爬虫大作业
2018-04-28 00:13 linxj97 阅读(344) 评论(0) 收藏 举报1、爬取网站:17173
主要爬取单机游戏的排行以及点击量
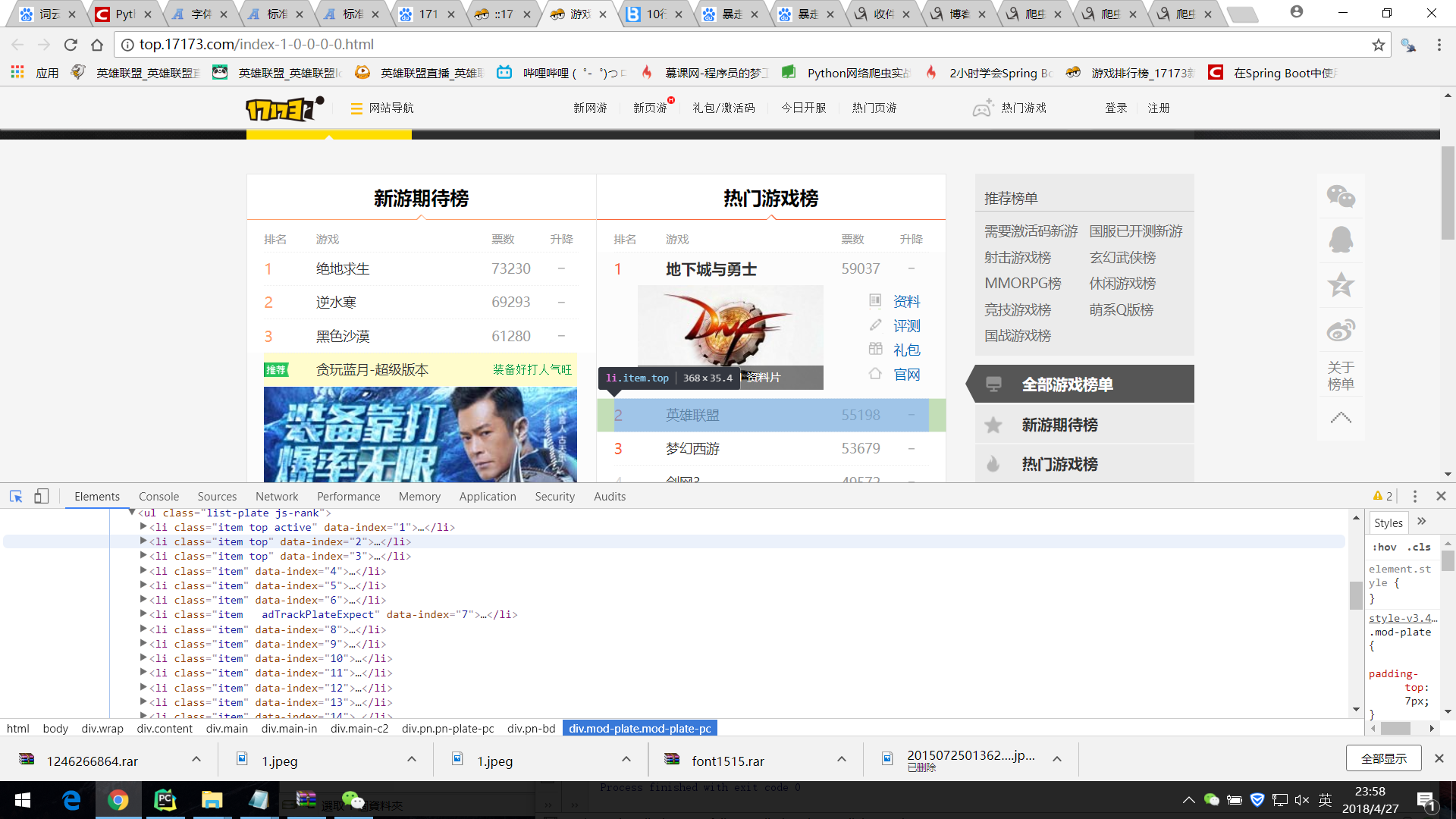
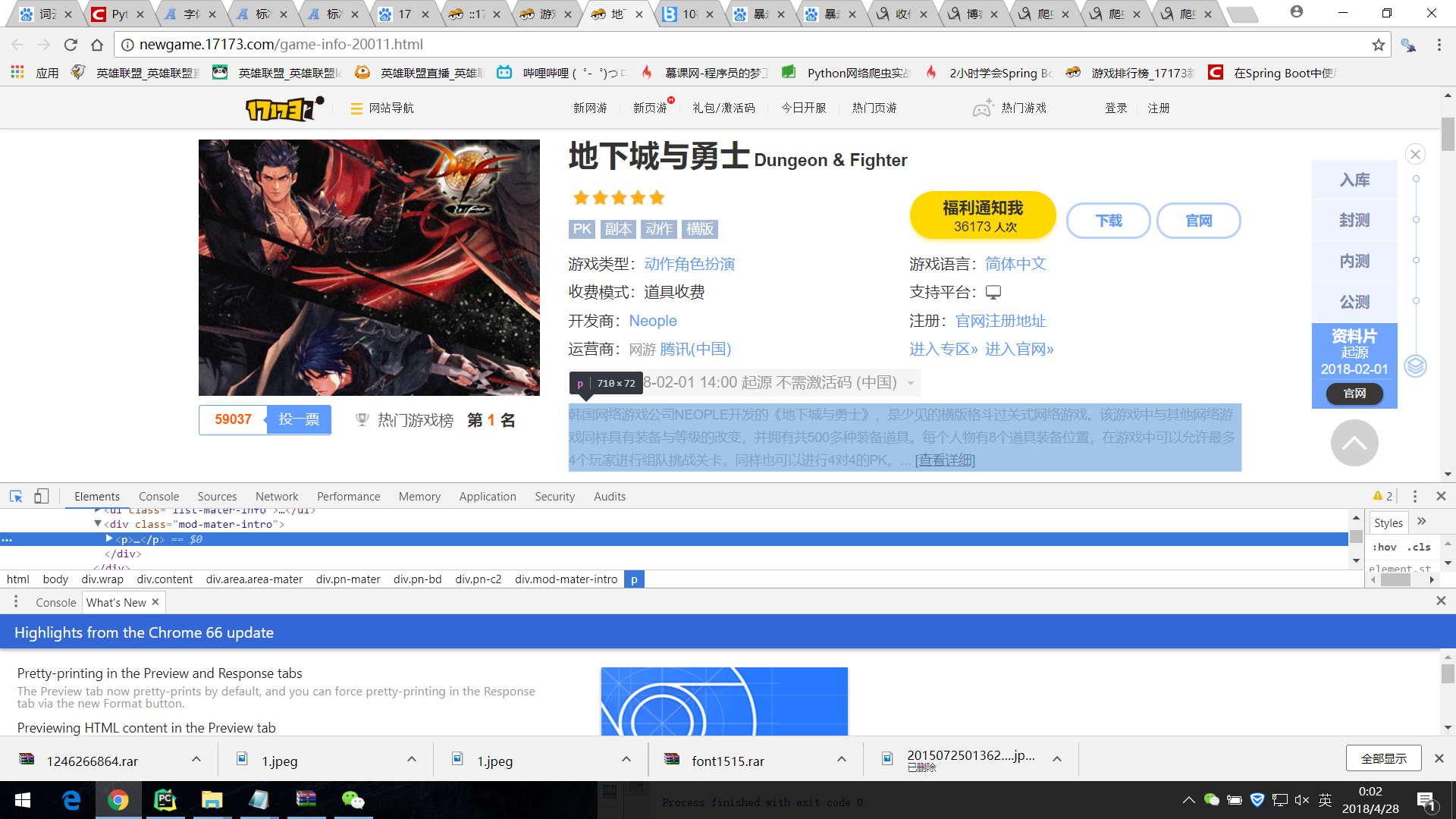
并且进入到每个游戏的链接中获取游戏的详细信息
2、代码
通过翻页判断出URLS
urls = ['http://top.17173.com/list-0-0-0-0-0-0-0-0-0-0-{}.html'.format(str(i)) for i in range(1, 37)]
通过循环找出每页每个游戏的href
def getallhref(urls):
x = 1
c = 1
for i in range(0, 36):
res = requests.get(urls[i])
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text, 'html.parser')
href = soup.select('.pn-plate-pc')
for href in href:
for vote in href.select('li'):
for vote in vote.select('div'):
for vote in vote.select('.c3'):
a[c]=vote.text.strip()
c=c+1
for href in href.select('.con'):
for href in href.select('a'):
print(href['href'])
print("下载量",a[x])
print('第', x, '名')
pageurl = href['href']
name=getmessage(pageurl)
b=a[x]
f = open('game.txt', 'a')
f.write(name + ' '+ b+ '\n')
f.close()
x = x + 1
# for head in href:
# print('N!!')
# for href in href.select('div'):
# print('投票数:',href.text)
return
再写出爬取游戏详细信息的函数
def getmessage(url):
res = requests.get(url)
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text, 'html.parser')
# 游戏名
gamename = soup.select('.mod-mater-name')
# 简介
intro = soup.select(' .mod-mater-intro')
for gamename in gamename:
