
一、简介
官网:https://shardingsphere.apache.org/index_zh.html
文档:https://shardingsphere.apache.org/document/legacy/4.x/document/cn/overview/
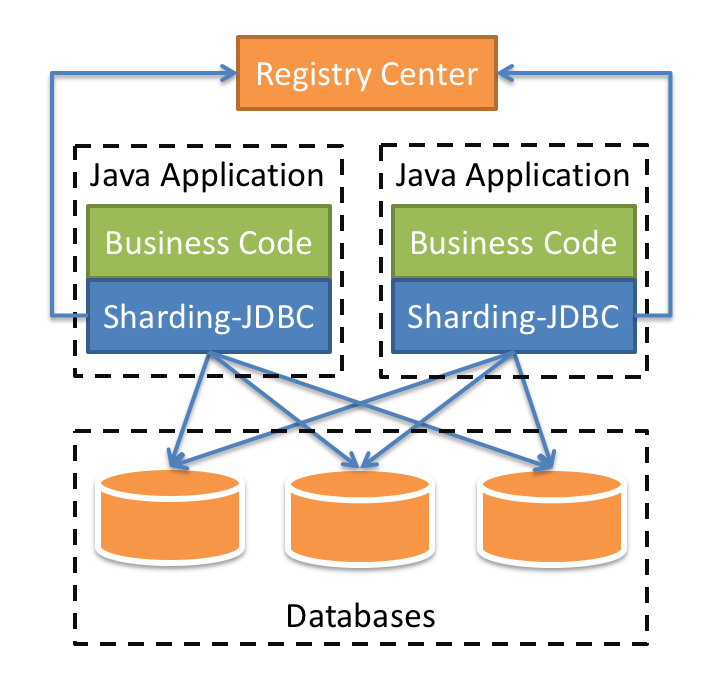
ShardingSphere-JDBC 是 Apache ShardingSphere 的第一个产品,也是 Apache ShardingSphere 的前身。 定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。 它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
- 适用于任何基于 JDBC 的 ORM 框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template 或直接使用 JDBC。
- 支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP 等。
- 支持任意实现 JDBC 规范的数据库,目前支持 MySQL,Oracle,SQLServer,PostgreSQL 以及任何遵循 SQL92 标准的数据库。
二、对比
| ShardingSphere-JDBC | ShardingSphere-Proxy | ShardingSphere-Sidecar | |
|---|---|---|---|
| 数据库 | 任意 |
MySQL/PostgreSQL | MySQL/PostgreSQL |
| 连接消耗数 | 高 |
低 | 高 |
| 异构语言 | 仅Java |
任意 | 任意 |
| 性能 | 损耗低 |
损耗略高 | 损耗低 |
| 无中心化 | 是 |
否 | 是 |
| 静态入口 | 无 |
有 | 无 |
ShardingSphere-JDBC 的优势在于对 Java 应用的友好度。
三、核心概念
逻辑表
水平拆分的数据库(表)的相同逻辑和数据结构表的总称。例:订单数据根据主键尾数拆分为 10 张表,分别是 t_order_0 到 t_order_9,他们的逻辑表名为 t_order。
真实表
在分片的数据库中真实存在的物理表。即上个示例中的 t_order_0 到 t_order_9。
数据节点
数据分片的最小单元。由数据源名称和数据表组成,例:ds_0.t_order_0。
绑定表
指分片规则一致的主表和子表。例如:t_order 表和 t_order_item 表,均按照 order_id 分片,则此两张表互为绑定表关系。绑定表之间的多表关联查询不会出现笛卡尔积关联,关联查询效率将大大提升。举例说明,如果 SQL 为:
SELECT i.* FROM t_order o JOIN t_order_item i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
在不配置绑定表关系时,假设分片键 order_id 将数值 10 路由至第 0 片,将数值 11 路由至第 1 片,那么路由后的 SQL 应该为 4 条,它们呈现为笛卡尔积:
SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_0 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
在配置绑定表关系后,路由的 SQL 应该为 2 条:
SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
其中 t_order 在 FROM 的最左侧,ShardingSphere 将会以它作为整个绑定表的主表。 所有路由计算将会只使用主表的策略,那么 t_order_item 表的分片计算将会使用 t_order 的条件。故绑定表之间的分区键要完全相同。
广播表
指所有的分片数据源中都存在的表,表结构和表中的数据在每个数据库中均完全一致。适用于数据量不大且需要与海量数据的表进行关联查询的场景,例如:字典表。
单表
指所有的分片数据源中只存在唯一一张的表。适用于数据量不大且不需要做任何分片操作的场景。
分片键
用于分片的数据库字段,是将数据库(表)水平拆分的关键字段。例:将订单表中的订单主键的尾数取模分片,则订单主键为分片字段。 SQL 中如果无分片字段,将执行全路由,性能较差。 除了对单分片字段的支持,Apache ShardingSphere 也支持根据多个字段进行分片。
分片算法
通过分片算法将数据分片,支持通过 =、>=、<=、>、<、BETWEEN 和 IN 分片。 分片算法需要应用方开发者自行实现,可实现的灵活度非常高。
目前提供 3 种分片算法。 由于分片算法和业务实现紧密相关,因此并未提供内置分片算法,而是通过分片策略将各种场景提炼出来,提供更高层级的抽象,并提供接口让应用开发者自行实现分片算法。
- 标准分片算法
对应 StandardShardingAlgorithm,用于处理使用单一键作为分片键的 =、IN、BETWEEN AND、>、<、>=、<= 进行分片的场景。需要配合 StandardShardingStrategy 使用。
- 复合分片算法
对应 ComplexKeysShardingAlgorithm,用于处理使用多键作为分片键进行分片的场景,包含多个分片键的逻辑较复杂,需要应用开发者自行处理其中的复杂度。需要配合 ComplexShardingStrategy 使用。
- Hint分片算法
对应 HintShardingAlgorithm,用于处理使用 Hint 行分片的场景。需要配合 HintShardingStrategy 使用。
分片策略
包含分片键和分片算法,由于分片算法的独立性,将其独立抽离。真正可用于分片操作的是分片键 + 分片算法,也就是分片策略。目前提供 4 种分片策略。
