样本特征数据标准化
样本特征数据的标准化(Feature Scaling 或 Standardization)是数据预处理的关键步骤之一,尤其在线性回归、逻辑回归、神经网络、支持向量机等依赖距离度量的算法中至关重要。
标准化可以通过多种方法实现,最常用的是 Z-Score 标准化 和归一化(Min-Max Scaling)。
1. Z-Score 标准化 (Standardization)
Z-Score 标准化将数据转换为均值为 0、标准差为 1 的分布。它假设数据服从或近似服从正态分布。

特点及适用场景:
- 特点:经过标准化后,数据的范围不再固定(理论上可以从负无穷大到正无穷大,但绝大部分落在 [-3, 3] 之间)。它保留了数据的原始分布形状。
- 适用算法:非常适合依赖距离度量的算法,如 KNN、K-Means、以及所有基于梯度的优化算法(如线性回归、逻辑回归、神经网络)。
- 对异常值敏感:均值和标准差都受异常值影响较大,因此标准化也受影响。
2. 归一化 (Min-Max Scaling)
归一化将数据缩放到一个固定的特定范围内,通常是[0,1]或[−1,1]
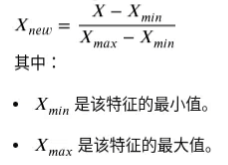
特点及适用场景:
- 特点:将所有数据压缩到固定区间,消除了量纲(单位)的影响。
- 适用算法:在神经网络中常用于将输入值缩放到激活函数的敏感区域(如 Sigmoid 函数的 [0-1] 范围)。也适用于需要明确范围的算法。
- 对异常值非常敏感:数据的最大值和最小值会严重影响缩放结果。如果存在一个极端异常值,大部分数据将被压缩在一个很小的范围内。
3. 何时使用标准化?
以下是需要进行特征标准化的主要原因:
- 消除量纲影响:不同特征可能具有不同的单位和数量级(例如,房屋面积通常是几百平方米,而房间数量是个位数)。标准化使得所有特征在同一尺度上,避免数量级大的特征主导模型。
- 加速模型收敛:在线性回归、逻辑回归和神经网络中使用梯度下降算法时,标准化后的数据能使损失函数的等高线更接近圆形,从而让优化器更快地找到最小值(收敛速度更快)。
- 算法要求:某些算法(如 SVM、KNN)假设特征在相似的尺度上,否则具有较大方差的特征将主导结果。
在 Python 中如何实现?
使用 Scikit-learn 库可以非常方便地实现标准化和归一化:
在虚拟环境中安装库
(.vpyenv)$ pip install scikit-learn
from sklearn.preprocessing import StandardScaler, MinMaxScaler import numpy as np data = np.array([[100], [200], [300], [400], [1000]]) # 1. Z-Score 标准化 scaler_z = StandardScaler() data_standardized = scaler_z.fit_transform(data) print("Standardized Data:\n", data_standardized) # 结果的均值接近 0,标准差接近 1 # 2. 归一化 (Min-Max Scaling) scaler_mm = MinMaxScaler() data_normalized = scaler_mm.fit_transform(data) print("Normalized Data (0-1):\n", data_normalized) # 结果范围在 [0, 1] 之间
4. 思考题
1). 如何预测数据的标准化?
预测数据的标准化(Standardization of Prediction Data),也称为推理数据的预处理,是指在模型已经训练完毕并准备投入使用(进行预测)时,如何处理新的输入数据。
这是一个至关重要的步骤,核心原则是:
在预测阶段,必须使用训练模型时所用的完全相同的标准化参数(均值、标准差、最大值、最小值)来处理新的预测数据。
2). 如何对标签值标准化?
标签值标准化(Target Variable Standardization 或 Scaling the Target)是指对模型的输出(即标签
y 或因变量)进行预处理的过程。标签值标准化的目的
与特征标准化(Feature Scaling)相似,对标签值进行标准化主要是为了改善模型的训练过程和性能。
- 加速收敛:尤其在使用梯度下降优化算法的神经网络和线性模型中,将标签值缩放到较小的范围(例如均值 0,方差 1)有助于损失函数更快地收敛。
- 统一尺度:当处理多个具有不同数量级输出的模型时,标准化有助于保持一致性。
通常使用与特征数据相同的标准化或归一化方法
关键步骤和注意事项
对标签值进行标准化涉及一个重要的逆向操作:
1)训练阶段:你需要使用训练集的 y 值来计算标准化参数(均值、标准差、最大/最小值)。然后,模型是基于标准化后的𝑦̂𝑛𝑒𝑤来学习和预测的。

2)预测阶段:模型输出的预测值𝑦̂𝑛𝑒𝑤也是标准化的值。
3)逆转换(Inverse Transform):为了得到实际的、可解释的结果,你必须使用训练阶段保存的参数将预测值逆转换回原始的量纲。
逆向操作是连接模型内部工作(使用标准化数据加速训练)与外部现实世界(需要实际、可解释的预测结果)的桥梁。
对标签值(目标变量
y)进行标准化后,逆向操作(Inverse Transform)是必须的。原因在于:1)使预测结果具有实际意义和可解释性;2)评估模型的性能需要原始尺度的比较。
参考资料:
1. 《智能之门》 高等教育出版社出版。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号