

唤醒 “乐奇” 的秘密:语音唤醒技术全链路解析 —— 从硬件收音到软件识别
前言
从2014到2025,从初代Rokid Alien到全新Rokid Glasses,从唤醒词“若琪”到“乐奇”——Rokid的产品形态虽历经更迭升级,但在人机交互领域的深耕之心始终未变。
每一代产品的亮相,都收获了用户的深切支持与认可。一句“若琪”,不仅是用户与Rokid的专属故事,更是一段关于科技与情感交融的温暖叙事。如今,伴随新一代Rokid Glasses的正式发布,唤醒词也从“若琪”升级为“乐奇”:那句曾深入人心的“若琪”,并未走远,而是以全新姿态回到我们身边,唤醒新的交互可能,却依旧延续着那份陪伴的温度。
尽管Rokid Alien与Rokid Glasses形态各异,却共同承载着Rokid对卓越人机交互体验的不懈追求。两者均搭载时下前沿的语音交互技术,让每一次人机对话,都兼具科技的便捷与情感的温度。
你是不是也好奇,为何轻轻喊一声‘乐奇’,就能唤醒这份便捷的人机交互?接下来,我们就从‘乐奇’的唤醒场景出发,以硬件、软件、性能指标的全链路视角解析语音唤醒技术原理,带大家彻底弄清‘乐奇’能够应声响应的来龙去脉。
硬件算力基础:Rokid Glasses是怎么 “听到”并“听懂”声音的
要实现语音唤醒,第一步得让设备精准 “听到” 你的声音,还得有足够的 “脑子” 处理这些声音信号。这就靠麦克风阵列、回路参考音、喇叭、DSP/CPU这些硬件部件配合。硬件好不好,直接决定了后续处理的声音质量,是唤醒效果的根本。
2.1 麦克风阵列:设备的 “耳朵”,越多越会 “定向听声”
麦克风阵列就是设备的 “耳朵”,靠多个麦克风一起工作,实现 “朝着声音来源听”,解决了单个麦克风抗干扰差的问题。现在常见的有单麦、双麦、4麦、5麦、8麦这几种,麦克风数量越多,“定向听声” 的能力越强。

实际应用中,单麦方案成本最低但抗噪能力有限,适合近距离场景;双麦通过波束成形可实现基本的方向滤波,常用于耳机产品;4麦、6麦甚至8麦阵列则广泛应用于智能音箱、车载系统等远场场景,能提供更精准的声源定位和噪声抑制能力。Rokid Glasses采用的就是4麦方案,通过麦克风阵列实现不同适用场景的定向收音。
衡量麦克风阵列好不好,主要看这几个参数:
- 采样率与位深:现在主流是 16kHz/16bit——16kHz 能覆盖人说话的主要频率范围(80Hz-4kHz),16bit 能保证声音细节不丢;主流的音频识别产品都是采用这个配置,既能确保人声的完整性也能控制合理的数据量。
- 灵敏度:就是麦克风把声音转换成电信号的能力。太不灵敏,远一点说话就听不清;太灵敏,又容易把杂音也收进来。得根据使用场景调,比如智能眼镜类的产品,用户戴的时候嘴离麦克风也就15-20 厘米,所以把灵敏度设为 - 38dBFS±2dB,可以既能保证听清说话声,又不会让杂音过载。
