22从汇编的角度深入理解c++_win32编程基础:编码
标准ASCII码:开头为0,长度为1个字节表示,0XXXXXXX
扩展ASCII码:开头为1,长度1个字节:1XXXXXXX
中文GB3212/GB1232-80:2个扩展ASCII字节合并在一起表示,并且每个字节开头都是1:1XXXXXXX 1YYYYYYY。
存在的问题:
1、乱码,因为GB3212/GB1232-80这样的设计,日本、韩文也可能这样设计等,这样就会有乱码。
2、判断符号个数的时候,容易出问题。让计算机判断含有中文的字符的时候,由于1个中文是2个字节,这2个字节可能会被当成2个字符,这样字符个数就会出错。
unicode 解决部分问题:
2个字符,把字符按照范围分配,每个范围供不同的国家使用,只能保存常用的字符。
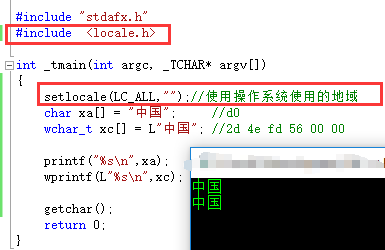
内核中所有的字符都是使用unicode编码。
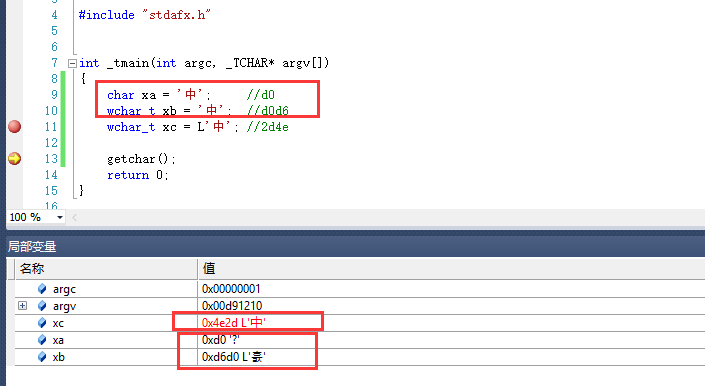
问题:
为什么同1个字,显示的编码不一样呢?
答:因为查的不同的表,前2句查的都是ASCII码表,
第3句加上L,表示查的是UNICODE码表。
就是因为查的表不一样,因此显示的编码值不一样。
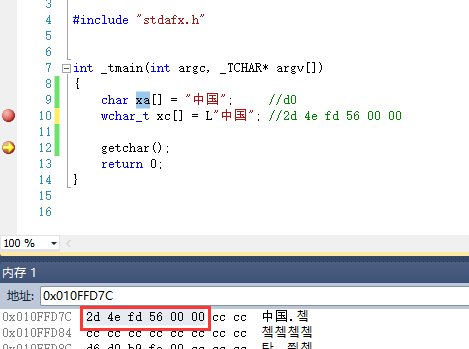
当使用宽字节的时候,结尾的0也是2个字节。
单字节还是ASCII码表
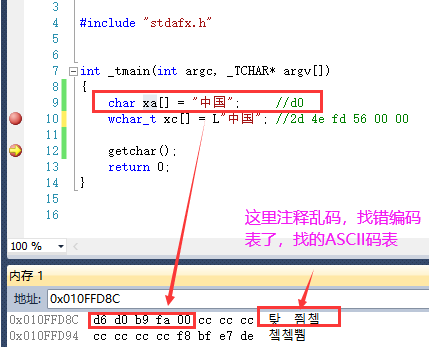
为什么要搞懂这个ASCII和宽字节的UNICODE呢?
