

python
此教程为python3,供个人学习使用
基础语法
注释
#python以#作为注释
此外,python的每个语句后不需要加分号
数据类型
数字类型
python中只有四种数据类型:
- int:表示整数,只有一种整数类型int,表示为长整数(Python2中有Long类型,Python3没有)
- bool:布尔类型,True为1,False为0
- float:浮点数
- complex:复数,由实部和虚部组成,形式为a+bj,j表示虚数单位
字符串String
-
Python没有单独的字符类型,一个字符就为长度为1的字符串
-
Python中单引号''和双引号""使用完全相同
-
使用三引号('''或""")可以指定多行字符串
-
在字符串前加r可以是其中的转义字符不发发生转义
-
+可以连接字符串,*可以使一个字符串重复多次
-
字符串为双向索引,从左到右遍历开始为0,从右到左开始为-1
str1="abc"
str2="def"
str3="""ghi
jkl"""
str4="asd\nzxc"
str5=r"asd\nzxc"
print(str1+str2) #字符串拼接
print(str1*3) #字符串重复
print(str3) #多行字符串
print(str4) #转义字符
print(str5) #不转义
输出:
abcdef
abcabcabc
ghi
jkl
asd
zxc
asd\nzxc
切片
切片适用于列表,元组,字符串,range对象等类型
格式:变量名[start : end : step]
切片是从变量中截取一段,返回一个新的同类型变量
start代表开始位置,end为结束为止,step为步长
截取[start,end)位置的字符串,每隔( |step|-1 )个取一次值
step可以省略,step不能等于0
str="helloworld"
cut = str[2:7:1] #截取[2,7)位置的字符串,隔0个取一次值,也就是依次取值
cut2 = str[2:7:2] #隔1个取一次值
print(cut)
print(cut2)
输出
llowo
loo
当step>0时,代表正向取值,start默认值为0,end默认值为L(字符串长度)
当step<0时,代表负向取值,start默认值为-1,end默认值为-L-1
str="helloworld"
cut = str[-2:-7:-1] #逆向取值,截取[-2,-7)位置的字符串,依次取值
cut2 = str[-2:-7:-2] #隔1个取一次值
print(cut)
print(cut2)
输出
lrowo
loo
行与缩进
python最具特色的就是使用缩进来表示代码块,不需要使用大括号 {}
缩进的空格数是可变的,但是同一个代码块的语句必须包含相同的缩进空格数。实例如下
if True:
print ("True")
else:
print ("False")
如果缩进不一致,会导致错误
多行语句
Python 通常是一行写完一条语句,但如果语句很长,我们可以使用反斜杠 \来实现多行语句,例如:
total = item_one + \
item_two + \
item_three
变量
python是一种动态类型语言,定义变量时无需指定数据类型
x = 3
print(type(x))#type()函数可以查看类型
x = "sdsad"
print(type(x))
x = [1,2,3]
print(type(x))
输出
<class 'int'>
<class 'str'>
<class 'list'>
虽然无需指定,但python仍是强类型语言,python的解释器会根据赋值来判断数据类型
动态类型是由于python采用基于值的内存管理方式成立的:
- 在java中,创建变量后会给对象在内存中开辟一块空间,访问这个地址访问到的是该变量,每次为变量赋值都会修改这个地址的内容
- 而python是为该变量的值开辟空间,不同变量但值相同,二者会指向同一个地址,所以为变量赋一个新值时,会让变量指向新值的地址,从而改变变量的值
运算符
大部分和其他语言相同,这里介绍几个不同的
-
python的除法有两种,/和//分别代表真除法和整除
例如:
3/5 #结果为0.6,真除法会将整数转换为浮点数再除 3//5 #结果为0,整除不会转换 -
and和or具有惰性求值的特点,第一个能判断出结果就直接返回结果
例如and第一个为false,直接返回false;or第一个为true,直接返回true
>>> 3>5 and a>5 #这里的a未被定义,应该报错
False #3<5and能直接判断结果,忽略了a>5的判断,直接返回结果
>>> 3<5 and a>5
NameError: ... #需要判断a>5时才会报错
>>> 3<5 or a >5
True #or同理
-
python不支持++和--
i++ #报错 i-- #报错 ++i #这里的+被看做证数,没有影响 --i #这里的-被看做负数,两个-负负得正,没有影响
import
在 python 用 import 或者 from...import 来导入相应的模块。
- 将整个模块(somemodule)导入,格式为: import somemodule
- 从某个模块中导入某个函数,格式为: from somemodule import somefunction
- 从某个模块中导入多个函数,格式为: from somemodule import firstfunc, secondfunc, thirdfunc
- 将某个模块中的全部函数导入,格式为: from somemodule import *
可迭代对象
可迭代对象指的是实现了_ _ iter _ _()方法的对象
列表
列表是有序可变序列,用[]定义
一个列表可以包含不同类型的元素,也可以包含其他列表
[10,20,30,40]
