分布式账本存储
1、概述
超级账本采用背书/共识(Endorsement/Consensus)模型,模拟执行和区块验证是在不同角色结点中分开执行的,模拟执行交易是并发的,这可以提高扩展性和吞吐量
- 在背书结点
(Endorsement Peer)出模拟执行链码(Chaincode) - 在所有的
Peer结点验证交易并提交到账本
每个Peer结点会维护多个账本,账本包含以下元素
- 账本编号:快速查询存在哪些账本
- 账本数据:实际的区块数据存储
- 区块索引:快速查询区块/交易
- 状态数据:最新的世界状态数据
- 历史数据:跟踪键的历史
每个Peer结点会维护4个DB,分别是:
idStore:存储chainIDstateDB:存储world statehistoryDB:存储key的版本变化blockIndex:存储block索引
2、读写集
交易模拟和读写集
在背书结点(Endorser)模拟执行交易的过程中,会生成读写集(Read-Write Set)。读集(Read Set)包含了唯一键的列表,还有在模拟执行过程中交易读取的已提交键值。写集(Write Set)也包含了唯一键列表,还有在模拟执行过程中写的键值。交易过程中有删除键,他会记录删除标记。如果在一个交易中对一个键进行了多次更新,则会以最后一个为准。交易只会读取已经提交的数据,即使在交易中更新了某个键的值,但是没有提交也不能读取,就是说不支持读取本次交易更新后的结果。
读集会包含键的版本,写集只会包含键的最新值。版本号是每个键不重复的唯一标识。在目前的版本中,版本号是根据区块链的高度来实现的,一个交易中所有简直修改的版本号是相同的。高度是一个二元组Height(blockNumber,txNumber),其中blockNumber是区块号,txNumber是区块内的交易编号。以下是一个读写集的示例,为了描述简单,版本号使用数字来表示
<TxReadWriteSet>
<NsReadWriteSet name="chaincode1">
<read-set>
<read key="K1" version="1"/>
<read key="K2" version="1"/>
</read-set>
<write-set>
<write key="K1" value="V1"/>
<write key="K3" value="V2"/>
<write key="K4" isDelete="true"/>
</write-set>
</NsReadWriteSet>
</TxReadWriteSet>
如果交易过程中有范围查询,那么范围查询及其结果都会添加到读写集中,他们用query-info来表示
交易验证和世界状态更新
提交结点根据读写集中的读集来验证交易,根据写集来更新键的版本和值
验证交易合法性的时候,首先会检查读集的版本号,比较在交易中读集里的每个键的版本号是否和世界状态(world state)键的版本号一致。然后如果读写集包含了范围查询(query-info),则会检查query-info包含的键是否有变化,比如新增键,更新或者删除键,要比较在模拟阶段进行范围查询的结果是否和验证阶段范围查询的结果是一致的。通过了这个检查以后,提交结点会根据写集来更新世界状态。遍历写集中的每个键,更新世界状态里对应的键值和版本号
模拟和验证示例
假设有5个交易T1、T2、T3、T4、T5,用三元组来表示他们(key,version,value),他们都基于同一个世界状态的快照进行模拟,下面的片段说明的是每个交易的读写集的操作:
世界状态:(k1,1,v1),(k2,1,v2),(k3,1,v3),(k4,1,v4),(k5,1,v5)
T1 -> Write(k1,v1'), Write(k2,v2')
T2 -> Read(k1), Write(k3,v3')
T3 -> Write(k2,v2'')
T4 -> Write(k2,v2'''), Read(k2)
T5 -> Write(k6,v6') ,Read(k5)
