
数据库
Mysql 学习记录
01 基础:查询语句的实现
大体来说,MySQL可以分为Server层和存储引擎层两部分。
Server层包括连接器、查询缓存、分析器、优化器、执行器等,涵盖MySQL的大多数核心服务功能,以及所有的内置函数(如日期、时间、数学和加密函数等),所有跨存储引擎的功能都在这一层实现,比如存储过程、触发器、视图等。
而存储引擎层负责数据的存储和提取。其架构模式是插件式的,支持InnoDB、MyISAM、Memory等多个存储引擎。现在最常用的存储引擎是InnoDB,它从MySQL 5.5.5版本开始成为了默认存储引擎。
也就是说,你执行create table建表的时候,如果不指定引擎类型,默认使用的就是InnoDB。不过,你也可以通过指定存储引擎的类型来选择别的引擎,比如在create table语句中使用engine=memory, 来指定使用内存引擎创建表。不同存储引擎的表数据存取方式不同,支持的功能也不同,在后面的文章中,我们会讨论到引擎的选择。
从图中不难看出,不同的存储引擎共用一个Server层,也就是从连接器到执行器的部分。你可以先对每个组件的名字有个印象,接下来我会结合开头提到的那条SQL语句,带你走一遍整个执行流程,依次看下每个组件的作用。
02 mysql索引基础
索引是怎么工作的
mysql会给主键建一个索引。如果给另一个列A建一个普通索引,那么mysql就会维护一个数据结构,每个元素包括A和主键。根据A的值进行排序。
当执行以下查找语句时
select * from table where A = a;
mysql会优先根据索引列查找。找到了主键以后,再根据主键索引查找完整记录。
索引的数据结构
哈希集合
根据索引值计算hash,然后快速定位。只能计算等值,不能进行区间查找。
有序数组
查找复杂度平均是\(O(logn)\)(二分查找),比较优秀。但是对于插入、删除、更新的操作复杂度比较差。适合不怎么修改的表。
B树、B+树
最常见,因为数据库一般很大,需要保存大量数据块在硬盘上。读写硬盘时间很长,为了减少读写时间,所以选择B+树,多叉、矮树。
InnoDb的索引
覆盖索引、最左匹配、索引下推
覆盖索引
如果对数据表的k字段建立索引,以id为主键然后有一条这样的查询语句:
select id from user where k between 3 and 5;
数据库扫描索引列时,因为id已经带到了,所以不需要再扫描主键索引。这就是覆盖索引。
最左匹配
最左匹配的两种情形:
- 联合索引
- 字符串索引匹配
所以如果对a,b,c,d字段建立联合索引,然后有这样的查询语句:
select * from user where a= 1 and b =2 and c >3 and d=4;
因为最左匹配,所以到c>3时无法匹配,从而d=4的条件没用到。
普通索引和唯一索引该怎么选?
假如业务场景是某个字段是唯一的,不存在重复。那么究竟应该加普通索引还是唯一索引?
- 这两个索引在查询上的效率差距微乎其微,都是在内存中执行的操作。但是对于数据的更新操作差距很大。
- 普通索引在更新时有一个缓冲区change buffer,用于缓存更新操作,在查询目标的场景下触发merge,进行持久化操作。而唯一索引因为必须检索保证唯一性,所以不存在这个change buffer,每一次更新操作都需要与硬盘交互。这样会造成大量的IO操作。
- 对于写多读少的业务场景,使用change buffer能够有效减少磁盘IO。而对于经常读的业务场景,可能刚写完就触发merge操作,这时候change buffer不起到什么作用反而会增加维护成本。
- 建议使用普通索引。
给字符串加索引
字符串也可以加索引,可以进行全部索引,也可以进行前缀索引(只给某个固定长度加索引)
例如,业务场景是需要进行email登录。所以需要sql查询语句:
select * from user where email = #{email};
如果没有加索引,sql会进行全表扫描进行字符串匹配。如果加了索引,那么会先扫描索引获得主键,然后根据主键索引匹配email字符串。
有以下两种加索引的方法:
- 全字段索引
alter table user add index index1(email);
全字段索引比较消耗空间,但是检索效率最高。执行流程为:首先搜索字符串索引定位主键,然后搜索主键索引,判断对应的字段是否匹配。然后判断字符串索引的下一个是否满足条件,以此循环。
- 前缀索引
alter table user add index index1(email(6));
新建的索引B+树中只保存前6个字节。空间利用率高,但可能会造成性能问题。
前缀索引该定多长?