["red",'blue','yellow']
["apple",20,["banana",30]]
列表的创建与删除
list1 = [10,20,30,40] #直接给变量赋值列表
list2 =list("hello") #使用list()函数将其他可迭代对象转换成列表
#list2=['h','e','l','l','o']
del(list2) #使用del()函数删除列表
列表的修改
增
list1=[1,2,3,2]
list1.append(4) #在列表尾部附加元素
print(list1)
list1.extend([5,6,7]) #在列表尾部附加另一个列表
print(list1)
list1.insert(2,8)
print(list1)
print(list1*2) #使列表重复几次
输出
[1, 2, 3, 2, 4]
[1, 2, 3, 2, 4, 5, 6, 7]
[1, 2, 8, 3, 2, 4, 5, 6, 7]
[1, 2, 8, 3, 2, 4, 5, 6, 7, 1, 2, 8, 3, 2, 4, 5, 6, 7]
删
list1=[1,2,3,2]
list1.remove(2) #删除正向查询到的第一个元素
print(list1)
del list1[0] #使用del命令删除指定索引的元素
print(list1)
a=list1.pop() #删除并返回最后一个元素
print(a,list1)
输出
[1, 3, 2]
[3, 2]
2 [3]
查
list1=[1,2,3,2]
a=list1[2] #根据下标获取元素
print(a)
a=list1.index(3) #使用index()函数根据索引获取元素
print(a)
a=3 in list1 #使用in或not in关键字,查询列表中是否存在某一元素
print(a)
a=list1.count(2) #获取某元素在列表中的数量
print(a)
输出:
3
2
True
2
切片
切片操作在字符串,列表,元组等类型中通用
在作用与元组和字符串时,只能用于访问其中的元素,而作用于列表是可以对列表元素进行增删改查操作
list1=[1,2,3,2]
list1[len(list1):]=[4] #在切片的位置在列表末尾可以添加元素
print(list1)
list1[2:4]=[7,8] #替换掉切片位置的元素
print(list1)
del list1[2:4] #删除切片位置的元素
# list1[2:4]=[] #等于空列表也相当于删除了元素
print(list1)
输出
[1, 2, 3, 2, 4]
[1, 2, 7, 8, 4]
[1, 2, 4]
切片返回的是浅复制,即新建一个变量,将被切片变量中的引用复制到新变量中。这种复制在不同的情况下会不同
str="helloworld"
str2=str[:]
#对于字符串的切片,如果切完后的新字符串和原字符串相同,那么二者都指向同一个地址
print(str2==str) #==判断值是否相同
print(str2 is str) #is 关键字,如果二者指向同一地址,返回true
输出
True
True
#如果切完后二者不同或者切完后新字符串发生了修改,新字符串会指向一个新的地址,新字符串不会影响原字符串
str2+="w"
print(str2==str)
print(str2 is str)
print(str2)
print(str)
输出
False
False #二者不在指向同一地址
helloworldw
helloworld
#而对于列表,切出来的新列表会指向一个新的地址,不会影响原列表
list1=[1,2,3]
list2=list1[:]
print(list1==list2)
print(list1 is list2)
输出
True
False
如果列表基础数据类型和字符串,元组这样不可变的数据类型是没有问题的
但如果包含了列表这样的可变数据类型会发生情况
list1=[1,[2],3] #list1包含了另一个列表
list2=list1[1:]
print(list1 is list2)
输出
False
#list2仍是指向新地址的,但元素中的列表没有改变,指向的还是原来的地址
#所以修改list2中的列表时,会影响到list1中的列表
list2[0].append(4)
print(list1)
print(list2)
输出
[1, [2, 4], 3]#list1的列表也被附加了一个4
[[2, 4], 3]
如果想要不影响,需要进行深复制
list1=[1,[2],3] #list1包含了另一个列表
list2=list1[1:]
import copy#导入copy
list2=copy.deepcopy(list1)#使用deepcopy()函数,遇到可变对象,对其进行复制。以此递归复制,保证list1和list2互不影响
list2[1].append(4)
print(list1)
print(list2)
输出
[1, [2], 3]
[1, [2, 4], 3]
排序
sort()函数可以为列表排序
list1=[1,3,4,2,5,6,3,7,1,0]
list1.sort()#默认升序排序
print(list1)
list1.sort(reverse=True)#reverse=True时为降序排序
print(list1)
输出
[0, 1, 1, 2, 3, 3, 4, 5, 6, 7]
[7, 6, 5, 4, 3, 3, 2, 1, 1, 0]
sort()函数除了reverse参数外,还有一个key参数。
key参数需要传入一个函数,当执行sort()时,列表中的每个元素都会传入进key所传入的函数里,并根据返回结果进行排序
list1=[0, 1, 1, 2, 3, 3, 4, 5, 6, 7]
