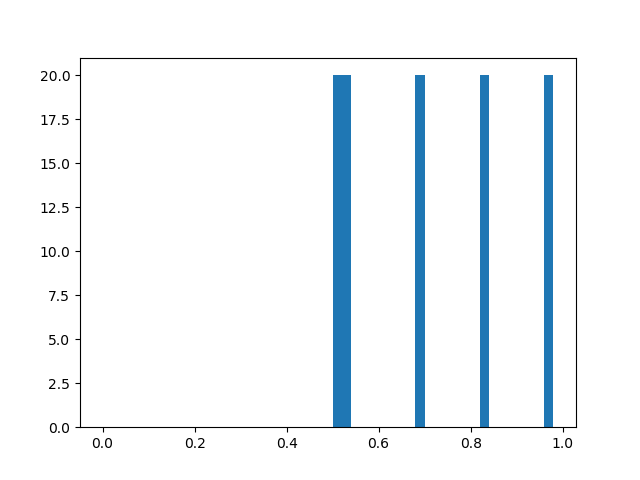
对短评情感进行分析
1 # 短评情感分析 2 def emotion_analysis(url, cookies): 3 headers = { 4 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3298.4 Safari/537.36' 5 } 6 page_num = 0 7 hot_comment_list = [] 8 while True: 9 page_num += 1 10 url = url + 'comments/hot?p={}'.format(page_num) 11 res = requests.get(url, cookies=cookies, headers=headers) 12 soup = bs4.BeautifulSoup(res.text, 'html.parser') 13 # 找到该页所有短评 14 soup_list = soup.findAll('p', attrs={'class': 'comment-content'}) 15 for com in soup_list: 16 comment = com.string.strip() 17 hot_comment_list.append(comment) 18 print('第%d页短评采集完毕' % page_num) 19 if page_num > 19: 20 print('前20页短评全部采集完毕,开始情感分析') 21 break 22 marks_list = [] 23 for com in hot_comment_list: 24 mark = SnowNLP(com) 25 marks_list.append(mark.sentiments) 26 plt.hist(marks_list, bins=np.arange(0, 1, 0.02)) 27 plt.show()
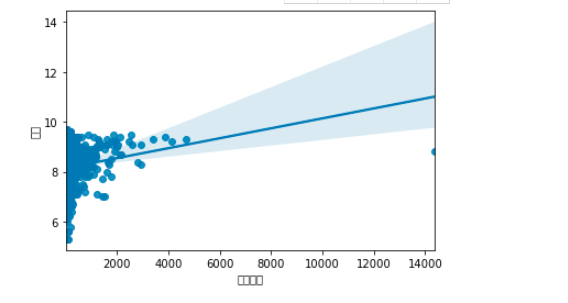
4、根据数据之间的关系,分析两个变量之间的相关系数,画出散点图,并建立变量之间的回归方程
分析评价和评价人数两个变量之间的关系绘制回归图
1 #插入所需要的库 2 import pandas as pd 3 import pandas as np 4 import sklearn 5 #将本地的编程.xlsx数据加载到DataFrame中 6 boston_df=pd.read_excel('编程.xlsx',index_col=0) 7 boston_df.head() 8 #绘制回归图 9 import seaborn as sns 10 sns.regplot(boston_df.评价人数,boston_df.评分)
5、完整程序代码
1 #导入requests模块 2 import requests 3 import pandas as pd 4 from bs4 import BeautifulSoup 5 import re 6 7 # 类别选择 8 def choice_category(cookies): 9 headers = { 10 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3298.4 Safari/537.36' 11 } 12 url = 'https://book.douban.com/tag/?view=type&icn=index-sorttags-hot' 13 category_list = [] 14 res = requests.get(url, cookies=cookies, headers=headers) 15 soup = bs4.BeautifulSoup(res.text, 'html.parser') 16 # 找到所有分类列表 17 soup_list = soup.find('div', attrs={'class': 'article'}) 18 # 大类 19 first_class = soup_list.findAll('a', attrs={'class': 'tag-title-wrapper'}) 20 # 小类 21 second_class = soup_list.findAll('table', attrs={'class': 'tagCol'}) 22 # 进一步提取 23 first_class_list = [] 24 for fc in first_class: 25 first_class_list.append(fc.attrs['name']) 26 num = 0 27 for sc in second_class: 28 second_class_list = [] 29 sc = sc.findAll('a') 30 for sc_i in sc: 31 second_class_list.append(sc_i.string.strip()) 32 category_list.append([first_class_list[num], second_class_list]) 33 num += 1 34 return category_list 35 36 37 # 书籍信息爬虫 38 def book_spider(book_tag, cookies): 39 headers = { 40 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3298.4 Safari/537.36' 41 } 42 books_list = [] 43 page_num = 0 44 url = 'https://book.douban.com/tag/' + urllib.parse.quote(book_tag) + '?start=' + str(page_num*20) + '&type=T' 45 res = requests.get(url, cookies=cookies, headers=headers) 46 soup = bs4.BeautifulSoup(res.text, 'html.parser') 