- 信噪比(SNR):就是有效声音和杂音的比例,数值越高(比如≥65dB),采集的声音越干净,抗干扰能力越强。Rokid搭载的是MEMS麦克风,信噪比最高能达到70dB以上。就算在咖啡馆、地铁这种有杂音的地方,也能较为准确的试音。
- 麦克风 “一致性校准”:多个麦克风出厂时,性能会有细微差别,得校准让它们一致 —— 不然 “耳朵” 听的不一样,定向效果就差了,甚至会 “听错”。所以在生产产线上,需要对每台设备的麦克风阵列进行的单独的校准,把误差控制在 ±1dB 以内,保证批量生产的设备,麦克风收音能力都是相对稳定可靠的。
2.2 喇叭:设备的 “嘴巴”,也影响回声

喇叭是设备的 “嘴巴”,但它也是回声的主要来源,声道配置得跟麦克风阵列配合好才可以。
- 单声道:结构简单、成本低,适合小型设备,比如智能手环,但回声方向单一,得针对性消除。
- 双声道 / 立体声:适合大设备或者对音质一定要求的设备,比如智能电视,但回声来源复杂,得靠麦克风阵列的定向功能,区分喇叭回声和用户说话声。
Rokid Glasses采用的是双立体声骨传导喇叭,骨传导不用空气传声,声音清晰,既能减少对外界的干扰,又能让麦克风少收点回声。
2.3 回路参考音:用于解决 “设备自己的声音干扰麦克风收音”的问题
如果设备既能 “听”(麦克风)又能 “说”(喇叭),比如智能音箱,喇叭播放的声音会被麦克风再收进来,形成 “回声”—— 比如放音乐时,麦克风既收音乐声,又收你喊的唤醒词,特别影响唤醒。回路参考音主要有两种采集方式:
- 硬件回路采集:直接通过硬件线路拿喇叭的原始声音,延迟低、稳定,适合对实时性要求高的场景,比如直播音箱。
- 软件回路采集:通过软件接口拿声音信号,不用额外加硬件,成本低,但延迟高(可能差 10-20 毫秒),得用算法补这个延迟。
Rokid Glasses采用的是骨传导喇叭,能避免声音漏出去,但可能还是会有轻微回声。如果要得到比较纯净人生,还是需要通过回声消除(AEC)算法将喇叭播放的回路声音去掉。
2.4 DSP/MPU:设备的 “大脑”,负责处理声音
语音唤醒要准要快,得有足够的算力支撑,一般来说,语音识别类产品都是使用专业的DSP芯片(数字信号处理器)或者直接使用高性能MPU芯片(微处理器)来替代进行语音信号的前端处理和唤醒词检测等。

Rokid Glasses采用高通骁龙AR1和恩智浦的 RT600 系列芯片组成的双芯片架构。其中,
- 骁龙AR1作为主控应用处理器,它是一颗专为智能眼镜打造的SoC,主要负责处理所有高负载的任务,例如通过处理摄像头拍摄的图像和视频,以及驱动Micro-LED+光波导的显示等。