def reversed(i): #定义一个函数
return -i #该函数返回传入变量的负值
list1.sort(key=reversed)
print(list1)
输出
[7, 6, 5, 4, 3, 3, 2, 1, 1, 0] #根据0,-1,-1,...-6,-7来升序排序的
内置函数
- len()
len(列表名),返回列表中元素个数,同样适用于元组,字典,集合,字符串,range对象
- max(),min()
返回列表中的最大/最小元素,要求所有元素之间可以相互比较,同样适用于元组,字典,集合,字符串,range对象
- sum()
返回列表中所有元素之和,元素不是数值时需要指定第二个参数,同样适用于元组,字典,集合,字符串,range对象
>>>a={1:2,2:3,3:4}
>>>sum(a) #元组默认对key进行相加
6
>>>sum(a.values()) #value进行相加
9
>>>sum([[1],[2]] , []) #列表相加,指定参数
[1,2]
- zip()
将多个可迭代对象,按照位置对应组合成元组,并返回包含这些元组的zip对象
alist=[1,2,3,4] #alist要比下面的要长,则按照最短的对象进行组合,其他对象多出的舍弃
blist=['a','b','c']
clist=['d','e','f']
ziplist=zip(alist,blist,clist)#返回zip对象
print(list(ziplist)) #将zip对象转换为列表输出
输出
[(1, 'a', 'd'), (2, 'b', 'e'), (3, 'c', 'f')]
列表推导式
也叫列表解析式,是对列表进行遍历的语法
列表推导式在逻辑上等同于循环语句,最终会返回一个列表
例如
list1=[1,3,4,2,5,6,3,7,1,0]
list2=[x*x for x in list1]#等号右边为列表推导式
print(list2)
输出
[1, 9, 16, 4, 25, 36, 9, 49, 1, 0]
#等同于
list1=[1,3,4,2,5,6,3,7,1,0]
list2=[]
for x in list1:
list2.append(x*x)
print(list2)
在对列表遍历的for语句前,添加对遍历元素的操作,然后把操作后的结果附加到一个新列表上
x*x部分也可以是一个函数,将函数的返回结果附加到新列表上
元组
元组是有序不可变序列,用()定义
x=(1,2,3)#定义一个元组
如果创建一个单元素元组,需要在元素后面加逗号,
x=(1,)
x=1, #单元素元组可以没有圆括号
可以用tuple()函数将列表,字符串,字典,集合,map对象等转换为元组
print(tuple("hello"))
输出
('h', 'e', 'l', 'l', 'o')
元组属于不可变序列,一旦创建元组内的元组就不允许执行任何增删改,只能使用del命令删除整个元组
元组是不可变的,但从元组中取出的元组元素若是可变的,仍然可以修改
x=(1,[2,3])
x[1].append(4)#这样我们修改的是列表而不是元组中的元素
print(x)
x[1]=[5,6]#不能修改元组中的元素的引用
输出
TypeError: 'tuple' object does not support item assignment
(1, [2, 3, 4])
序列解包
序列解包是一种为多个变量赋值的方式
赋值时要求等号两边数量相同
x,y,z=1,2,3 #为变量x,y,z赋值1,2,3,实际上两边都是元组
vtuple=(True,'a',20)
(x,y,z)=vtuple #变量x,y,z赋值True,a,20
#也可以使用其他可迭代对象
a=[1,2,3]
b,c,d=a
s={'a':1,'b':2,'c':3}
b,c,d=s.items()
#用于遍历多个序列
keys=['a','b','c','d']
values=['1','2','3','4']
for k,v in zip(keys,values): #相当于把zip后的元组赋给k,v
print(k,v)
输出
a 1
b 2
c 3
d 4
生成器表达式
生成器表达式和列表推导式的格式相似,只是把方括号[]改为了圆括号()
生成器表达式返回的是一个迭代器对象,可以根据需要把该对象转换为列表,元组或其他形式
不管转换成那种形式,迭代器对象都只能被用一次,转换后就会变成空的
g=( i for i in range(10) ) #生成器表达式
#range(start,stop,step),每隔(step-1),生成从[start,stop)的整数
print(tuple(g))
print(tuple(g))
输出
(0, 1, 2, 3, 4, 5, 6, 7, 8, 9)
()#第1次转换后变为空的
字典
字典是包含若干键值对的可变容器对象,键与值用冒号:隔开,键值对之间用逗号,隔开
字典用{}定义
adict={'a':1,'b':2,'c':3} #创建一个字典
keys=[1,2,3,4]
values=['a','b','c','d']
bdict=dict(zip(keys,values))#可以用dict函数来创建字典
print(bdict)
输出
{1: 'a', 2: 'b', 3: 'c', 4: 'd'}
字典元素的访问
adict={'a':1,'b':2,'c':3} #创建一个字典
print(adict['c']) #用key来访问value,不存在产生error
print(adict.get('b')) #使用get()函数,传入key返回value,key不存在返回None
print(adict.items()) #item()函数,返回所有键值对
print(adict.keys()) #keys()函数,返回所有的键
