
机器学习之归一化和标准化总结
一般做机器学习应用的时候大部分时间是花费在特征处理上,其中很关键的一步就是对特征数据进行归一化,为什么要归一化呢?
很多同学并未搞清楚,维基百科给出的解释:
1)归一化后加快了梯度下降求最优解的速度, 主要是加快梯度下降法收敛速度。
2)归一化有可能提高精度。下面我简单扩展解释下这两点。
1.什么是归一化
有两种实现方法:
(1)常用的方法是通过对原始数据进行线性变换把数据映射到[0,1]之间,变换函数为:
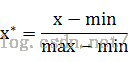
其中max为样本数据的最大值,min为样本数据的最小值。
缺点:这种方法有个缺陷就是当有新数据加入时,可能导致max和min的变化,需要重新定义。
另外,最大值与最小值非常容易受异常点影响,
所以这种方法鲁棒性较差,只适合传统精确小数据场景
2. 标准化
常用的方法是z-score标准化,经过处理后的数据均值为0,标准差为1,处理方法是:
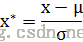
其中,其中μ是样本的均值, σ是样本的标准差。
特点: 该种归一化方式要求原始数据的分布可以近似为高斯分布,否则标准化的效果会变得很糟糕。它们可以通过现有样本进行估计。
在已有样本足够多的情况下比较稳定,适合现代大数据场景。
以上为两种比较普通但是常用的归一化技术,那这两种归一化的应用场景是怎么样的呢?下面做一个简要的分析概括:
1、在分类、聚类算法中,需要使用距离来度量相似性的时候、或者使用PCA技术进行降维的时候,第二种方法(Z-score standardization)表现更好。
2、在不涉及距离度量、协方差计算、数据不符合正太分布的时候,可以使用第一种方法或其他归一化方法。比如图像处理中,将RGB图像转换为灰度图像后将其值限定在[0 255]的范围。
import numpy as np import pandas as pd def standardize(X): m, n = X.shape for j in range(n): features = X[:,j] meanVal = features.mean(axis=0) std = features.std(axis=0) if std != 0: X[:, j] = (features-meanVal)/std else: X[:, j] = 0 return X def normalize(X): m, n = X.shape for j in range(n): features = X[:,j] minVal = features.min(axis=0) maxVal = features.max(axis=0) diff = maxVal - minVal if diff != 0: X[:,j] = (features-minVal)/diff else: X[:,j] = 0 return X result = pd.read_table(r'E:\Python\resource\house.txt',sep='\s+') X=result.as_matrix() normResult = normalize(X) standardResult = standardize(X) print(normResult) print(standardResult)
house.txt 数据格式如下
面积 间数 价钱
2104 3 399900
1600 3 329900
2400 3 369000
1416 2 232000
3000 4 539900
1985 4 299900

 浙公网安备 33010602011771号
浙公网安备 33010602011771号