- 恩智浦RT600芯片配备了Arm® Cortex®-M33 和 Cadence® Xtensa® HiFi4音频DSP,专门承接那些需要长时间运行但计算负载相对较轻的任务,尤其是音频相关的处理。它能够在主芯片骁龙AR1处于深度休眠状态时,以极低的功耗维持“乐奇”的随时唤醒能力,持续监听用户的唤醒指令。
软件算法模块:去掉杂音,精准识别“乐奇”唤醒词
麦克风负责音频信号的采集,DSP提供计算能力,剩下的如何算,算什么就全靠软件了。比如说,硬件采集的声音里有杂音、回声,得靠软件处理,把干净的语音提出来;如何从音频信号中准确计算识别出唤醒词等等。软件设计得好不好,直接决定了唤醒准不准、抗不抗干扰。Rokid Glasses根据设备的场景(方便携带、近场使用、续航能力、容易有杂音),在软件算法上做了不少优化,形成了自己的唤醒方案。
3.1 回声消除(AEC):把设备自己的声音去掉
回声消除就是从麦克风采集的声音里,把喇叭播放的声音去掉,主要有两种方式:
- 硬件 AEC:靠专门的硬件芯片(比如音频芯片),通过硬件回路参考音实时算回声模型,消除回声的延迟低(≤5 毫秒),适合对实时性要求高的场景,比如视频通话。
- 软件 AEC:用算法(比如 NLMS 自适应滤波)建回声模型,不用额外加硬件,但得补软件传输的延迟 —— 比如先通过时间戳对齐 “参考音信号” 和 “麦克风采集的信号”,再用滤波把回声去掉,能把回声减 40dB 以上。

如上图所示,以单路麦克风为例,进行一个AEC算法的效果演示:将一路麦克风录音数据和一路喇叭回路数据送给AEC算法进行回声消除运算,最终得到一路只包含人声和环境噪声的语音数据。如果是多路麦克风,AEC算法也是每个麦克风通道输出一路语音数据,用作后续的信号处理和唤醒词检测流程。
3.2 前端信号处理(SGP):去杂音、调音量、定向增强
前端信号处理就是将AEC回声消除之后的信号,去杂音、把音量调均匀、朝着说话方向增强声音,给后续识别唤醒词提供干净的声音,主要有三个功能:
- 噪声抑制(NS):就是消杂音,比如电视声、风声、键盘声。常用的方法是先分析没声音时的杂音特征,再从混合声音里把杂音减掉。比如在嘈杂的客厅,能把电视声降 30dB 以上,突出你的唤醒词。
- 自动增益控制(AGC):解决 “近了声音太大、远了声音太小” 的问题。你离设备近(1 米内),就降低音量避免声音失真;离得远(5 米外),就提高音量到合适范围(比如 - 20dBFS~-10dBFS),保证不同距离的声音大小一致。
- 波束成形(BF):麦克风阵列的 “定向增强” 功能,通过调整每个麦克风的信号权重,形成 “朝着你说话方向的声音波束”,同时减弱其他方向的干扰(比如回声、旁边的杂音)。比如,对于智能音箱类产品来说,你在设备左边 3 米说话,能把左边的声音增强 10-15dB,右边的杂音减 20dB 以上,实现 “只听你说话”。

