

EasyData实体标注工具使用-NASICON文献实体标注
NASIOCN文献NLP
命名实体识别
实体分类
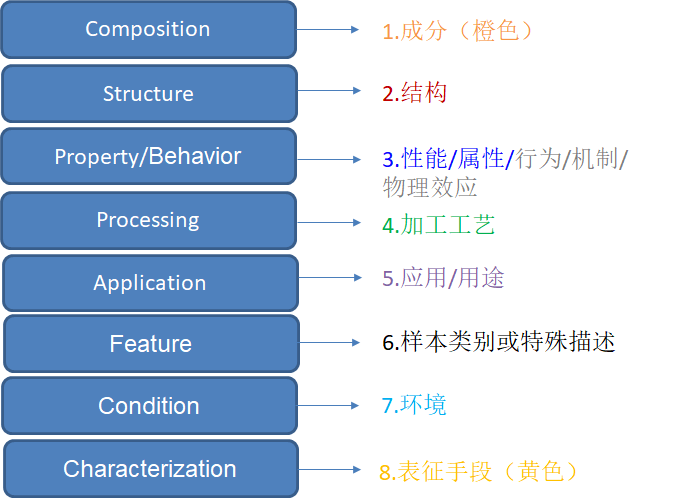
分类实体解释

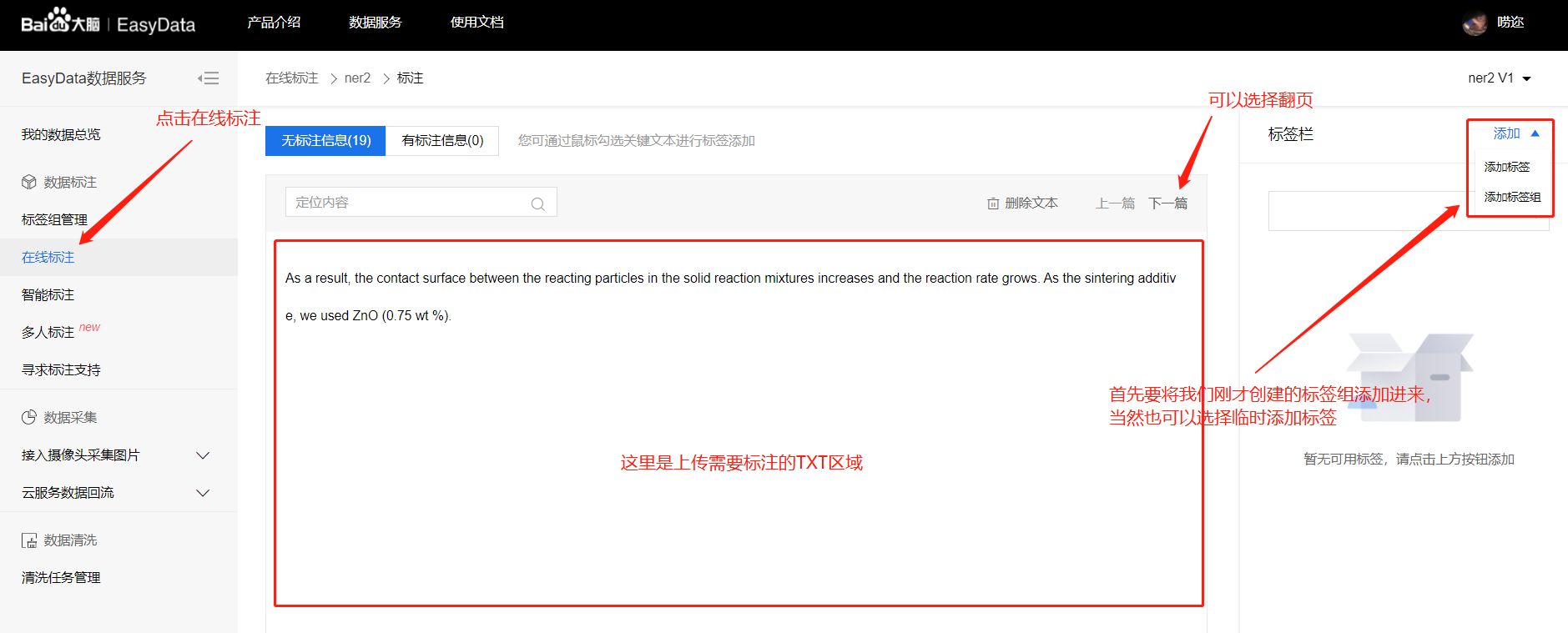
实体标注
前提
我们针对的是全文的标注,抽出来的自然段,我们要进行逐一的分词分句(单词之间是空格隔开的,句子之间是句点隔开的)并给每个单词打上标签(但我们只需要对文本中的名词打上我们预定义好的8个大类即可,后续的可代码处理)。
准备工作
