Hadoop 三种运行模式
Hadoop运行模式:本地模式、伪分布式模式以及完全分布式模式
本地运行模式
官方Grep案例
1.在/opt/hadoop-3.3.6文件夹下创建一个input的文件夹
[root@hadoop101 hadoop-3.3.6]# mkdir input
2.将hadoop的配置文件复制到input文件下下
[root@hadoop101 hadoop-3.3.6]# cp etc/hadoop/*.xml input
3.查看目录下有哪些案例jar
[root@hadoop101 mapreduce]# pwd
/opt/hadoop-3.3.6/share/hadoop/mapreduce
[root@hadoop101 mapreduce]# ll
total 5432
-rw-r--r--. 1 1000 1000 591026 Jun 18 2023 hadoop-mapreduce-client-app-3.3.6.jar
-rw-r--r--. 1 1000 1000 805775 Jun 18 2023 hadoop-mapreduce-client-common-3.3.6.jar
-rw-r--r--. 1 1000 1000 1773049 Jun 18 2023 hadoop-mapreduce-client-core-3.3.6.jar
-rw-r--r--. 1 1000 1000 181708 Jun 18 2023 hadoop-mapreduce-client-hs-3.3.6.jar
-rw-r--r--. 1 1000 1000 9969 Jun 18 2023 hadoop-mapreduce-client-hs-plugins-3.3.6.jar
-rw-r--r--. 1 1000 1000 49800 Jun 18 2023 hadoop-mapreduce-client-jobclient-3.3.6.jar
-rw-r--r--. 1 1000 1000 1660525 Jun 18 2023 hadoop-mapreduce-client-jobclient-3.3.6-tests.jar
-rw-r--r--. 1 1000 1000 90706 Jun 18 2023 hadoop-mapreduce-client-nativetask-3.3.6.jar
-rw-r--r--. 1 1000 1000 62096 Jun 18 2023 hadoop-mapreduce-client-shuffle-3.3.6.jar
-rw-r--r--. 1 1000 1000 22265 Jun 18 2023 hadoop-mapreduce-client-uploader-3.3.6.jar
-rw-r--r--. 1 1000 1000 281349 Jun 18 2023 hadoop-mapreduce-examples-3.3.6.jar
drwxr-xr-x. 2 1000 1000 4096 Jun 18 2023 jdiff
drwxr-xr-x. 2 1000 1000 35 Jun 18 2023 lib-examples
drwxr-xr-x. 2 1000 1000 4096 Jun 18 2023 sources
4.执行share目录下的MapReduce程序
[root@hadoop101 hadoop-3.3.6]# bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar grep input output 'dfs[a-z.]'
5.查看输出结果
[root@hadoop101 hadoop-3.3.6]# cat output/*
1 dfsadmin
官方WordCount案例
1.在/opt/hadoop-3.3.6文件夹下创建wcinput文件夹
[root@hadoop101 hadoop-3.3.6]# mkdir wcinput
2.在wcinput文件夹下创建wc.input文件
[root@hadoop101 hadoop-3.3.6]# cd wcinput/
[root@hadoop101 wcinput]# touch wc.input
3.编辑wc.input文件
[root@hadoop101 wcinput]# vi wc.input
输入以下内容
hadoop yarn
hadoop mapreduce
atguigu
atguigu
保存退出 :wq
4.回到目录 /opt/hadoop-3.3.6
[root@hadoop101 wcinput]# cd /opt/hadoop-3.3.6/
[root@hadoop101 hadoop-3.3.6]# pwd
/opt/hadoop-3.3.6