print(adict.values()) #values()函数,返回所有的值
输出
3
2
dict_items([('a', 1), ('b', 2), ('c', 3)])
dict_keys(['a', 'b', 'c'])
dict_values([1, 2, 3])
字典元素的增删改
adict={'a':1,'b':2,'c':3} #创建一个字典
adict['d']=4 #如果这个键不存在,则新建一个键值对存入字典
adict['a']=5 #如果这个键存在,则修改该键的值
del adict['b'] #删除键所对应的键值对
# adict.clear() #清除字典中的所有元素
c=adict.pop('c') #删除键对应的键值对并返回值
print(c)
print(adict)
输出
3
{'a': 5, 'd': 4}
集合
集合是无序可变容器对象,和字典一样用花括号{}定义
同一集合中的元素不允许重复
a={1,2,3}
print(a)
a={1,1,2,2,3,3}
print(a)
输出
{1, 2, 3}
{1, 2, 3}#重复的元素会被删除
集合的增删改
- add()方法添加元素
- pop()删除并返回第一个元素
- remove()或discard()删除指定元素
- clear()删除所有元素,del 删除集合
集合运算
集合支持交并差集操作,和数学中的集合运算规则一直
a={1,2,3,4,5}
b={4,5,6,7,8}
print(a|b) #并集
print(a&b) #交集
print(a-b) #差集
输出
{1, 2, 3, 4, 5, 6, 7, 8}
{4, 5}
{1, 2, 3}
控制结构
条件表达式
在选择和循环结构中,只要条件表达式不是False,0,以及一系列空值,空列表之类的,Python解释器同一认为与True等价
map,zip等所有迭代器对象都为True
对象的TrueFalse根据其内置函数bool()的结果判定
选择
最简单的选择结构就是if,这里介绍几种它的写法
#if语句
if 表达式:
语句块
#if...else
if 表达式:
语句块
else:
语句块
#python还支持这种形式,效果类似于条件表达式
#如果表达式为True,a=value1;为False,a=value2
a=(value1 if 表达式 else value2)
#elseif在python中简化成了elif
#if...else
if 表达式:
语句块
elif 表达式2:
语句块
elif 表达式3:
语句块
由于Python不用{}来限制区域,所以使用if语句时一定要注意好每行的缩进
如果出现了这个:TabError: inconsistent use of tabs and spaces in indentation
就是你没对齐。有时候你确实对齐了,但是解释器认为你没对齐,你需要把这些空格重新删了再对一遍
多分支选择结构
python3.9之前没有提供过类似于switch之类的多分支选择结构
Python3.10提供了软关键字match和case,可以用于实现多分支选择结构
软关键字指的是在特定场合作为关键字,普通场合可以做变量名
不过它都做关键字了,还是别把他当变量名用了
a=3
match a: #相当于switch(a)
case 3:
print("3")
case 4:
print("4")
case _: #Python中下划线_代表通配符,可以用于占位。在这里表示如果上面情况都不匹配则执行这里,当做Default用
print("none")
#case后还可以接条件表达式
match(3,5):
case(x,y):if x<y
print("<")
#_通配符代表任意一项,*_表示在当前位置后还有任意多项
a=[1,2,3,4]
match a:
case[1, 2, *_]: #第0个和第1个元素为1,2,且之后有0或任意个元素匹配此项
print("[1,2,...]]")
case [1,2]:#第0个和第1个元素为1,2,且列表只有这两个元素匹配此项
print("[1,2]")
case [1,2,3,4]:
print("[1,2,3,4]")
输出:
[1,2,...] #没有输出[1,2,3,4],说明在一个case被匹配后自动执行break了,直接跳出了match,不会发生case穿透
循环
while和for
最基本的两种循环就是while和for,只不过python中没有其他语言中传统的for,只有foreach
while 条件表达式:
循环体
#for只有foreach,没有for(::)
for 循环变量 in 可迭代对象:
循环体
#Python为while和for添加了else子句,当循环因为条件表达式不成立而导致循环结束后,执行else子句,、
#只有在条件表达式不成立时执行else,像break结束循环这种不会执行else
while 条件表达式:
循环体
else:
else代码块
for 循环变量 in 可迭代对象:
循环体
else:
else代码块
break和continue
break和continue在while和for中都可以使用
和其他语言作用一样:
执行到时break使整个循环停止,跳出循环,执行下一部分代码
执行到时continue跳过本次循环,忽略continue后所有的循环体代码,直接进行下一次循环
字符串和正则表达式
Python3.0后程序默认使用UTF-8编码
字符串
字符串使用单引号,双引号和三引号作为界定符,不同的界定符之间可以互相嵌套
字符串属于不可变序列,不能对字符串对象进行元素添加,修改和删除操作
字符串对象提供的replace(),translate()等方法不是对原字符串进行直接修改,而是返回一个修改替换后的字符串
字符串格式化
使用 '格式字符' % 待转换表达式 的形式对字符串进行格式化,格式字符是对字符串进行某种操作的指标