-
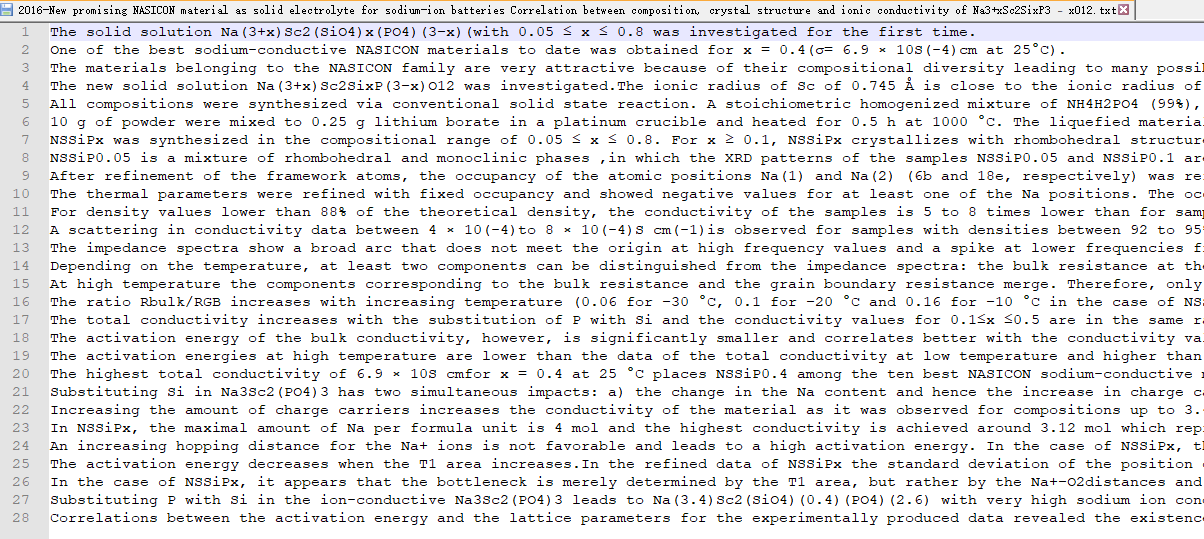
标注工具需要上传txt格式的中英文文本文献。
-
txt格式的文本文献是按行传入标注工具的,一行可以有多个句子或是一个段落。
-
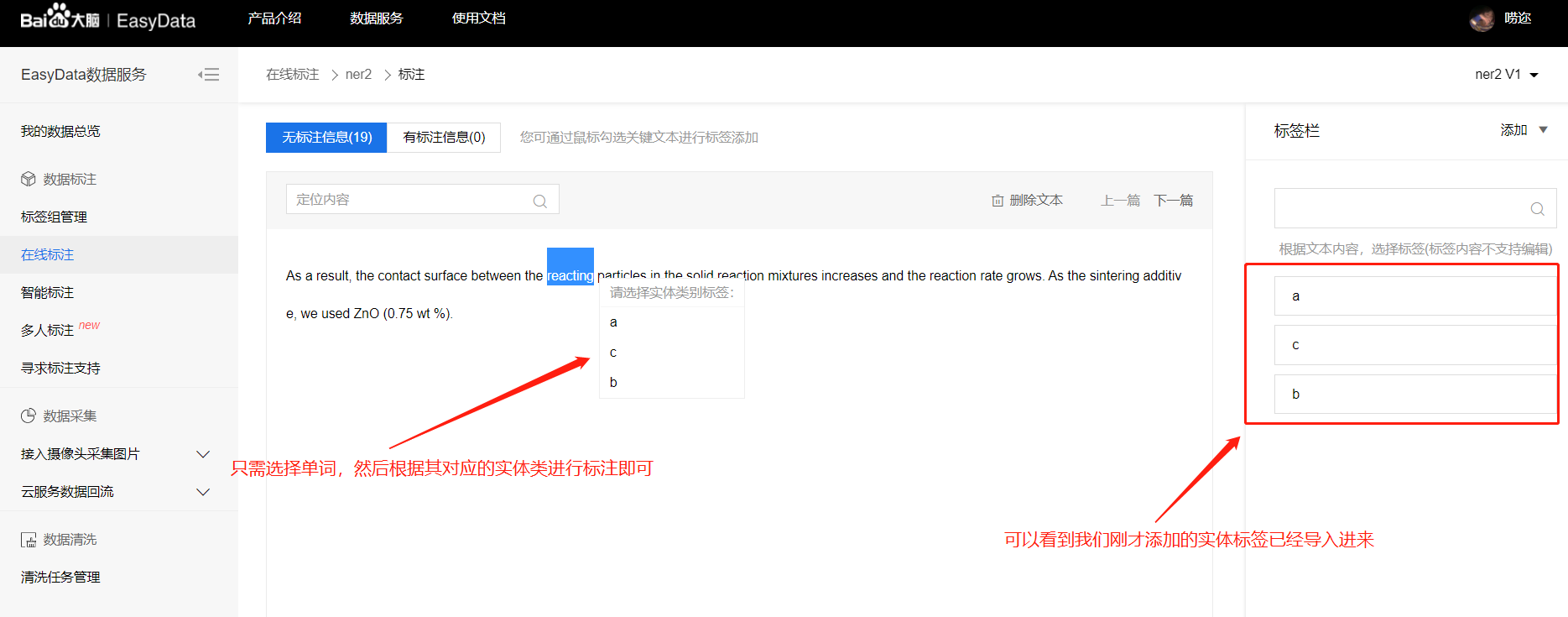
根据分好的实体类对每一行进行实体的标注(只需要标注出实体即可!)。
注意
- 从pdf提取要标注的文本,我们是基于全文做标注,文中有些段落我们并不需要就不用提取出来,但并不意味着我们只一句一句话的抽出来做标注,这会影响我们的数据质与量,甚至使我们花功夫提取出来的文本变得意义不大。