5.执行程序
[root@hadoop101 hadoop-3.3.6]# hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar wordcount wcinput/ wcoutput
6.查看结果
[root@hadoop101 hadoop-3.3.6]# cat wcoutput/part-r-00000
atguigu 2
hadoop 2
mapreduce 1
yarn 1
伪分布式模式
启动HDFS并运行
配置集群
配置 hadoop-env.sh
1.Linux系统中获取JDK的安装路径
[root@hadoop101 hadoop-3.3.6]# echo $JAVA_HOME
/opt/jdk1.8.0_381
2.添加JDK路径到hadoop-env.sh 配置文件中
#配置文件所在路径
[root@hadoop101 hadoop]# pwd
/opt/hadoop-3.3.6/etc/hadoop
[root@hadoop101 hadoop]# vi hadoop-env.sh
#修改JAVA_HOME 路径:
export JAVA_HOME=/opt/jdk1.8.0_381
配置 core-site.xml
#配置文件所在路径
[root@hadoop101 hadoop]# pwd
/opt/hadoop-3.3.6/etc/hadoop
[root@hadoop101 hadoop]# vi core-site.xml
添加以下内容到配置文件
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop101:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-3.3.6/data/tmp</value>
</property>
配置 hdfs-site.xml
#配置文件所在路径
[root@hadoop101 hadoop]# pwd
/opt/hadoop-3.3.6/etc/hadoop
[root@hadoop101 hadoop]# vi hdfs-site.xml
添加以下内容到配置文件
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
启动集群
格式化NameNode【第一次启动时格式化,以后就不要总格式化】
[root@hadoop101 hadoop-3.3.6]# pwd
/opt/hadoop-3.3.6
[root@hadoop101 hadoop-3.3.6]# bin/hdfs namenode -format
【为什么不要总格式化NameNode?】
格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到已往数据。所以,格式NameNode时,一定要先删除data数据和log日志,然后再格式化NameNode。
启动NameNode
[root@hadoop101 hadoop-3.3.6]# sbin/hadoop-daemon.sh start namenode
WARNING: Use of this script to start HDFS daemons is deprecated.
WARNING: Attempting to execute replacement "hdfs --daemon start" instead.
表示这种启动方式已经被废掉,更换新的启动方式
bin/hdfs --daemon start namenode
启动DataNode
[root@hadoop101 hadoop-3.3.6]# bin/hdfs --daemon start datanode
查看集群
查看是否启动成功
[root@hadoop101 hadoop-3.3.6]# jps
22789 Jps
22376 NameNode
22717 DataNode
web端查看HDFS系统
http://10.211.55.7:9870/dfshealth.html#tab-overview

查看产生的日志
[root@hadoop101 logs]# pwd
/opt/hadoop-3.3.6/logs
[root@hadoop101 logs]# ll
total 92
-rw-r--r--. 1 root root 38106 Mar 24 10:46 hadoop-root-datanode-hadoop101.log
-rw-r--r--. 1 root root 698 Mar 24 10:46 hadoop-root-datanode-hadoop101.out
-rw-r--r--. 1 root root 43266 Mar 24 10:46 hadoop-root-namenode-hadoop101.log