需要找到一个临界值,使得每次检索索引时,能够既快又省空间。
于是可以根据区分度(distinct关键字)进行判断
select count(distinct left(email,7))/count(*) from user;
可以修改前缀的长度(上面例子为7)进行尝试。
不适用前缀索引的情况
当业务场景为存储身份证字符串时,一定区域的字符串前缀都是一样的,可能区分度会低。因此可以采用以下的方法:
- 先倒序,再进行前缀索引
- 新建哈希列,再对哈希列前缀索引
字符串查找的实践
-
数据库内容:
![image]()
-
索引内容:在goods_name列上加了前缀索引:
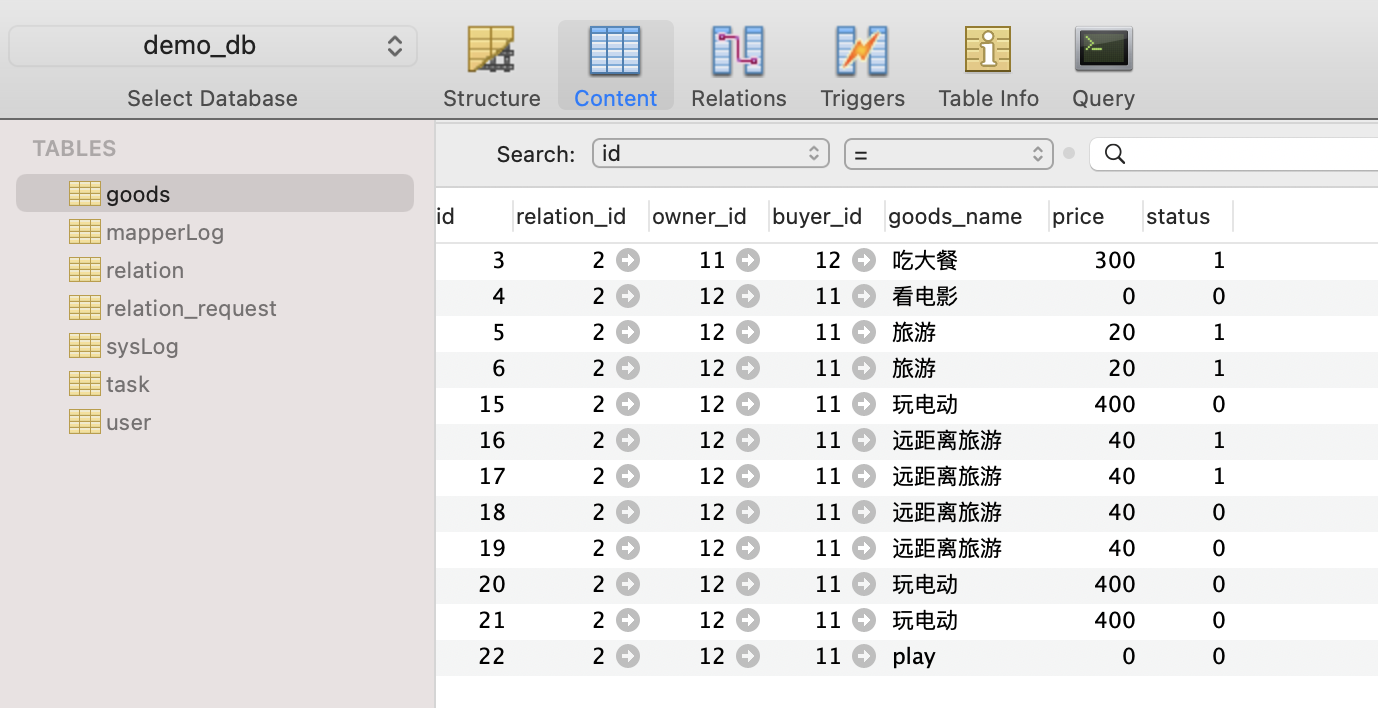
alter table goods add index GoodName(goods_name(3));
- 查找语句比较:
- 使用left(goods_name,1) = 语句
select * from goods where left(goods_name,1)="p";
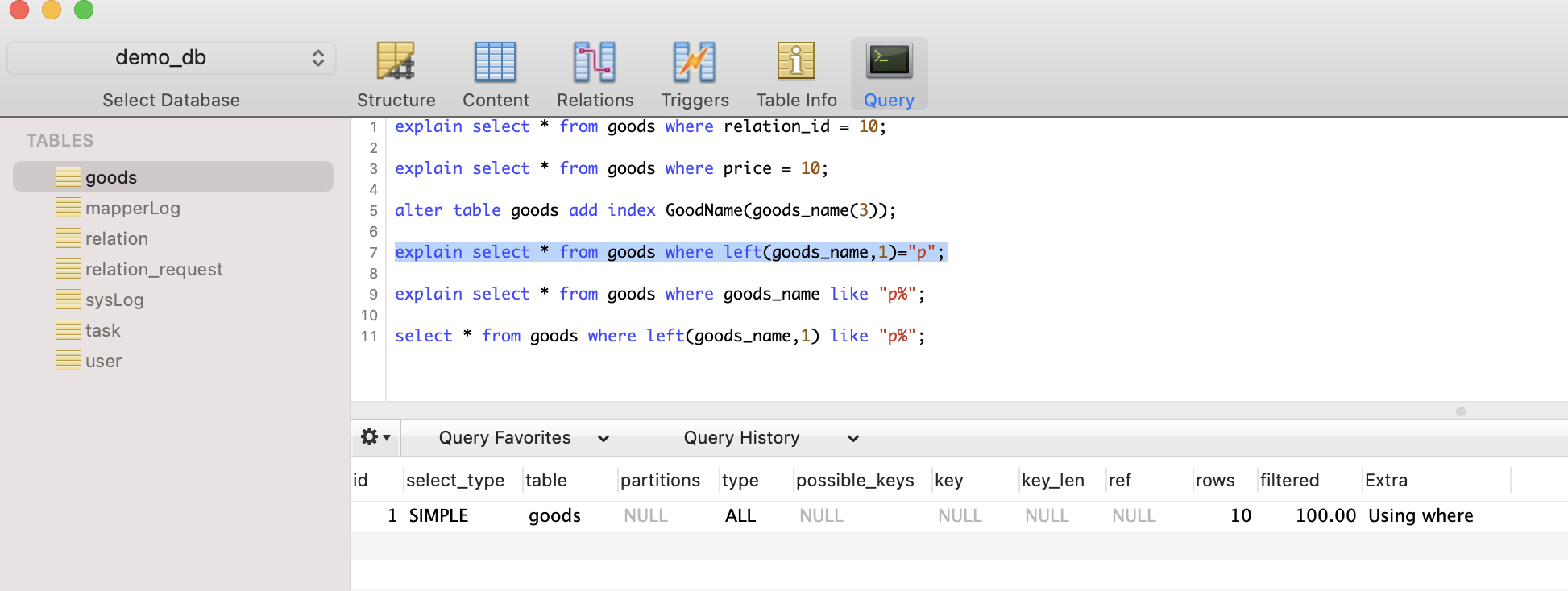
可以看出使用这个语句没有用到索引;
