


IPIDEA代理IP深度测评:构建智能体知识库的得力助手
1. 智能体知识库的重要性
我最近在做“历史大事记”智能体时,踩了个实打实的坑:初期全靠大模型原生知识库支撑,回答总是“缺斤短两”:要么漏了关键历史事件,要么对人物生卒、传统习俗的描述模糊不清,甚至连一些广为人知的纪念日都没法精准对应。
为了补齐这个短板,我找遍了各种数据源,最终发现维基百科这一“宝藏库”:它把全年365/366天的内容拆解得明明白白,大到影响世界的历史拐点,小到行业先驱的诞辰、地方特有的民俗,甚至冷门的科普事件都有收录,数据维度全、权威性也够,完全能满足智能体知识库的扩充需求。
2. 代理IP在数据采集中的重要性
数据源找到了,但新的数据采集问题又来了:维基百科在国内没法直接访问,而且单天数据就包含几十甚至上百条目数据,365/366天累计下来就是海量数据,手动采集根本不现实,自动化爬虫又被网络管理卡了脖子。这时候我才意识到,想要高效抓取这些数据,解决网络壁垒的代理IP工具是刚需。
合理运用代理IP技术是实现高效稳定网络爬虫不可或缺的一环,代理IP帮助爬虫获得了更广泛、更深入的数据资源。这些数据经过清洗、整合后就可以形成高质量的知识库,为智能体的问题回答提供优质准确的数据支撑。
3. 选择IPIDEA代理IP的原因
为了高效、稳定的完成数据抓取,我对市面上的一些代理服务商进行了详细的分析和研究,包括IPIDEA、星空代理、IPIPGO等。具体对比如下:
| 优势维度 | IPIDEA核心表现 | 星空代理表现 | IPIPGO表现 |
|---|---|---|---|
| 一、IP资源规模+质量 | 1亿+优质IP,含1亿+真实住宅IP、千万级移动IP,自建纯净合规池,严格筛选 | 仅提及“海量IP”,无具体数值,以国内运营商授权节点为主,未强调“真实用户IP” | 9000万+IP,住宅IP以动态为主,移动IP覆盖有限 |
| 二、覆盖范围+精度 | 全球220+国家/地区,支持“国家-州/省-城市-ASN”四级定位,热门地区IP密度高 | 仅覆盖国内200+城市,无全球布局,定位精度仅到城市级 | 全球200+国家/地区,定位精度到城市级,热门地区(如美国数据中心IP仅3.5万+)密度低 |
| 三、稳定性 | 99.9%正常运行时间+99.9%采集成功率,支持1-120分钟自定义时效 | IP可用率>98%,IP有效时长仅1-15分钟,无长效选项 | 数据中心IP稳定性99.9%,整体采集成功率未明确,部分套餐带宽有隐性限制 |
| 四、代理类型 | 8类细分类型(含移动、IPv6、无限量、长效ISP、独享数据中心等特色类型) | 仅4类基础套餐(计量/不限量A/B),无移动、IPv6、长效等类型 | 无IPv6、长效ISP代理,移动IP类型单一 |
| 五、高匿名性 | 住宅/移动IP为真实用户网络,搭配IP轮转+自定义指纹 | IP为运营商节点,非真实用户IP,匿名性仅满足基础需求 | 住宅IP为真实节点,但规模小于IPIDEA,防封策略侧重基础轮转 |
| 六、协议+集成能力 | 支持HTTP/HTTPS/Socks5,提供7种主流语言代码示例,无缝对接AI/ML工作流与数据基础设施 | 支持HTTP/HTTPS/Socks5,无多语言代码示例,仅提供基础代理服务 | 支持HTTP/HTTPS/Socks5,无多语言代码示例,代理与辅助工具为合作模式 |
| 七、合规性 | 符合GDPR、CCPA等国际数据保护法规,SSL/TLS加密+DDoS防护+24/7安全监控 | 仅提及“运营商正规授权”,无国际合规认证,安全防护体系未明确 | 未提及国际合规认证,仅强调IP正规授权,安全防护体系较基础 |
| 八、附加价值 | 配套抓取API\浏览器**抓取器**等工具,服务阿里巴巴、华为等头部企业,支持多买多送 | 仅提供代理服务,无配套工具,缺乏知名企业背书 | 合作工具类平台,缺乏头部企业背书,优惠以折扣为主 |
可以看到,IPIDEA作为企业级代理IP服务提供商,其优势在IP资源规模、覆盖精度、稳定性、场景适配性、合规性等核心维度均显著领先于同类平台。以1亿+真实IP资源、220+国家四级定位构建全球网络覆盖,以99.9%稳定性+8类细分代理类型适配全场景需求,以国际合规认证+一体化工具降低企业使用成本与风险,最终形成“代理IP+数据采集+安全保障”的闭环服务。