常见的格式字符如下:
| 格式字符 | 说明 | 格式字符 | 说明 | 格式字符 | 说明 |
|---|---|---|---|---|---|
| %s | 字符串采用str()形式显示 | %d/%i | 转换为十进制整数 | %e/%E | 转换为指数(基底写为e/E) |
| %r | 字符串采用repr()形式显示 | %o | 转换为八进制整数 | %f/%F | 转换为浮点数 |
| %c | 转换为单个字符(根据ASCII码) | %x | 转换为十六进制整数 | %g/%G | 指数(e/E)或浮点数(显示长度决定) |
| %% | 字符"%" |
name,age="zhangsan",20
a = '名字是%s , 年龄是%d '%(name,age)
b = '名字是%(bname)s , 年龄是%(bage)d '%{'bname':'lisi','bage':45}
c = 'π = %.2f'%3.1415926
print(a,'\n'+b,'\n'+c)
输出
名字是zhangsan , 年龄是20
名字是lisi , 年龄是45
π = 3.14
一般情况下,和c语言的print函数相似
也可以使用format()方法进行格式化
name,age="zhangsan",20
a = '名字是{} , 年龄是{} '.format(name,age)#{}为占位符,format参数以此占位
b = '名字是{1}, 年龄是{0} '.format('lisi',45)#根据占位符指定的下标进行占位
c = 'a的名字是{name},年龄是{age}'.format(**{'name':'zhangsan','age':20})#需要在字典前加两个星号,对字典进行序列解包
d = 'π = {:.2f}'.format(3.1415926) #占位符{}内的冒号:为格式说明符,相当于格式字符的百分号
print(a,'\n'+b,'\n'+c,'\n'+d)
输出
名字是zhansgan , 年龄是20
名字是45, 年龄是lisi
a的名字是zhangsan,年龄是20
π = 3.14
Python3.6+版本提供了format()方法的简化f-string模式
在字符串前加f/F,在占位符{}里写变量名,格式说明符:后写格式字符
name,age="zhangsan",20
a = f'名字是{name} , 年龄是{age} '#占位符内写变量
b = f'名字是{'lisi'}, 年龄是{45} '
c = f'π = {3.1415926:.2f}' #字符写在格式说明符之前
print(a,'\n'+b,'\n'+c)
输出
名字是zhangsan , 年龄是20
名字是lisi, 年龄是45
π = 3.14
字符串常用方法
find(),rfind();index(),rindex(),count()
index()/rindex()返回字符串str在原字符串首次/最后一次出现的位置,不存在报错,可以指定查找位置
find()/rfind()和index()/rindex()用法完全一致,不同的是查找不存在或报错时返回-1
count返回字符串在原字符串中出现的次数,不存在返回0
str="bananaappleapplebananapeach"
print(str.find("apple"))
print(str.rfind("apple"))
print(str.index("banana"))
print(str.rindex("banana"))
print(str.count("peach"))
print(str.count("watermelon"))
print(str.find("watermelon"))
print(str.index("watermelon"))
输出:
6
11
0
16
1
#count不存在返回0,find返回-1,index报错
0
-1
Traceback (most recent call last):
File "E:\WorkSpaces\pythonProject\Test01\main\main.py", line 12, in <module>
print(str.index("watermelon"))
^^^^^^^^^^^^^^^^^^^^^^^
ValueError: substring not found
split(),rsplit();partition(),rpartition()
split()和rsplit(),根据指定的字符串,对原字符串从左到右/从右到左进行分割,并返回一个列表
partition(),rpartition(),根据指定的字符串,将原字符串分割成三部分:分隔符前的字符串,分隔符,分隔符后的字符串,以元组返回
str="apple,banana,orange"
print(str.split(","))
print(str.rsplit(","))
print(str.partition("banana"))
print(str.rpartition("banana"))
输出:
['apple', 'banana', 'orange']
['apple', 'banana', 'orange']
('apple,', 'banana', ',orange')
('apple,', 'banana', ',orange')
对于split()和rsplit()
如果没有传入参数,那么一切空白符号(空格,换行符,制表符等)会被作为分隔符使用
如果字符串中存在分隔符相邻,则会将相邻之间的空字符串给提取出来
str="apple,,b anan\na,,orange"
#未传入参数,空格和\n被当做分隔符
print(str.split())
print(str.rsplit())