- 使用like语句
select * from goods where goods_name like "p%";
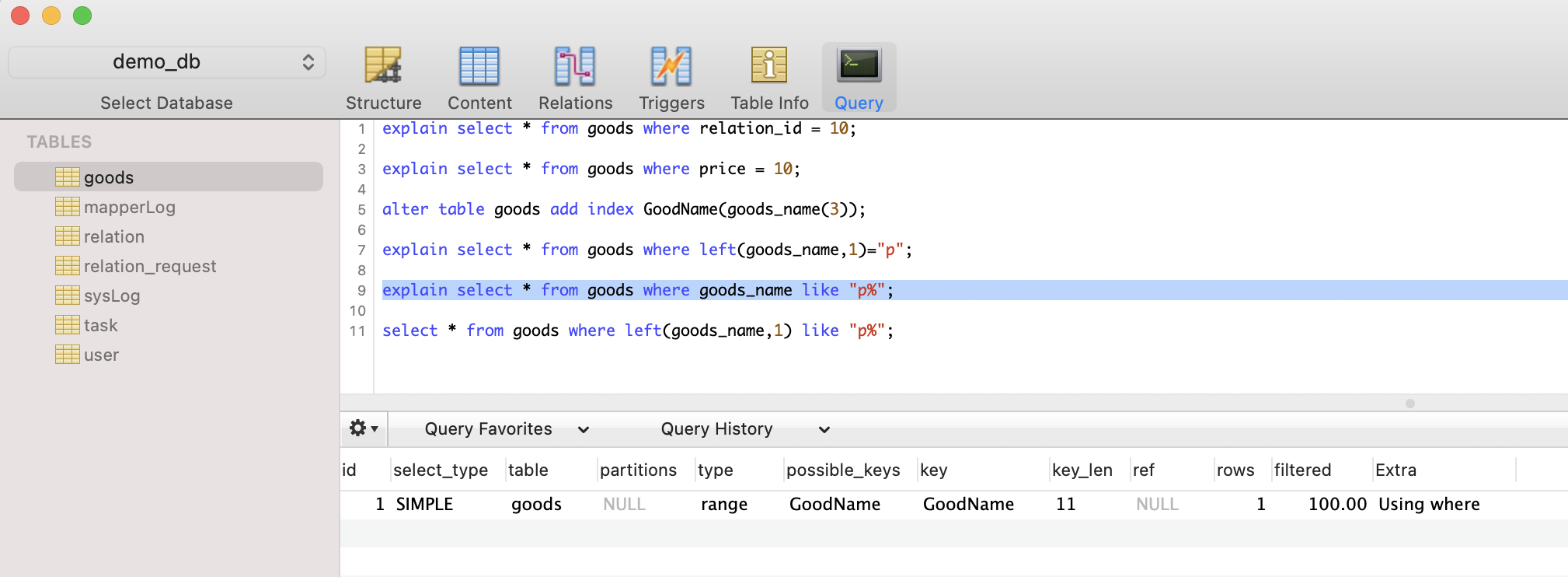
type字段为range,表示使用了索引,范围查找。
查看mysql语句的执行情况
在待执行的语句前面加上explain关键字
explain select * from goods where relation_id = 10;
返回的内容为:

type为ref表示使用了索引,索引名为key。rows是预估需要扫描的行数。
03 数据锁
04 数据库事务
ACID
atomicity,consistency,isolation, durability
隔离级别
- read committed 读提交:事务提交了才能被读
- read uncommitted 读未提交:事务没提交就能被读
- repeatable read 可重复读:事务看到的永远跟它开始时看到的一样
- serializable 串行化:顾名思义是对于同一行记录,“写”会加“写锁”,“读”会加“读锁”。当出现读写锁冲突的时候,后访问的事务必须等前一个事务执行完成,才能继续执行。
