R方分数
R-squared 分数(R² Score),也称为决定系数(Coefficient of Determination)或简称R方,是回归分析中用来评估模型拟合优度的一个重要统计指标。
它衡量了因变量(Y)的变异中可以被自变量(X)解释的比例。简单来说,R-squared 分数告诉您回归模型对数据变化的解释程度有多好。
1. 核心概念与解释
- 取值范围:R-squared 的值通常介于 0 到 1 之间(或表示为 0% 到 100%)。在某些特殊情况下(例如模型拟合效果非常差,甚至比简单地使用平均值进行预测还差时),它可能为负值。
- 解释:
- R² 越接近 1 (100%):表示模型对数据点的拟合程度越高,模型能解释因变量变化的绝大部分原因。完美的拟合意味着 R² = 1。
- R² 越接近 0 (0%):表示模型的解释能力越弱,模型不能很好地预测因变量的变化。这意味着自变量对因变量几乎没有线性解释能力。
- 例如,如果 R² = 0.75,这意味着因变量中 75% 的变异可以通过模型的自变量来解释,而剩下的 25% 是由模型未包含的其他因素或随机误差造成的。
2. 如何计算
R-squared 分数的计算基于以下三个关键概念:
- 总平方和 (SST, Total Sum of Squares):因变量观测值与因变量均值之间的总变异。
- 回归平方和 (SSR, Sum of Squares for Regression):模型预测值与因变量均值之间的变异(由模型解释的部分)。
- 残差平方和 (SSE, Sum of Squared Errors):观测值与模型预测值之间的变异(模型未能解释的部分,即误差)。
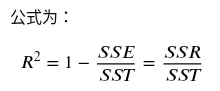

代码示例:
import numpy as np # Example data X = np.array([ [1, 50, 30], # Example of multiple independent variables [1, 60, 35], [1, 70, 40], [1, 80, 45], [1, 90, 50] ]) # Added a constant term (1s) for the intercept y = np.array([200, 240, 280, 320, 360]) # Dependent variable # Calculate the coefficients coefficients = np.linalg.inv(X.T @ X) @ X.T @ y # Predict your values y_pred = X @ coefficients # Calculate SS_residual and SS_total SS_residual = np.sum((y - y_pred) ** 2) SS_total = np.sum((y - np.mean(y)) ** 2) # Calculate R-squared R_squared = 1 - (SS_residual / SS_total) print("R-squared:", R_squared)
3. 局限性
虽然 R-squared 是一个有用的指标,但它并非万能:
- 不保证准确性:高 R-squared 并不一定意味着模型预测准确性高,它只衡量了模型解释历史数据的能力(拟合优度)。
- 增加变量的问题:在线性回归中,每当你向模型添加更多的自变量时,R-squared 的值通常都会增加(或至少保持不变),即使这些新变量并没有实际的预测价值。为了解决这个问题,通常会使用调整后 R-squared(Adjusted R-squared),它会对模型中自变量的数量进行惩罚。
- 依赖具体领域:在某些自然科学领域,R-squared 达到 0.9 可能是正常的;而在社会科学领域,由于涉及复杂的人类行为,R-squared 达到 0.2 就可能被认为是相当不错的成绩。
参考资料:
1. Understanding R-squared in Regression Analysis

 浙公网安备 33010602011771号
浙公网安备 33010602011771号