- 标准分片策略
对应 StandardShardingStrategy。提供对 SQL 语句中的 =, >, <, >=, <=, IN 和 BETWEEN AND 的分片操作支持。 StandardShardingStrategy 只支持单分片键,提供 PreciseShardingAlgorithm 和 RangeShardingAlgorithm 两个分片算法。 PreciseShardingAlgorithm 是必选的,用于处理 = 和 IN 的分片。 RangeShardingAlgorithm 是可选的,用于处理 BETWEEN AND, >, <, >=, <= 分片,如果不配置 RangeShardingAlgorithm,SQL 中的 BETWEEN AND 将按照全库路由处理。
- 复合分片策略
对应 ComplexShardingStrategy。复合分片策略。提供对 SQL 语句中的 =, >, <, >=, <=, IN 和 BETWEEN AND 的分片操作支持。 ComplexShardingStrategy 支持多分片键,由于多分片键之间的关系复杂,因此并未进行过多的封装,而是直接将分片键值组合以及分片操作符透传至分片算法,完全由应用开发者实现,提供最大的灵活度。
- Hint分片策略
对应 HintShardingStrategy。通过 Hint 指定分片值而非从 SQL 中提取分片值的方式进行分片的策略。
- 不分片策略
对应 NoneShardingStrategy。不分片的策略。
SQL Hint
对于分片字段非 SQL 决定,而由其他外置条件决定的场景,可使用 SQL Hint 灵活的注入分片字段。 例:内部系统,按照员工登录主键分库,而数据库中并无此字段。SQL Hint 支持通过 Java API 和 SQL 注释(待实现)两种方式使用。 详情请参见强制分片路由。
四、数据分片使用
1、在mysql中,新建2个数据库 test-shardingsphere1 与 test-shardingsphere2
1 CREATE TABLE IF NOT EXISTS t_order_0 (order_id BIGINT NOT NULL, user_id BIGINT NOT NULL, status VARCHAR(45) NULL, PRIMARY KEY (order_id)); 2 CREATE TABLE IF NOT EXISTS t_order_1 (order_id BIGINT NOT NULL, user_id BIGINT NOT NULL, status VARCHAR(45) NULL, PRIMARY KEY (order_id)); 3 CREATE TABLE IF NOT EXISTS t_order_item_0 (item_id BIGINT NOT NULL, order_id BIGINT NOT NULL, user_id BIGINT NOT NULL, status VARCHAR(45) NULL, PRIMARY KEY (item_id)); 4 CREATE TABLE IF NOT EXISTS t_order_item_1 (item_id INT BIGNOT NULL, order_id INT BIGNOT NULL, user_id BIGINT NOT NULL, status VARCHAR(45) NULL, PRIMARY KEY (item_id));
1 INSERT INTO t_order VALUES(1000, 10, 'init'); 2 INSERT INTO t_order VALUES(1001, 10, 'init'); 3 INSERT INTO t_order VALUES(1100, 11, 'init'); 4 INSERT INTO t_order VALUES(1101, 11, 'init'); 5 INSERT INTO t_order_item VALUES(100000, 1000, 10, 'init'); 6 INSERT INTO t_order_item VALUES(100001, 1000, 10, 'init'); 7 INSERT INTO t_order_item VALUES(100100, 1001, 10, 'init'); 8 INSERT INTO t_order_item VALUES(100101, 1001, 10, 'init'); 9 INSERT INTO t_order_item VALUES(110000, 1100, 11, 'init'); 10 INSERT INTO t_order_item VALUES(110001, 1100, 11, 'init'); 11 INSERT INTO t_order_item VALUES(110100, 1101, 11, 'init'); 12 INSERT INTO t_order_item VALUES(110101, 1101, 11, 'init');
2、新建maven项目,引入依赖