47 # 找到一共有多少页 48 page_num_max = soup.find('div', attrs={'class': 'paginator'}) 49 page_num_max = page_num_max.findAll('a') 50 page_num_max = page_num_max[-2].string.strip() 51 page_num_max = int(page_num_max) 52 while True: 53 url = 'https://book.douban.com/tag/' + urllib.parse.quote(book_tag) + '?start=' + str(page_num*20) + '&type=T' 54 res = requests.get(url, cookies=cookies, headers=headers) 55 soup = bs4.BeautifulSoup(res.text, 'html.parser') 56 # 找到该页所有书 57 soup_list = soup.findAll('li', attrs={'class': 'subject-item'}) 58 for book_info in soup_list: 59 # 书名 60 title = book_info.find('a', attrs={'title': True}) 61 book_url = title.attrs['href'] 62 title = title.attrs['title'] 63 # 基本信息 64 basic_info = book_info.find('div', attrs={'class': 'pub'}).string.strip() 65 basic_info_list = basic_info.split('/') 66 try: 67 author_info = '/'.join(basic_info_list[0: -3]) 68 except: 69 author_info = '暂无' 70 try: 71 pub_info = '/'.join(basic_info_list[-3: ]) 72 except: 73 pub_info = '暂无' 74 # 评价方面的数据 75 evaluate_info = book_info.find('div', attrs={'class': 'star clearfix'}) 76 # 星级 77 try: 78 allstar = evaluate_info.find('span', attrs={'class': True}) 79 if (allstar.attrs['class'])[0][-1] == '1': 80 allstar = (allstar.attrs['class'])[0][-1] 81 else: 82 allstar = (allstar.attrs['class'])[0][-2] + '.' + (allstar.attrs['class'])[0][-1] 83 except: 84 allstar = '0.0' 85 # 评分 86 try: 87 rating_nums = evaluate_info.find('span', attrs={'class': 'rating_nums'}).string.strip() 88 except: 89 rating_nums = '0.0' 90 # 评价人数 91 try: 92 people_num = evaluate_info.find('span', attrs={'class': 'pl'}).string.strip() 93 people_num = people_num[1: -4] 94 except: 95 people_num = '0' 96 # 内容描述 97 try: 98 description = book_info.find('p').string.strip() 99 except: 100 description = '暂无' 101 # 信息整理 102 books_list.append([title, author_info, pub_info, allstar, rating_nums, people_num, description, book_url]) 103 print('第%d页信息采集完毕,共%d页' % (page_num+1, page_num_max)) 104 time.sleep(0.5) 105 page_num += 1 106 if page_num == page_num_max: 107 break 108 return books_list 109 110 111 # 结果保存到excel中 112 def save_to_excel(books_list, excel_name): 113 wb = Workbook() 114 ws = wb.active 115 ws.append(['序号', '书名', '作者/译者', '出版信息', '星级', '评分', '评价人数', '简介', '豆瓣链接']) 116 count = 1 117 for bl in books_list: 118 ws.append([count, bl[0], bl[1], bl[2], bl[3], bl[4], bl[5], bl[6], bl[7]]) 119 count += 1 120 wb.save('./results/' + excel_name + '.xlsx') 121 122 123 #数据处理 124 import pandas as pd 125 #读取数据 126 db_read = pd.read_excel("编程.xlsx",index_col=0) 127 #数据清理 128 #重复值的处理 129 titanic = titanic.drop_duplicates() 130 titanic.head() 131 132 #可视化 133 from matplotlib import pyplot as plt 134 #可视化 135 import seaborn