- 从pdf文献中提取出来的文本看到乱码的问题应处理一下,比如一个化学式中间的一些元素可能乱码,此时我们尽可能的手动的敲上去,实在无法处理的就将其删掉,以使得我们抽出来文本达到标注的要求(单词之间是空格隔开的,句子之间是句点隔开的)。
- 我们在进行标注的时候一定要仔细将我们标注的单词标注全,不要出现单词少标一个字母的情况,也不要出现标注的单词或者短语的前后多标注了一个空格的情况,这会给后续的处理带来很大的麻烦,甚至出错。
- 一定要认真对待我们的标注工作,多考虑一句话中的名词是否需要标注。一大段中我们就仅仅标注了两个或者三个名词的情况,会使我们的数据很稀疏,这种情况既花费了时间,而且还达不到标注要求的是会打回去重新标注的,所以大家一定要认真标注。
标注工具EasyData的使用
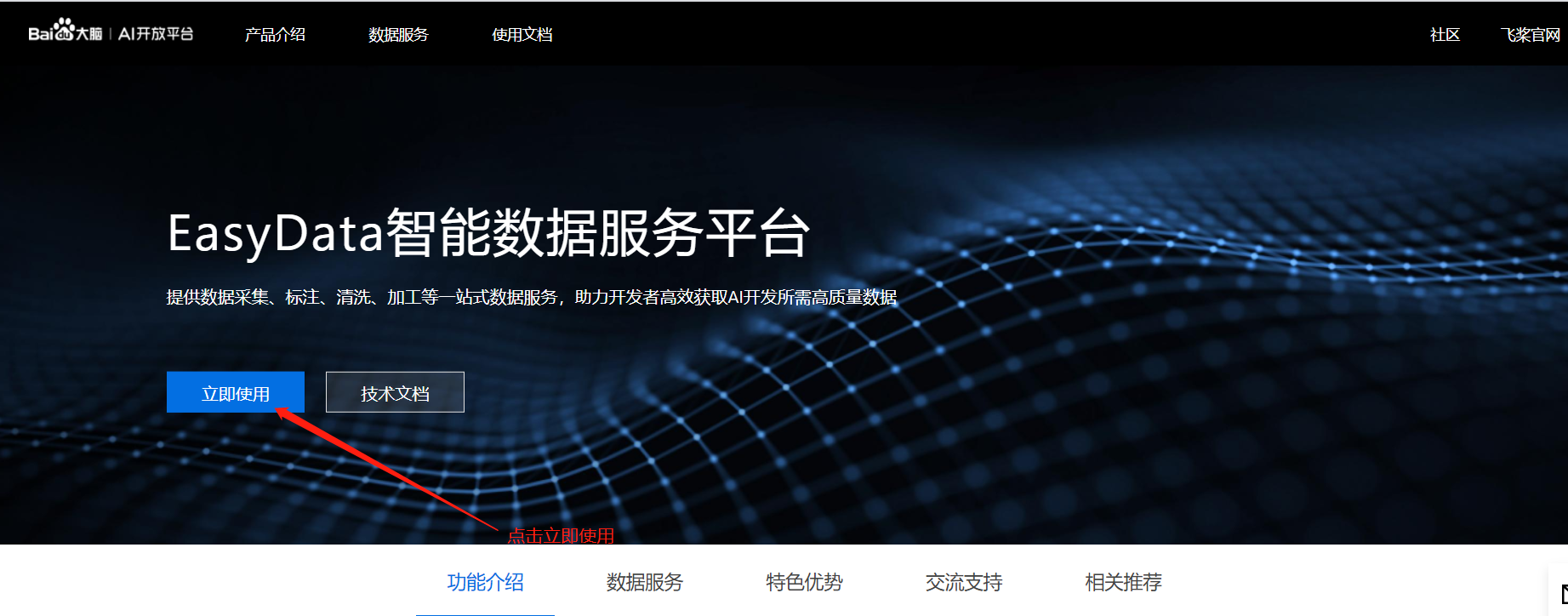
点击https://ai.baidu.com/easydata/进入标注工具首页
点击立即使用
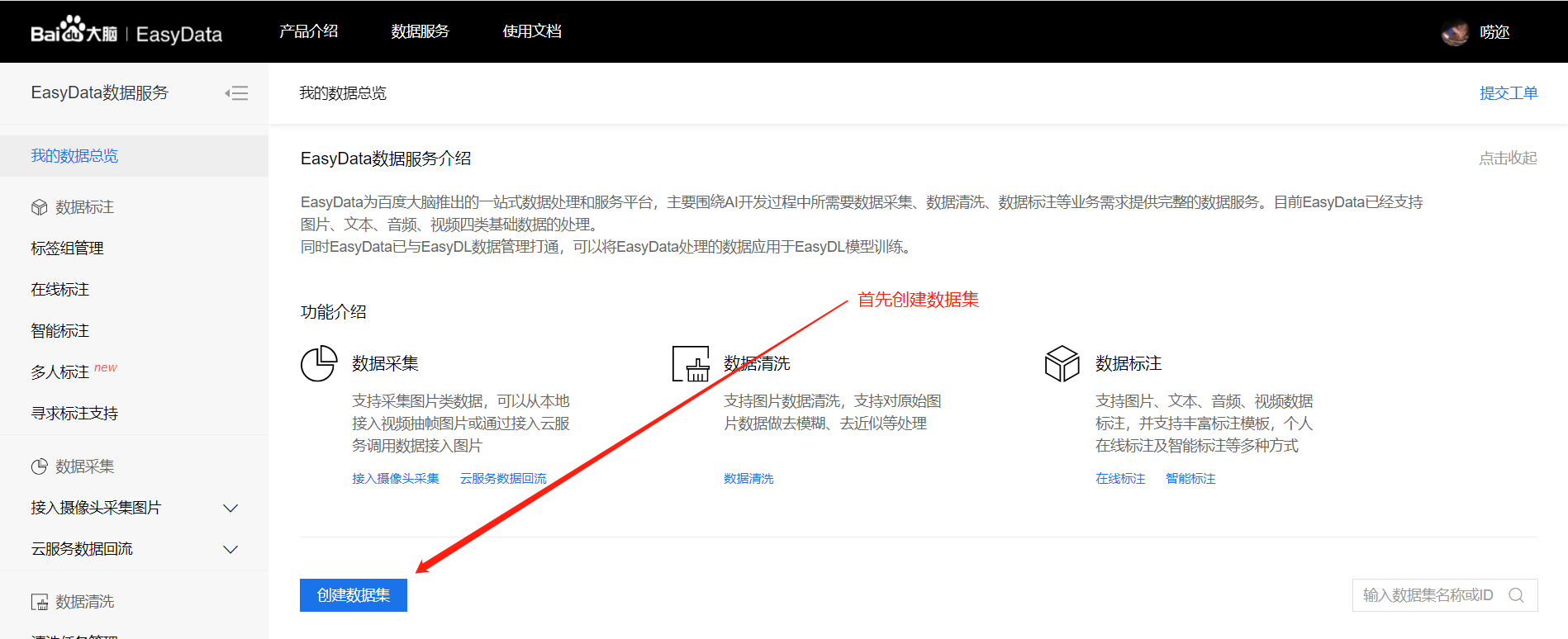
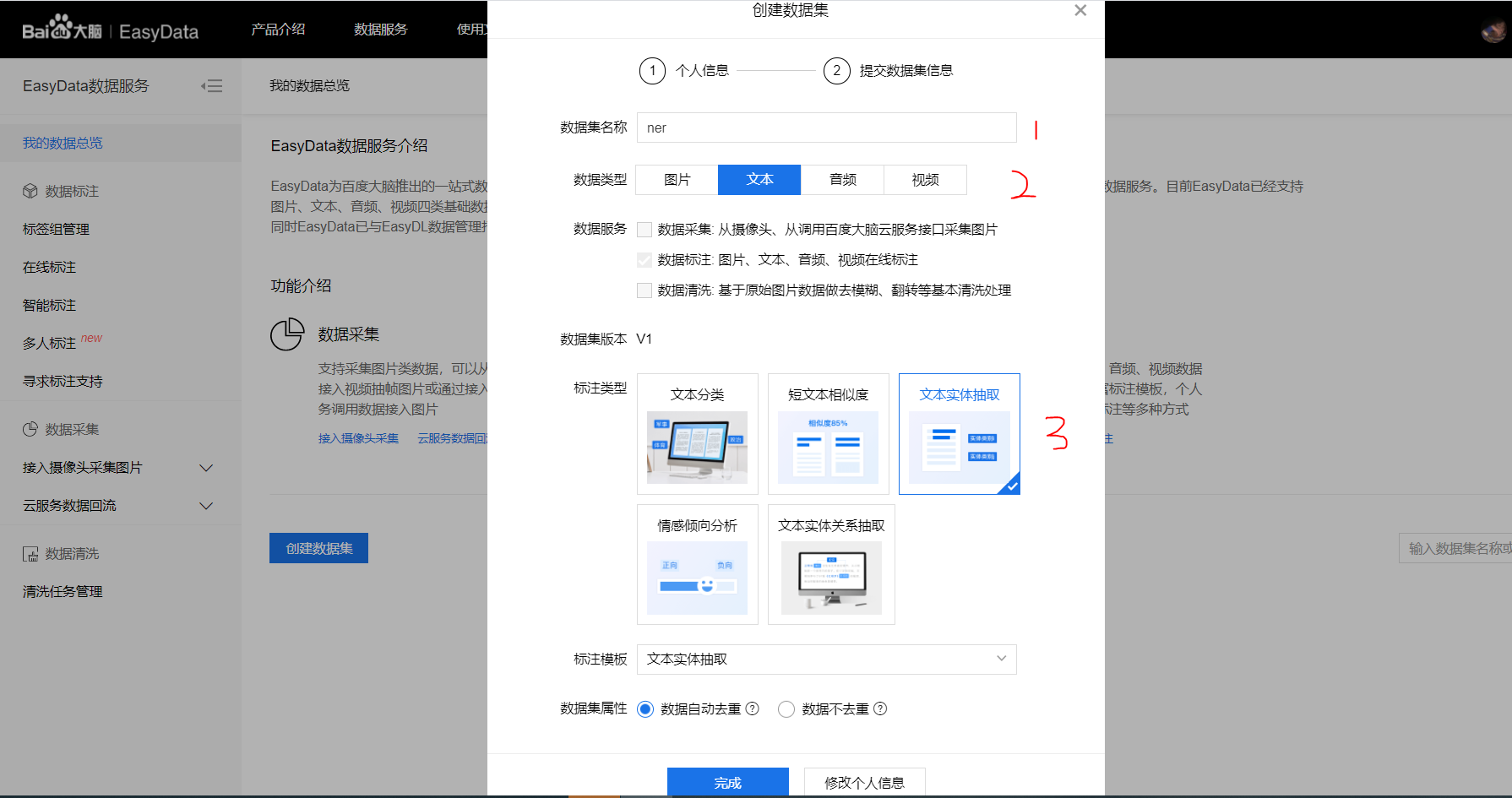