显然,这就是契合我需求的那个“它”。所以,最后我选择了IPIDEA来作为我构建智能体知识库的代理IP。
4. IPIDEA的使用流程和性能测试
接下来,我将介绍如何使用IPIDEA的服务来实现代理IP的提取,并对其提供的代理服务的实际表现进行一系列测试。
4.1 使用流程
4.1.1 账号注册登录
介绍使用代理IP前的准备工作,包括注册账号、获取API密钥、选择合适套餐、安装必要Python库等。
首先访问IPIDEA官网,点击右上角注册按钮,完成注册登录。
4.1.2 配置IP白名单
IP白名单仅允许预先添加信任的IP调用代理资源,可有效防止账号盗用导致的代理资源浪费,锁定合规使用的网络范围。
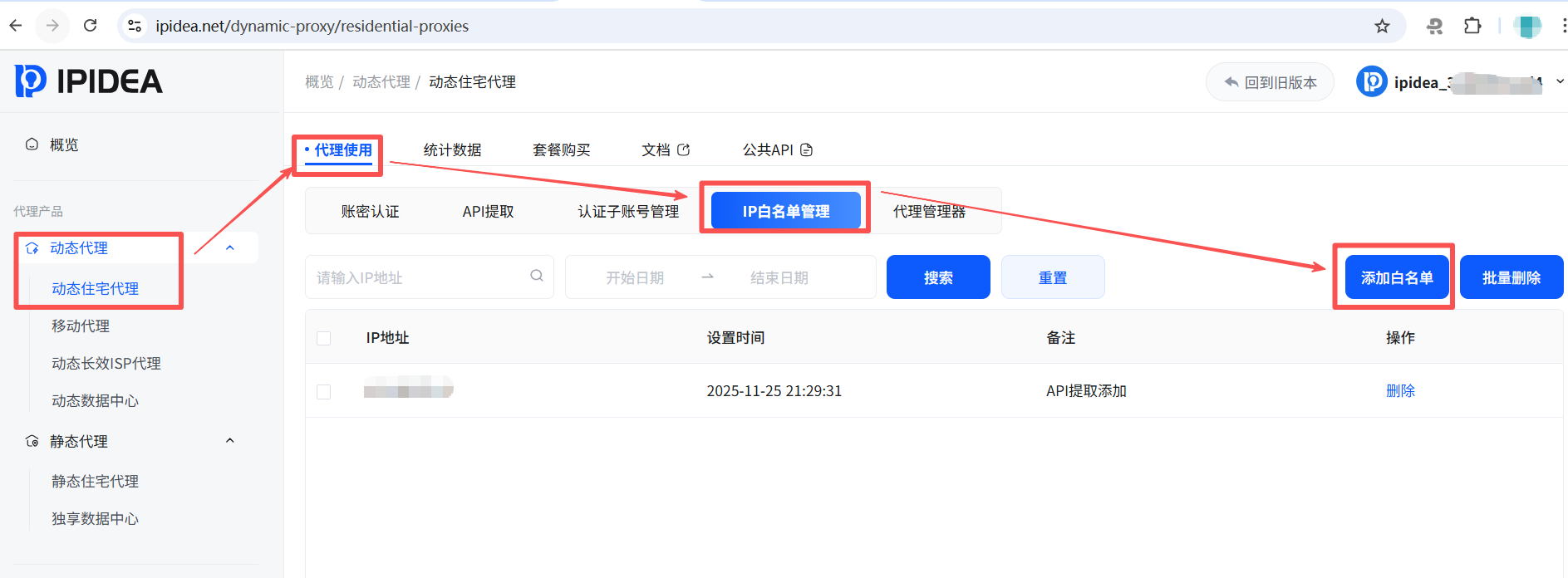
如上图所示,账号注册成功之后,点击右上角用户名,进入概览页。然后依次找到动态代理->动态住宅代理->代理使用->IP白名单管理->添加白名单,然后输入自己当前的IP地址和备注信息,点击确认按钮即可。
4.1.3 配置提取API地址
在概览页,依次找到动态代理->动态住宅代理->API提取。如下图配置之后,点击生成链接,然后右侧复制按钮复制备用。
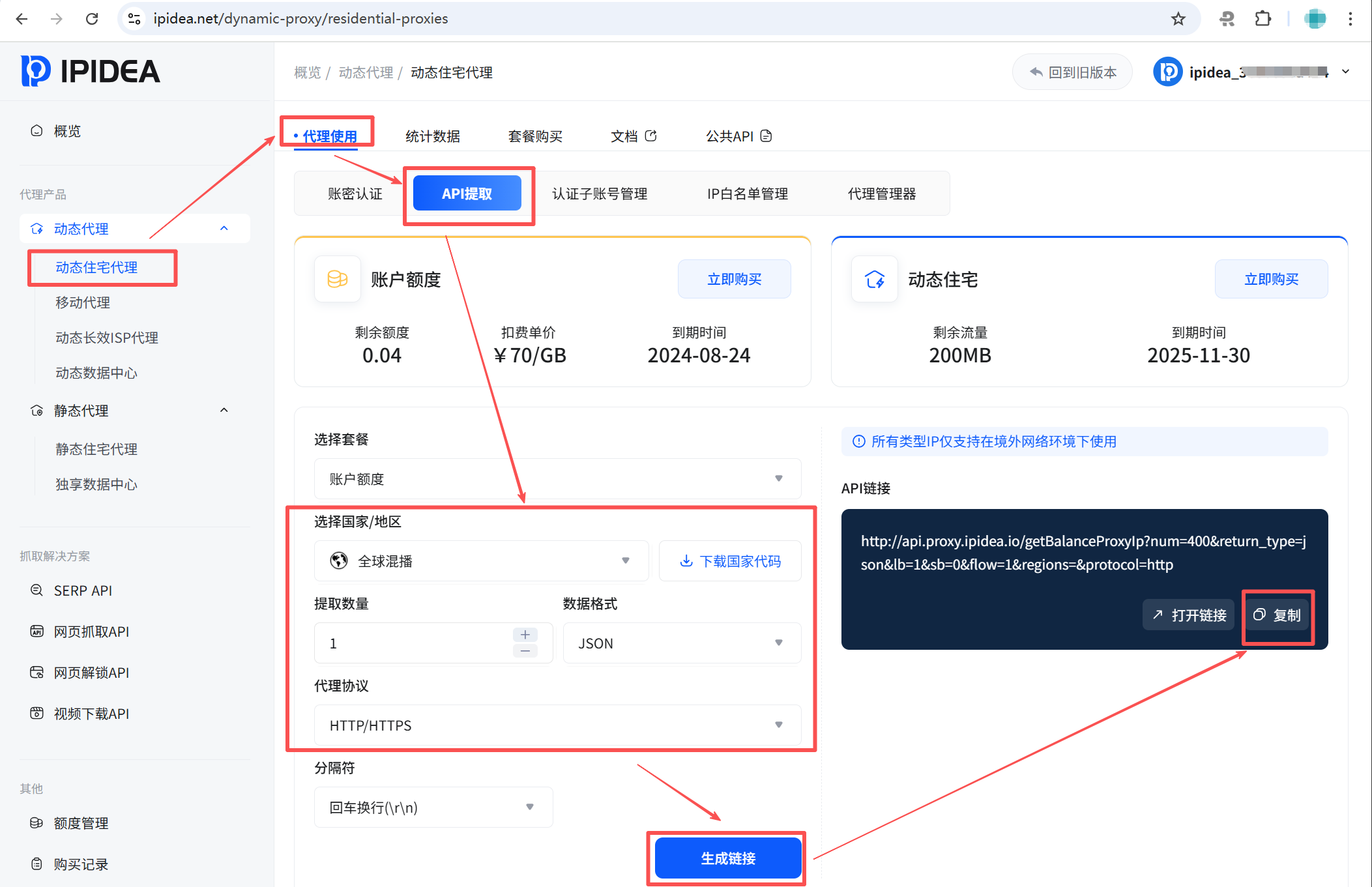
比如,我得到的是:[http://api.proxy.ipidea.io/getBalanceProxyIp?num=1&return_type=json&lb=1&sb=0&flow=1®ions=&protocol=http](http://api.proxy.ipidea.io/getBalanceProxyIp?num=1&return_type=json&lb=1&sb=0&flow=1®ions=&protocol=http)。
4.2 性能测试
代理IP的提取API地址已经有了,接下来我们对其进行一列测试验证,确保它能够符合的数据采集需求。
4.2.1 提取API有效性验证
接下来,我们写一段python代码,来验证API的有效性,确保我们能够顺利提取到代理IP,同时验证我们的白名单IP配置是否生效:
import requests
import json
def fetch_proxy_IP():
api_url = "http://api.proxy.IPIDEA.io/getBalanceProxyIP?num=1&return_type=json&lb=1&sb=0&flow=1®ions=&protocol=http"
try:
# 发送 GET 请求(超时设置为 10 秒,避免无限等待)
response = requests.get(api_url, timeout=10)
# 检查 HTTP 响应状态码(200 表示请求成功)
if response.status_code != 200:
print(f"请求失败,HTTP 状态码:{response.status_code}")
return
# 解析 JSON 响应(将字符串转为 Python 字典)
result = response.json()
print("完整响应数据:")
print(json.dumps(result, indent=2, ensure_ascii=False)) # 格式化打印
print("-" * 50)
# 根据响应状态判断是否获取代理IP成功
if result.get("success") is True and result.get("code") == 0:
# 提取代理IP和端口
proxy_data = result.get("data", [])
if proxy_data:
proxy_IP = proxy_data[0].get("IP")
proxy_port = proxy_data[0].get("port")
request_IP = result.get("request_IP")
print("请求成功!")
