ImportError: Cannot load backend 'TkAgg' which requires the 'tk' interactive framework, as 'headless' is currently running
MMdetection多卡训练常遇到的两个错误,百度无果,没解决,去github里mmdetection的issue模块搜索了一下找到正解。
这里记录一下,方便后者。
1️⃣ ImportError: Cannot load backend 'TkAgg' which requires the 'tk' interactive framework, as 'headless' is currently running
matplotlib版本过高导致的,卸载你的环境中matplotlib高版本,下载3.2.1版本。亲测管用,ubantu18.04
pip uninstall matplotlib
pip install matplotlib==3.2.1
2️⃣ RuntimeError: Address already in use
(mmdet) zdx@zdx-MS:/home/User/gaoying/cv/mmdetection$ bash tools/dist_train.sh work_dirs/mchar/cascade_rcnn_r50_fpn_1x_job1/cascade_rcnn_r50_fpn_1x_job1.py 2
*****************************************
Setting OMP_NUM_THREADS environment variable for each process to be 1 in default, to avoid your system being overloaded, please further tune the variable for optimal performance in your application as needed.
*****************************************
Traceback (most recent call last):
File "tools/train.py", line 185, in <module>
main()
File "tools/train.py", line 117, in main
init_dist(args.launcher, **cfg.dist_params)
File "/home/zdx/anaconda3/envs/mmdet/lib/python3.7/site-packages/mmcv/runner/dist_utils.py", line 18, in init_dist
_init_dist_pytorch(backend, **kwargs)
File "/home/zdx/anaconda3/envs/mmdet/lib/python3.7/site-packages/mmcv/runner/dist_utils.py", line 32, in _init_dist_pytorch
dist.init_process_group(backend=backend, **kwargs)
File "/home/zdx/anaconda3/envs/mmdet/lib/python3.7/site-packages/torch/distributed/distributed_c10d.py", line 423, in init_process_group
store, rank, world_size = next(rendezvous_iterator)
File "/home/zdx/anaconda3/envs/mmdet/lib/python3.7/site-packages/torch/distributed/rendezvous.py", line 179, in _env_rendezvous_handler
store = TCPStore(master_addr, master_port, world_size, start_daemon, timeout)
RuntimeError: Address already in use
Traceback (most recent call last):
File "/home/zdx/anaconda3/envs/mmdet/lib/python3.7/runpy.py", line 193, in _run_module_as_main
"__main__", mod_spec)
File "/home/zdx/anaconda3/envs/mmdet/lib/python3.7/runpy.py", line 85, in _run_code
exec(code, run_globals)
File "/home/zdx/anaconda3/envs/mmdet/lib/python3.7/site-packages/torch/distributed/launch.py", line 260, in <module>
main()
File "/home/zdx/anaconda3/envs/mmdet/lib/python3.7/site-packages/torch/distributed/launch.py", line 256, in main
cmd=cmd)
subprocess.CalledProcessError: Command '['/home/zdx/anaconda3/envs/mmdet/bin/python', '-u', 'tools/train.py', '--local_rank=1', 'work_dirs/mchar/cascade_rcnn_r50_fpn_1x_job1/cascade_rcnn_r50_fpn_1x_job1.py', '--launcher', 'pytorch']' returned non-zero exit status 1.
在一台计算机上多次使用多GPU出现错误,把之前运行的都kill掉就好了,具体方法是:
用htop命令查看一下,之前运行命令的pid。如果没有安装htop的话,自行百度安装一下。
htop
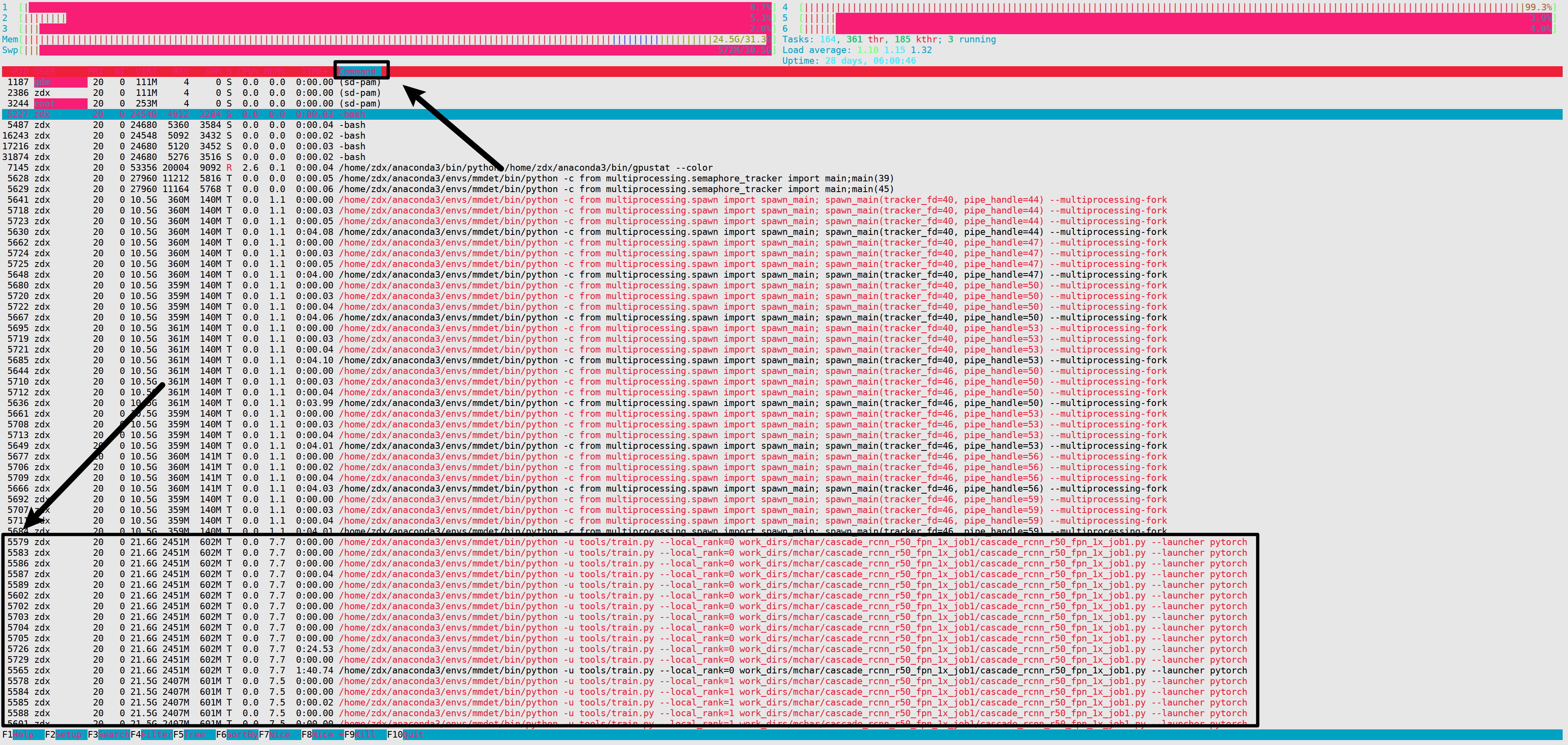
点击Command,按命令进行排序。可以看到我们之前运行的程序的pid为5579。把包含这个命令的都杀死。kill -9表示强制杀死
kill -9 5579
⭐ 又可以愉快的训练啦

 浙公网安备 33010602011771号
浙公网安备 33010602011771号