因为win32编程中会有很多的同名的,但是结尾是W和A函数,就是分别处理这2种编码的函数。
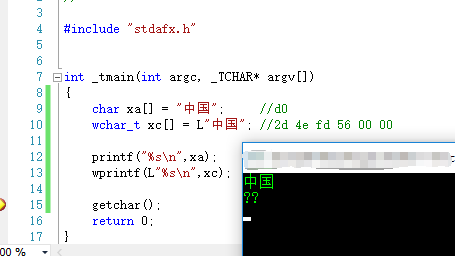
为什么第二个打印不显示或者显示乱码
你得告诉编译器,使用unicode表的分配给我们国家使用那一段,这样才能正确打印。
加2行代码,1个头文件,1行设置地域。
win32程序的使用的API,主要是Windows/system32/ 文件夹里面的dll提供的函数。
Kernel32.dll 核心的内存、进程和线程管理
User32.dll 创建窗口和发送消息
GDI32.dll 图形设备接口
………………
这些dll其实都不提供实际的功能,只是一个转发,真正的功能其实是内核提供的,通过上边的这些dll转发进入内核。
当不知道一种新的类型的时候,F12跟进去就行了。

不管是CHAR还是WCHAR都是之前定义的类型,只是使用typedef重新进行命名了,那么为什么要这样做:
因为你会发现如下的现象:
TCHAR tc; //当项目设置为unicode编码的时候,这个类型会变成wchar_t;当项目编码设置为ASCII码的时候,F12跟进去会发现,这个类型是char。
当这样定义TCHAR 的时候,会自动根据项目设置的编码,自动把TCHAR 变为char或者wchar_t,相当于自适应。
因此我们以后win32编码最好使用T类型的,TCHAR,而不是char,也不是wchar_t。因为这样兼容性好,自适应。
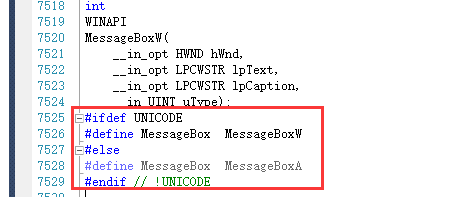
最简单的MessageBox其实就是一个宏,根据你定义的设置的编码,自行选择使用哪个版本的MessageBoxA/W
int APIENTRY WinMain(HINSTANCE hInstance,
HINSTANCE hPrevInstance,
LPSTR lpCmdLine,
int nCmdShow)
{
int xx = (int)hInstance;
getchar();
return 0;
}
WinMain函数的参数:
APIENTRY 按F12,其实就是__stdcall,调用约定,平栈(内平还是外平),参数入栈顺序。
hInstance是句柄,其实就是模块的首地址。
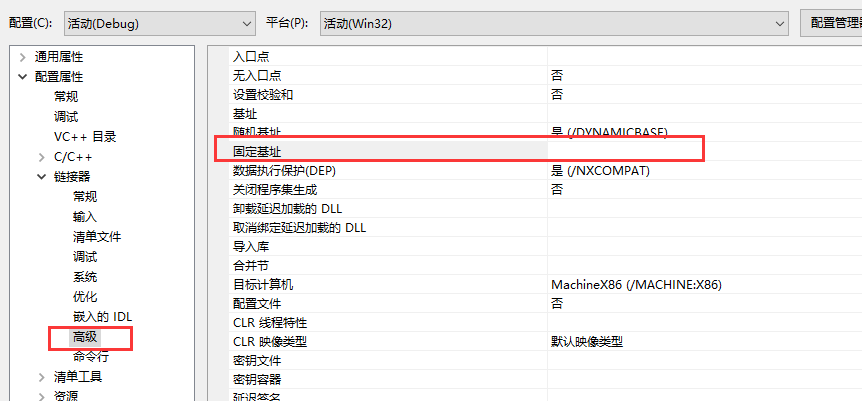
在项目------>属性------->链接器----->高级--------->固定基址,可以改变这个基址的值。
HINSTANCE hPrevInstance,如果hPrevInstancehPrevInstance非空,则它表明当前实例是从一个已经运行的实例中拷贝过来的。历史遗留问题win16的时候这个参数可能为非空,win32程序都为空。
在win16的时候,存在一块共享内存,可以使用GetInstanceData从之前已经运行起来的一个程序实例的内存直接复制一份到现在运行的程序实例中。而在win32中,由于每个程序的空间都是4GB,这个4GB是隔离的,不能直接从已运行起来的实例内存中复制到当前运行的实例内存中,这样做很不安全。这个参数就没用了。
lpCmdLine是命令行参数,可以用GetCommandLine()来获取完整的命令行,可以用GetCommandLine()来获取完整的命令行参数
nCmdShow窗体显示的方式,最大化、最小化、隐藏显示。
win32程序中输出打印问题:
控制台程序我们都用printf打印,但是win32没有控制台了,我们要换种调试方式,项目------->右键------>添加类,添加1个*.h和*.cpp文件
//*.h代码 void __cdecl OutputDebugStringF(const char* format , ...); #ifdef _DEBUG #define DbgPrintf OutputDebugStringF #else #define DbgPrintf #endif
和
//*.output代码
#include "StdAfx.h"
void __cdecl OutputDebugStringF(const char* format,...)