print(f"你的请求 IP:{request_IP}")
print(f"获取到的代理 IP:{proxy_IP}")
print(f"代理端口:{proxy_port}")
print(f"可用代理格式(HTTP):http://{proxy_IP}:{proxy_port}")
else:
print("响应中未包含代理IP数据")
else:
# 打印失败原因
error_msg = result.get("msg", "未知错误")
error_code = result.get("code", "未知状态码")
print(f"获取代理IP失败!")
print(f"错误码:{error_code}")
print(f"错误信息:{error_msg}")
# 针对 113 错误码给出明确提示(你之前遇到的白名单问题)
if error_code == 113:
print("提示:请登录 ipidea 后台,将你的请求 IP(result 中的 request_IP)添加到白名单后重试")
except requests.exceptions.Timeout:
print("错误:请求超时(超过 10 秒未响应)")
except requests.exceptions.ConnectionError:
print("错误:网络连接失败(可能是 API 地址不可达或网络问题)")
except json.JSONDecodeError:
print("错误:响应数据不是有效的 JSON 格式")
except Exception as e:
print(f"未知错误:{str(e)}")
if __name__ == "__main__":
# 执行函数
fetch_proxy_IP()
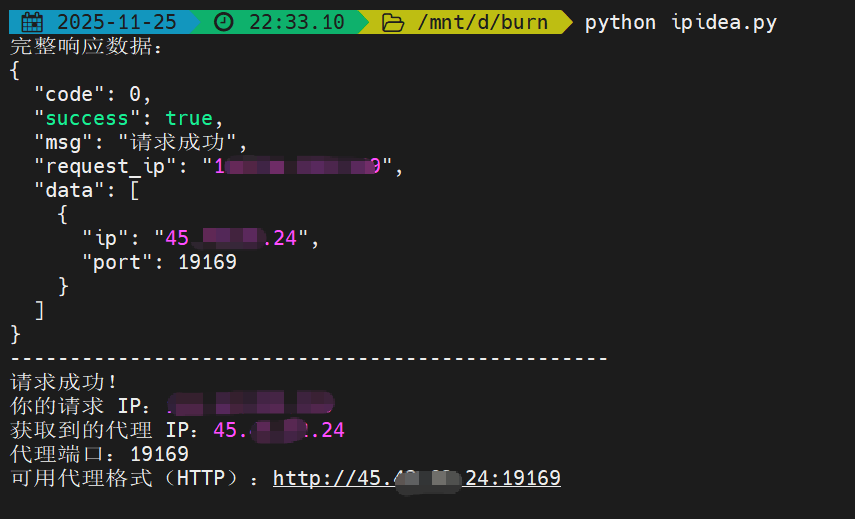
如下图所示,是测试程序的运行截图。顺利的请求到了1个代理IP,API验证有效。
4.2.2 代理IP提取成功率
代理IP提取成功率是指从代理IP池中成功获取有效IP地址的比例,是衡量代理服务质量和可靠性的关键指标。高成功率有助于用户快速获得高质量的代理IP资源,确保数据采集顺利进行。
循环提取100次,每次提取1个代理IP,根据成功提取到的数量来计算提取成功率。如下是核心代码:
def test_1_extraction_success_rate():
"""测试1: 代理IP提取成功率"""
print("=" * 60)
print("测试1: 代理IP提取成功率 (测试100次)")
print("=" * 60)
successful_extractions = 0
failed_extractions = 0
errors = {}
for i in range(100):
proxy_data, _, error = extract_proxy()
if proxy_data and error is None:
successful_extractions += 1
print(f"第{i+1:3d}次提取: 成功 - {proxy_data['data'][0]['IP']}:{proxy_data['data'][0]['port']}")
else:
failed_extractions += 1
errors[error] = errors.get(error, 0) + 1
print(f"第{i+1:3d}次提取: 失败 - {error}")
time.sleep(1)
success_rate = (successful_extractions / 100) * 100
print(f"\n提取成功率: {success_rate:.2f}% ({successful_extractions}/100)")
print("错误统计:")
for error, count in errors.items():
print(f" {error}: {count}次")
return success_rate, errors
运行截图如下所示:
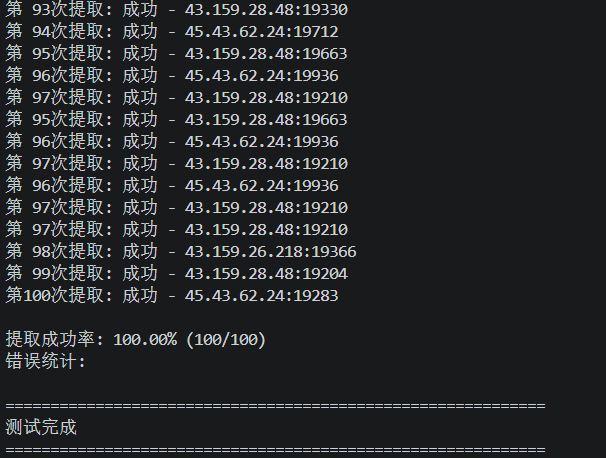
测试结果:提取成功率100%,这与官方所声明的99.9%正常运行时间标准相符。
4.2.3 代理IP提取时间
代理IP提取时间是从代理服务器池获取可用IP所需的时间。这对于需要多次更换IP以应对网络管理、提高抓取效率或保护隐私的应用非常重要,能缩短数据采集时间并提升用户体验。
循环提取100次,每次提取1个代理IP,然后根据成功提取到的数量来计算提取时间。如下是核心代码:
def test_2_extraction_time():
"""测试2: 代理IP提取时间"""
print("\n" + "=" * 60)
print("测试2: 代理IP提取时间 (测试100次)")
print("=" * 60)
extraction_times = []
for i in range(100):
_, extraction_time, error = extract_proxy()
extraction_times.append(extraction_time)
if error is None:
print(f"第{i+1:3d}次提取时间: {extraction_time:.3f}秒")
else:
print(f"第{i+1:3d}次提取时间: {extraction_time:.3f}秒 (提取失败: {error})")
avg_time = statistics.mean(extraction_times)
min_time = min(extraction_times)
max_time = max(extraction_times)
median_time = statistics.median(extraction_times)
print(f"\n提取时间统计:")
print(f" 平均时间: {avg_time:.3f}秒")
print(f" 最短时间: {min_time:.3f}秒")
print(f" 最长时间: {max_time:.3f}秒")
print(f" 中位时间: {median_time:.3f}秒")
return
运行截图如下所示:
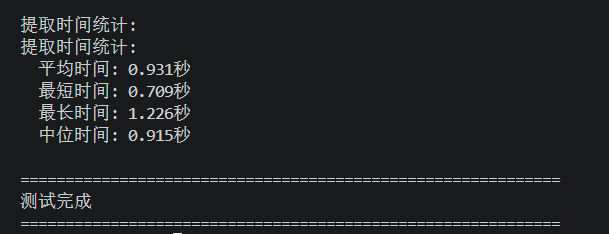