name=gamename.text
print(gamename.text.strip())
for intro in intro:
if intro.text.find('...')>0:
for intro in intro.select('#tmpl-game-intro-detail'):
print(intro.text.strip().split())
else:
for intro in intro.select('p'):
print(intro.text.strip().split())
# info = intro.text
# print(intro.text.split())
return name
3、生成词云
import jieba
import matplotlib.pyplot as plt
from wordcloud import WordCloud, ImageColorGenerator
import numpy as np
from PIL import Image
import re
#读取txt
f=open('hhh.txt','r',encoding='utf-8')
#背景图片
image = np.array(Image.open('./1.jpeg'))
#字体路径
font=r'C:\Windows\Fonts\simkai.ttf'
word=f.read()
resultword = re.sub("[A-Za-z0-9\[\`\~\!\@\#\$\^\&\*\(\)\=\|\{\}\'\:\;\'\,\[\]\.\<\>\/\?\~\!\@\#\\\&\*\%]", "", word)
wordlist_after_jieba = jieba.cut(resultword, cut_all=True)
wl_space_split = " ".join(wordlist_after_jieba)
wordcloud=WordCloud( background_color="white",font_path=font,mask=image,width=1000,height=860,margin=2)\
.generate(wl_space_split)
# 根据图片生成词云
iamge_colors = ImageColorGenerator(image)
wordcloud.recolor(color_func=iamge_colors)
#显示生成的词云
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
wordcloud.to_file('5.jpeg')
背景图片

生成的词云图片

4、问题总结
在爬取下载量时无法从游戏详细页面获取,只能通过首页获取

 浙公网安备 33010602011771号
浙公网安备 33010602011771号