{
va_list vlArgs;
char* strBuffer = (char*)GlobalAlloc(GPTR,4096);
va_start(vlArgs,format);
_vsnprintf(strBuffer,4096-1,format,vlArgs); //要引入#include <stdio.h>,不然这句话会报错
va_end(vlArgs);
strcat(strBuffer,"\n");
OutputDebugStringA(strBuffer);
GlobalFree(strBuffer);
return;
}
注意:在头文件中要引入:
#include <stdio.h>不然_vsnprintf会报错。
这样在主程序中,引入头文件就可以输出调试信息了:
win32程序中捕捉错误问题:
#include "stdafx.h"
#include "19C++Win32.h"
#include "Output.h"
int APIENTRY WinMain(HINSTANCE hInstance,
HINSTANCE hPrevInstance,
LPSTR lpCmdLine,
int nCmdShow)
{
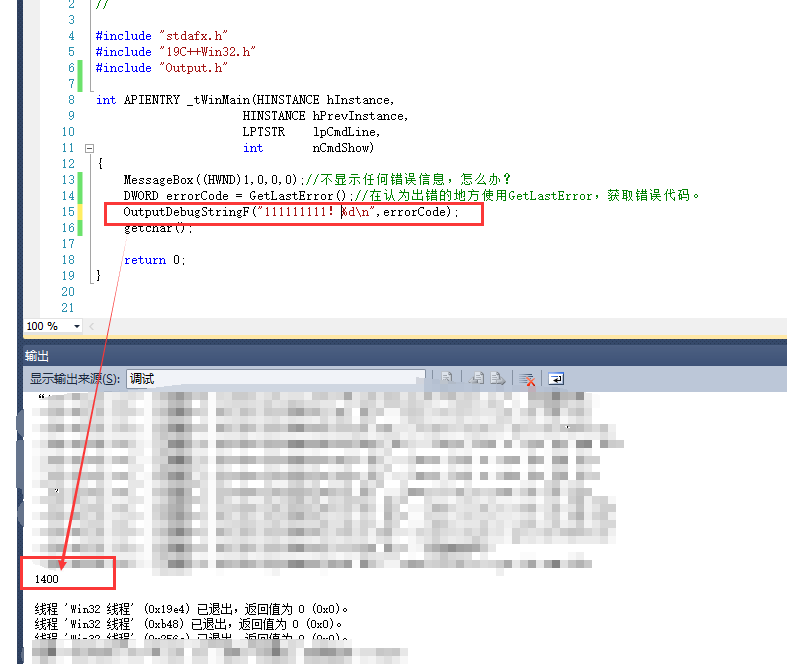
MessageBox((HWND)1,0,0,0);//不显示任何错误信息,怎么办?
getchar();
return 0;
}
在认识出错的地方,使用GetLastError()获取出错码
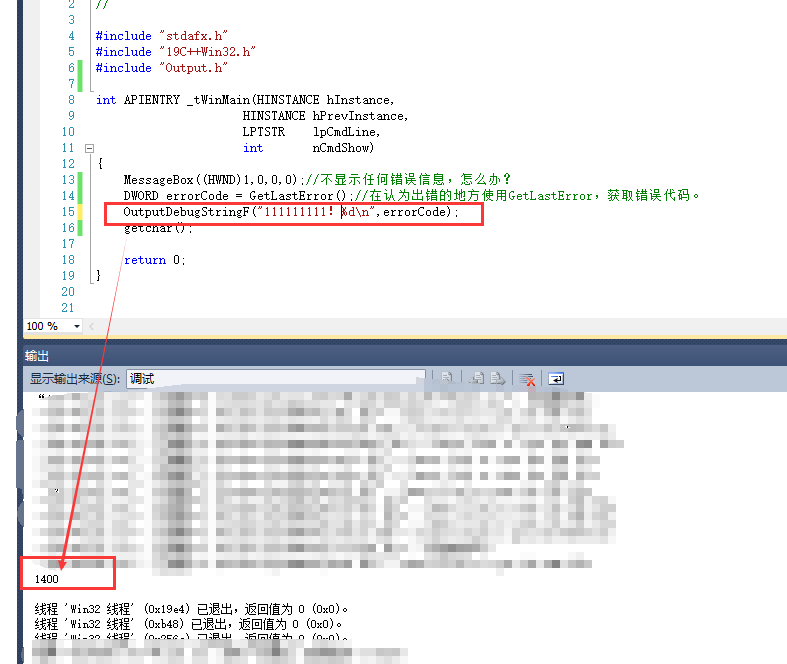
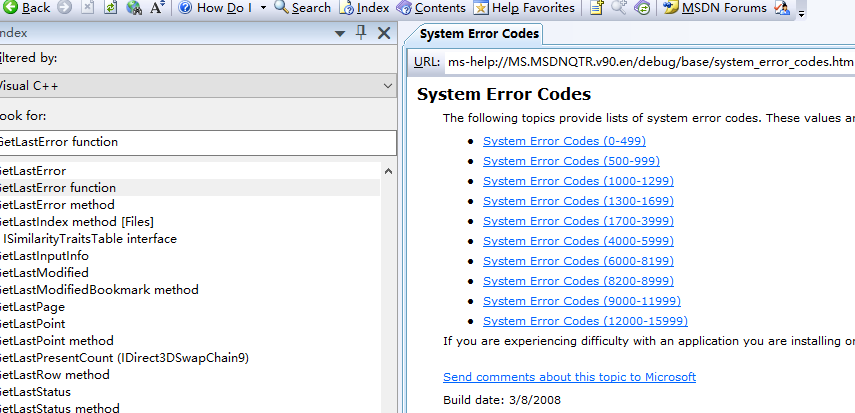
然后1,查找MSDN
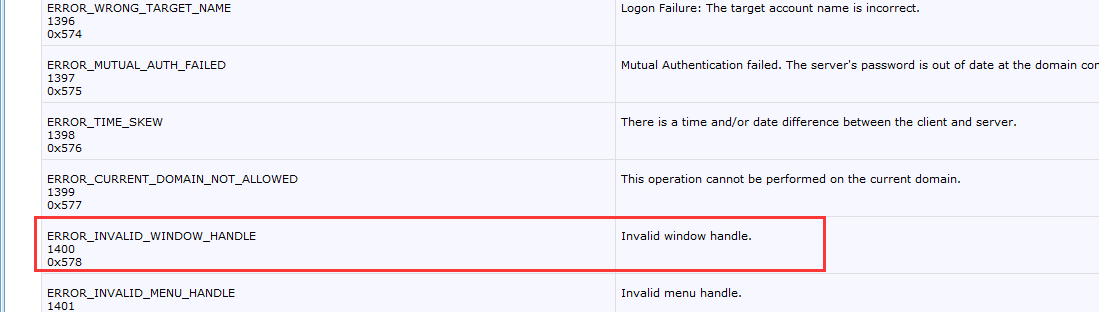
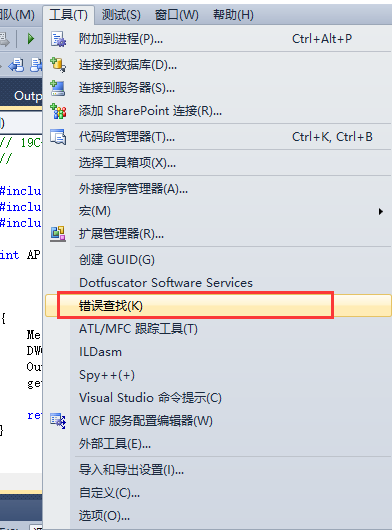
2,使用vs自带的工具,查找错误编码:
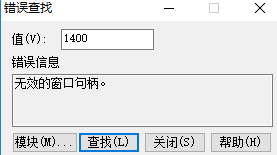
但是经过试验,发现新的问题,
DbgPrintf OutputDebugStringF只能输出ASCII编码,对于Unicode输出有问题,因此为了兼容就改写了一般既可以输出ASCII的,又可以输出Unicode。
头文件如下:
//output.h void __cdecl OutputDebugStringF(const char* format , ...); void __cdecl OutputDebugStringQ(const wchar_t* format, ...); #ifdef _DEBUG #define DbgPrintf OutputDebugStringF #define DbgWPrintf OutputDebugStringQ #else #define DbgPrintf #define DbgWPrintf #endif
源代码如下:
//output.cpp
#include "StdAfx.h"
//ASCII码版
void __cdecl OutputDebugStringF(const char* format,...)
{
va_list vlArgs;
char* strBuffer = (char*)GlobalAlloc(GPTR,4096);
//TCHAR strBuffer = (TCHAR)GlobalAlloc(GPTR,4096);
va_start(vlArgs,format);
_vsnprintf(strBuffer,4096-1,format,vlArgs);
va_end(vlArgs);
strcat(strBuffer,"\n");
OutputDebugStringA(strBuffer);
//OutputDebugStringW(strBuffer);
GlobalFree(strBuffer);
return;
}
//Unicode码版
void __cdecl OutputDebugStringQ(const wchar_t* format, ...)
{
va_list vlArgs;
wchar_t* strBuffer = (wchar_t*)GlobalAlloc(GMEM_ZEROINIT, 4096 * sizeof(wchar_t));
va_start(vlArgs, format);
_vsnwprintf(strBuffer, 4096 - 1, format, vlArgs);
va_end(vlArgs);
wcscat(strBuffer, L"\n");
OutputDebugStringW(strBuffer);
GlobalFree(strBuffer);
return;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号