测试结果:平均时间不足1秒,这个耗时在代理IP提取领域属于中上水平,还是非常优秀的。
| 最短时间 | 中位时间 | 最长时间 | 平均时间 |
|---|---|---|---|
| 0.709秒 | 0.915秒 | 1.226秒 | 0.931秒 |
4.2.4 代理IP连通成功率
代理IP连通成功率,是指代理服务器的网络连通性。该指标对需使用代理IP进行网络访问的用户至关重要,直接影响工作效率与服务质量。连通成功率低会导致数据采集多次失败、重试次数增加,消耗更多时间和资源。
循环提取100次,每次提取1个代理IP,然后向其发起tcp连接,根据连接成功的数量来计算连通成功率。如下是核心代码:
def test_proxy_connectivity(IP: str, port: int) -> Tuple[bool, float, Optional[str]]:
"""测试代理连通性"""
start_time = time.time()
try:
# 测试TCP连接
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.settimeout(10)
sock.connect((IP, port))
connect_time = time.time() - start_time
sock.close()
return True, connect_time, None
except Exception as e:
connect_time = time.time() - start_time
error_msg = f"连接失败: {str(e)}"
return False, connect_time, error_msg
def test_3_connection_success_rate():
"""测试3: 代理IP连通成功率"""
print("\n" + "=" * 60)
print("测试3: 代理IP连通成功率 (测试100次)")
print("=" * 60)
successful_connections = 0
failed_connections = 0
connection_errors = {}
for i in range(100):
proxy_data, _, extract_error = extract_proxy()
if proxy_data and extract_error is None:
IP= proxy_data["data"][0]["IP"]
port = proxy_data["data"][0]["port"]
success, _, conn_error = test_proxy_connectivity(IP, port)
if success:
successful_connections += 1
print(f"第{i+1:3d}次连接: {IP}:{port} - 成功")
else:
failed_connections += 1
connection_errors[conn_error] = connection_errors.get(conn_error, 0) + 1
print(f"第{i+1:3d}次连接: {IP}:{port} - 失败 ({conn_error})")
else:
failed_connections += 1
error_msg = f"提取失败: {extract_error}"
connection_errors[error_msg] = connection_errors.get(error_msg, 0) + 1
print(f"第{i+1:3d}次连接: 提取失败 - {extract_error}")
success_rate = (successful_connections / 100) * 100
print(f"\n连通成功率: {success_rate:.2f}% ({successful_connections}/100)")
print("连接错误统计:")
for error, count in connection_errors.items():
print(f" {error}: {count}次")
return success_rate, connection_errors
运行截图如下:
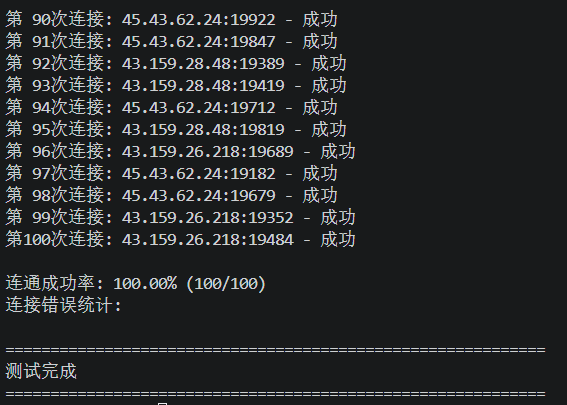
测试结果:提取成功率100%,这与官方所声明的99.9%正常运行时间标准相符。
4.2.5 代理IP响应时间
代理IP响应时间是指从客户端发送请求到通过代理服务器接收到响应数据之间的时间间隔。这个时间间隔可以用来衡量代理服务器的性能和效率。与代理IP连接时间类似,一般来说,响应时间越短,说明代理服务器处理请求的速度越快,用户体验也就越好。
循环提取100次,每次提取1个代理IP,然后使用它来请求baidu,计算请求成功的时间。如下是核心代码:
def test_proxy_response_time(IP: str, port: int) -> Tuple[Optional[float], float]:
"""测试代理响应时间"""
start_time = time.time()
proxy = f"http://{IP}:{port}"
proxies = {"http": proxy, "https": proxy}
test_url = "http://www.baidu.com"
try:
response = requests.get(test_url, proxies=proxies, timeout=15)
if response.status_code == 200:
response_time = time.time() - start_time
return response_time, response_time
except Exception as e:
pass
total_time = time.time() - start_time
return None, total_time
def test_5_response_time():
"""测试5: 代理IP响应时间"""
print("\n" + "=" * 60)
print("测试5: 代理IP响应时间 (测试100次)")
print("=" * 60)
response_times = []