点击创建数据集
-
填写数据集名称
-
选择文本
-
选择文本实体抽取
-
点击完成
点击导入数据
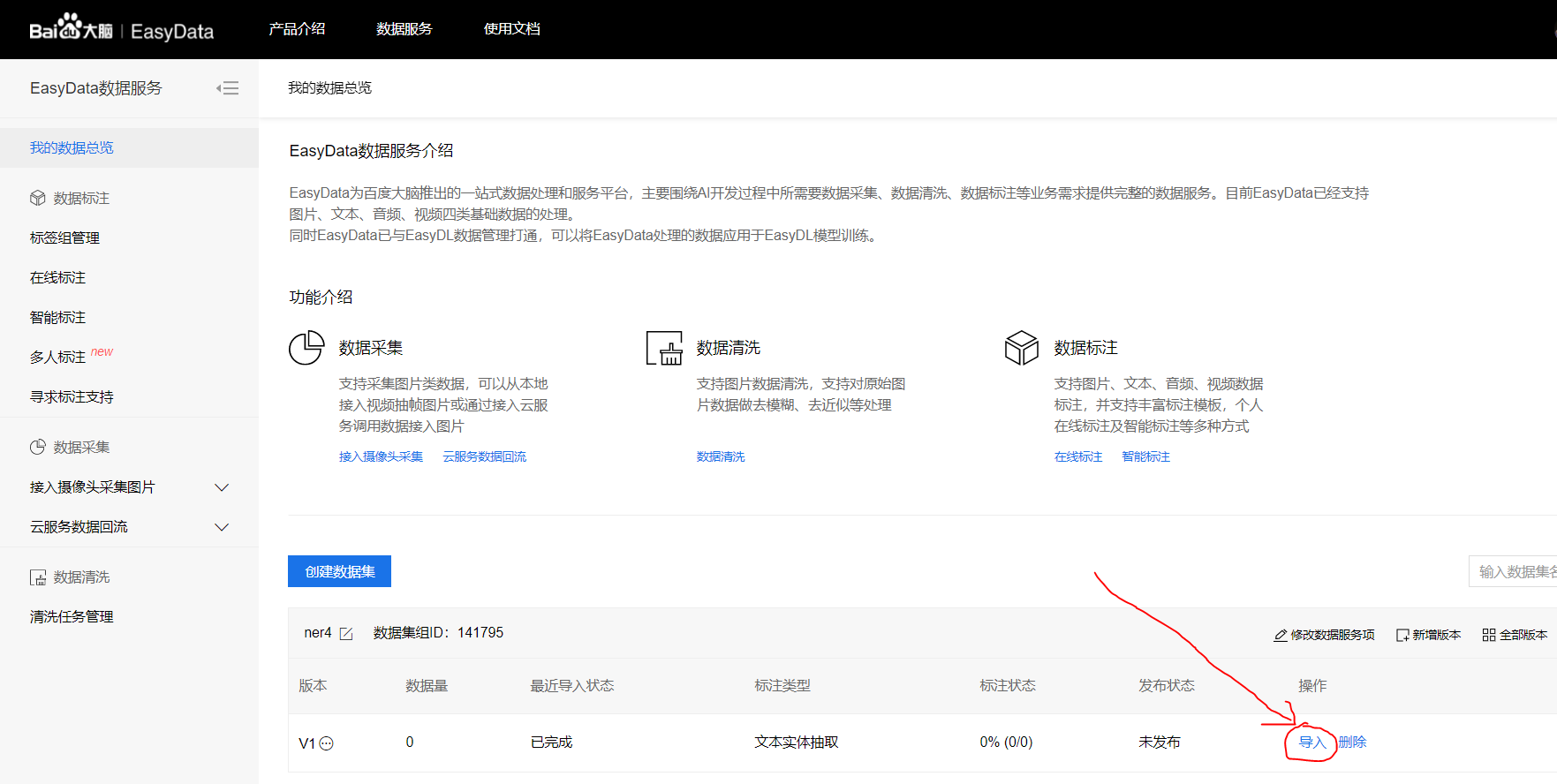
-
选择本地数据集
-
上传TXT文本
-
点击上传
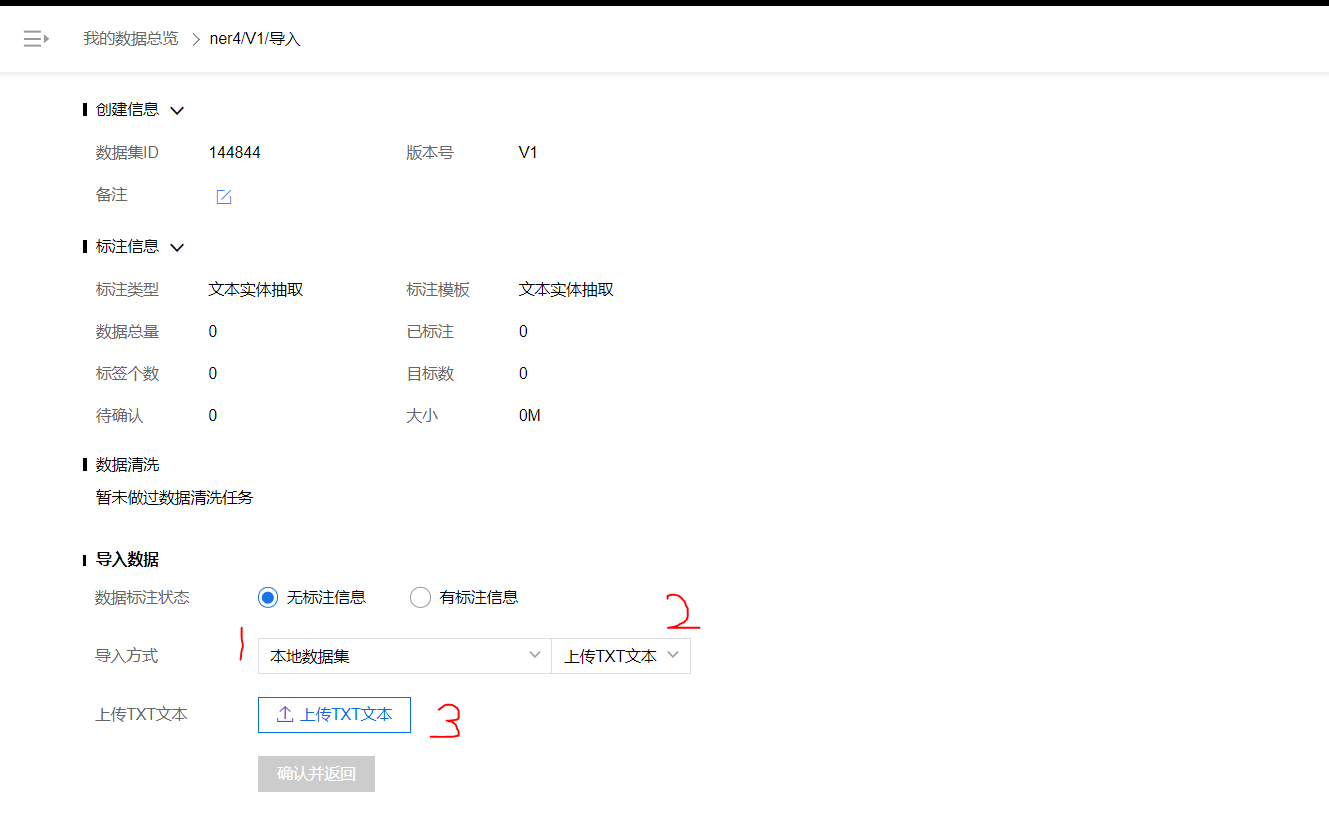
-
点击添加文件,选择本地需要标注的TXT文件
-
点击开始上传
-
确认并返回
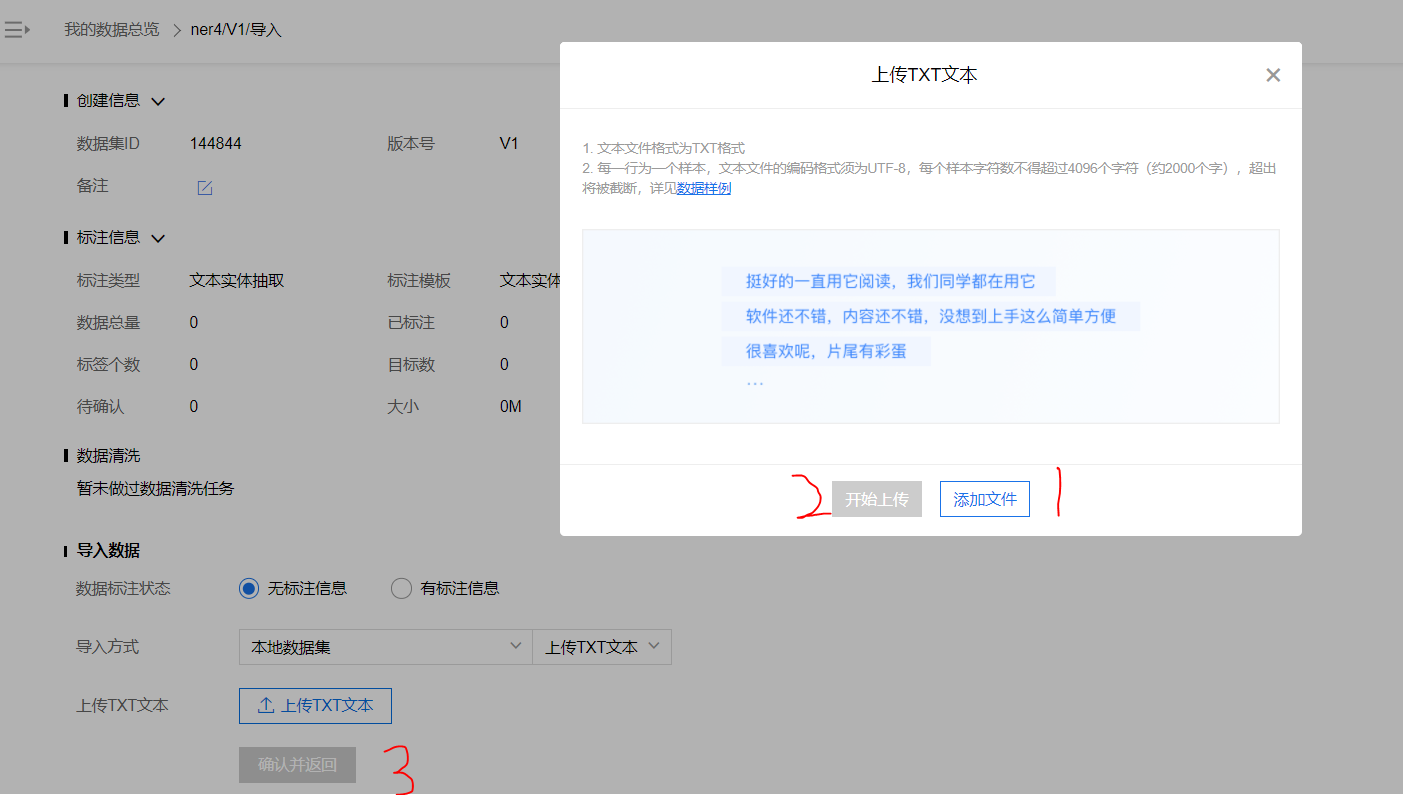
-
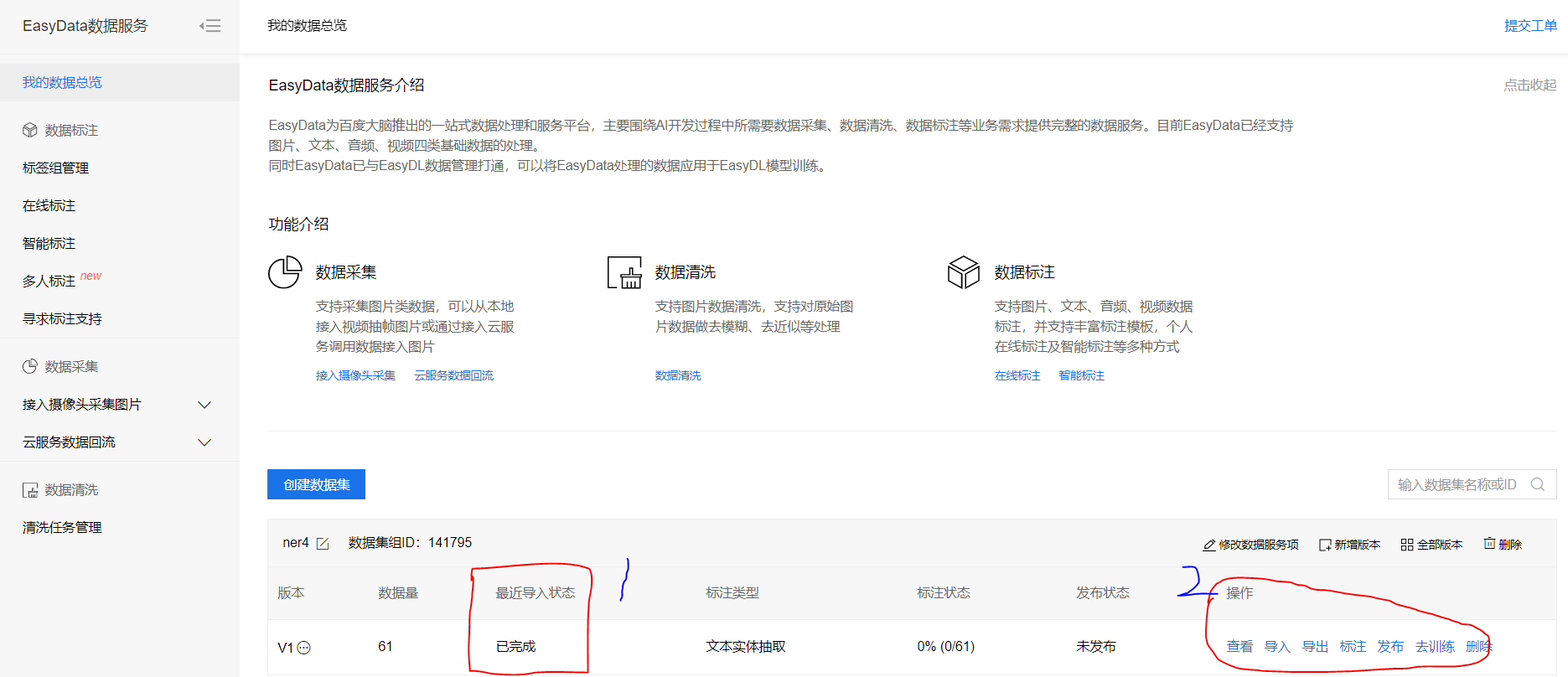
