

[数据结构] - 串
简介
字符串(String)是由字符组成有限序列,是常用的一种非数值数据,串的逻辑结构是线性表,串是一种特殊的线性表,限制其元素类型是字符,串的操作特点与线性表不同,主要对子串进行操作,通常采用顺序存储结构存储。
串的基本概念
串定义:一个串是由n(n>=0) 个字符组成的有限序列 记做s="s0 s1 s2" ,其中s是串名,一对双引号括起来的字符序列 s0 s1 s2 是串值,s1(i=0,1,n-1) 为特定字符集中的一个字符,一个串中包含的字符数称为串的长度,例如,字符串 “data” 长度是4,双引号不计入长度,长度为0的串称为空串, 记做“”,由多个空格字符构成的字符串 “” 称为 空格串。
一个字符在串中的位置称为该字符在串中的序号(Index),用一个整数表示,约定串中的第一个字符的序号为0,-1表示该字符不在指定串中。
子串:由串s中任意连续字符组成的一个子序列 sub称为s的子串(Substring),s称为sub的主串。例如 “at” 是“data” 的子串,特别的,空串是任意串的子串,任意串s都是他自身的子串,除了自身之外,s的其他子串称为s的真子串。
子串序号是指该子串首字符在主串中的序号。例如 “dat” 在 “data” 中序号是0
串比较规则与字符比较规则有关,字符比较规则犹豫所属字符集的编码决定,通常在字符集中同意字母的大小写形式有不同的编码。
两个串相等是指,串长度相等且哥哥对应位置是上的字符也相等。
两个串的大小由对应位置的收个不同字符的大小决定,字符比较次序是从头开始依次向后。当两个串长度不等而对应位置的字符都相同时候,较长的串定义为较大。
串的抽象数据类型
串与线性表是不同的抽象数据类型,两者操作不同,串的基本操作有:创建 求长度 读取设置字符,求子串,插入,删除,连接,判断等,查找,替换,其中求子串,插入,查找等操作1以子串为单位,一次操作处理多个字符。
串的存储结构
串有顺序存储和链式存储两种存储结构。
java语言字符串类有常量字符串类String,和变量字符串类 StringBuffer,这两种字符串类都采用顺序存储结构。能存储任意长度的字符串,实现串的基本操作,并且能够识别序号越界等错误,对数组占用的存储空间进行控制,具有健壮,安全性好等特点。
顺序存储结构:采用字符数组将串中的字符序列一次连续存存储在数组中的相邻但愿中,常量串和变量串的存储结构不同,数组容量length分半等于或者大于串长度n.

顺序存储的串具有随机存取特效,存取指定位置字符的时间复杂度为 O(1) ,缺点是插入和删除元素时需要移动元素,平均移动数据量是串长度的一半,当数组容量不够时,需要重新申请一个更大的数组,并复制原来数组中的所有元素,插入和删除操作的时间复杂度为O(n)
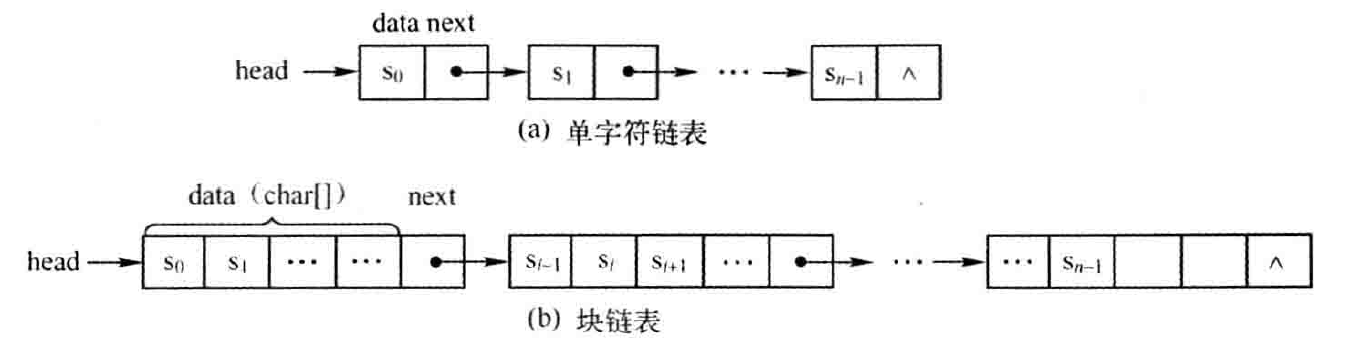
串的链式存储结构:有单字符串链表和块链表两种,但字符串链表是每个节点的数据域只包含一个字符的单链表,块链表是每个节点的数据域包含若干个字符的单链表。
链式存储的串,存取指定位置字符的时间复杂度为 O(n),单字符链表虽然插入/删除操作不需要移动元素,但是占用存储空间太多,块链表的插入和删除操作需要移动元素,效率低。
Java String 类
String是由双引号括起来的字符序列,其中可包含转义字符,如 “hello” "汉字\n" ""(空串) 等等,字符串只能在一行。
字符常量采用单引号括起来 ‘a’ '汗' 数据类型是char,占用2个字节存储字符的 Unicode编号,无论字符或者汉字,字符长度都是1.注意 只有空串 “” 没有空字符''
String字符串类,属于引用数据类型,提供构造串对象,求串长度取字符,求子串,连接串,比较串,比较大小等,如果charAt substring 方法序号越界将抛出 StringIndexOutOfBoundsException 字符串序号越界异常。
String是Java的一个特殊类,java不仅为之约定了常量形式,还重载赋值运算符 = 和 连接运算符 + += 使得String变量能够像基本数据类型变量一样,进行赋值和运算,
Java的字符串对象不是字符数组,不能以数组下表个数 s[i] 对指定 I 位置的字符进行操作
String类特点:
String类是最终类,不能被继承
String类以常量串方式存储和实现字符串的操作,采用字符数组存储字符序列,数组容量等于串长度,串尾部没有 \0 作为串结束符。
声明字符数组是最终变量,串中各个字符是只读的,当构造串对象时候,对字符数组进行一次赋值后,不能修改