for i in range(100):
proxy_data, _, extract_error = extract_proxy()
if proxy_data and extract_error is None:
IP= proxy_data["data"][0]["IP"]
port = proxy_data["data"][0]["port"]
resp_time, _ = test_proxy_response_time(IP, port)
if resp_time is not None:
response_times.append(resp_time)
print(f"第{i+1:3d}次响应时间: {resp_time:.3f}秒 - {IP}:{port}")
else:
print(f"第{i+1:3d}次响应时间: 测试失败 - {IP}:{port}")
else:
print(f"第{i+1:3d}次: 提取失败,无法测试响应时间")
if response_times:
avg_time = statistics.mean(response_times)
min_time = min(response_times)
max_time = max(response_times)
median_time = statistics.median(response_times)
print(f"\n响应时间统计:")
print(f" 平均时间: {avg_time:.3f}秒")
print(f" 最短时间: {min_time:.3f}秒")
print(f" 最长时间: {max_time:.3f}秒")
print(f" 中位时间: {median_time:.3f}秒")
else:
print("\n没有成功的响应时间测试,无法计算响应时间统计")
return response_times
运行截图:
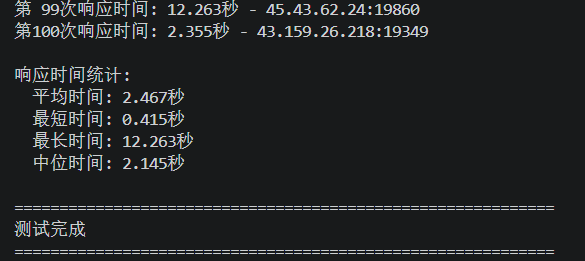
测试结果:平均时间2.467秒,除了因为我这里网络波动引起的个别异常值外,整体耗时还是比较优秀的。
| 最短时间 | 中位时间 | 最长时间 | 平均时间 |
|---|---|---|---|
| 0.415秒 | 2.145秒 | 12.263秒 | 2.467秒 |
5. 使用动态住宅代理IP爬取维基百科数据
为了简化爬虫代码,提高效率,我们直接访问维基百科的纯文本页面。在任意维基百科页面URL后加?action=raw,即可跳转纯文本版本。比如:[<font style="color:rgb(0, 0, 0);">https://zh.wikipedia.org/wiki/3%E6%9C%8830%E6%97%A5?action=raw</font>](https://zh.wikipedia.org/wiki/3%E6%9C%8830%E6%97%A5?action=raw):
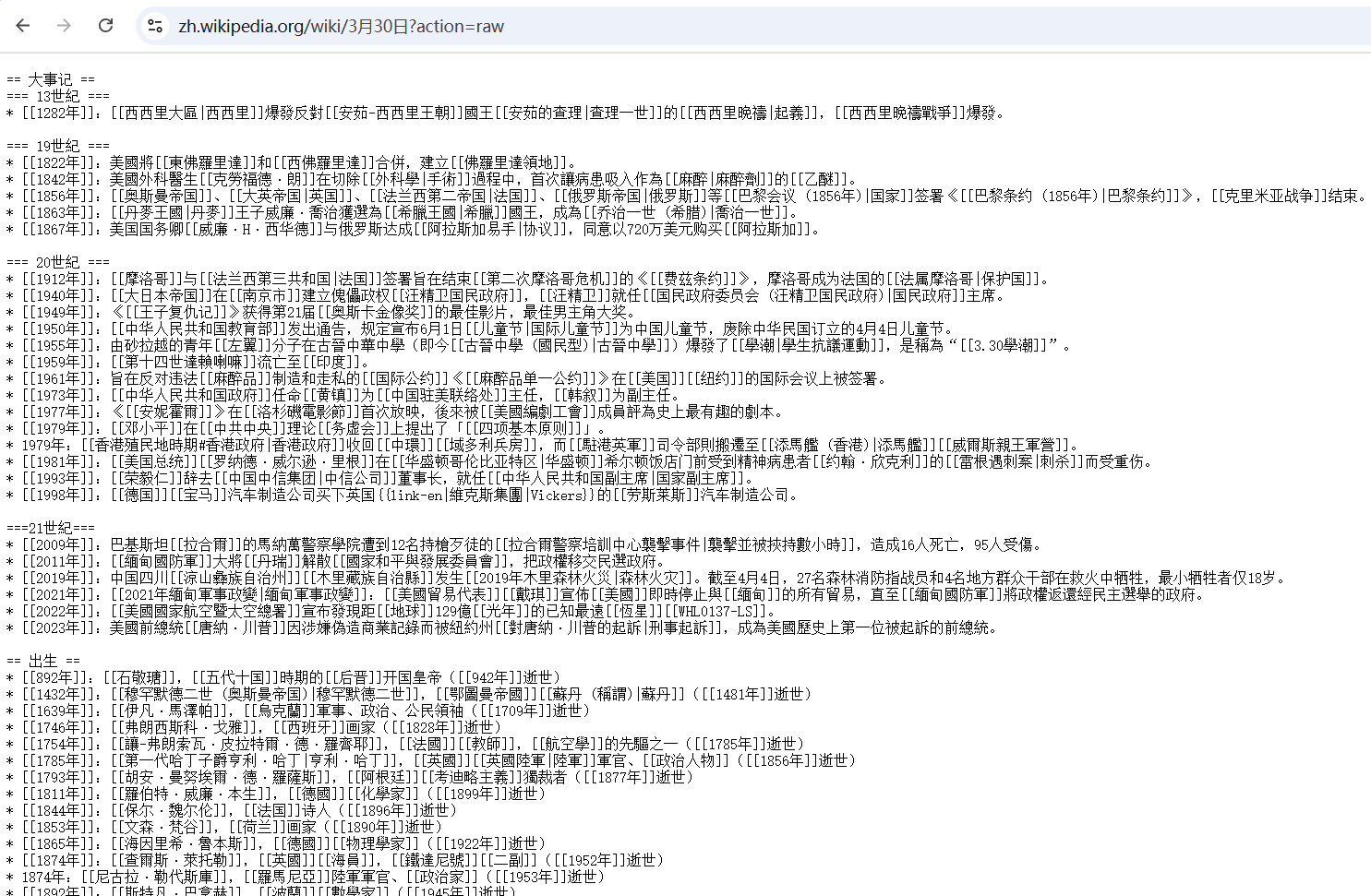
接下来就简单了,我们只需要对日期进行拼接,然后请求一个代理IP来抓取,然后将抓取到的数据,清洗整理之后,保存到文本文件中即可。完整代码如下所示:
import requests
import re
from datetime import datetime
import time
from typing import List, Dict, Optional, Tuple
# 配置参数
PROXY_API_URL = "http://api.proxy.IPIDEA.io/getBalanceProxyIP?num=1&return_type=json&lb=1&sb=0&flow=1®ions=us&protocol=http"
HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8"
}
BASE_WIKI_URL = "https://zh.wikIPedia.org/wiki/{month}月{day}日?action=raw"
PROXY_RETRY_TIMES = 3
WIKI_RETRY_TIMES = 2
DELAY = 1
OUTPUT_FILE = "维基百科所有日期历史信息_代理版_带月日.txt"
def get_proxy_IP() -> Optional[Dict[str, str]]:
"""获取代理IP,返回格式:{'http': 'http://IP:port', 'https': 'http://IP:port'}"""
for retry in range(PROXY_RETRY_TIMES):
try:
response = requests.get(PROXY_API_URL, timeout=10)
response.raise_for_status()
proxy_result = response.json()
if proxy_result.get("success") is True and proxy_result.get("code") == 0:
proxy_data = proxy_result.get("data", [])
if proxy_data:
IP= proxy_data[0].get("IP")
port = proxy_data[0].get("port")
ifIPand port:
proxy = {
"http": f"http://{IP}:{port}"
}
print(f"✅ 成功获取代理IP:{IP}:{port}")
return proxy
print("❌ 代理接口返回数据为空")
else:
error_msg = proxy_result.get("msg", "未知错误")
error_code = proxy_result.get("code", "未知状态码")
print(f"❌ 获取代理IP失败(错误码:{error_code},信息:{error_msg})")
if error_code == 113:
print("⚠️ 提示:请登录ipidea后台,将当前请求IP添加到白名单")
except requests.exceptions.Timeout:
print(f"⚠️ 获取代理IP超时,第{retry+1}/{PROXY_RETRY_TIMES}次重试...")