-rw-r--r--. 1 root root 698 Mar 24 10:41 hadoop-root-namenode-hadoop101.out
-rw-r--r--. 1 root root 0 Mar 24 10:40 SecurityAuth-root.audit
测试操作集群
在HDFS文件系统上创建一个input文件夹
[root@hadoop101 hadoop-3.3.6]# bin/hdfs dfs -mkdir -p /user/pablo/input
将测试文件内容上传到文件系统上
[root@hadoop101 hadoop-3.3.6]# bin/hdfs dfs -put wcinput/wc.input /user/pablo/input
查看文件是否上传正确
[root@hadoop101 hadoop-3.3.6]# bin/hdfs dfs -ls /user/pablo/input
Found 1 items
-rw-r--r-- 1 root supergroup 45 2024-03-24 11:24 /user/pablo/input/wc.input
[root@hadoop101 hadoop-3.3.6]# bin/hdfs dfs -cat /user/pablo/input/wc.input
hadoop yarn
hadoop mapreduce
atguigu
atguigu
运行MapReduce程序
[root@hadoop101 hadoop-3.3.6]# bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar wordcount /user/pablo/input/ /user/pablo/output
查看输出结果
[root@hadoop101 hadoop-3.3.6]# bin/hdfs dfs -cat /user/pablo/output/*
atguigu 2
hadoop 2
mapreduce 1
yarn 1
在web页面中进行查看
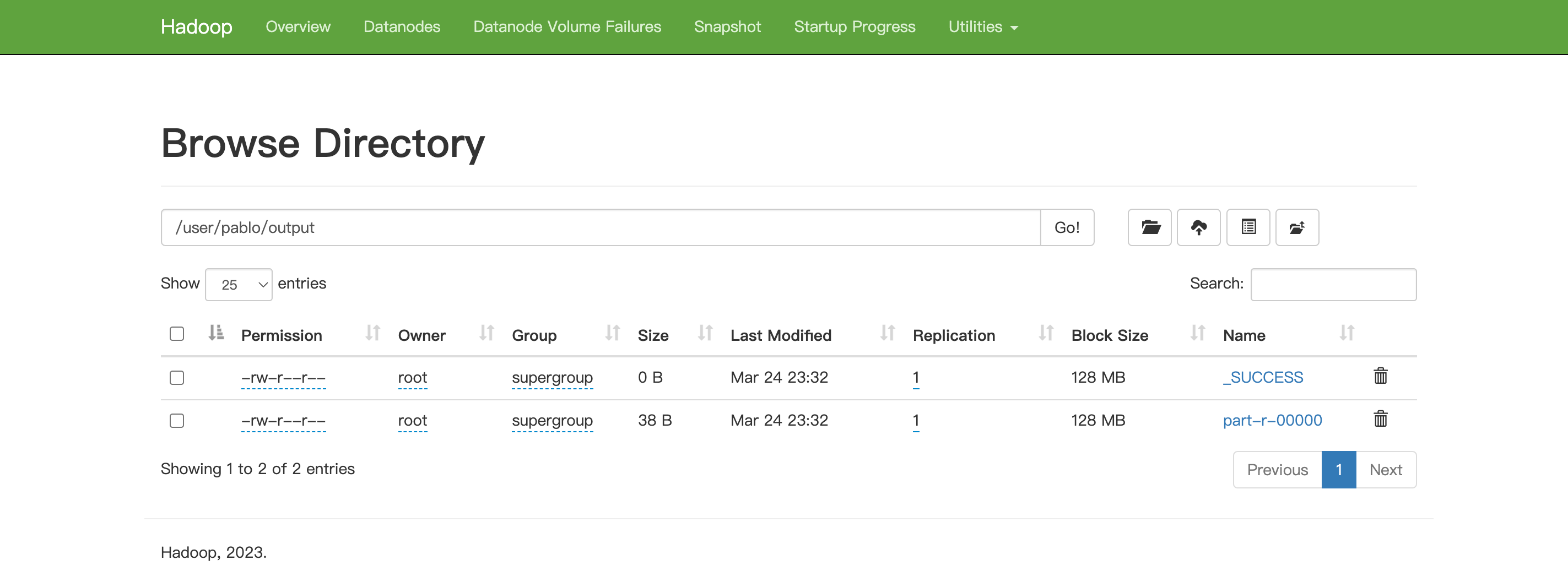
将测试文件内容下载到本地
[root@hadoop101 hadoop-3.3.6]# hdfs dfs -get /user/pablo/output/part-r-0000 ./wcoutput
删除输出结果
[root@hadoop101 hadoop-3.3.6]# hdfs dfs -rm -r /user/pablo/output
启动YARN并运行MapReduce
配置集群
配置yarn-env.sh
1.Linux系统中获取JDK的安装路径
[root@hadoop101 hadoop-3.3.6]# echo $JAVA_HOME
/opt/jdk1.8.0_381
2.添加JDK路径到hadoop-env.sh 配置文件中
#配置文件所在路径
[root@hadoop101 hadoop]# pwd
/opt/hadoop-3.3.6/etc/hadoop
[root@hadoop101 hadoop]# vi yarn-env.sh
#修改JAVA_HOME 路径:
export JAVA_HOME=/opt/jdk1.8.0_381
配置yarn-site.xml
<!-- Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop101</value>
</property>
<!--yarnweb http通讯地址 测试环境可以不用配置,服务器环境需要配置 否则不能访问web页面-->
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>0.0.0.0:8088</value>
</property>
配置mapred-env.sh
添加JAVA_HOME 到配置文件
export JAVA_HOME=/opt/jdk1.8.0_381
配置(对mapred-site.xml.template重新命名为) mapred-site.xml
重命名:mv mapred-site.xml.template mapred-site.xml
获取所有hadoop的类路径
[root@hadoop101 hadoop-3.3.6]# bin/hadoop classpath