假设交易按照T1--T5进行排序,检查结果如下:
T1检查通过,因为在这个交易里面没有任何读操作,交易会更新键k1和k2,更新后世界状态里的三元组为(k1,2,v1')和(k2,2,v2')T2检查失败,因为交易需要读取的键k1在前面一个交易T1中被修改了T3检查通过,因为这个交易里面没有任何读取操作,更新后世界状态的三元组为(k2,3,v2'')T4检查失败,因为交易需要读取的键k2在前面一个交易T1中被修改了,不是在交易T3中修改的,因为交易T3验证失败了T5检查通过,因为这个交易需要读取的键k5在前面的交易中没有修改
3、账本编号
超级账本支持多账本,每个账本的数据是分开存储的。账本编号(LedgerID)的数据存储在LevelDB数据库中,只是记录了有哪些账本,创建新的账本会检查是否有相同的账本编号存在,这保证了全局唯一性,账本编号库并不存储与区块相关的数据,这和后面的区块索引不相同。
4、账本数据
账本数据(Ledger)是以二进制文件的形式存储的,每个账本数据存储在不同的目录下面,后面的内容都是已经区分了账本的情况再对数据进行查询的。基于文件系统的区块存储实现了如下功能接口:
- 账本存储管理
- 提交区块到账本
(AddBlock) - 获取区块链信息
(GetBlockchainInfo) - 获取区块数据
(RetriveBlocks) - 关闭区块存储
(Shutdown)
- 提交区块到账本
- 索引管理:跟踪区块和交易保存在哪个文件
- 根据哈希值获取区块
(RetriveBlockByHash) - 根据区块编号获取区块
(RetriveBlocByNumber) - 根据交易编号获取交易
(RetriveTxByID) - 根据区块编号和交易编号获取交易
(RetriveTxByBlockNumTranNum) - 根据交易编号获取区块
(RetriveBlockByTxID) - 根据交易编号获取交易验证码
(RetriveTxValidationCodeByTxID)
- 根据哈希值获取区块
账本数据的所有操作都是通过区块文件管理器(blockfileMgr)实现的,定义如下:
type blockfileMgr struct{
rootDir string // 区块链中区块存储的根目录
conf *Conf // 配置信息
db *leveldbhelper.DBHandle // 数据库指针
index index // 区块索引接口
cpInfo *checkpointInfo // 区块检查点信息
cpInfoCond *sync.Cond // 条件变量
currentFileWrite *blockfileWriter // 当前写入区块文件的指针
bcInfo atomic.Value // 区块链信息
}
区块文件管理器实现的功能分为几类
- 账本数据存储管理
- 确定文件存储在哪个目录
- 确定区块存储在哪个文件
- 检查点管理:跟踪最新持久化存储的文件
- 索引管理:跟踪区块和交易保存哪个文件
账本数据存储
区块文件管理器穿件的文件名以blockfile_为前缀,6位数字为后缀,后缀是从小到大连续的数字,中间不能有缺失,区块文件大小上限为64MB,一个账本嫩保存的最大数据量大概有61TB
记账结点(Committer)负责维护结点本地的账本,通过Gossip模块从排序服务接收到区块以后,区块添加到账本的过程如下图所示:
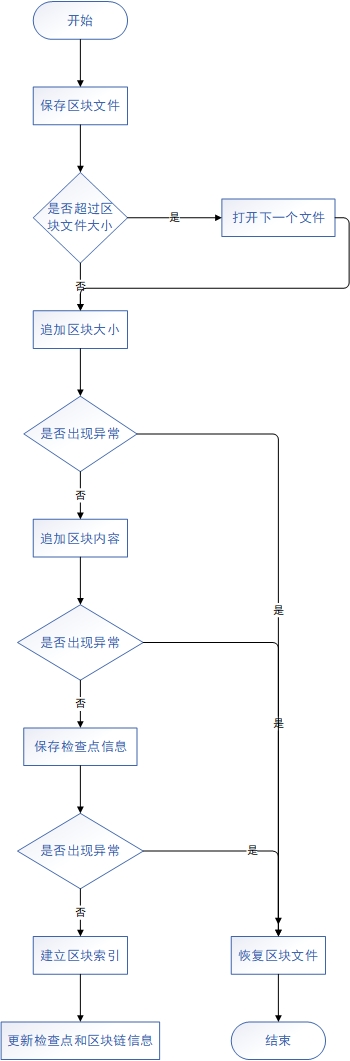
区块文件管理器维护一个当前写入区块文件的指针currentFileWriter,写入区块文件包括两个部分,一个是区块大小,一个是区块数据,写入文件的区块大小和数据都是经过序列化处理的,如果写入数据的大小超过当前区块文件的大小设定值,则会写入到下一个区块文件中,然后创建一个新的区块检查点信息,保存到数据库中。