查看文件的导入状态
-
对传入的数据进行操作
-
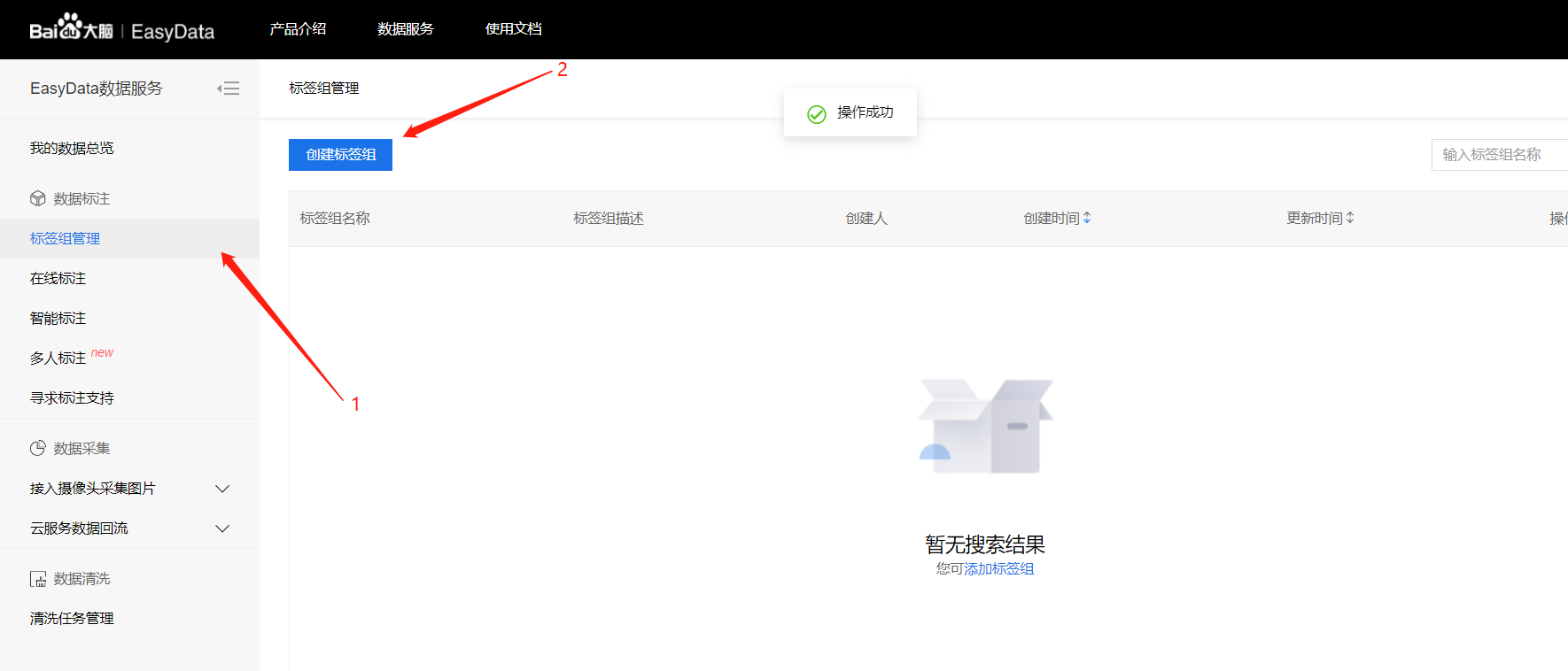
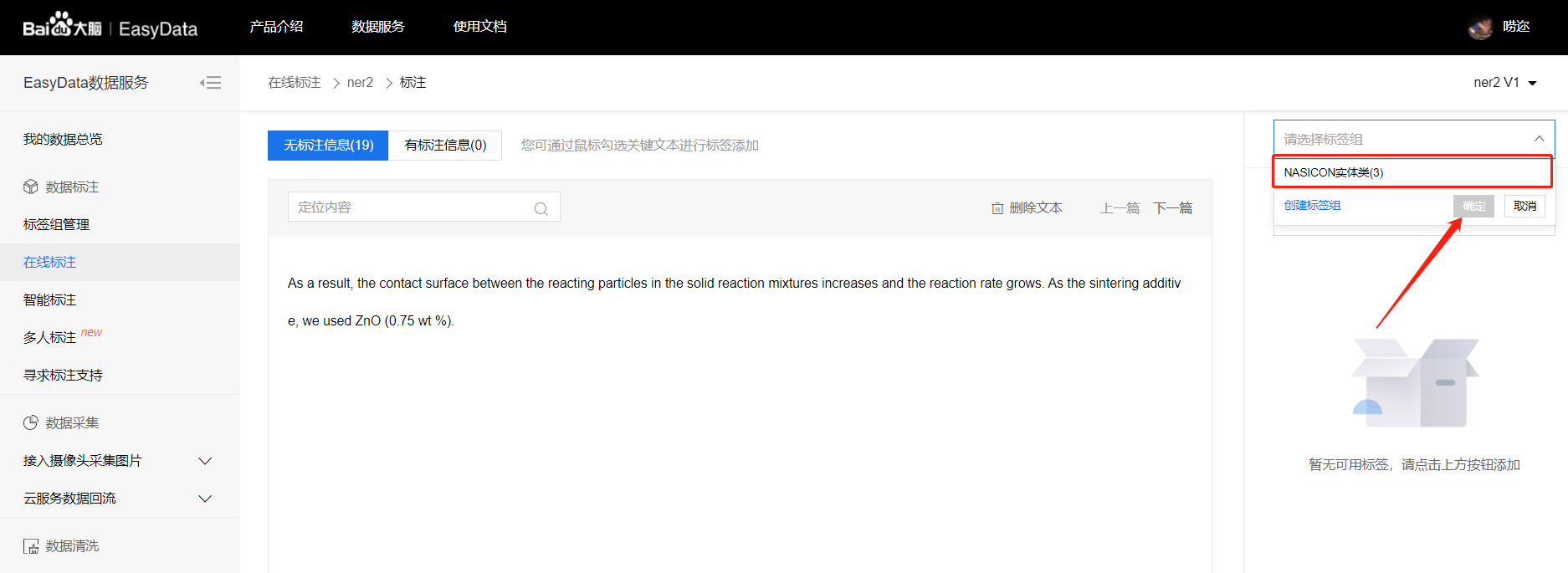
点击标签组管理
-
创建标签组
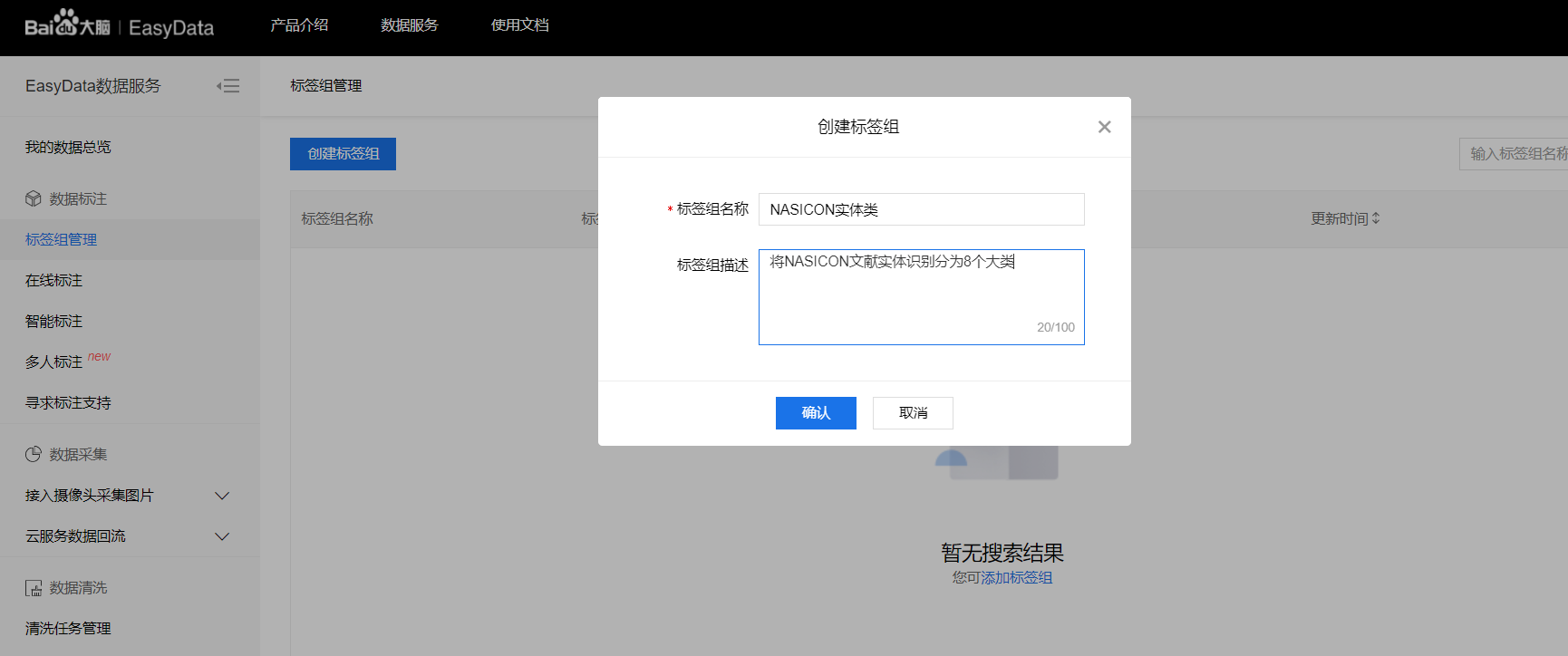
输入标签组名称点击确认即创建成功
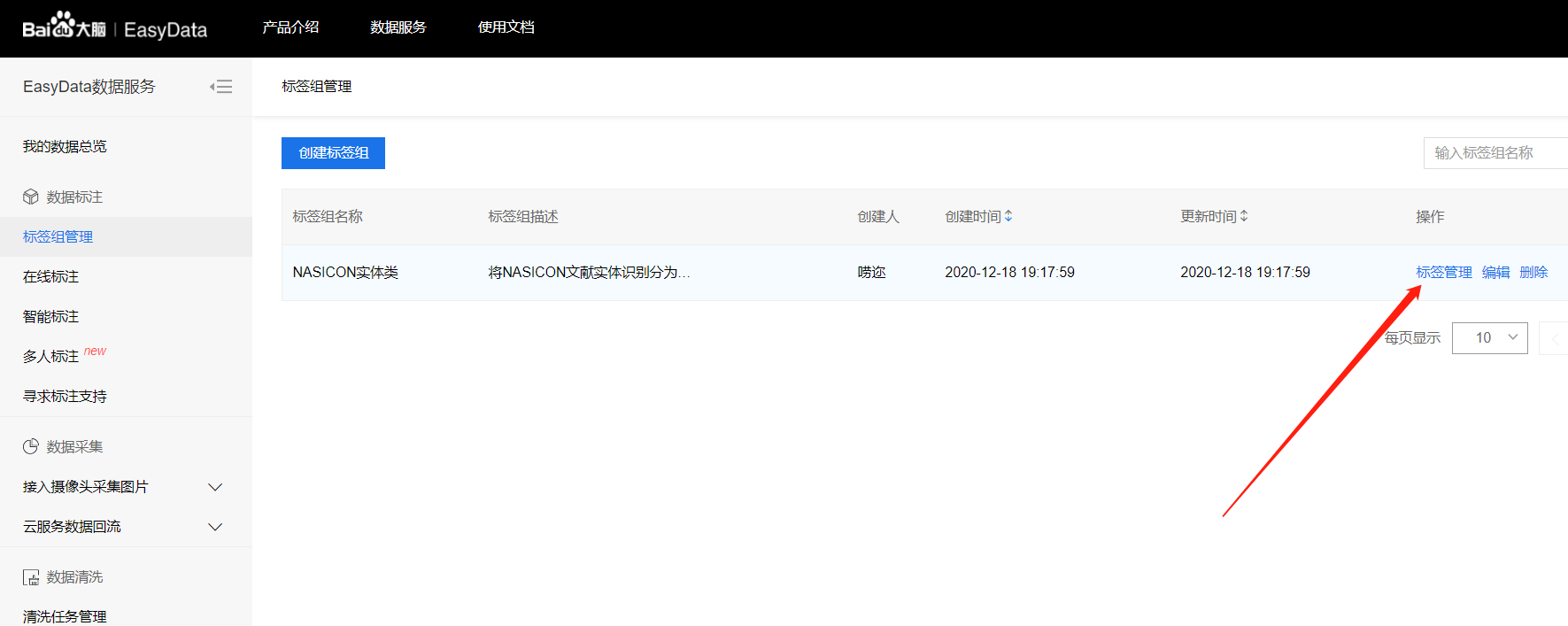
点击标签管理
-