#banana后有两个,,,他们两个之间会分割出一个空字符串
print(str.split(","))
print(str.rsplit(","))
输出
['apple,,b', 'anan', 'a,,orange']
['apple,,b', 'anan', 'a,,orange']
['apple', '', 'b anan\na', '', 'orange']
['apple', '', 'b anan\na', '', 'orange']
其他方法
由于方法过多,下面就只做简单介绍
-
join():join()方法可将可迭代对象(只包含字符串)中的全部字符进行连接
-
lower()/upper():将字符串中的英文转化为小写/大写
-
capitalize():将字符串首字母转为大写
-
title():将字符串中每个单词的首字母转为大写
-
swapcase():将字符串中的英文大小写互换
-
replace():替换字符串中的指定字符,返回处理后的字符串,不修改原字符串
-
strip()/rstrip()/lstrip():将字符两/右/左端的空格删除
-
eval():尝试将任意字符字符串转换为Python表达式并求值
str=eval('3+1')
a,b=3,6
str2=eval('a+b')
print(str,str2)
输出:
4 9
如果传入的字符串不能转换为算式,NameError
- startswith()/endswith():判断字符串是否以指定字符开始/结束
可以用于识别文件后缀名
- isalnum():判断字符串是否全为数字字符+英文字母
isalpha():是否全为英文字母
isdigit():是否全为数字字符
isspace():是否全为空白字符
isupper()/islower():英文字符是否全为大写/小写
- center()/ljust()/rjust()
返回指定宽度的字符串,以居中/靠左/靠右对齐方式返回
可以传入两个参数(int指定宽度,String两端的填充字符)
正则表达式
正则表达式用于处理字符串,进行增删改查操作。
整个处理字符串的公式被称为模式,模式中的每个元素被称为元字符
元字符
常用的元字符如下
| 元字符 | 含义 |
|---|---|
| () | ()内的内容当做一个整体来对待,成为一个子模式 |
| . | 默认匹配除换行符外的任意单个字符 \ . 前面加反斜线用于匹配圆点字符 |
| * | 匹配*前的字符或子模式0或多次 |
| + | 匹配+前的字符或子模式1或多次 |
| [],- | 二者协同使用,[]表示匹配括号内范围字符,如 '[0-9a-z]' 表示匹配09是数字和az的小写字母 []的内部开头写^,表示不匹配里面的字符 |
| | | 匹配|之前或之后的模式,表示或,可以重复多用表示多选一 |
| ^ | 匹配以^后面的字符或模式开头的字符串 |
| $ | 匹配以$前面的字符或模式结束的字符串 |
| {m,n}表示匹配{}前的字符或子模式m~n次 {m,}匹配{}前的字符或子模式m~+∞次 {,n}匹配{}前的字符或子模式~n次 {m}匹配{}前的字符或子模式恰好m次 {}内部不能有任何空格 |
|
| ? | 表示?前的字符或子模式可有可无 ?前为*,+,?,{}时,表示匹配模式为"非贪心",会返回尽可能少的结果(默认都是贪心,返回尽可能多的字符) 如re.findall('abc{,3}?','abccc'),匹配ab+0~3个c,?前为{},以非贪心模式返回'ab' 如re.findall('abc{,3}','abccc'),匹配ab+0~3个c,没有问号,以贪心模式返回'abccc' |
| \f,\n,\r | 匹配一个换页符/换行符/回车符 |
| \d,\D | \d匹配任意单个数字字符,等同于'[09]',\D与之相反,匹配除'[09]'外的字符 |
| \w,\W | \w匹配任意单个字母,汉字,数字及下划线,\W与之相反 |
| \b,\B | \b匹配单词头或尾,\B相反匹配单词内部 |
| \s,\S | \s匹配任意空白字符(空格,制表符,换页符,换行符,及'[\f\n\r\t\v]'),\S与之相反,匹配除空白字符外任意单个字符 |
re模块
python中,主要使用re模块来实现正则表达式的操作
import re #导入re模块
在使用时,既可以用re模块自带的函数进行处理,也可以创建正则表达式对象,然后用该对象的方法操作字符串
re模块的函数先根据正则表达式去匹配字符串,再去处理匹配到的字符串,最终返回结果
常用函数如下:pattern为正则表达式的模式,string为要匹配的字符串,flags为为函数添加特殊约束
| 函数 | 功能 |
|---|---|
| complie(pattern[,flags]) | 创建正则表达式对象 |
| findall(pattern,string[,flags]) | 返回字符串中模式的所有匹配项组成的列表 |
| match(pattern,string[,flags]) | 从字符串的开始处匹配模式,返回Match对象或None |
| search(pattern,string[,flags]) | 在整个字符串中寻找模式,返回Match对象或None |
| split(pattern,string[,maxsplit=0]) | 根据模式分割字符串 |
| sub(pattern,repl,string[,count=0]) | 将字符串中pattern的所有匹配项用repl替换 |
| escape(string) | 将字符串中所有正则表达式特殊字符进行转义 |
str='123456'
pattern=re.compile('\d+')#创建正则表达式对象
str1=re.findall('\d+',str+'12',re.A) #使用re自带函数匹配
