

【量化课堂】多因子策略入门
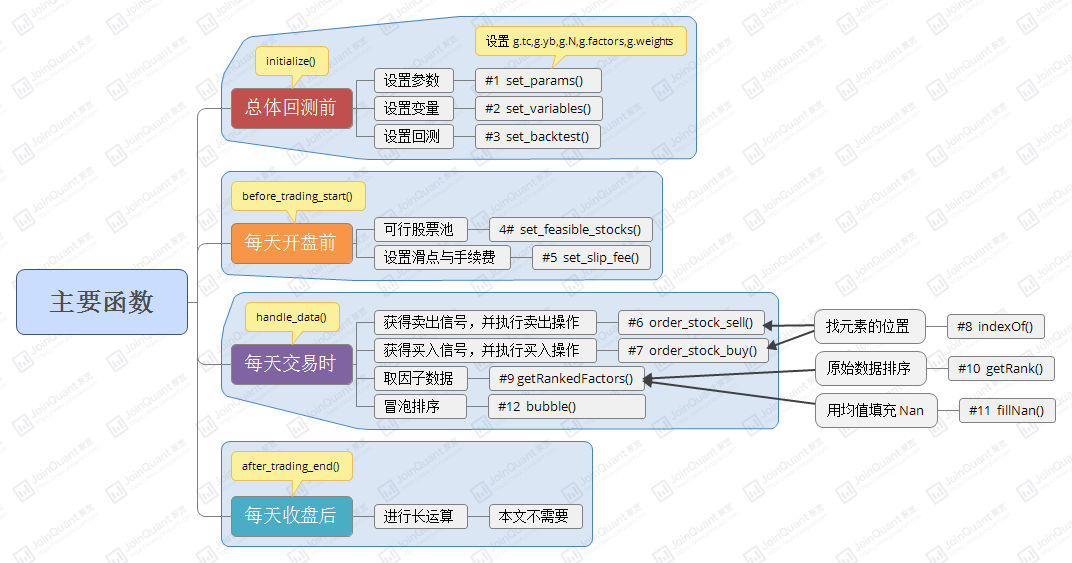
#多因子策略入门
# 2015-01-01 到 2016-03-08, ¥2000000, 每天
'''
================================================================================
总体回测前
================================================================================
'''
#总体回测前要做的事情
def initialize(context):
set_params() #1设置策参数
set_variables() #2设置中间变量
set_backtest() #3设置回测条件
#1
#设置策参数
def set_params():
g.tc=15 # 调仓频率
g.yb=63 # 样本长度
g.N=20 # 持仓数目
g.factors=["market_cap","roe"] # 用户选出来的因子
# 因子等权重里1表示因子值越小越好,-1表示因子值越大越好
g.weights=[[1],[-1]]
#2
#设置中间变量
def set_variables():
g.t=0 #记录回测运行的天数
g.if_trade=False #当天是否交易
#3
#设置回测条件
def set_backtest():
set_option('use_real_price', True)#用真实价格交易
log.set_level('order', 'error')
'''
================================================================================
每天开盘前
================================================================================
'''
#每天开盘前要做的事情
def before_trading_start(context):
if g.t%g.tc==0:
#每g.tc天,交易一次行
g.if_trade=True
# 设置手续费与手续费
set_slip_fee(context)
# 设置可行股票池:获得当前开盘的沪深300股票池并剔除当前或者计算样本期间停牌的股票
g.all_stocks = set_feasible_stocks(get_index_stocks('000300.XSHG'),g.yb,context)
# 查询所有财务因子
g.q = query(valuation,balance,cash_flow,income,indicator).filter(valuation.code.in_(g.all_stocks))
g.t+=1
#4
# 设置可行股票池
# 过滤掉当日停牌的股票,且筛选出前days天未停牌股票
# 输入:stock_list为list类型,样本天数days为int类型,context(见API)
# 输出:list
def set_feasible_stocks(stock_list,days,context):
# 得到是否停牌信息的dataframe,停牌的1,未停牌得0
suspened_info_df = get_price(list(stock_list), start_date=context.current_dt, end_date=context.current_dt, frequency='daily', fields='paused')['paused'].T
# 过滤停牌股票 返回dataframe
unsuspened_index = suspened_info_df.iloc[:,0]<1
# 得到当日未停牌股票的代码list:
unsuspened_stocks = suspened_info_df[unsuspened_index].index
# 进一步,筛选出前days天未曾停牌的股票list:
feasible_stocks=[]
current_data=get_current_data()
for stock in unsuspened_stocks:
if sum(attribute_history(stock, days, unit='1d',fields=('paused'),skip_paused=False))[0]==0:
feasible_stocks.append(stock)
return feasible_stocks
#5
# 根据不同的时间段设置滑点与手续费
def set_slip_fee(context):
# 将滑点设置为0
set_slippage(FixedSlippage(0))
# 根据不同的时间段设置手续费
dt=context.current_dt
log.info(type(context.current_dt))
if dt>datetime.datetime(2013,1, 1):
set_commission(PerTrade(buy_cost=0.0003, sell_cost=0.0013, min_cost=5))
elif dt>datetime.datetime(2011,1, 1):
set_commission(PerTrade(buy_cost=0.001, sell_cost=0.002, min_cost=5))
elif dt>datetime.datetime(2009,1, 1):
set_commission(PerTrade(buy_cost=0.002, sell_cost=0.003, min_cost=5))
else:
set_commission(PerTrade(buy_cost=0.003, sell_cost=0.004, min_cost=5))
'''
================================================================================
每天交易时
================================================================================
'''
def handle_data(context, data):
if g.if_trade==True:
# 计算现在的总资产,以分配资金,这里是等额权重分配
g.everyStock=context.portfolio.portfolio_value/g.N
# 获得今天日期的字符串
todayStr=str(context.current_dt)[0:10]
# 获得因子排序
a,b=getRankedFactors(g.factors,todayStr)
# 计算每个股票的得分
points=np.dot(a,g.weights)
# 复制股票代码
stock_sort=b[:]
# 对股票的得分进行排名
points,stock_sort=bubble(points,stock_sort)