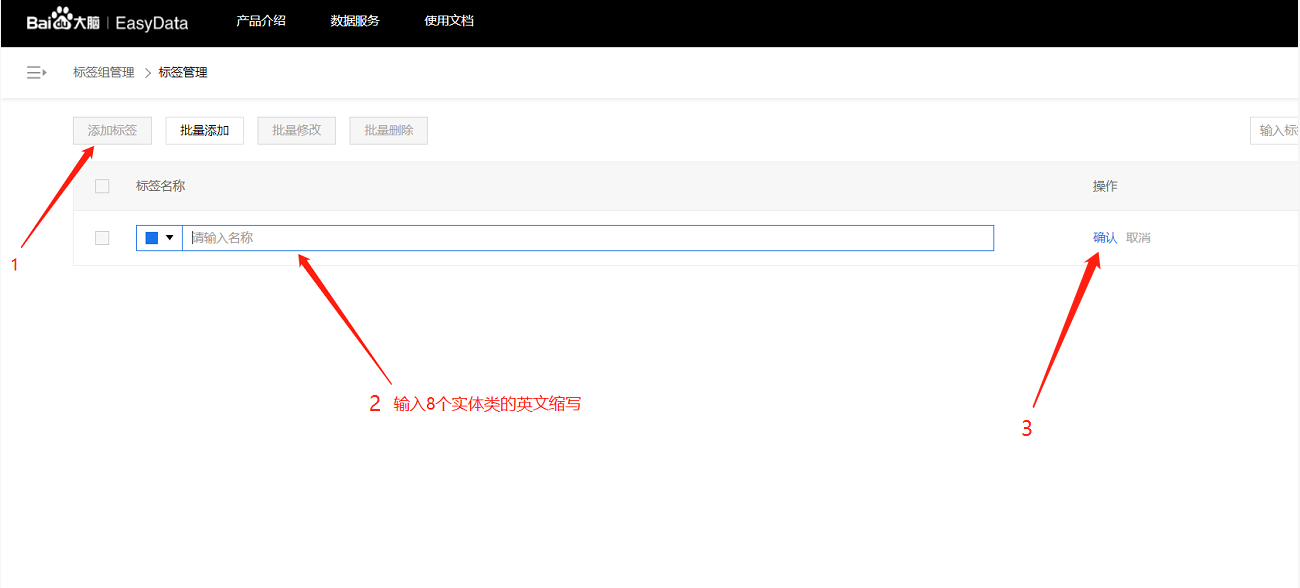
点击添加标签
-
输入标签的名称点击确认即可
至此我们的TXT已经标注结束
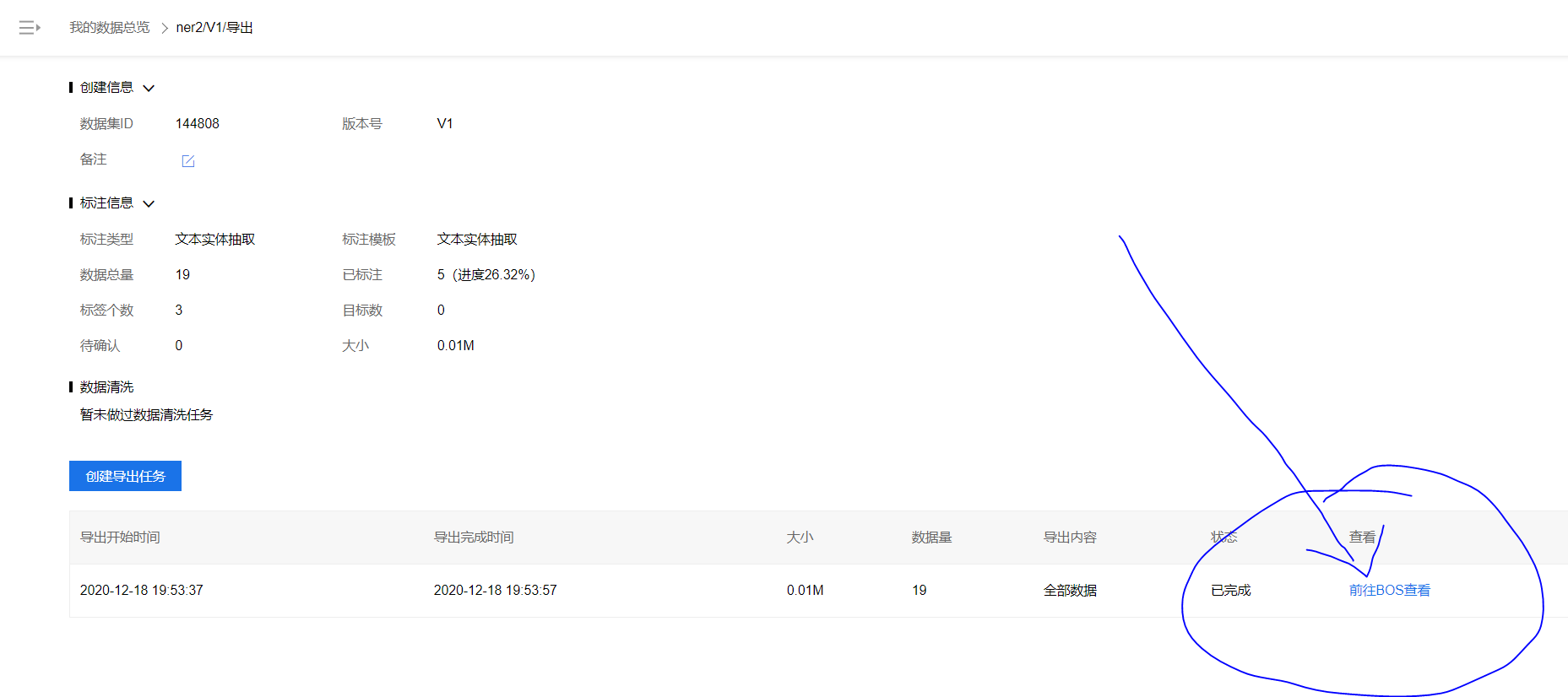
已标注数据的导出
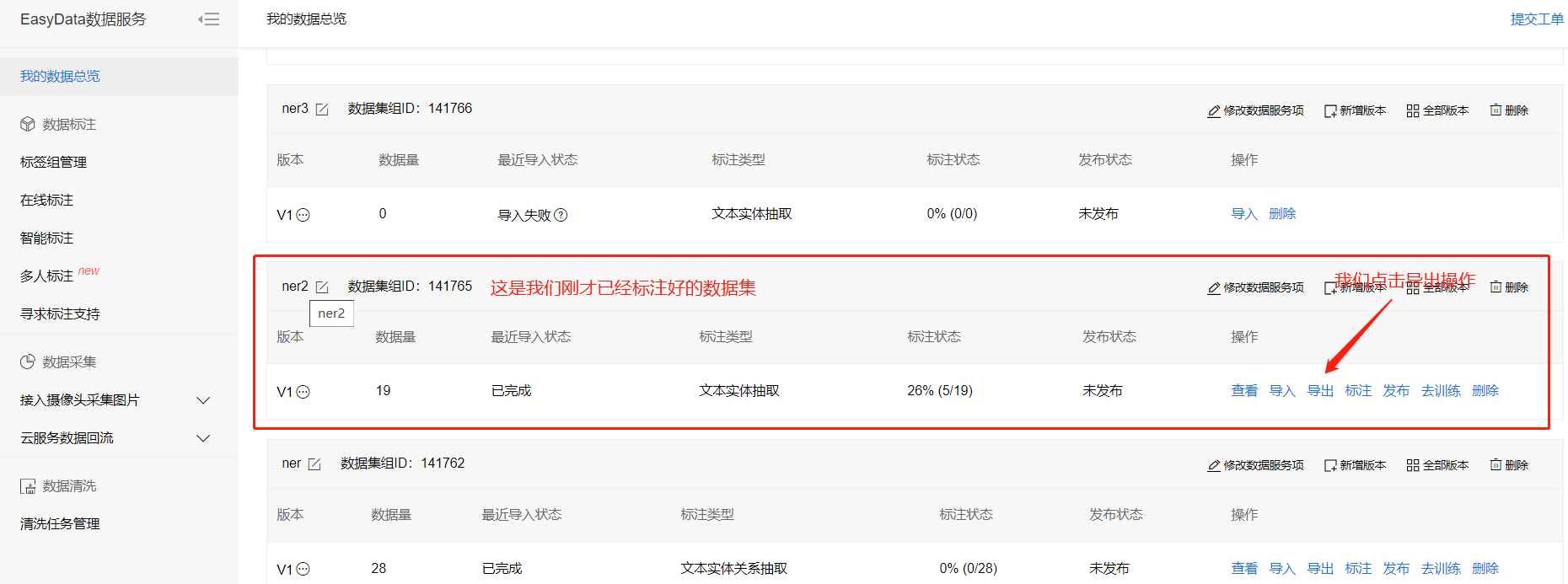
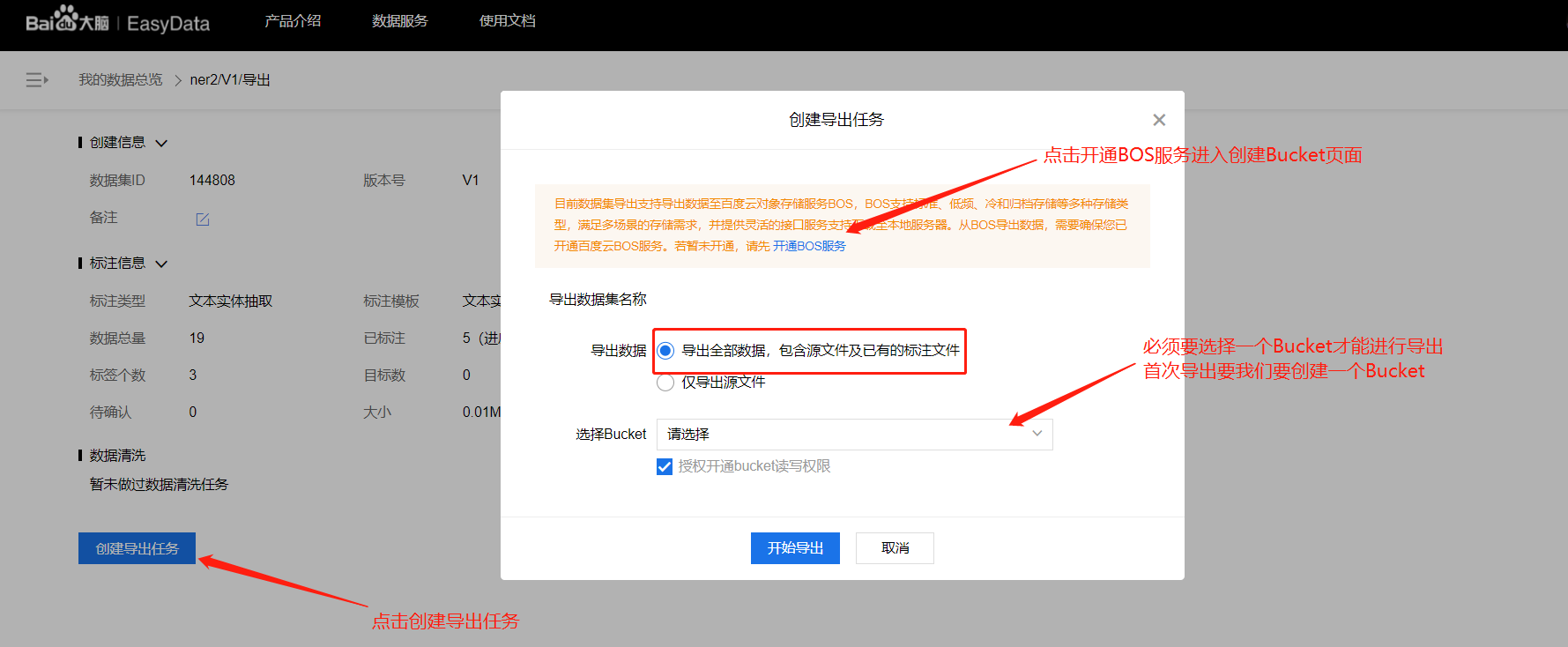
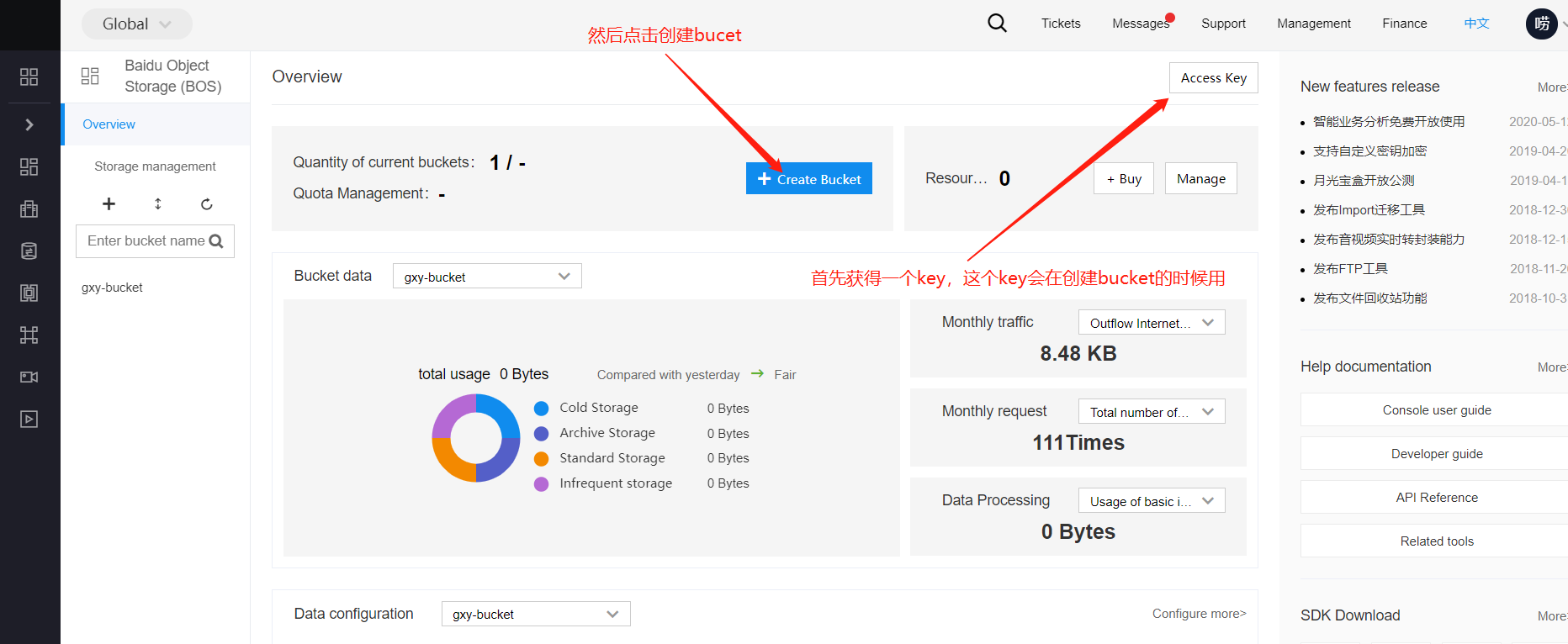
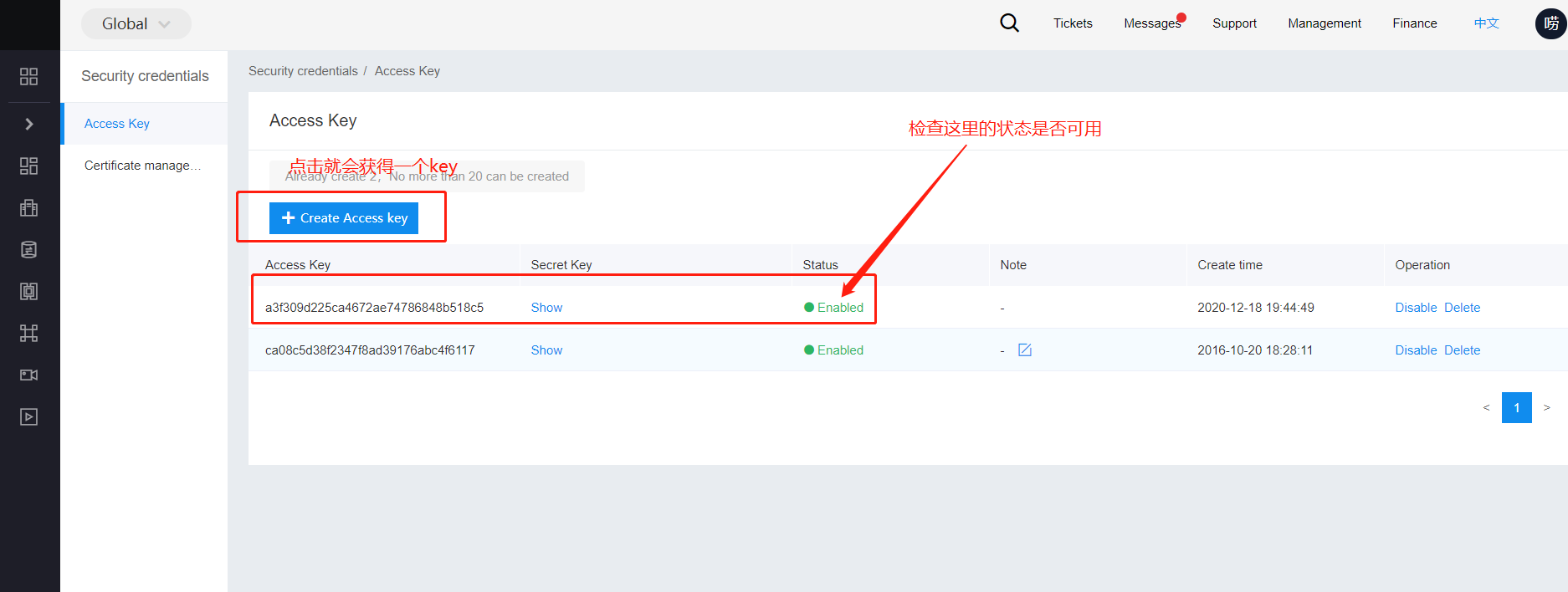
