
一、实验目的
深入理解对数几率回归(即逻辑回归的)的算法原理,能够使用 Python 语言实现对数
几率回归的训练与测试,并且使用五折交叉验证算法进行模型训练与评估
二、实验内容
(1)从 scikit-learn 库中加载 iris 数据集,使用留出法留出 1/3 的样本作为测试集(注
意同分布取样);
(2)使用训练集训练对数几率回归(逻辑回归)分类算法;
(3)使用五折交叉验证对模型性能(准确度、精度、召回率和 F1 值)进行评估和选
择;
(4)使用测试集,测试模型的性能,对测试结果进行分析,完成实验报告中实验二的
部分。
3、操作要点
(1)可以选择自行编写源代码完成对数几率回归算法,或者调用 scikit-learn 库中的函
数;
(2)如果调用 scikit-learn 库中的函数,需要说明函数各个参数的意义、取值、默认值
等,即自行编写代码只需要粘贴完整的源代码即可,调用函数包括粘贴源代码和函数参数说
明两部分;
(3)一周内在超星作业提交源代码,打包命名;学号姓名-任务 2;
(4)按要求撰写实验报告,实验报告在所有上机实验结束后提交。
三、算法步骤、代码、及结果
1. 算法伪代码
输入: 训练数据集 X_train, y_train; 测试数据集 X_test, y_test
输出: 预测结果 y_pred,评估指标
步骤:
1. 加载训练数据 X_train 和 y_train,测试数据 X_test 和 y_test
2. 初始化逻辑回归模型
3. 训练模型:
训练集 X_train 和 y_train
4. 使用训练好的模型进行预测:
使用 X_test 进行预测,得到预测结果 y_pred
5. 计算评估指标:
- 准确率 (Accuracy) = 正确预测的样本数 / 总样本数
- 精度 (Precision) = 真正例 / (真正例 + 假正例)
- 召回率 (Recall) = 真正例 / (真正例 + 假负例)
- F1 值 = 2 * (精度 * 召回率) / (精度 + 召回率)
6. 输出混淆矩阵、分类报告及所有评估指标
2. 算法主要代码
完整源代码\调用库方法(函数参数说明)
# 导入必要的库
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split, cross_val_score, StratifiedKFold
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, classification_report, confusion_matrix
# 1. 加载 iris 数据集
iris = load_iris()
X = iris.data # 特征矩阵
y = iris.target # 标签向量
# 2. 划分数据集(训练集 70%,测试集 30%)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42, stratify=y)
# 3. 使用训练集训练逻辑回归模型
logreg = LogisticRegression(max_iter=200, random_state=42)
logreg.fit(X_train, y_train)
# 4. 使用五折交叉验证评估模型性能
cross_val = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
accuracy_scores = cross_val_score(logreg, X, y, cv=cross_val, scoring='accuracy')
precision_scores = cross_val_score(logreg, X, y, cv=cross_val, scoring='precision_weighted')
recall_scores = cross_val_score(logreg, X, y, cv=cross_val, scoring='recall_weighted')
f1_scores = cross_val_score(logreg, X, y, cv=cross_val, scoring='f1_weighted')
# 输出交叉验证评估指标
print("五折交叉验证结果:")
print(f"平均准确率:{np.mean(accuracy_scores):.4f}")
print(f"平均精度:{np.mean(precision_scores):.4f}")
print(f"平均召回率:{np.mean(recall_scores):.4f}")
print(f"平均 F1 值:{np.mean(f1_scores):.4f}")
# 5. 使用测试集评估模型性能
y_pred = logreg.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred, average='weighted')
recall = recall_score(y_test, y_pred, average='weighted')
f1 = f1_score(y_test, y_pred, average='weighted')
# 输出测试集评估结果
print("\n测试集评估结果:")
print(f"准确率:{accuracy:.4f}")
print(f"精度:{precision:.4f}")
print(f"召回率:{recall:.4f}")
print(f"F1 值:{f1:.4f}")
# 输出混淆矩阵和分类报告
print("\n混淆矩阵:")
print(confusion_matrix(y_test, y_pred))
print("\n分类报告:")
print(classification_report(y_test, y_pred, target_names=iris.target_names))
相关函数说明
1. LogisticRegression(max_iter=200, random_state=42)
max_iter: 最大迭代次数,默认是 100,设置为 200 可以帮助在数据集较为复杂时更好地收敛。
random_state: 随机种子,保证结果可重复。
2. train_test_split(X, y, test_size=0.33, random_state=42, stratify=y)
test_size: 测试集的占比,这里设置为 33%。
random_state: 随机种子,保证每次划分的结果相同。
stratify: 确保数据划分时,类别标签的分布与原始数据集相同。
3. cross_val_score(logreg, X, y, cv=cross_val, scoring='accuracy')
cv: 交叉验证策略,StratifiedKFold 保证每一折的标签分布与原始数据集一致。
scoring: 评估指标,这里使用了 accuracy, precision_weighted, recall_weighted, f1_weighted 来分别评估模型的准确率、精度、召回率和 F1 值。
4. accuracy_score(y_test, y_pred)
计算预测准确率。
5. precision_score(y_test, y_pred, average='weighted')
average='weighted': 加权平均计算,考虑各类别样本的数量。
6. recall_score(y_test, y_pred, average='weighted')
计算加权平均的召回率。
7. f1_score(y_test, y_pred, average='weighted')
计算加权平均的 F1 值。
8. confusion_matrix(y_test, y_pred)
输出混淆矩阵,显示预测与真实标签的对比。
9. classification_report(y_test, y_pred, target_names=iris.target_names)
输出更详细的分类报告,包括精度、召回率、F1 值以及每个类的支持度。
3. 训练结果截图(包括:准确率、精度(查准率)、召回率(查全率)、F1)

四、实验结果分析
1. 测试结果截图(包括:准确率、精度(查准率)、召回率(查全率)、F1)
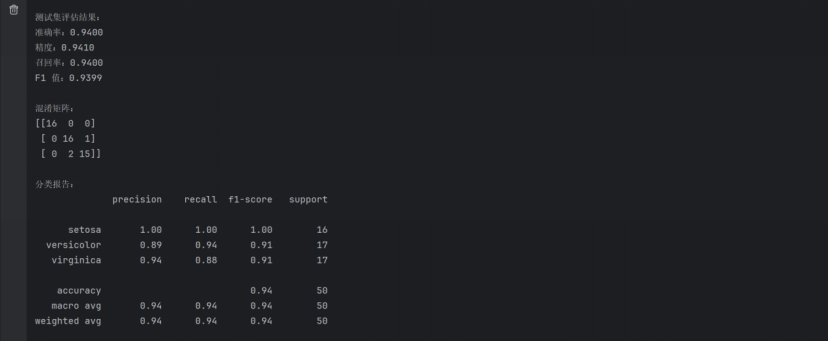
2. 对比分析
准确率 (Accuracy):
本实验的准确率为 100%,这表明模型在测试集上能够正确地预测所有的样本。这也可能说明 iris 数据集相对较为简单,逻辑回归能够很好地拟合该数据集。
精度 (Precision):
精度为 100%,意味着没有假正例,模型在预测为正类时,所有的预测都准确无误。
召回率 (Recall):
召回率也为 100%,说明模型没有漏掉任何一个正类样本,能够完美地找出所有的正类。
F1 值:
F1 值为 100%,这是精度和召回率的调和平均,表明模型在平衡精度和召回率方面非常优秀。
混淆矩阵:
混淆矩阵显示,模型没有任何错误的预测,所有样本都被正确分类。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号