


正文前先来一波福利推荐:
福利一:
百万年薪架构师视频,该视频可以学到很多东西,是本人花钱买的VIP课程,学习消化了一年,为了支持一下女朋友公众号也方便大家学习,共享给大家。
福利二:
毕业答辩以及工作上各种答辩,平时积累了不少精品PPT,现在共享给大家,大大小小加起来有几千套,总有适合你的一款,很多是网上是下载不到。
获取方式:
微信关注 精品3分钟 ,id为 jingpin3mins,关注后回复 百万年薪架构师 ,精品收藏PPT 获取云盘链接,谢谢大家支持!

-----------------------正文开始---------------------------
一、背景介绍:
例如原来顺序是: 10 20 30 40 插入顺序如下 10 20 10 30 20 10 40 30 20 10
二、存在的问题:
采用队头插入的方式,导致了HashMap在“多线程环境下”的死循环问题
问题的症状
从前我们的Java代码因为一些原因使用了HashMap这个东西,但是当时的程序是单线程的,一切都没有问题。后来,我们的程序性能有问题,所以需要变成多线程的,于是,变成多线程后到了线上,发现程序经常占了100%的CPU,查看堆栈,你会发现程序都Hang在了HashMap.get()这个方法上了,重启程序后问题消失。但是过段时间又会来。而且,这个问题在测试环境里可能很难重现。
我们简单的看一下我们自己的代码,我们就知道HashMap被多个线程操作。而Java的文档说HashMap是非线程安全的,应该用ConcurrentHashMap。
但是在这里我们可以来研究一下原因。
Hash表数据结构
HashMap通常会用一个指针数组(假设为table[])来做分散所有的key,当一个key被加入时,会通过Hash算法通过key算出这个数组的下标i,然后就把这个<key, value>插到table[i]中,如果有两个不同的key被算在了同一个i,那么就叫冲突,又叫碰撞,这样会在table[i]上形成一个链表。
我们知道,如果table[]的尺寸很小,比如只有2个,如果要放进10个keys的话,那么碰撞非常频繁,于是一个O(1)的查找算法,就变成了链表遍历,性能变成了O(n),这是Hash表的缺陷。
所以,Hash表的尺寸和容量非常的重要。一般来说,Hash表这个容器当有数据要插入时,都会检查容量有没有超过设定的thredhold,如果超过,需要增大Hash表的尺寸,但是这样一来,整个Hash表里的无素都需要被重算一遍。这叫rehash,这个成本相当的大。
相信大家对这个基础知识已经很熟悉了。
HashMap的rehash源代码
void transfer(Entry[] newTable, boolean rehash) { int newCapacity = newTable.length; //for循环中的代码,逐个遍历链表,重新计算索引位置,将老数组数据复制到新数组中去(数组不存储实际数据,所以仅仅是拷贝引用而已)和 arraylist 或者 linkedlist 中的clone方法是一样的 都是浅拷贝关系 foreach (Entry<K,V> e : table) { while(null != e) { Entry<K,V> next = e.next; if (rehash) { e.hash = null == e.key ? 0 : hash(e.key); } int i = indexFor(e.hash, newCapacity); //将当前entry的next链指向新的索引位置,newTable[i]有可能为空,有可能也是个entry链,如果是entry链,直接在链表头部插入。
//第一次时 newTable[i] = null
e.next = newTable[i]; newTable[i] = e; e = next; } } }
好了,这个代码算是比较正常的。而且没有什么问题。
正常的ReHash的过程
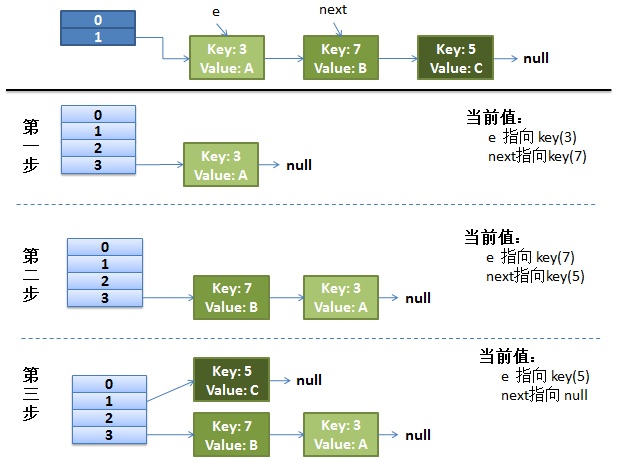
画了个图做了个演示。
- 我假设了我们的hash算法就是简单的用key mod 一下表的大小(也就是数组的长度)。
- 最上面的是old hash 表,其中的Hash表的size=2, 所以key = 3, 7, 5,在mod 2以后都冲突在table[1]这里了。