# 取前N名的股票
toBuy=stock_sort[0:g.N].values
# 对于不需要持仓的股票,全仓卖出
order_stock_sell(context,data,toBuy)
# 对于不需要持仓的股票,按分配到的份额买入
order_stock_buy(context,data,toBuy)
g.if_trade=False
#6
#获得卖出信号,并执行卖出操作
#输入:context, data,toBuy-list
#输出:none
def order_stock_sell(context,data,toBuy):
#如果现有持仓股票不在股票池,清空
list_position=context.portfolio.positions.keys()
for stock in list_position:
if stock not in toBuy:
order_target(stock, 0)
#7
#获得买入信号,并执行买入操作
#输入:context, data,toBuy-list
#输出:none
def order_stock_buy(context,data,toBuy):
# 对于不需要持仓的股票,按分配到的份额买入
for i in range(0,len(g.all_stocks)):
if indexOf(g.all_stocks[i],toBuy)>-1:
order_target_value(g.all_stocks[i], g.everyStock)
#8
#查找一个元素在数组里面的位置,如果不存在,则返回-1
#输入:元素,对应数组
#输出:-1
def indexOf(e,a):
for i in range(0,len(a)):
if e==a[i]:
return i
return -1
#9
#取因子数据
#输入:f-全局通用的查询,d-str
#输出:因子数据,股票的代码-dataframe
def getRankedFactors(f,d):
# 获得股票的基本面数据,这个API里面有,g.q是一个全局通用的查询
df = get_fundamentals(g.q,d)
# 为了防止Python里面的浅复制现象,采用循环来定义二维数组
res = [([0] * len(f)) for i in range(len(df))]
# 把数据填充到刚才定义的数组里面
for i in range(0,len(df)):
for j in range(0,len(f)):
res[i][j]=df[f[j]][i]
# 用均值填充NaN值
fillNan(res)
# 将数据变成排名
getRank(res)
# 返回因子数据和股票的代码(这个是因为沪深300指数成分股一直在变,如果用未来的沪深300指数成分股在之前可能有一些股票还没上市)
return res,df['code']
#10
#把每列原始数据变成排序的数据
#输入:r-list
#输出:r-list
def getRank(r):
# 定义一个临时数组记住一开始的顺序
indexes=list(range(0,len(r)))
# 对每一列进行冒泡排序
for k in range(len(r[0])):
for i in range(len(r)):
for j in range(i):
if r[j][k] < r[i][k]:
# 交换所有的列以及用于记录一开始的顺序的数组
indexes[j], indexes[i] = indexes[i], indexes[j]
for l in range(len(r[0])):
r[j][l], r[i][l] = r[i][l], r[j][l]
# 将排序好的因子顺序变成排名
for i in range(len(r)):
r[i][k]=i+1
# 再进行一次冒泡排序恢复一开始的股票顺序
for i in range(len(r)):
for j in range(i):
if indexes[j] > indexes[i]:
indexes[j], indexes[i] = indexes[i], indexes[j]
for k in range(len(r[0])):
r[j][k], r[i][k] = r[i][k], r[j][k]
# 因为Python是引用传递,所以其实这个可以不用返回值也行,当然如果你想用另外一个变量来存储排序结果的话可以考虑返回值的方法
return r
#11
#用均值填充Nan
#输入:m-list
#输出:m-list
def fillNan(m):
# 计算出因子数据有多少行(行是不同的股票)
rows=len(m)
# 计算出因子数据有多少列(列是不同的因子)
columns=len(m[0])
# 这个循环是对每一列进行操作
for j in range(0,columns):
# 定义一个临时变量,用来存储每列加总的值
sum=0.0
# 定义一个临时变量,用来计算非NaN值的个数
count=0.0
# 计算非NaN值的总和和个数
for i in range(0,rows):
if not(isnan(m[i][j])):
sum+=m[i][j]
count+=1
# 计算平均值,为了防止全是NaN,如果当整列都是NaN的时候认为平均值是0
avg=sum/max(count,1)
for i in range(0,rows):
# 这个for循环是用来把NaN值填充为刚才计算出来的平均值的
if isnan(m[i][j]):
m[i][j]=avg
return m
#12
#定义一个冒泡排序的函数
#输入:numbers是股票的综合得分-list
#输出:indexes是股票列表-list
def bubble(numbers,indexes):
for i in range(len(numbers)):
for j in range(i):
if numbers[j][0] < numbers[i][0]:
# 在进行交换的时候同时交换得分以记录哪些股票得分比较高
numbers[j][0], numbers[i][0] = numbers[i][0], numbers[j][0]
indexes[j], indexes[i] = indexes[i], indexes[j]
return numbers,indexes
'''
================================================================================
每天收盘后
================================================================================
'''
# 每日收盘后要做的事情(本策略中不需要)
def after_trading_end(context):
return
来源聚宽文章:https://www.joinquant.com/post/1399
# 标题:【量化课堂】多因子策略入门
# 作者:JoinQuant量化课堂

 浙公网安备 33010602011771号
浙公网安备 33010602011771号