as sns 136 #读取数据 137 db_read = pd.read_excel("编程.xlsx",index_col=0) 138 #查看数据信息 139 db_read.info() 140 #查看前五条数据 141 db_read.head() 142 143 #将整个数组以评分来排序 144 desc_data = db_read.sort_values(by="评分",ascending=False) 145 desc_data 146 147 #可视化 148 #评分主要分布区域 149 sns.distplot(db_read["评分"]) 150 151 #取出前一百条,体现星级分布 152 top_100 = desc_data.iloc[:100,:] 153 sns.catplot(x="星级",data = top_100,kind="count",height=10) 154 plt.xticks(rotation=90) 155 plt.show() 156 157 # 将书籍热门短评制作为词云 158 def Book_Blurb_wordcloud(url, cookies): 159 headers = { 160 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3298.4 Safari/537.36' 161 } 162 page_num = 0 163 hot_comment_list = [] 164 while True: 165 page_num += 1 166 url = url + 'comments/hot?p={}'.format(page_num) 167 res = requests.get(url, cookies=cookies, headers=headers) 168 soup = bs4.BeautifulSoup(res.text, 'html.parser') 169 # 找到该页所有短评 170 soup_list = soup.findAll('p', attrs={'class': 'comment-content'}) 171 for com in soup_list: 172 comment = com.string.strip() 173 hot_comment_list.append(comment) 174 print('第%d页短评采集完毕' % page_num) 175 if page_num > 19: 176 print('前20页短评全部采集完毕,开始制作词云') 177 break 178 all_comments = '' 179 for hc in hot_comment_list: 180 all_comments += hc 181 all_comments = filterword(all_comments) 182 words = ' '.join(jieba.cut(all_comments)) 183 # 这里设置字体路径 184 Words_Cloud = WordCloud(font_path="simkai.ttf").generate(words) 185 Words_Cloud.to_file('Book_Blurb.jpg') 186 187 188 # 短评情感分析 189 def emotion_analysis(url, cookies): 190 headers = { 191 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3298.4 Safari/537.36' 192 } 193 page_num = 0 194 hot_comment_list = [] 195 while True: 196 page_num += 1 197 url = url + 'comments/hot?p={}'.format(page_num) 198 res = requests.get(url, cookies=cookies, headers=headers) 199 soup = bs4.BeautifulSoup(res.text, 'html.parser') 200 # 找到该页所有短评 201 soup_list = soup.findAll('p', attrs={'class': 'comment-content'}) 202 for com in soup_list: 203 comment = com.string.strip() 204 hot_comment_list.append(comment) 205 print('第%d页短评采集完毕' % page_num) 206 if page_num > 19: 207 print('前20页短评全部采集完毕,开始情感分析') 208 break 209 marks_list = [] 210 for com in hot_comment_list: 211 mark = SnowNLP(com) 212 marks_list.append(mark.sentiments) 213 plt.hist(marks_list, bins=np.arange(0, 1, 0.02)) 214 plt.show() 215 216 #数据处理 217 import pandas as pd 218 #可视化 219 from matplotlib import pyplot as plt 220 #可视化 221 import seaborn as sns 222 import sklearn 223 from sklearn.linear_model import LinearRegression 224 #绘制回归图 225 boston_df=pd.read_excel('编程.xlsx',index_col=0) 226 boston_df.head()
五、总结
经过本次对豆瓣书籍的爬取及分析,了解到现在人们对书籍的类别需求,也体会到了社会发展带来的便利。
无论是纸质书还是电子书,多读书呀!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号