构造串,求子串和连接串的操作,都是深度拷贝,重新申请字符串占用的字符数组,复制字符串数组,不会改变原来的串。
Java StringBuffer
String类存储常量字符串,一旦创建了实例,就不能修改它,这是线程安全的,但是每次连接等运算结果都将创建新的实例,频繁进行连接等操作将增加使用空间并降低运算效率,因此,java还声明StringBuffer类,采用缓冲区存储可变的字符串,避免在运算时频繁申请内存。
提供构造串对象,求串长度,取字符,求子串,等操作 提供修改字符,插入串,删除子串,若序号越界,将抛出字符串序号越界异常。
StringBuffer是最终类,不能被继承
StringBuffer 类以变量串方式存储和实现字符串操作,数组容量大于串长度 串尾没有\0 作为串结束符,当数组容量不能满足要求时,将自动扩容。
StringBuffer类的插入,删除等方法是线程互斥的。通过加互斥锁,控制多个线程修改同一个共享字符串变量的次序是串行的不能并行交替的进行修改,否则将产生与时间有关的错误,不能保证结果的正确性。
模式匹配算法:
在进行文本编辑时候,我们经常查找和替换,在文档的指定范围内查找一个单词的位置,用另一个单词替换,替换操作的前提是查找操作,如果查找到指定单词,则确定了操作位置,可以将指定单词用另一个单词替换掉,否则不能进行替换操作,每进行一次替换操作,都需要执行一次查找操作,那么如何快速查找指定单词在文档中的位置呢,就是串的模式批评算法需要姐姐的问题,
设有2个串,目标串target 和模式串 pattern ,在目标串target中查找与模式串pattern相等的一个子串并确定该子串的操作称为 串的模式批评,两个子串相等指的是:长度相等且对应各个字符相同,匹配结果有两种 如果target存在pattern相等的子串,则批评成功 获得该子串在target中的位置,否则匹配失败给出失败信息。
模式匹配应用:
要对目标串target 与模式串pattern 匹配的子串进行删除或者替换操作,必须先执行串的模式匹配算法,在target串中查找与pattern匹配的子串序号,确定删除或者替换操作的起始位置,如果匹配失败,则不进行替换或者删除操作,因此,串的模式匹配算法是替换和删除子串的基础。
Brute - force 算法描述
已知目标串,target = "t0,t1,t2,tn-1" , 模式串 pattern = "p0 p1 p2 pn-1" , 0 < m <= n Brute-Force 算法将目标串中的每个长度为 m的子串 “t0 tm-1” "t1 tm-1" ... "tn-m tn-1" 依次与模式串进行匹配操作,设 target="aababcd" pattern = "abcd" 匹配四次, 匹配层高返回子串序号3 ,字符比较10次。
KMP算法简介:
KMP是一种无回溯的模式匹配算法,他改进了Brute-Force 算法,目标串不回溯。
已知目标串 “t0 t1 t2 tn-1” 与模式串 pattern = "p0 p1 p2 pn-1" 0<m<=n KMP算法每次匹配依次比较p1 与pj, (0<=i<n 0<=j<m).
若t=p 则继续比较 t+1 与 p+1,直到ti+m+1...ti = p0...pm-1 则匹配成功,返回模式串在目标串中匹配子串序号 i-m+1.
若ti!=pj 表示ti-j ...ti 与 p0...pj 匹配失败,目标串不回溯,下次匹配ti 将与模式串pk(0<=k<j)比较,对于每个pj, k取值不同,因此,如何求得这个k,就成了KMP算法核心问题。
目标不回溯:
Brute-Force算法的目标串存在回朔,两个串逐级比较,如果t1!=p1 (0<=i<n || 0<=j<m)则下次匹配目标串从ti 退回到 ti-j+1,开始于模式串p0 比较,实际上 目标串回朔是不必要的,ti-j+1 与p0 的比较结果可由前一次匹配结果得到.
设t0 t1 t2 与 p0 p1 p2 匹配一次,有t0 = p0 t1 = p1 t2 != p2
1.若p1 != p0 那么 t1 也不等于 p0 下次匹配从t2 与 p0 开始匹配。
2.若p1 = p0 那么 t1 = p0 下次匹配 从 t2 与 p1 开始。
总之,当t2 != p2 时,无论p1 p0 是否相等,目标下次匹配都从t2开始比较,不回溯,而模式串要根据p1 和p0 是否相同,确定从p0或者p1 开始比较。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号