- 接下来的三个步骤是Hash表 resize成4,然后所有的<key,value> 重新rehash的过程
并发下的Rehash
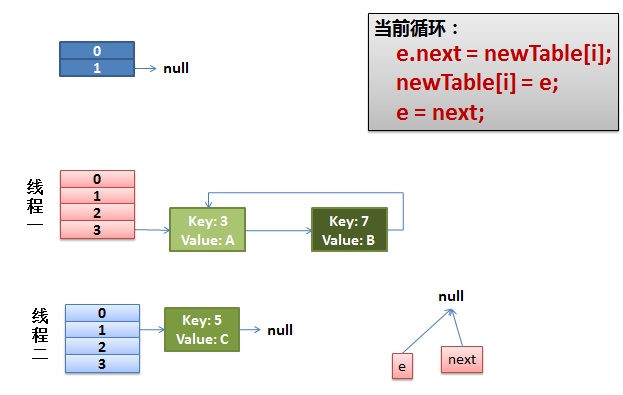
1)假设我们有两个线程。我用红色和浅蓝色标注了一下。
我们再回头看一下我们的 transfer代码中的这个细节:
int i = indexFor(e.hash, newCapacity); //假设线程一执行到这 失去了运行权限 //将当前entry的next链指向新的索引位置,newTable[i]有可能为空,有可能也是个entry链,如果是entry链,直接在链表头部插入。 //第一次时 newTable[i] = null e.next = newTable[i]; newTable[i] = e; e = next;
而我们的线程二执行完成了。于是我们有下面的这个样子。
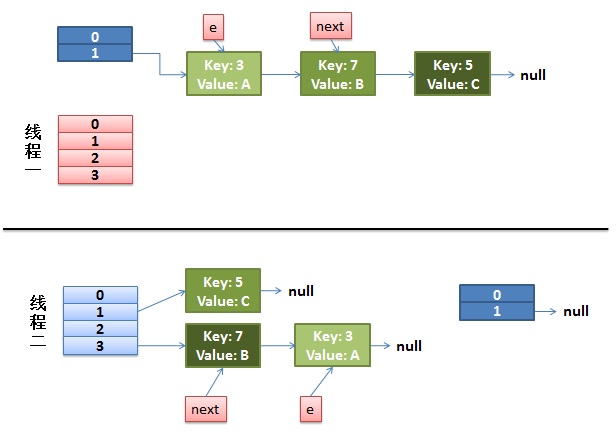
注意,因为Thread1的 e 指向了key(3),而next指向了key(7),其在线程二rehash后,指向了线程二重组后的链表。我们可以看到链表的顺序被反转后。
2)线程一被调度回来执行。
- 先是执行 newTalbe[i] = e;
- 然后是e = next,导致了e指向了key(7),
- 而下一次循环的next = e.next导致了next指向了key(3)
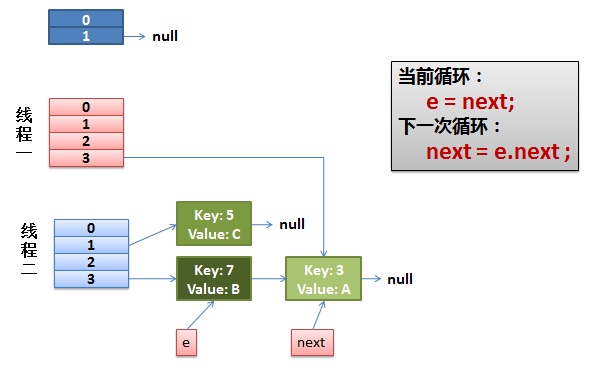
3)一切安好。
线程一接着工作。把key(7)摘下来,放到newTable[i]的第一个,然后把e和next往下移。
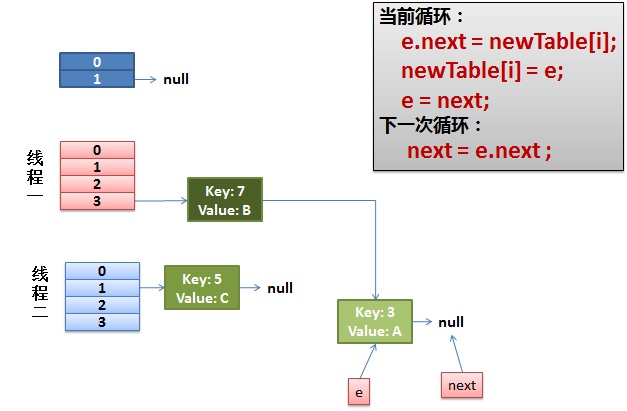
4)环形链接出现。
e.next = newTable[i] 导致 key(3).next 指向了 key(7)
注意:此时的key(7).next 已经指向了key(3), 环形链表就这样出现了。
于是,当我们的线程一调用到,HashTable.get(11)时,悲剧就出现了——Infinite Loop。
三、问题解决:
if (oldTab != null) { for (int j = 0; j < oldCap; ++j) { Node<K,V> e; if ((e = oldTab[j]) != null) { oldTab[j] = null; if (e.next == null) newTab[e.hash & (newCap - 1)] = e; else if (e instanceof TreeNode) ((TreeNode<K,V>)e).split(this, newTab, j, oldCap); else { // preserve order Node<K,V> loHead = null, loTail = null; // JDK1.8改进了rehash算法,扩容时,容量翻倍,新扩容部分,标识为hi,原来old的部分标识为lo Node<K,V> hiHead = null, hiTail = null; // 声明了队尾和队头指针。 Node<K,V> next; do { next = e.next; if ((e.hash & oldCap) == 0) { if (loTail == null) loHead = e; else loTail.next = e; loTail = e; } else { if (hiTail == null) hiHead = e; else hiTail.next = e; hiTail = e; } } while ((e = next) != null); if (loTail != null) { loTail.next = null; newTab[j] = loHead; } if (hiTail != null) { hiTail.next = null; newTab[j + oldCap] = hiHead; } } } } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号