/opt/hadoop-3.3.6/etc/hadoop:/opt/hadoop-3.3.6/share/hadoop/common/lib/*:/opt/hadoop-3.3.6/share/hadoop/common/*:/opt/hadoop-3.3.6/share/hadoop/hdfs:/opt/hadoop-3.3.6/share/hadoop/hdfs/lib/*:/opt/hadoop-3.3.6/share/hadoop/hdfs/*:/opt/hadoop-3.3.6/share/hadoop/mapreduce/*:/opt/hadoop-3.3.6/share/hadoop/yarn:/opt/hadoop-3.3.6/share/hadoop/yarn/lib/*:/opt/hadoop-3.3.6/share/hadoop/yarn/*
<!-- 指定MR运行在YARN上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/opt/hadoop-3.3.6</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>/opt/hadoop-3.3.6/etc/hadoop:/opt/hadoop-3.3.6/share/hadoop/common/lib/*:/opt/hadoop-3.3.6/share/hadoop/common/*:/opt/hadoop-3.3.6/share/hadoop/hdfs:/opt/hadoop-3.3.6/share/hadoop/hdfs/lib/*:/opt/hadoop-3.3.6/share/hadoop/hdfs/*:/opt/hadoop-3.3.6/share/hadoop/mapreduce/*:/opt/hadoop-3.3.6/share/hadoop/yarn:/opt/hadoop-3.3.6/share/hadoop/yarn/lib/*:/opt/hadoop-3.3.6/share/hadoop/yarn/*</value>
</property>
启动集群
启动前必须保证NameNode和DataNode已经启动
使用Jps命令查看是否已经启动
[root@hadoop101 hadoop]# jps
25185 Jps
22376 NameNode
22717 DataNode
启动ResourceManager
[root@hadoop101 hadoop-3.3.6]# bin/yarn --daemon start resourcemanager
启动NodeManager
[root@hadoop101 hadoop-3.3.6]# bin/yarn --daemon start nodemanager
Jps名称查看是否启动成功
[root@hadoop101 hadoop-3.3.6]# jps
25778 Jps
22376 NameNode
25676 NodeManager
22717 DataNode
25407 ResourceManager
测试操作集群
yarn的Web 页面访问
http://10.211.55.7:8088/cluster

删除文件系统上的output文件
[root@hadoop101 hadoop-3.3.6]# bin/hdfs dfs -rm -R /user/pablo/output
Deleted /user/pablo/output
执行MapReduce程序
[root@hadoop101 hadoop-3.3.6]# bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar wordcount /user/pablo/input /user/pablo/output
查看执行结果
[root@hadoop101 hadoop-3.3.6]# bin/hdfs dfs -cat /user/pablo/output/*
atguigu 2
hadoop 2
mapreduce 1
yarn 1
配置历史服务器
为了查看程序的历史运行情况,需要配置历史服务器。
配置mapred-site.xml
在该文件里面增加如下配置
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop101:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop101:19888</value>
</property>
启动历史服务器
[root@hadoop101 hadoop-3.3.6]# sbin/mr-jobhistory-daemon.sh start historyserver
WARNING: Use of this script to start the MR JobHistory daemon is deprecated.
WARNING: Attempting to execute replacement "mapred --daemon start" instead.