利用数据库的多版本并发控制(MVCC)记录回滚段。尽可能少地使用长事务。
当使用可重复读的隔离级别时,数据库会记录read-review视图和回滚段。这样的话反复访问同一视图就需要将事务回滚。
05 日志系统
基于innodb的redo log
不知道你还记不记得《孔乙己》这篇文章,酒店掌柜有一个粉板,专门用来记录客人的赊账记录。如果赊账的人不多,那么他可以把顾客名和账目写在板上。但如果赊账的人多了,粉板总会有记不下的时候,这个时候掌柜一定还有一个专门记录赊账的账本。
如果有人要赊账或者还账的话,掌柜一般有两种做法:
一种做法是直接把账本翻出来,把这次赊的账加上去或者扣除掉;
另一种做法是先在粉板上记下这次的账,等打烊以后再把账本翻出来核算。
在生意红火柜台很忙时,掌柜一定会选择后者,因为前者操作实在是太麻烦了。首先,你得找到这个人的赊账总额那条记录。你想想,密密麻麻几十页,掌柜要找到那个名字,可能还得带上老花镜慢慢找,找到之后再拿出算盘计算,最后再将结果写回到账本上。
这整个过程想想都麻烦。相比之下,还是先在粉板上记一下方便。你想想,如果掌柜没有粉板的帮助,每次记账都得翻账本,效率是不是低得让人难以忍受?