对于Rokid Glasses来说,通过4路麦克风阵列,结合使用场景就可以定向选择使用哪几路麦克风,比如通话使用后排麦克风精准录制佩戴者声音,确保录音的清晰纯净;聊天翻译使用前排麦克风仅录制对方的声音,进行翻译识别;录像模式使用所有麦克风同时收音原声录制,确保还原最真实的录像场景。
3.3 唤醒词检测(WWD):核心环节,认出“乐奇”
唤醒词检测很好理解,就是判断用户是不是喊了唤醒词“乐奇”,本质是靠AI模型识别:
- 模型原理:现在主流用深度学习模型(比如 CNN、RNN、Transformer),通过大量唤醒词样本(比如不同人、不同场景下喊 “乐奇”的录音文件)训练模型,让模型能认出唤醒词的声音特征(比如音调、节奏、频谱分布)。
- 检测流程:预处理后的声音先转成频谱特征(比如 MFCC、Fbank),再输入模型,如果模型判断 “是唤醒词” 的概率超过预设值(比如 0.8),就判定唤醒成功,触发设备响应。
相比市面上「天猫精灵」、「小爱同学」、「hey,siri」、「OK,Google」一众智能语音产品的3-4音节唤醒词来说,不管是初代Rokid Alien的“若琪”还是全新Rokid Glasses的“乐奇”,Rokid做到了只用双音节就能唤醒,交互体验更加自然。从4到2,其实是一个比较大的技术门槛。语音唤醒词音节越少,意味着误唤醒率越高,需要做的技术成本和测试成本越高。Rokid凭借过硬的技术实力,为用户带来了一流的交互自然感。
3.4 低功耗场景下的语音唤醒:既要灵敏,又要省电
像智能手表、智能眼镜这类便携式设备,对续航时间是比较敏感的。需要得在省电的前提下实现语音唤醒,方案有很多种,下面介绍其中适应性比较广的 “多级检测”:
- 一级:软硬 VAD 检测:VAD(语音活动检测)先判断有没有人说话 —— 硬件VAD靠简单电路检测声音强度,特别省电(微安级);不如不支持硬件VAD,也可以在协处理器或者多核异构的小核上运行软件VAD检测算法。
- 二级:小模型唤醒检测:如果VAD检测到有人说话,在协处理器或者多核异构的小核上加载小体积的唤醒模型,快速判断是不是唤醒词,这步耗电相对较少(微安级),响应快。实际应用过程中,可以适当调高这一级唤醒的灵敏度,来平衡功耗和唤醒率。
- 三级:大模型唤醒确认:如果小模型检测到唤醒词,再唤醒主核加载高精度的大模型来做唤醒词的二次确认。因为一级唤醒模型的灵敏度较高,可能会来相对偏高的误唤醒率,所以这一步主要是为了降低误唤醒。这样就实现了大模型和高功耗的主核只在必要时才启用,能大幅省电。
