OpenStack HA
OpenStack HA
参考:https://www.cnblogs.com/sammyliu/p/4741967.html
OpenStack 部署环境中,各节点可以分为几类:
- Cloud Controller Node (云控制节点):安装各种 API 服务和内部工作组件(worker process)。同时,往往将共享的 DB 和 MQ 安装在该节点上。
- Neutron Controller Node (网络控制节点):安装 Neutron L3 Agent,L2 Agent,LBaas,VPNaas,FWaas,Metadata Agent 等 Neutron 组件。
- Storage Controller Node (存储控制节点):安装 Cinder volume 以及 Swift 组件。
- Compute node (计算节点):安装 Nova-compute 和 Neutron L2 Agent,在该节点上创建虚机。
要实现 OpenStack HA,一个最基本的要求是这些节点都是冗余的。根据每个节点上部署的软件特点和要求,每个节点可以采用不同的 HA 模式。但是,选择 HA 模式有个基本的原则:
- 能 A/A 尽量 A/A,不能的话则 A/P (RedHat 认为 A/P HA 是 No HA)
- 有原生(内在实现的)HA方案尽量选用原生方案,没有的话则使用额外的HA 软件比如 Pacemaker 等
- 需要考虑负载均衡
- 方案尽可能简单,不要太复杂
OpenStack 官方认为,在满足其 HA 要求的情况下,可以实现 IaaS 的 99.99% HA,但是,这不包括单个客户机的 HA。
云控制节点的 A/A HA 方案
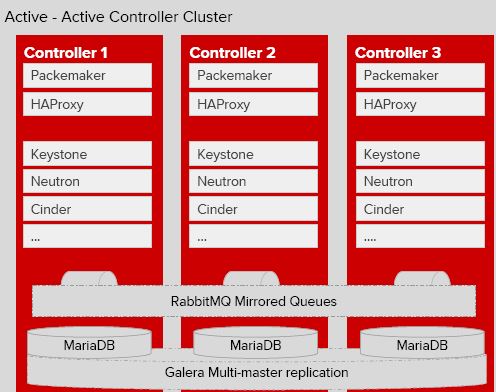
该方案至少需要三台服务器。以 RDO 提供的案例为例,它由三台机器搭建成一个 Pacemaker A/A集群,在该集群的每个节点上运行:
- API 服务:包括 *-api, neutron-server,glance-registry, nova-novncproxy,keystone,httpd 等。由 HAProxy 提供负载均衡,将请求按照一定的算法转到某个节点上的 API 服务。由 Pacemaker 提供 VIP。
- 内部组件:包括 *-scheduler,nova-conductor,nova-cert 等。它们都是无状态的,因此可以在多个节点上部署,它们会使用 HA 的 MQ 和 DB。
- RabbitMQ:跨三个节点部署 RabbitMQ 集群和镜像消息队列。可以使用 HAProxy 提供负载均衡,或者将 RabbitMQ host list 配置给 OpenStack 组件(使用 rabbit_hosts 和 rabbit_ha_queues 配置项)。
- MariaDB:跨三个阶段部署 Gelera MariaDB 多主复制集群。由 HAProxy 提供负载均衡。
- HAProxy:向 API,RabbitMQ 和 MariaDB 多活服务提供负载均衡,其自身由 Pacemaker 实现 A/P HA,提供 VIP,某一时刻只由一个HAProxy提供服务。在部署中,也可以部署单独的 HAProxy 集群。
- Memcached:它原生支持 A/A,只需要在 OpenStack 中配置它所有节点的名称即可,比如,memcached_servers = controller1:11211,controller2:11211。当 controller1:11211 失效时,OpenStack 组件会自动使用controller2:11211。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号