1 <?xml version="1.0" encoding="UTF-8"?> 2 <project xmlns="http://maven.apache.org/POM/4.0.0" 3 xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" 4 xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> 5 <modelVersion>4.0.0</modelVersion> 6 7 <groupId>com.test.sharding</groupId> 8 <artifactId>test-sharding-jdbc</artifactId> 9 <version>1.0-SNAPSHOT</version> 10 11 <properties> 12 <maven.compiler.source>8</maven.compiler.source> 13 <maven.compiler.target>8</maven.compiler.target> 14 </properties> 15 16 <dependencies> 17 <!-- shardingsphere-jdbc --> 18 <dependency> 19 <groupId>org.apache.shardingsphere</groupId> 20 <artifactId>shardingsphere-jdbc-core</artifactId> 21 <version>5.0.0-beta</version> 22 </dependency> 23 24 <!-- mysql --> 25 <dependency> 26 <groupId>mysql</groupId> 27 <artifactId>mysql-connector-java</artifactId> 28 <version>8.0.12</version> 29 </dependency> 30 31 32 <!-- 日志 --> 33 <dependency> 34 <groupId>org.slf4j</groupId> 35 <artifactId>slf4j-simple</artifactId> 36 <version>1.7.25</version> 37 <scope>compile</scope> 38 </dependency> 39 </dependencies> 40 41 </project>
3、Java代码如下:
1 /** 2 * 水平分库分表 3 */ 4 public class ShardingJDBCTest { 5 6 public static void main(String[] args) throws SQLException { 7 // ShardingJDBCTest.insert(); 8 ShardingJDBCTest.select(); 9 } 10 11 12 13 public static void insert() throws SQLException { 14 // 获取数据源 15 DataSource dataSource = getDataSource(); 16 17 String insertSql1 = "INSERT INTO t_order VALUES(1000, 10, 'init');"; 18 String insertSql2 = "INSERT INTO t_order VALUES(1001, 10, 'init');"; 19 String insertSql3 = "INSERT INTO t_order VALUES(1100, 11, 'init');"; 20 String insertSql4 = "INSERT INTO t_order VALUES(1101, 11, 'init');"; 21 22 try ( 23 Connection conn = dataSource.getConnection(); 24 PreparedStatement ps = conn.prepareStatement(insertSql3)) { 25 int num = ps.executeUpdate(); 26 System.out.println("num = " + num); 27 } 28 29 } 30 31 public static void select() throws SQLException { 32 // 获取数据源 33 DataSource dataSource = getDataSource(); 34 35 // String sql = "select * from t_order order"; 36 String sql = "select * from t_order order by user_id desc"; 37 // String sql = "select * from t_order order by order_id desc limit 2"; 38 39 try ( 40 Connection conn = dataSource.getConnection(); 41 PreparedStatement ps = conn.prepareStatement(sql)) { 42 try (ResultSet rs = ps.executeQuery()) { 43 while(rs.next()) { 44 int order_id = rs.getInt(1); 45 int user_id = rs.getInt(2); 46 String status = rs.getString(3); 47 System.out.println(order_id + "\t" + user_id + "\t" + status); 48 } 49 } 50 } 51 } 52 53 public static DataSource getDataSource() throws SQLException { 54 // 配置真实数据源 55 Map<String, DataSource> dataSourceMap = new HashMap<>(); 56 57 // 配置第 1 个数据源 58 HikariDataSource dataSource1 = new HikariDataSource(); 59 dataSource1.setDriverClassName("com.mysql.cj.jdbc.Driver"); 60 