str2=pattern.findall(str) #使用正则表达式的方法匹配
print(str1)
print(str2)
输出:
['12345612']
['123456']
实际上,创建出的正则表达式对象的方法和re提供的那几个函数没什么区别
子模式和Match对象
()确定一个子模式,一个子模式为一个整体,如(red)+表示匹配red 1~多次
函数
在Python中,函数的定义如下:
def 函数名([形参列表]):
'"注释"'
函数体
使用def关键字定义函数。
Python的函数和参数都不用定义类型,解释器会自动推断。必须要注意首行缩进,缩进长度决定作用域
使用 函数名([形参列表]) 调用函数
参数
默认值参数
定义函数时可以为参数设置默认值,当该参数未被传递时使用默认值
def num(a,b=3):
#为b参数设置默认值3
return a+b
print(num(1))#只为a传递了参数
输出
4
设置了默认值的参数,后面所有的参数都要设置默认值,否则会报错
def num2(a=3,b):
return a+b
print(num2(1,2))#即使给b传递了参数,也会报错
输出
SyntaxError: parameter without a default follows parameter with a default
Python采用基于值的内存管理方式,两个相同值的对象指向的是同一个地址
所以对于默认值,也会给开辟一片地址,来存储函数定义时给的值,不给该参数传值时函数就会使用该地址的引用,来为该参数赋值。
这种方式对于可变类型,例如列表,会产生逻辑错误
def num(a,b=[]):# 这段代码的本意是如果未传b,则返回只有元素a的列表。
b.append(a)
return b
print(num(1))
print(num(2))
print(num(3))
输出:
[1]
[1, 2]
[1, 2, 3]
如果默认值为列表这种可变类型,对其进行函数内部使用下标,或可变对象自身增删改元素,会对默认值进行修改,导致逻辑上的错误
对于这种情况,应将其赋值为空值None,再在函数内部指定其为何类型
def num(a,b=None):
if b is None:
b=[]
b.append(a)
return b
print(num(1))
print(num(2))
print(num(3))
输出:
[1]
[2]
[3]
关键参数
关键参数即可以通过参数名来传递实参,这种方式可以不按函数规定传递参数
def num(a,b,c=3):
return a+b+c
print(num(1,2))#正常情况
print(num(b=1,c=8,a=5))#指定了参数名后,可以不按abc顺序传参
输出:
6
14
对于Python3.8及更高版本,允许将斜线/和星号*作为参数。这两个符号不为真正参数,用于约束其它参数
- /表示前面的所有参数都必须按照函数规定的位置传递参数
- *表示后面的所有参数都必须以关键参数形式传递参数
def num(a,/,b,*,c,d=3):
return a+b+c+d
print(num(1,2,d=6,c=1)) # /前面的a只能传递数字,不能以a=1的形式传递;后面的cd只能以c=1,d=6的形式传递,否则会报错
print(num(2,b=1,c=3,d=9))#对于中间的b,不在这两个符号的控制范围内,就没有约束了
输出:
10
15
可变长度参数
python支持函数可以传递任意个参数,以*和**作为代表
- *表示把传入的任意个参数整合为一个元组使用
- **表示把传入的任意个参数整合为一个字典使用
def num(*a):#作为元组
return a
print(num(1,2,3))
print(num(1,2,3,4))
输出:
(1, 2, 3)
(1, 2, 3, 4)
def num2(**a):#作为字典
return a
print(num2(x=1,y=2))
print(num2(x=1,y=2,z=3))
输出:
{'x': 1, 'y': 2}
{'x': 1, 'y': 2, 'z': 3}
可变长度参数可以与正常的参数使用,将其后面多出的所有参数整合起来。
序列解包
对于可迭代对象参数,可以在其传递时前加一个星号*,以表示对齐进行解包,这样会将其中的元素按照顺序为参数赋值
def num(a,b,c):
return a+b+c
print(num(1,2,3))
print(num(*[1,2,3]))#*将列表[1,2,3]解包,其中的函数按顺序为参数abc赋值
输出:
6
6
如果需要解包的是字典,则前面使用两个型号,将字典解包成键值对,键作为参数名,值作为参数的值
return
return表示函数的结束,在任何地方被执行到都会结束该函数
Python中return默认返回一个空值 None,即使没有return语句,也会返回空值None
Lambda表达式
Lambda表达式常用于声明匿名函数,可以包含一个表达式,不允许使用控制结构,函数定义等语法,可以调用其他函数,支持默认值参数和关键值参数,函数的返回值就是表达式的值
f=lambda x,y,z=3:x+y+z #lambda函数f,有xyz三个参数,z有默认值3,返回值为x+y+z
print(f(y=3,x=1)) #使用关键参数
输出:
7
L=[(lambda a,b:a+b),(lambda a,b:a-b)] #可以作为可迭代对象的元素
print(L[0](2,1))
print(L[1](b=1,a=2))
输出:
3
1
def square(num):
return num*num
alist=[1,2,3]
print(list(map(lambda x:square(x),alist)))#可以调用其他函数
输出:
[1, 4, 9]
常用函数
map(function, iterable,...)