查看历史服务器是否启动
[root@hadoop101 hadoop-3.3.6]# jps
22376 NameNode
28312 JobHistoryServer
28377 Jps
25676 NodeManager
22717 DataNode
25407 ResourceManager
查看JobHistory
http://10.211.55.7:19888/jobhistory
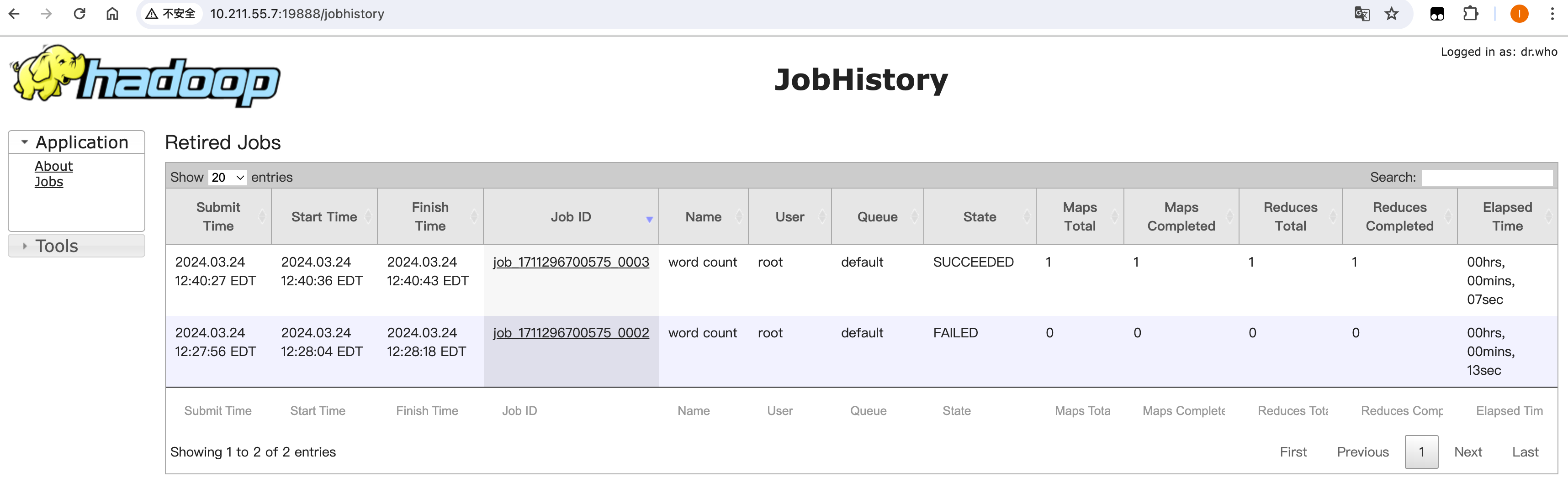
配置日志收集
日志聚集概念:应用运行完成以后,将程序运行日志信息上传到HDFS系统上。
日志聚集功能好处:可以方便的查看到程序运行详情,方便开发调试。
注意:开启日志聚集功能,需要重新启动NodeManager 、ResourceManager和HistoryManager。
配置yarn-site.xml
在该文件里面增加如下配置。
<!-- 日志聚集功能使能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 日志保留时间设置7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
关闭NodeManager 、ResourceManager和HistoryManager
[root@hadoop101 hadoop-3.3.6]# bin/yarn --daemon stop resourcemanager
[root@hadoop101 hadoop-3.3.6]# bin/yarn --daemon stop nodemanager
[root@hadoop101 hadoop-3.3.6]# bin/mapred --daemon stop historyserver
启动NodeManager 、ResourceManager和HistoryManager
[root@hadoop101 hadoop-3.3.6]# bin/yarn --daemon start resourcemanager
[root@hadoop101 hadoop-3.3.6]# bin/yarn --daemon start nodemanager