except requests.exceptions.ConnectionError:
print(f"⚠️ 获取代理IP网络连接失败,第{retry+1}/{PROXY_RETRY_TIMES}次重试...")
except Exception as e:
print(f"⚠️ 获取代理IP异常:{str(e)},第{retry+1}/{PROXY_RETRY_TIMES}次重试...")
time.sleep(DELAY)
print("❌ 多次获取代理IP失败")
return None
def get_max_days(month: int, year: int = 2024) -> int:
"""获取指定月份的最大天数(2024是闰年,适配2月29天)"""
if month == 2:
return 29 if (year % 4 == 0 and year % 100 != 0) or (year % 400 == 0) else 28
elif month in [4, 6, 9, 11]:
return 30
else:
return 31
def generate_all_dates() -> List[Dict[str, int]]:
"""生成全年所有日期(月/日)"""
all_dates = []
for month in range(1, 13):
max_days = get_max_days(month)
for day in range(1, max_days + 1):
all_dates.append({"month": month, "day": day})
return all_dates
def fetch_wikitext_with_proxy(month: int, day: int) -> Optional[str]:
"""使用代理IP请求指定日期的维基百科原始wikitext内容"""
url = BASE_WIKI_URL.format(month=month, day=day)
print(f"\n📥 正在请求 {month}月{day}日 维基内容(使用代理)")
for retry in range(WIKI_RETRY_TIMES):
proxy = get_proxy_IP()
if not proxy:
print(f"⚠️ 第{retry+1}/{WIKI_RETRY_TIMES}次重试:获取代理失败,跳过该日期")
return None
try:
response = requests.get(
url,
headers=HEADERS,
proxies=proxy,
timeout=20,
verify=False
)
response.raise_for_status()
print(f"✅ {month}月{day}日 维基内容请求成功")
return response.text
except requests.exceptions.ProxyError:
print(f"⚠️ 第{retry+1}/{WIKI_RETRY_TIMES}次重试:代理失效或不可用")
except requests.exceptions.Timeout:
print(f"⚠️ 第{retry+1}/{WIKI_RETRY_TIMES}次重试:代理请求超时")
except requests.exceptions.ConnectionError:
print(f"⚠️ 第{retry+1}/{WIKI_RETRY_TIMES}次重试:代理网络连接失败")
except requests.exceptions.HTTPError as e:
print(f"❌ 第{retry+1}/{WIKI_RETRY_TIMES}次重试:请求失败({e})")
except Exception as e:
print(f"⚠️ 第{retry+1}/{WIKI_RETRY_TIMES}次重试:未知异常 {str(e)}")
time.sleep(DELAY * 2)
print(f"❌ {month}月{day}日 多次代理请求失败,跳过该日期")
return None
def add_month_day_to_year(item: str, month: int, day: int) -> str:
"""在年份后添加月日(支持公元/公元前、1-4位数年份)"""
# 正则匹配规则:支持 公元前xxxx年、xxxx年、xx年 格式,匹配后在年份后插入 月日
# 分组说明:\1=前缀(公元前)、\2=年份数字、\3=年字、\4=冒号及后面内容
pattern = r"(^(前|公元前)?(\d{1,4})(年)(:|:))(.*)"
match = re.match(pattern, item, re.UNICODE)
if match:
# 提取各部分并拼接:前缀 + 年份 + 年 + 月日 + 冒号 + 内容
prefix = match.group(1) # 包含"公元前"(如有)、年份、"年"、冒号
content = match.group(6) # 冒号后的内容
# 插入月日(格式:x月x日)
new_item = f"{match.group(2) if match.group(2) else ''}{match.group(3)}年{month}月{day}日{match.group(5)}{content}"
return new_item
else:
# 无明确年份格式的记录,保持原样
return item
def parse_wikitext(wikitext: str, month: int, day: int) -> Dict[str, List[str]]:
"""解析wikitext,提取大事记、出生、逝世信息,在年份后补充月日"""
section_pattern = r"==\s*(%s)\s*==\n([\s\S]*?)(?=\n==\s*[\u4e00-\u9fa5]+\s*==|\Z)"
target_sections = ["大事记", "出生", "逝世"]
result = {section: [] for section in target_sections}
for section in target_sections:
match = re.search(section_pattern % section, wikitext, re.IGNORECASE)
if not match:
result[section] = ["无相关记录"]
continue
content = match.group(2).strIP()
if not content:
result[section] = ["无相关记录"]
continue
# 基础清洗
content = re.sub(r"\{\{[^\}]+\}\}", "", content)
content = re.sub(r"\[\[([^\]|]+)\|([^\]]+)\]\]", r"\2", content)
content = re.sub(r"\[\[([^\]]+)\]\]", r"\1", content)
content = re.sub(r"<ref[^>]*>[\s\S]*?</ref>", "", content)
content = re.sub(r"\n+", "\n", content)
items = re.findall(r"^\* (.+)$", content, re.MULTILINE)
# 核心步骤:为每条记录的年份后添加月日
processed_items = []
for item in items:
processed_item = add_month_day_to_year(item, month, day)
processed_items.append(processed_item)
result[section] = processed_items if processed_items else ["无相关记录"]
return result
def save_result(date_info: Dict[str, int], parsed_data: Dict[str, List[str]], file):
"""将解析结果写入文件"""
month, day = date_info["month"], date_info["day"]
# 注意:这里要和target_sections对应
for section in ["大事记", "出生", "逝世"]:
for idx, item in enumerate(parsed_data[section], 1):
file.write(f"{item}\n")
def main():
"""主函数:生成日期→获取代理→代理请求维基→解析→保存"""
requests.packages.urllib3.disable_warnings()
all_dates = generate_all_dates()
total_dates = len(all_dates)
print(f"📅 共生成 {total_dates} 个日期,开始遍历(每个日期将使用独立代理IP)...")