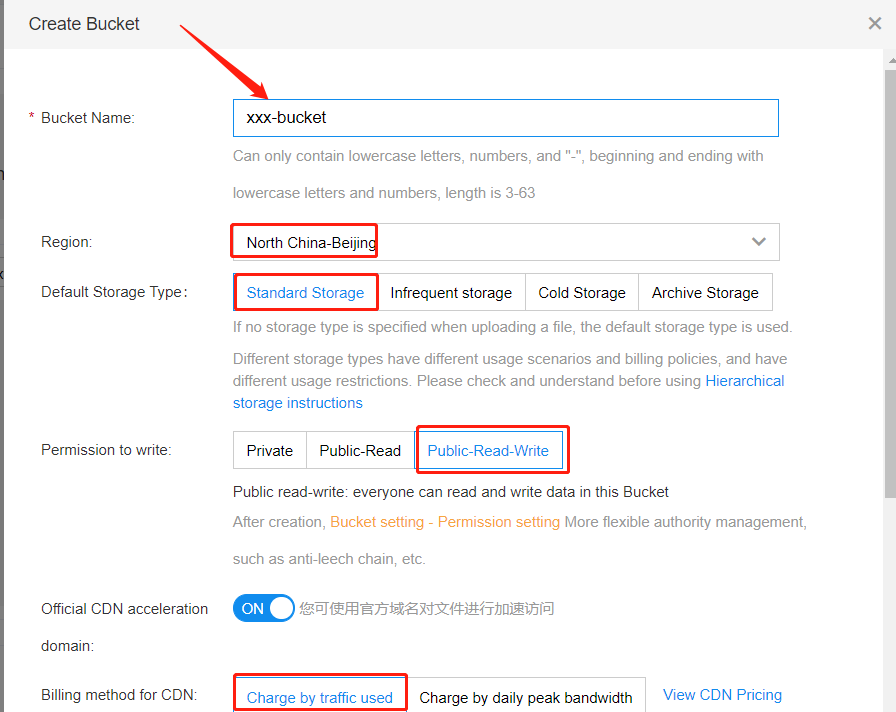
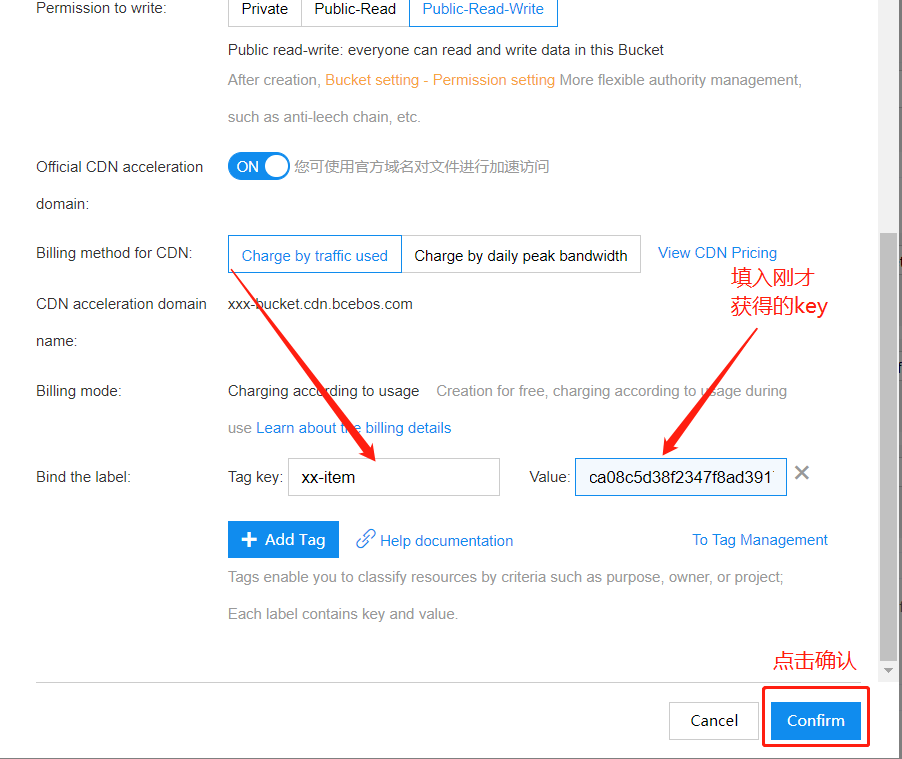
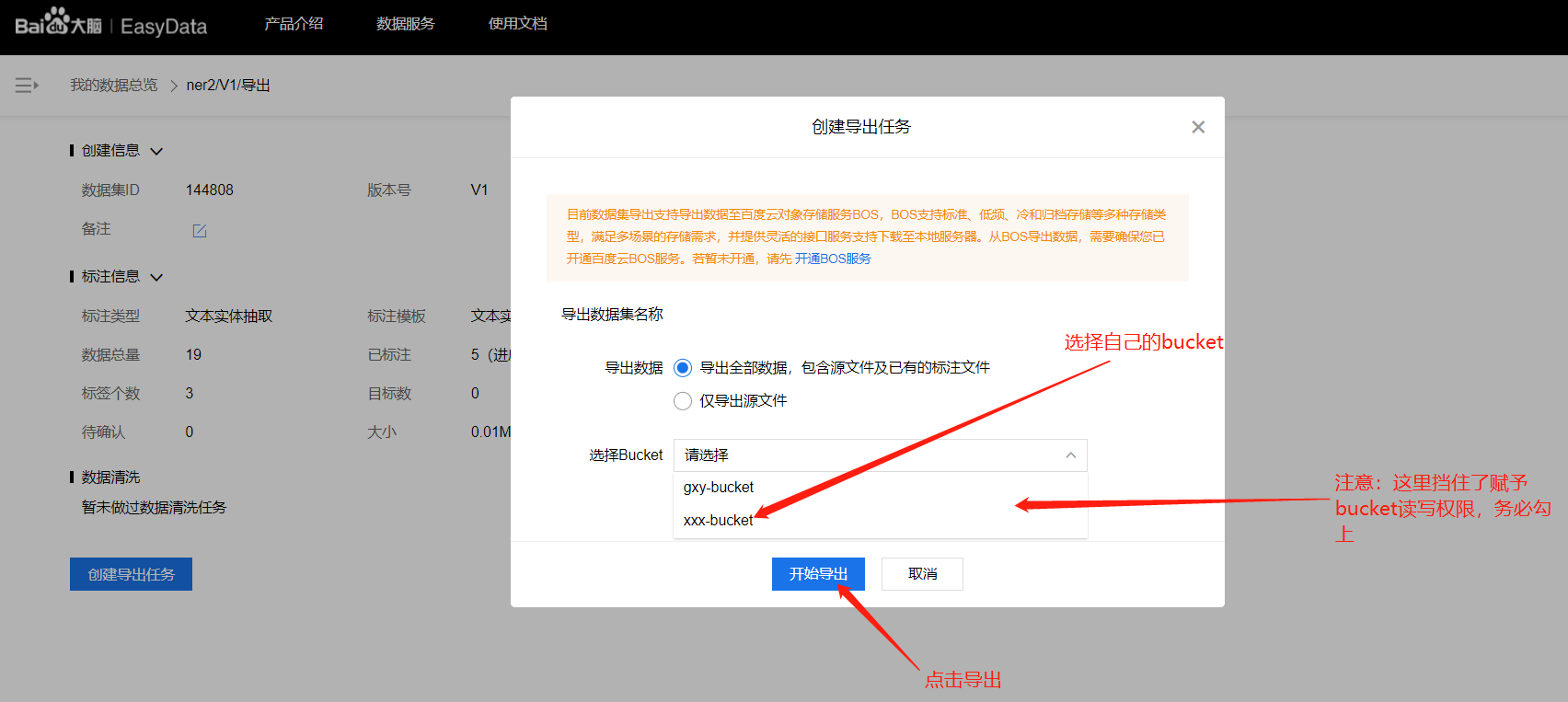
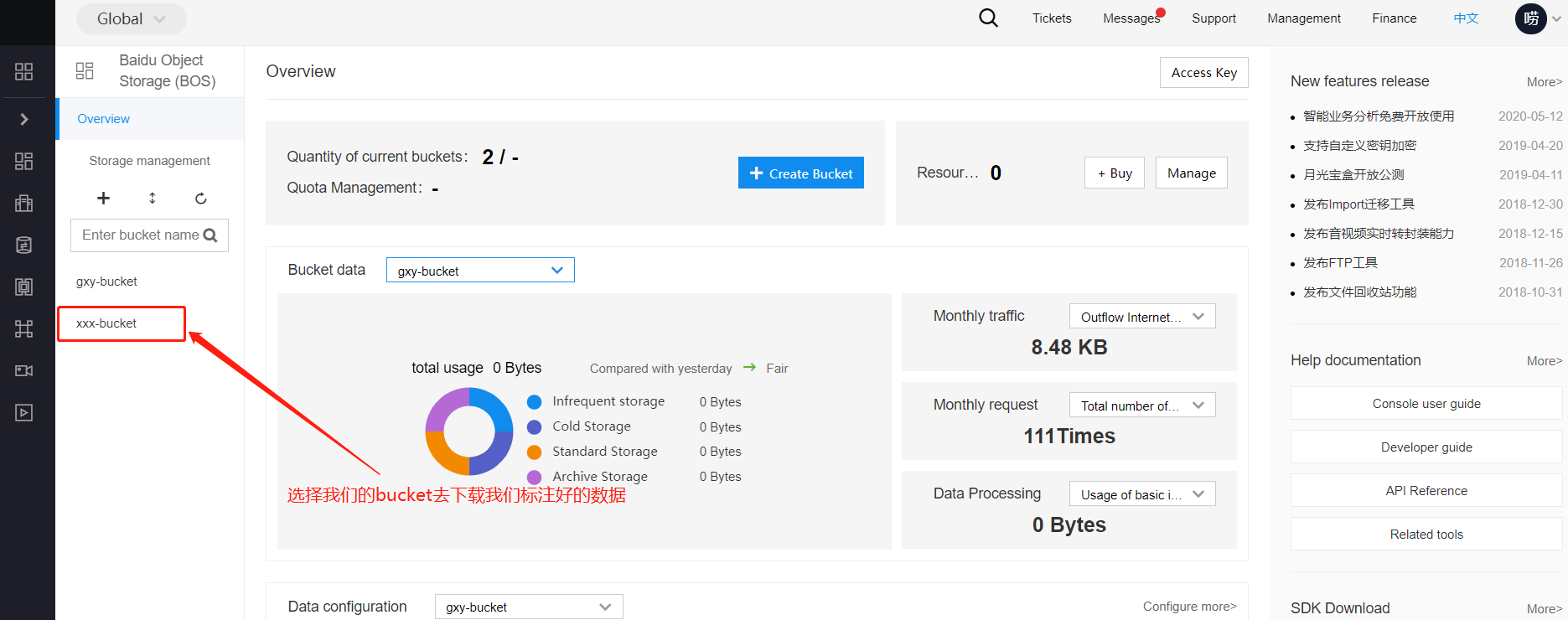
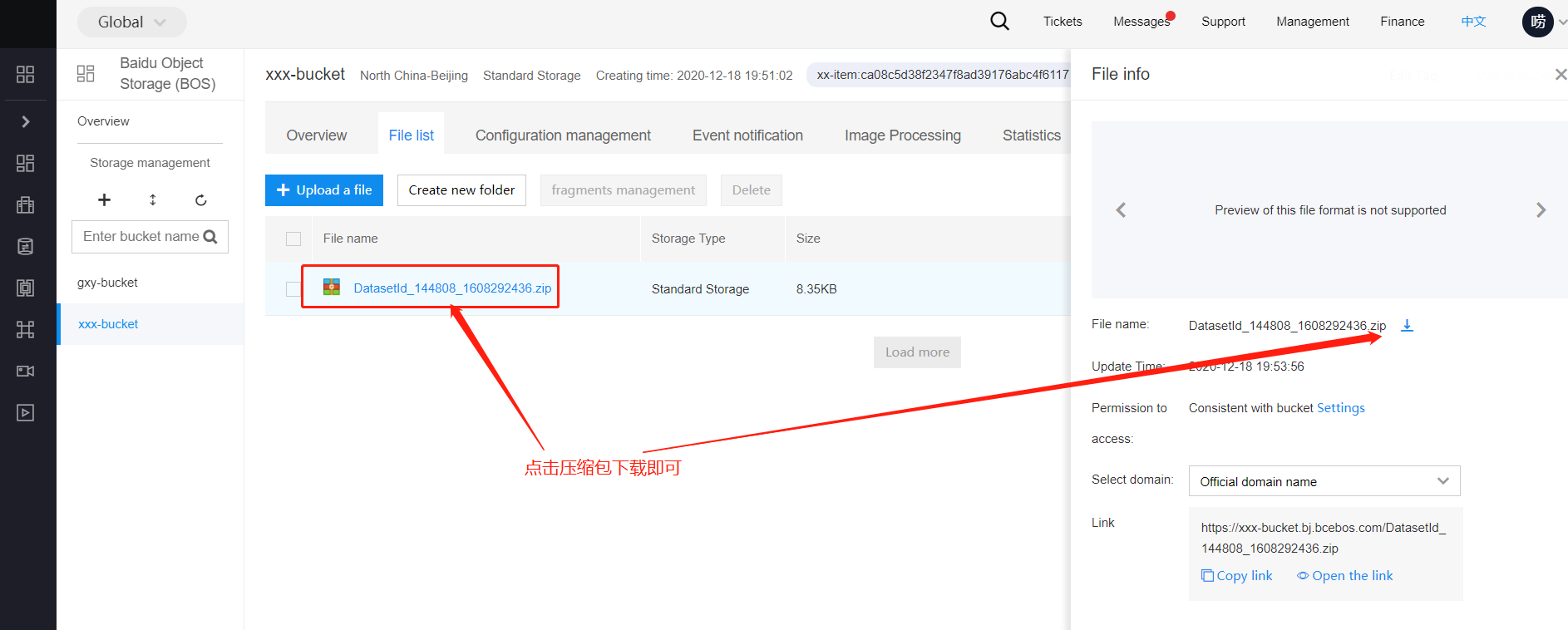
前往BOS查看

 浙公网安备 33010602011771号
浙公网安备 33010602011771号