如果写入区块文件和保存区块检查点信息的过程出现任何异常,就会根据区块检查点记录的最新区块文件偏移latestFileChunksize,恢复区块文件到写入前的状态。多个区块数据保存到区块文件后,区块文件形成了一个非结构化的二进制文件,它需要在区块文件外记录索引信息,才能快速定位到区块。保存区块数据后会建立这个区块的索引,并保存到数据库中,最后更新区块链文件管理器维护的区块检查点信息和区块链信息。
账本数据读取
区块文件流(blockfileStream)和区块流(blockStream)是以数据流的方式从区块文件系统中读取区块的,区块文件流是从单个文件中读取的,区块流可以跨文件读取,实际的文件读取通过区块文件流实现,区块流维护了当前区块文件流指针,还有当前区块文件的编号,定义如下:
type blockStream struct{
rootDir string // 区块链中区块存储的根目录
currentFileNum int // 当前读取文件区块的编号
endFileNum int // 结束读取文件区块的编号
currentFileStream *blockfileStream // 当前区块文件流指针
}
可以有多个区块流同时读取区块文件以获取区块数据,读取从区块文件currentFileNum的某个偏移开始,到endFileNum之间的所有区块,当endFileNum小于0的时候表示读取后续的所有区块
跟区块存储的过程类似,读取区块的时候需要首先读取区块数据的大小,再读取区块本身。区块迭代器(blockItr)基于区块流,实现了获取区块数据(RetriveBlocks)的接口,如果需要获取的区块编号还没有生成,迭代器会一直等待,直到获取了指定的区块或者迭代器关闭。
交易模拟执行
链码是可以并行执行的,执行的过程并不会影响当前的状态数据库。实现的方法是在最新的账本上生成一个账本数据的模拟器,模拟执行过程中生成的数据会写入模拟器的writeMap中,读取的数据写入到readMap中,最后再根据writeMap和readMap生成TxRwSet结果。每次链码执行的时候都会生成一个新的模拟器,所以多个链码并行执行并不会相互影响,模拟执行的结果也不会影响当前的状态数据库,生成的TxRwSet在提交交易的时候只有验证通过以后才会记录到账本中。
5、区块索引
超级账本提供多种区块索引(Block Index)方式,以便能够快速找到区块,这些方式包括:
- 区块编号
- 区块哈希
- 交易编号
- 同时按区块编号和交易编号
- 区块交易编号
- 交易验证码
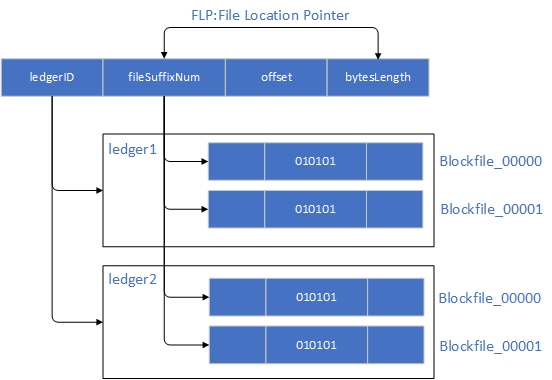
文件位置指针
索引的内容是文件位置指针(File Location Pointer) ,位置指针的结构如下所示:
type fileLocPointer struct{
fileSuffixNum int
locPointer
}
type locPointer struct{
offset int
bytesLength int
}
文件位置指针由三个部分组成:
- 所在文件的编号:
fileSuffixNum - 文件内的偏移量:
offset - 区块占用的字节数:
bytesLength
区块查找是一个三级索引过程:
- 查找一个区块首先就是确定是哪个链
- 然后根据文件编号找到对应的文件
- 再根据文件的偏移量和占用的字节数确定区块的内容
如下图所示:
文件位置指针序列化后保存到LevelDB中,不同的索引方式对应的键如下表所示:
| 索引类型 | 键的组成(转换成[]byte) |
|---|---|
| 区块编号 | n+blockNum |
| 区块哈希 | h+blockHash |
| 交易编号 | t+txID |
| 同时按区块编号和交易编号 | a+blockNum+txNum |
| 区块交易编号 | b+txID |
| 交易验证码 | v+txID |
构建哪些索引类型是可配置的,默认所有类型都建立索引(排序服务也会建立索引,但只有区块编号这种索引类型),有两种途径可以建立索引:
- 提交区块
(Commt Block) - 同步索引
(Sync Index)
索引的同步过程
索引同步只在创建区块文件管理器(blockMgr)的时候执行,验证数据库里保存的索引是否和区块文件系统里的一致
数据库记录了两个检查点信息:
- 索引检查点信息
(indexCheckpointKey) - 区块检查点信息
(blkMgrInfo)
索引检查点信息记录的是最后建立索引的区块编号。通过索引检查点信息的区块编号可以查询到区块编号对应的文件位置指针,它代表了数据库中记录的最新状态,这个状态由于系统异常等原因可能和区块文件系统存储的不一致。
区块检查点信息记录的是已提交到账本的区块信息,数据结构如下:
type checkpointInfo struct{
latestFileChunkSufficNum int // 最新区块的文件编号
latestFileChunksize int // 最新区块的文件偏移
isChainEmpty bool // 是否为空链
lastBlockNumber uint64 // 最新的区块编号
}
区块检查点信息记录的是区块文件系统的一个状态,可能和索引检查点信息记录的数据库状态的区块编号不一致,也可能和区块文件系统不一致,区块检查点信息记录过程如下:
- 先提交区块到区块文件系统
- 记录区块检查点信息
- 记录索引检查点信息
所以区块文件系统的信息是最完整的,可以通过区块文件系统同步区块检查点信息和索引检查点信息,而索引同步可以从检查点记录的状态开始,更新为区块文件系统的最新状态,减少同步时间。
区块文件管理器在创建的时候会从数据库中获取区块检查点信息,并且需要和区块文件系统对比检查其是否问最新的状态,检查过程基于区块检查点的文件编号和文件内由偏移构建的一个区块文件流(blockfileStream),从这个偏移开始验证该文件是否还有区块数据,如果确实还有区块,找到该文件实际存储的最大区块编号,更新区块检查点信息。这里使用的是区块文件流,它只会检查单个文件。这可能会存在一个特殊情况,就是上一个区块刚好写满这个文件,达到了上限,这个区块从下一个文件开始写,写完区块数据以后,更新区块检查点信息的时候出现异常,这时会导致区块检查点信息记录和区块文件系统的永久性不一致。
经过上面的检查以后,区块检查点信息就和区块文件系统完全一致了,根据区块检查点信息,构建区块流,从索引检查点信息记录的区块文件和偏移开始,到区块检查点记录的最新区块的文件编号为止全部重新构建索引,并更新索引检查点信息。
6、状态数据
状态数据(State Database)记录的是交易执行的结果,最新的状态代表了通道(channel)上所有键的最新值,所以又被称为世界状态。链码调用根据当前世界状态数据执行交易。为了提高链码执行的效率,所有键的最新值都存储在状态数据库中。状态数据库只是区块链交易日志中的索引视图,因此可以随时根据区块链重新生成。状态数据库在Peer结点启动时自动恢复,重新构建完成后才接受新的交易。状态数据库目前支持LevelDB和CouchDB
LevelDB(默认的KV数据库):支持键的查询,组合键的查询,范围键的查询CouchDB(可选):支持键的查询,组合键的查询,复杂查询
不同账本的状态数据库存放在不同的目录下,同一个账本的数据存放在一起,不同链码的数据按链码编号(chaincodeID)作为命名空间(namespace)划分数据,命名空间在组合键的时候作为组合键的前缀,分隔符可以自定义,默认分隔符是0x00
状态数据库的基本操作是基于键值对管理的,一个键值对是一个三元组(key,version,value)存储和读取数据都是版本化的。读取状态数据的时候不能指定版本,读取到的就是最新版本的。返回的数据包含版本和数据两个部分。版本的实现有区块编号和交易编号组成的二元组,数据结构如下:
type VersionedValue struct{
Value []byte // 数据
Version *version.Height // 版本
}