print(f"⚠️ 注意:若持续获取代理失败,请检查IP白名单配置\n")
with open(OUTPUT_FILE, "w", encoding="utf-8") as f:
for idx, date in enumerate(all_dates, 1):
month, day = date["month"], date["day"]
print(f"\n{'='*60}")
print(f"[{idx}/{total_dates}] 正在处理:{month}月{day}日")
print(f"{'='*60}")
wikitext = fetch_wikitext_with_proxy(month, day)
if not wikitext:
continue
parsed_data = parse_wikitext(wikitext, month, day)
save_result(date, parsed_data, f)
print(f"✅ {month}月{day}日 信息已保存")
print(f"\n🎉 所有日期处理完成!结果已保存至:{OUTPUT_FILE}")
print(f"⚠️ 部分日期可能因代理失效或网络问题未获取到内容,可查看控制台日志")
if __name__ == "__main__":
main()
爬取每个日期的事件前,先提取一个代理IP。然后使用代理IP去抓取,抓取到内容后进行内容清洗,保存到文件:维基百科所有日期历史信息_代理版_带月日.txt中,依次循环,直到抓取完365/366个日期的所有事件。
如下所示是代码运行截图,成功的将每个日期的大事件记录抓取、清洗并保存了下来。
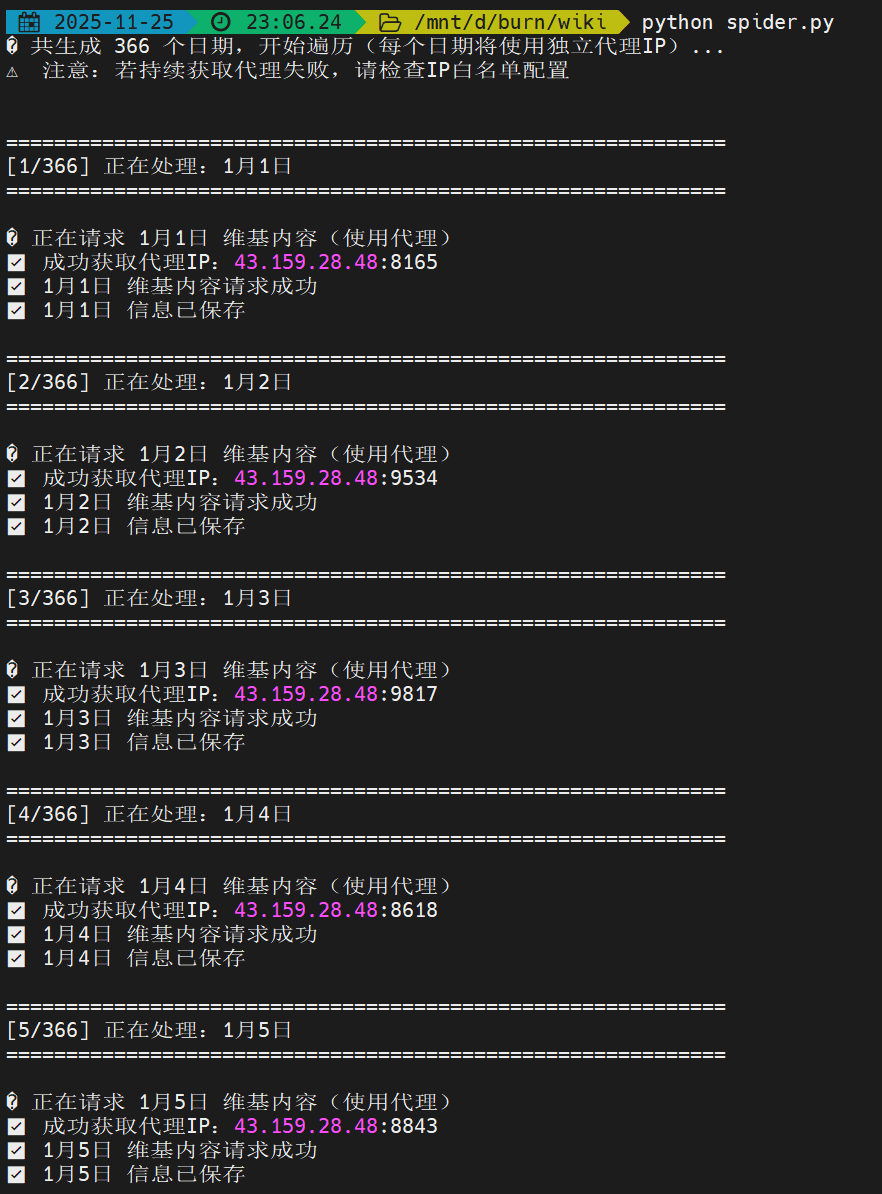
6. 智能体效果验证
智能体的最终回答质量,从来都离不开优质数据源、高效采集能力与完整数据支撑的三重保障——而IPIDEA代理IP的核心功能与强悍性能,正是打通这一链路的关键纽带。它绝非单纯的“工具”,更像是全程赋能的“得力助手”:不仅在数据采集环节扫清障碍,更将自身优势直接转化为智能体回答质量的跨越式提升,让知识库的价值真正落地见效。
6.1 知识库展示
如下图所示,是我抓取清洗后的内容。这就是一份可以用来构建知识库的优质数据集了。
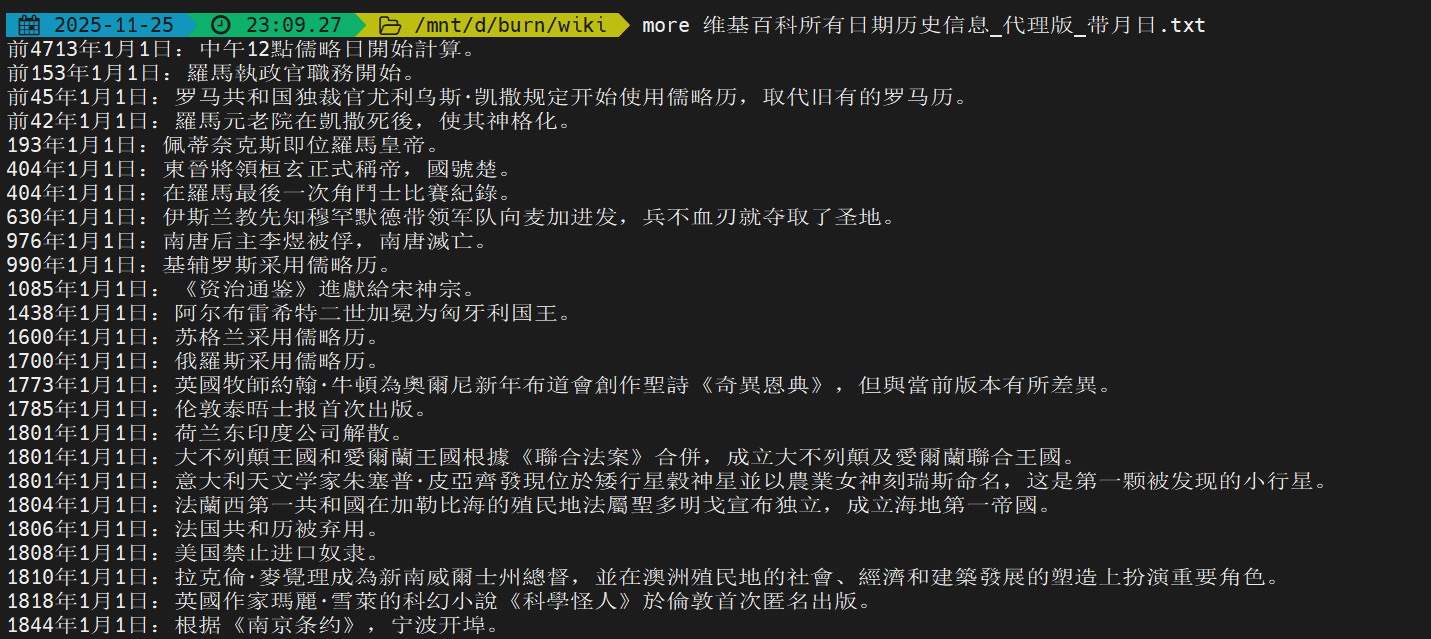