同样,在MySQL里也有这个问题,如果每一次的更新操作都需要写进磁盘,然后磁盘也要找到对应的那条记录,然后再更新,整个过程IO成本、查找成本都很高。为了解决这个问题,MySQL的设计者就用了类似酒店掌柜粉板的思路来提升更新效率。
而粉板和账本配合的整个过程,其实就是MySQL里经常说到的WAL技术,WAL的全称是Write-Ahead Logging,它的关键点就是先写日志,再写磁盘,也就是先写粉板,等不忙的时候再写账本。
具体来说,当有一条记录需要更新的时候,InnoDB引擎就会先把记录写到redo log(粉板)里面,并更新内存,这个时候更新就算完成了。同时,InnoDB引擎会在适当的时候,将这个操作记录更新到磁盘里面,而这个更新往往是在系统比较空闲的时候做,这就像打烊以后掌柜做的事。
如果今天赊账的不多,掌柜可以等打烊后再整理。但如果某天赊账的特别多,粉板写满了,又怎么办呢?这个时候掌柜只好放下手中的活儿,把粉板中的一部分赊账记录更新到账本中,然后把这些记录从粉板上擦掉,为记新账腾出空间。
与此类似,InnoDB的redo log是固定大小的,比如可以配置为一组4个文件,每个文件的大小是1GB,那么这块“粉板”总共就可以记录4GB的操作。从头开始写,写到末尾就又回到开头循环写。
实现在server层的binlog
前面我们讲过,MySQL整体来看,其实就有两块:一块是Server层,它主要做的是MySQL功能层面的事情;还有一块是引擎层,负责存储相关的具体事宜。上面我们聊到的粉板redo log是InnoDB引擎特有的日志,而Server层也有自己的日志,称为binlog(归档日志)。
我想你肯定会问,为什么会有两份日志呢?
因为最开始MySQL里并没有InnoDB引擎。MySQL自带的引擎是MyISAM,但是MyISAM没有crash-safe的能力,binlog日志只能用于归档。而InnoDB是另一个公司以插件形式引入MySQL的,既然只依靠binlog是没有crash-safe能力的,所以InnoDB使用另外一套日志系统——也就是redo log来实现crash-safe能力。
这两种日志有以下三点不同。
redo log是InnoDB引擎特有的;binlog是MySQL的Server层实现的,所有引擎都可以使用。
redo log是物理日志,记录的是“在某个数据页上做了什么修改”;binlog是逻辑日志,记录的是这个语句的原始逻辑,比如“给ID=2这一行的c字段加1 ”。
redo log是循环写的,空间固定会用完;binlog是可以追加写入的。“追加写”是指binlog文件写到一定大小后会切换到下一个,并不会覆盖以前的日志。
有了对这两个日志的概念性理解,我们再来看执行器和InnoDB引擎在执行这个简单的update语句时的内部流程。
执行器先找引擎取ID=2这一行。ID是主键,引擎直接用树搜索找到这一行。如果ID=2这一行所在的数据页本来就在内存中,就直接返回给执行器;否则,需要先从磁盘读入内存,然后再返回。
执行器拿到引擎给的行数据,把这个值加上1,比如原来是N,现在就是N+1,得到新的一行数据,再调用引擎接口写入这行新数据。
引擎将这行新数据更新到内存中,同时将这个更新操作记录到redo log里面,此时redo log处于prepare状态。然后告知执行器执行完成了,随时可以提交事务。
执行器生成这个操作的binlog,并把binlog写入磁盘。
执行器调用引擎的提交事务接口,引擎把刚刚写入的redo log改成提交(commit)状态,更新完成。
06 数据库主从原理
07 sql语法
- 存储过程procedure
建表
mysql> create database db1;
mysql> use db1;
mysql> create table PLAYERS as select * from TENNIS.PLAYERS;
mysql> create table MATCHES as select * from TENNIS.MATCHES;
定义存储过程
mysql> delimiter $$ #将语句的结束符号从分号;临时改为两个$$(可以是自定义)
mysql> CREATE PROCEDURE delete_matches(IN p_playerno INTEGER)
-> BEGIN
-> DELETE FROM MATCHES
-> WHERE playerno = p_playerno;
-> END$$
Query OK, 0 rows affected (0.01 sec)
mysql> delimiter; #将语句的结束符号恢复为分号
08 sql调优
- join语句调优:
使用join语句将两个表连接起来,选择驱动表和被驱动表很重要。看下面的sql语句:
select * from table1 left join table2 on (table1.a=table2.a);
什么是驱动表和被驱动表呢?上面sql中的table1就是驱动表,table2是被驱动表。这个sql的执行流程为:
- 将table1的一条记录R读入内存;
- 根据R.a查找table2的符合条件的记录;
- 做连接操作;
- 继续读下一条记录。
可以看出,在这个过程中,对于驱动表是走的全表扫描,对于被驱动表,需要根据是否有索引判断扫描的条数。
- 对于被驱动表在相应字段上有索引的情况,驱动表选择较小的表、被驱动表选择大表比较好。(INDEX-NESTED-LOOP-JOIN)
- 但假如被驱动表在字段上没有索引,理论上需要对被驱动表也全表扫描,总共要扫描两个表记录数相乘那么多的记录,还会包含一些IO操作,会非常慢。(SIMPLE-NESTED-LOOP-JOIN)
- 但是Mysql实际上不会用SNLJ,会用BLOCKED-NESTED-LOOP-JOIN优化,在内存中进行比较。但是计算量仍然有两个表记录数相乘那么多。
非关系型数据库学习
elasticSearch
Elasticsearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎。Elasticsearch用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。官方客户端在Java、.NET(C#)、PHP、Python、Apache Groovy、Ruby和许多其他语言中都是可用的。根据DB-Engines的排名显示,Elasticsearch是最受欢迎的企业搜索引擎,其次是Apache Solr,也是基于Lucene。
es底层是基于Lucene,最核心的概念就是Segment(段),每个段本身就是一个倒排索引。ES中的Index由多个段的集合和commit point(提交点,一个列出了所有已知段的文件)文件组成。
一个Lucene索引,我们在ES称作分片。一个ES索引是分片的集合。当ES在索引中搜索的时候,他发送查询到每一个属于索引的分片(Lucene 索引),然后像分布式检索提到的那样,合并每个分片的结果到一个全局的结果集。
es为什么这么快?分词+倒排索引
首先使用分词器将文本分词,分析文档再对其进行索引。例如,分词器会把一句话分成若干个单词。
然后使用倒排索引:
例如,有这么几条记录:
| docId | age | Sex |
|---|---|---|
| 1 | 18 | F |
| 2 | 21 | M |
| 3 | 18 | F |
| 4 | 21 | F |
| docId为主键,age,sex为属性,那么会生成倒排索引: | ||
| age字段建立的索引: | ||
| term | PostingList | |
| ------ | ----------- | |
| 18 | [1,3] | |
| 21 | [2,4] |
sex字段建立的索引:
| term | PostingList |
|---|---|
| F | [1,3,4] |
| M | [2] |
以文本为索引键,以主键列表为索引值。
1、Posting list就是一个int的数组,存储了所有符合某个term的文档id。
2、term的数量很多,那查找某个指定的term会变慢。所以采用Term Dictionary,对于term进行排序,采用二分查找,查询logN次才能找到。
3、即便变成查询logN次,但是由于数据不可能全量放在内存,故还是存在磁盘操作,磁盘操作导致耗时增加。所以通过trie树(变种的),构建Term Index。
该trie树不会存储所有的terms。当查找对应的term,根据trie树找到Term Dictionary对应的offset,从偏移的位置往后顺序查找。除此以外,term index在内存中是以FST(finite state transducers)的形式保存的,其特点是非常节省内存。Term dictionary在磁盘上是以分block的方式保存的,一个block内部利用公共前缀压缩,比如都是Ab开头的单词就可以把Ab省去。这样term dictionary可以比b-tree更节约磁盘空间。
倒排索引的特点:
倒排索引被写入磁盘后是不可改变的:它永远不会修改。 不变性有重要的价值:
1、不需要锁。如果你从来不更新索引,你就不需要担心多进程同时修改数据的问题。
2、一旦索引被读入内核的文件系统缓存,便会留在哪里,由于其不变性。只要文件系统缓存中还有足够的空间,那么大部分读请求会直接请求内存,而不会命中磁盘。这提供了很大的性能提升。
3、其它缓存(像filter缓存),在索引的生命周期内始终有效。它们不需要在每次数据改变时被重建,因为数据不会变化。
4、写入单个大的倒排索引允许数据被压缩,减少磁盘 I/O 和 需要被缓存到内存的索引的使用量。
当然,一个不变的索引也有不好的地方。主要事实是它是不可变的,你不能修改它。如果你需要让一个新的文档可被搜索,你需要重建整个索引。这要么对一个索引所能包含的数据量造成了很大的限制,要么对索引可被更新的频率造成了很大的限制。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号