type Height struct{
BlockNum uint64 // 区块编号
TxNum uint64 // 交易编号
}
区块数据的读取通过键来查询,有三种方式:查询单个键的数据、查询多个键的数据、查询一个范围内的数据。如果是采用的是CouchDB数据库还支持某些字段的条件查询。
结点验证完数据以后会批量更新,以同时包含不同链码上的数据,用链码编号(chaincodeID)作为命名空间分割。相同链码的数据是由不同键值对组成的字典(map),批量更新的数据各自有不同的版本,在更新同一批数据的同时会更新世界状态的高度。
状态数据库支持如下的功能:
- 根据命名空间和键获取状态数据
- 获取单个键的数据:
GetState - 获取多个键的数据:
GetStateMultipleKeys - 获取一个范围内的查询数据:
GetStateRangeScanIterator
- 获取单个键的数据:
- 根据条偶见查询获取数据:
ExecuteQuery - 更新状态数据:
ApplyUpdates,可批量更新 - 获取最新交易高度:
GetLatestSavePoint - 数据库操作:
- 打开数据库:
Open - 关闭数据库:
Close
- 打开数据库:
基于状态数据的区块验证
区块数据提交到账本前,会基于状态数据验证区块数据是否有效。区块验证之前会从区块中解析出有效载荷,根据不同的类型分别进行验证,目前主要分为背书交易区块和配置交易区块
在背书交易区块验证中,主要验证读写集,从ChaincodeAction中解析出读写集TxRwSet,验证读取的版本是否和状态数据库里的版本一致。如果读写集中还有范围查询,还会验证范围查询中每个记录是否和状态数据库中的版本一致。通过验证的交易,其读写集会添加到UpdateBatch中,同一个区块的交易还会验证是否读取UpdateBatch中的记录,因为UpdateBatch中的数据是当前区块更新的数据,读取还没有提交到账本中的数据会验证失败。
区块提交到账本以后,要从区块数据中恢复状态数据和历史数据,就不会再对读写集进行版本检查了。
交易验证过程实现了一个验证字节图,每个交易占用一个字节,并标识其状态,定义如下:
type TxValidationFlags []uint8
验证后的字节位图会存放在Metadata中。验证成功的背书交易区块会生成读写集。
基于版本验证
比较状态数据库中保存的版本和交易记录里面读取的版本是否一致,一致就通过验证,不一致就验证失败。
基于范围查询的验证
比较范围查询的结果是否和在最新状态数据基础上更新本次交易数据后的模拟状态数据一致
- 基于默克尔数计算哈希值比较
- 基于范围查询结果的查询
7、历史数据
历史数据(History Database)记录了每个状态数据的历史信息,历史信息保存在LevelDB中,每个历史信息用一个四元组(namespace,writeKey,blockNo,tranNo)表示
namespace:实际表示的是不同的chaincodeID,不同的chaincode是逻辑分离的writeKey:要写入数据的键blockNo:要写入数据所在的区块编号tranNo:要写入数据所在区块内的交易序号,从0开始
历史信息记录的最细粒度就是交易,如果在一个交易中多次对同一个writeKey更新数据,以第一个数据为准(与更新世界状态相反),更新区块的历史信息的时候会同步更新检查点信息,保存的内容是最新的区块高度和最大的交易序号,检查点信息用来判断历史信息的状态是否是最新的。
8、数据恢复
区块的提交过程分为3个步骤:
- 先保存区块到文件存储的账本数据中
- 然后更新状态数据
- 最后更新历史信息数据
上面3个步骤是顺序执行的,如果某个过程出现了异常,就会根据账本记录的区块信息和状态数据、历史信息数据的检查点信息进行比较,重新提交检查点之后的区块信息,保持账本的一致性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号