经过分段解析后,会得到下图所示的一个知识条目,适配智能体的知识库检索调用逻辑,让大模型能直接精准抓取所需信息。
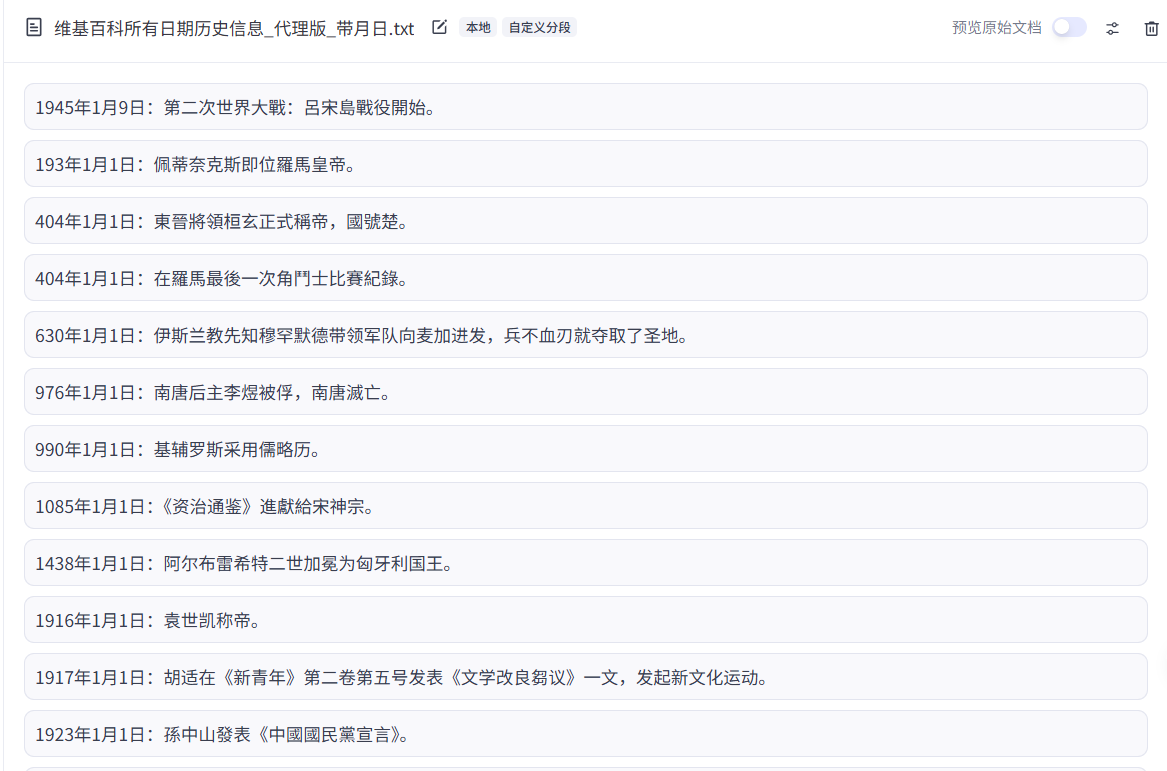
6.2 智能体表现对比
接下来,我们通过2个简单的问题,来对比使用知识库前后的智能体表现差异。
| 问题 | 无知识库 | 有知识库 |
|---|---|---|
| 1945年1月9日有哪些重大事件发生? | 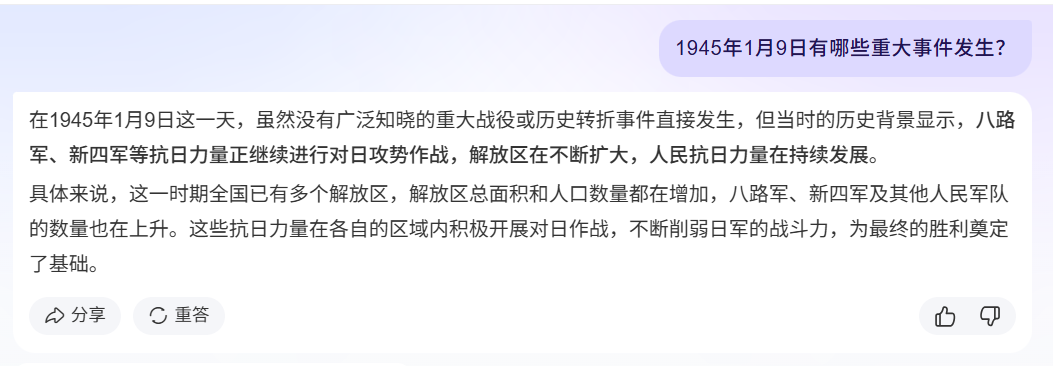 |
 |
| 1月1日发生过什么重要事件? |  |
 |
根据对第一个问题的回答进行对比分析后发现,引入知识库显著提升了AI系统的知识容量。从第二个问题的回答对比中可以看出,在知识库的支持下,AI的回答更加贴合“历史大事记”智能体的特定调性,其重点集中于历史事件而非近期发生的事件上,从而更接近预期设定的标准。
7. 结论
回头看“历史大事记”智能体的搭建过程,最核心的感悟是:智能体的回答质量,本质是知识库的“数据质量”决定的。初期依赖大模型原生知识库,之所以出现“缺斤短两”“描述模糊”的问题,核心就是缺乏结构化、全覆盖、高权威的专属数据支撑--而维基百科作为全球公认的优质数据源,恰好弥补了这一短板,但“国内无法直接访问”“海量数据需自动化采集”的现实难题,又让代理IP成为了不可或缺的“桥梁”。
在整个数据采集环节中,IPIDEA代理IP的选择堪称“关键一步”。它的亿级纯净代理IP池解决了“代理失效、反爬机制”的顾虑,220+国家/地区的四级精准定位解决了网络地域问题,99.9%的稳定性和多类型代理适配,确保了365/366个日期、数十万条历史数据的高效抓取。对比同类平台,其“真实IP占比高、场景适配全、合规有保障”的优势,不仅让我避开了“劣质IP导致业务中断”“定位不准无法访问目标资源”等问题,更通过多语言代码示例,降低了开发成本,最终实现了“采集-清洗-入库”的全流程顺畅落地。
最终,通过“维基百科数据源+IPIDEA代理IP+Python爬虫”的组合,我成功构建了一份覆盖全年日期、包含大事记、出生、逝世三大核心维度的高质量知识库--不仅数据完整度远超大模型原生知识库,还通过“年份+月日”的格式优化,让智能体能够精准定位历史事件,彻底解决了“回答模糊、遗漏关键信息”的问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号