dataSource1.setJdbcUrl("jdbc:mysql://127.0.0.1:3306/test-shardingjdbc1?allowPublicKeyRetrieval=true&useSSL=true"); 61 dataSource1.setUsername("root"); 62 dataSource1.setPassword("123456"); 63 dataSourceMap.put("ds0", dataSource1); 64 65 // 配置第 2 个数据源 66 HikariDataSource dataSource2 = new HikariDataSource(); 67 dataSource2.setDriverClassName("com.mysql.cj.jdbc.Driver"); 68 dataSource2.setJdbcUrl("jdbc:mysql://127.0.0.1:3306/test-shardingjdbc2?allowPublicKeyRetrieval=true&useSSL=true"); 69 dataSource2.setUsername("root"); 70 dataSource2.setPassword("123456"); 71 dataSourceMap.put("ds1", dataSource2); 72 73 // 配置 t_order 表规则 74 ShardingTableRuleConfiguration orderTableRuleConfig = new ShardingTableRuleConfiguration("t_order", "ds${0..1}.t_order_${0..1}"); 75 76 // 配置分库策略 77 orderTableRuleConfig.setDatabaseShardingStrategy(new StandardShardingStrategyConfiguration("user_id", "dbShardingAlgorithm")); 78 79 // 配置分表策略 80 orderTableRuleConfig.setTableShardingStrategy(new StandardShardingStrategyConfiguration("order_id", "tableShardingAlgorithm")); 81 82 // 省略配置 t_order_item 表规则... 83 // ... 84 // ShardingTableRuleConfiguration itemTableRuleConfig = new ShardingTableRuleConfiguration("t_order_item", "ds${0..1}.t_order_item_${0..1}"); 85 // itemTableRuleConfig.setDatabaseShardingStrategy(new StandardShardingStrategyConfiguration("user_id", "dbShardingAlgorithm")); 86 // itemTableRuleConfig.setTableShardingStrategy(new StandardShardingStrategyConfiguration("order_id", "tableShardingAlgorithm")); 87 88 89 // 配置分片规则 90 ShardingRuleConfiguration shardingRuleConfig = new ShardingRuleConfiguration(); 91 shardingRuleConfig.getTables().add(orderTableRuleConfig); 92 93 // 配置分库算法 94 Properties dbShardingAlgorithmrProps = new Properties(); 95 dbShardingAlgorithmrProps.setProperty("algorithm-expression", "ds${user_id % 2}"); 96 shardingRuleConfig.getShardingAlgorithms().put("dbShardingAlgorithm", 97 new ShardingSphereAlgorithmConfiguration("INLINE", dbShardingAlgorithmrProps)); 98 99 // 配置分表算法 100 Properties tableShardingAlgorithmrProps = new Properties(); 101 tableShardingAlgorithmrProps.setProperty("algorithm-expression", "t_order${order_id % 2}"); 102 shardingRuleConfig.getShardingAlgorithms().put("tableShardingAlgorithm", 103 new ShardingSphereAlgorithmConfiguration("INLINE", tableShardingAlgorithmrProps)); 104 105 // 创建 ShardingSphereDataSource 106 DataSource dataSource = ShardingSphereDataSourceFactory.createDataSource(dataSourceMap, Collections.singleton(shardingRuleConfig), new Properties()); 107 108 return dataSource; 109 } 110 }
更多使用,请参考官网文档


 浙公网安备 33010602011771号
浙公网安备 33010602011771号