将可迭代对象中的元素以此作为参数传递给function,返回一个map对象,其中的值为可迭代对象的元素,传入给function后得到的返回值
常和list()函数结合使用,直接将map对象转换为列表输出
reduce(function, iterable[, initializer])
将可迭代对象的所有元素,依次迭代传给一个双参数函数
def add(a,b):
return a+b
print(reduce(add,[1,2,3,4,5]))
输出:
15
其运行的步骤如下:
-
reduce(add,[1,2,3,4,5])
-
reduce(add,[3,3,4,5])
-
reduce(add,[6,4,5])
-
reduce(add,[10,5])
-
15
面向对象
Python支持面向对象
类定义
使用class关键字定义类
class Car:
def infor(self):#成员方法,self相当于java中this
print("IMCARRRRR")
通过构造函数创建对象,不用new关键字
car = Car()
car.infor()
输出:
IMCARRRRR
Python提供了内置函数isinstance(),来检验对象是否属于某个类
isinstance(car,Car)#如果car对象属于Car类,返回True,否则False
构造函数和析构方法
构造函数统一为 __ init __ (),析构方法为__ del __ ()
class Car:
color = 'blue'
def __init__(self,c):
self.color=c
def __del__(self)
print("end")
car = Car("red")
print(car.color)
输出:
red
私有和公有
python的访问权限不用关键字来标明,使用下划线
如果成员名以两个下划线__开头但不以两个下划线结束,则表示为私有成员
class Car:
color = 'blue'#公有成员
__value= 128 #私有成员
def __init__(self,c,v):
self.color=c
self.__value=v
下划线对访问权限的设置如下:
-
xxx,没有下划线,表示public
-
_xxx,前一个下划线,表示protected
-
__xx,前两个下划线,表示private
-
__ xx__,前后都有双下划线,表示为系统预定义的特殊成员,不能随意定义和添加,只能修改和重写
成员方法
成员方法的公私有性,由注解决定
class Car:
color = 'blue'
__value= 128
def __init__(self,c,v):
self.color=c
self.__value=v
#python提供类方法,该方法在被调用时,自动将类本身作为第一个参数传入该方法。
#类方法可以使用cls访问和修改类属性
@classmethod
def from_string(cls):
print(cls.__value)
#该函数为静态函数
@staticmethod
def showColor():
print(Car.color)
def showAll(self):
print(self.color)
print(self.__value)
car = Car("red",256)
car.showAll()
car.showColor()
car.from_string()
输出:
red
256
blue
128
对于公有方法,需要显式的为该方法传入一个self参数,用于明确指定访问那个对象的成员
静态方法和类方法可以用对象或类名调用。被调用时,只能访问类原有的成员,而不会访问调用它们的对象的成员
Python还支持@property注解,该注解将类中的方法转换为属性,属性值即类的返回值
class A:
@property
def number(self):
return 1
a=A()
print(a.number)
输出:
1
抽象方法只能在抽象类中定义。抽象类不能实例化,只有实现了抽象类的所有抽象方法的派生类才能实例化
#import abc模块,以此标识为抽象类
class AbstarctBase(abc.ABC):
#使用abc模块的注解来标识抽象方法
@abc.abstractmethod
def show(self):
pass
#实现抽象类的类
class Student(AbstarctBase):
__value =1024
def __init__(self,v):
self.__value=v
#重写方法
def show(self):
print(self.__value)
student = Student(2048)
student.show()
继承
父类或基类对应子类或派生类
class Father:
def __init__(self, name, age):
self.name = name
self.age = age
def showAll(self):
print(self.name, self.age)
class Child(Father):
def __init__(self, name, age,sex):
self.name = name
self.age = age
self.sex=sex
def showSex(self):
print(self.sex)
c=Child("John", 20, "Male")
c.showAll()
c.showSex()
输出:
John 20
Male
继承的方法是,在类的后面加中括号(),里面写父类的类名
Python支持多重继承,所有父类的方法都会继承到子类中
类似于C继承B,B继承A这样的继承,称为多级继承
由于多重和多级继承,Python中的多个类的继承可以总结出继承树,例如:
class base:
def show(self):
print("base")
class A(base):
def show(self):
print("Enter A")
super().show()
print("Exit A")
class B(base):
def show(self):
print("Enter B")
super().show()
print("Exit B")
class C(base):
def show(self):
print("Enter C")
super().show()
print("Exit C")
class D(A,B,C):
def show(self):
print("Enter D")
super().show()
print("Exit D")
d=D()
d.show()
该程序的继承树为
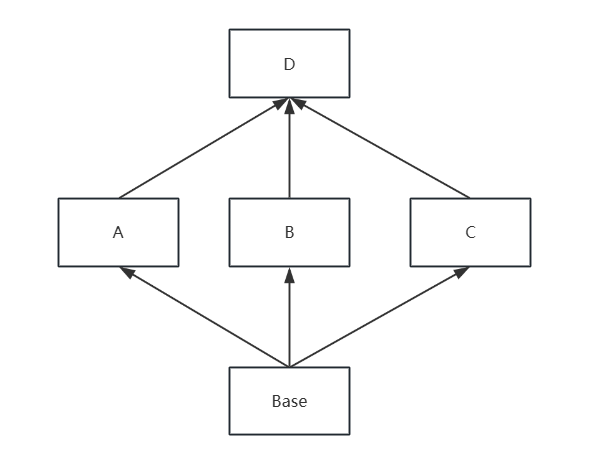
Python类的调用是根据MRO表决定的,通过 类名._ _ mro_ _属性来查看MRO表

 浙公网安备 33010602011771号
浙公网安备 33010602011771号