[root@hadoop101 hadoop-3.3.6]# bin/mapred --daemon start historyserver
删除HDFS上已经存在的输出文件
[root@hadoop101 hadoop-3.3.6]# bin/hdfs dfs -rm -R /user/pablo/output
Deleted /user/pablo/output
执行wordcount程序
[root@hadoop101 hadoop-3.3.6]# bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar wordcount /user/pablo/input /user/pablo/output
在web端查看日志
http://10.211.55.7:19888/jobhistory
JobHistory

运行情况:
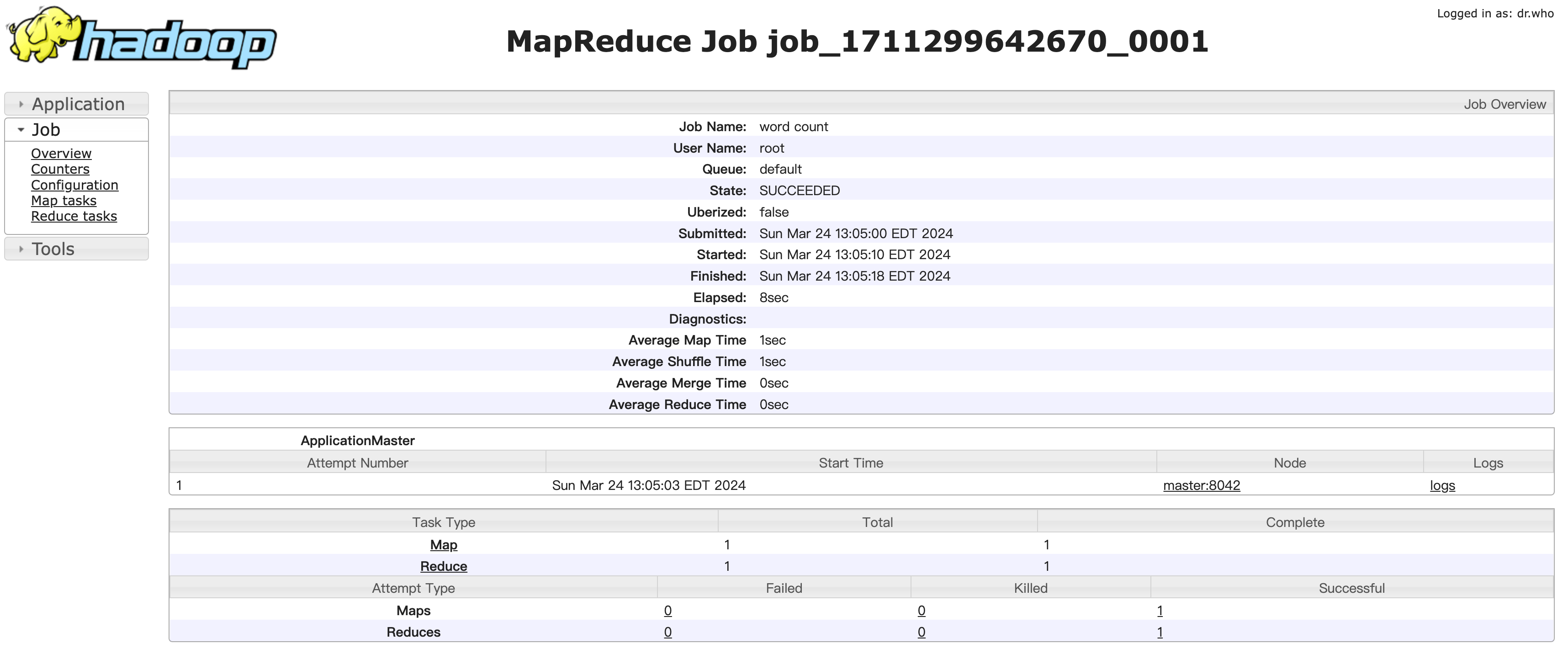
查看日志:
配置文件说明
Hadoop配置文件分两类:默认配置文件和自定义配置文件,只有用户想修改某一默认配置值时,才需要修改自定义配置文件,更改相应属性值。
默认配置文件
| 要获取的默认文件 | 文件存放在Hadoop的jar包中的位置 |
|---|---|
| core-default.xml | hadoop-common-3.3.6.jar/ core-default.xml |
| hdfs-default.xml | hadoop-hdfs--3.3.6.jar/ hdfs-default.xml |
| yarn-default.xml | hadoop-yarn-common-3.3.6.jar/ yarn-default.xml |
| mapred-default.xml | hadoop-mapreduce-client-core--3.3.6.jar/ mapred-default.xml |
自定义配置文件
core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml四个配置文件存放在$HADOOP_HOME/etc/hadoop这个路径上,用户可以根据项目需求重新进行修改配置。
完全分布式模式

 浙公网安备 33010602011771号
浙公网安备 33010602011771号