对于Rokid Glasses来说,前面我们提到过,它搭载了一个RT600芯片,专门用于处理语音识别等需求。RT600支持多达 5 种功耗模式:Active(活动)、Sleep(睡眠)、Deep Sleep(深度睡眠)、Deep Power Down(深度掉电)和 Full Deep Power Down(完全深度掉电)。在 AI 眼镜待机时,RT600 可以进入功耗极低的深度睡眠模式,仅保留语音活动检测(VAD)功能,一旦检测到用户的唤醒词或物理按键激活,便能以微秒级的速度唤醒自身及主控AP,同时最大限度地延长 AI 眼镜的待机时间 。
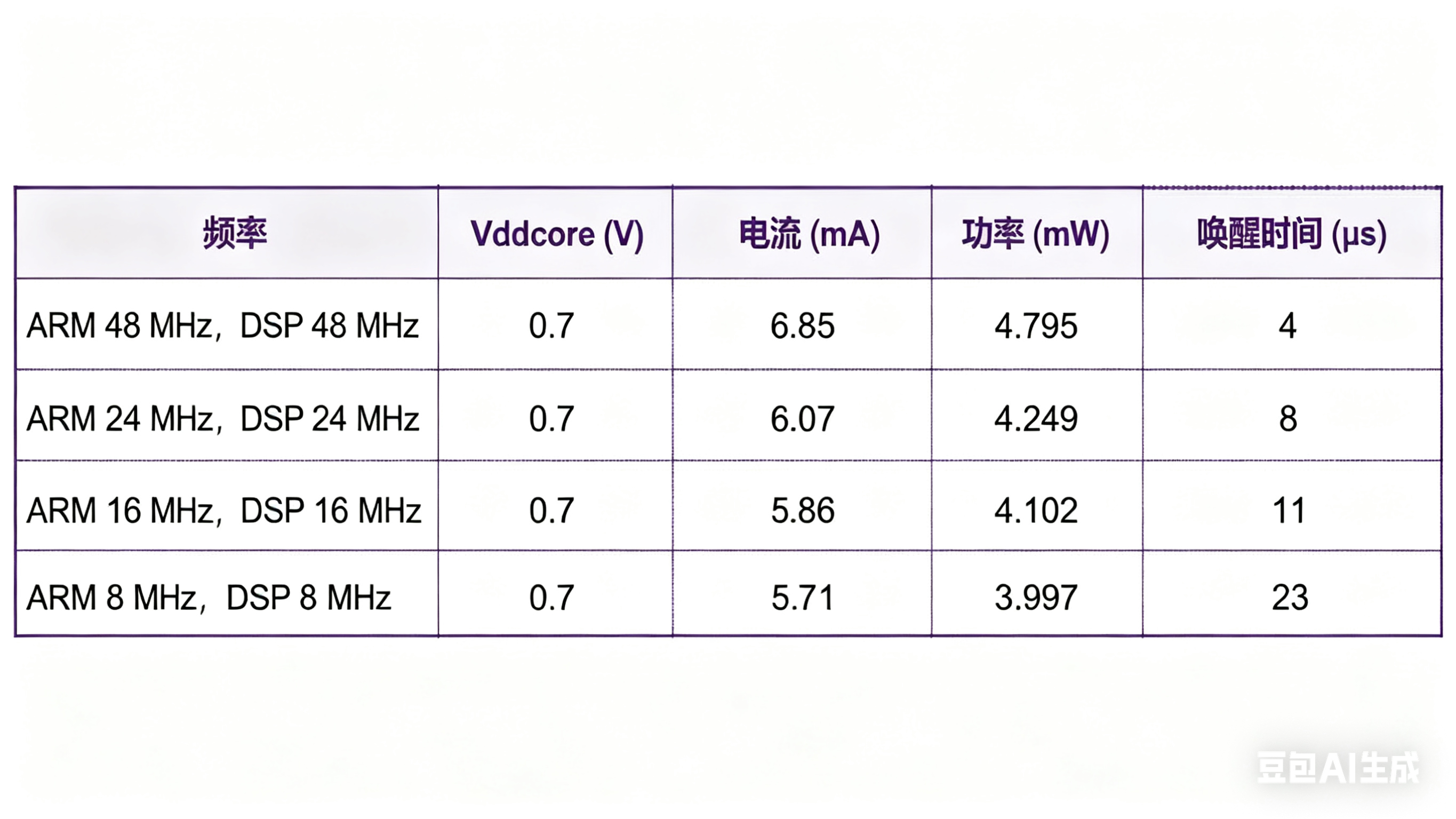
恩智浦半导体官方的测试数据展示了 RT600 系列芯片在不同工作频率下的核心功耗。可以看到,即使在 48 MHz 的活动状态下,其核心功率也仅为 4.795 毫瓦,这与动辄数十毫瓦甚至百瓦级的应用处理器形成了鲜明对比,可以说是 AI 眼镜的低功耗“辅助神器”。
性能指标评估:“乐奇”唤醒体验的量化标准
性能指标设计需全面覆盖 “唤醒 - 识别 - 交互” 全流程,且需清晰界定各指标间的权衡关系,为系统优化提供明确方向。当前阶段,我们暂聚焦于唤醒流程,其核心指标主要包含如下:
| 指标 | 定义 | 标准值(主流产品) | 影响因素 |
|---|---|---|---|
| 唤醒率 | 成功唤醒次数 / 总尝试次数 | ≥95%(30dB SNR),≥70%(0dB SNR) | 麦克风 SNR、BF 效果、WWD 模型等 |
| 误唤醒率 | 无意图唤醒次数 / 单位时间 | ≤1 次 / 48小时 | 动态阈值,模型能力 |
| 唤醒响应延时 | 说完唤醒词到设备响应的时间 | ≤500ms,最长不可超过1秒 | DSP算力、模型效率、提示音等播放延时 |
| 唤醒距离 | 可靠唤醒的最远距离 | 远场唤醒:5-8 米(8 麦阵列) | 麦克风灵敏度、音腔设计 |
总结
从初代Rokid Alien到全新Rokid Glasses,从“若琪”到“乐奇”的唤醒词迭代,不仅是产品形态的升级,更是Rokid在人机交互领域深耕的缩影——“乐奇”之所以能实现应声响应,核心源于硬件、软件与性能指标的全链路协同。硬件层面,4麦阵列凭借精准的定向收音与高信噪比保障“听得到”,双立体声骨传导喇叭减少回声干扰,而骁龙AR1与恩智浦RT600组成的双芯片架构,既以骁龙AR1承载高负载任务,又靠RT600的低功耗特性实现待机时的持续监听;软件层面,回声消除(AEC)、前端信号处理(SGP)与唤醒词检测(WWD)形成闭环,不仅滤除杂音、增强人声,更突破双音节唤醒的技术门槛,在降低误唤醒率的同时提升交互自然感。最终,这套技术体系让“乐奇”不仅是一个唤醒指令,更将科技的便捷与陪伴的温度融合,延续了Rokid对卓越人机交互体验的始终追求。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号