

列表字典
序列中的每个值都有对应的位置值,称之为索引,第一个索引是 0,第二个索引是 1,依此类推。
Python 有 6 个序列的内置类型,但最常见的是列表和元组。
列表都可以进行的操作包括索引,切片,加,乘,检查成员。
此外,Python 已经内置确定序列的长度以及确定最大和最小的元素的方法。
列表是最常用的 Python 数据类型,它可以作为一个方括号内的逗号分隔值出现。
列表的数据项不需要具有相同的类型
创建一个列表,只要把逗号分隔的不同的数据项使用方括号括起来即可。如下所示:
list1 = ['Google', 'Runoob', 1997, 2000] list2 = [1, 2, 3, 4, 5 ] list3 = ["a", "b", "c", "d"] list4 = ['red', 'green', 'blue', 'yellow', 'white', 'black']
访问列表中的值
与字符串的索引一样,列表索引从 0 开始,第二个索引是 1,依此类推。
通过索引列表可以进行截取、组合等操作。
列表函数方法
| 1 | list.append(obj) 在列表末尾添加新的对象 |
| 2 | list.count(obj) 统计某个元素在列表中出现的次数 |
| 3 | list.extend(seq) 在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表) |
| 4 | list.index(obj) 从列表中找出某个值第一个匹配项的索引位置 |
| 5 | list.insert(index, obj) 将对象插入列表 |
| 6 | list.pop([index=-1]) 移除列表中的一个元素(默认最后一个元素),并且返回该元素的值 |
| 7 | list.remove(obj) 移除列表中某个值的第一个匹配项 |
| 8 | list.reverse() 反向列表中元素 |
| 9 | list.sort( key=None, reverse=False) 对原列表进行排序 |
| 10 | list.clear() 清空列表 |
| 11 | list.copy() 复制列表 |
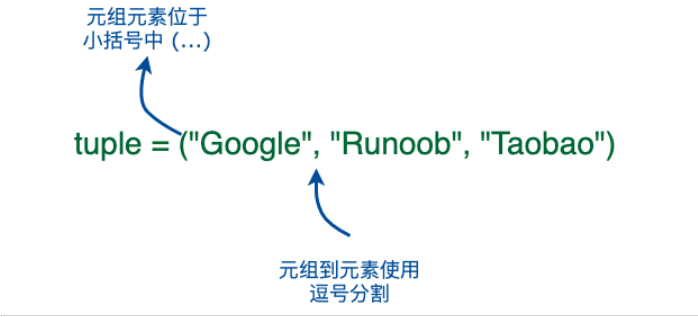
Python 的元组与列表类似,不同之处在于元组的元素不能修改。
元组使用小括号 ( ),列表使用方括号 [ ]。
元组创建很简单,只需要在括号中添加元素,并使用逗号隔开即可。
创建空元组
tup1 = ()
访问元组
元组可以使用下标索引来访问元组中的值,如下实例:
#!/usr/bin/python3
tup1 = ('Google', 'Runoob', 1997, 2000)
tup2 = (1, 2, 3, 4, 5, 6, 7 )
print ("tup1[0]: ", tup1[0])
print ("tup2[1:5]: ", tup2[1:5])
以上实例输出结果:
tup1[0]: Google
tup2[1:5]: (2, 3, 4, 5)
元组内置函数
| 1 | len(tuple) 计算元组元素个数。 |
>>> tuple1 = ('Google', 'Runoob', 'Taobao')
>>> len(tuple1)
3
>>>
|
| 2 | max(tuple) 返回元组中元素最大值。 |
>>> tuple2 = ('5', '4', '8')
>>> max(tuple2)
'8'
>>>
|
| 3 | min(tuple) 返回元组中元素最小值。 |
>>> tuple2 = ('5', '4', '8')
>>> min(tuple2)
'4'
>>>
|
| 4 | tuple(iterable) 将可迭代系列转换为元组。 |
>>> list1= ['Google', 'Taobao', 'Runoob', 'Baidu']
>>> tuple1=tuple(list1)
>>> tuple1
('Google', 'Taobao', 'Runoob', 'Baidu')
|
字典
字典是另一种可变容器模型,且可存储任意类型对象。
字典的每个键值 key=>value 对用冒号 : 分割,每个对之间用逗号(,)分割,整个字典包括在花括号 {} 中 ,格式如下所示:
d = {key1 : value1, key2 : value2, key3 : value3 }
键必须是唯一的,但值则不必。
值可以取任何数据类型,但键必须是不可变的,如字符串,数字。
字典内置函数&方法
Python字典包含了以下内置函数
| 1 | radiansdict.clear() 删除字典内所有元素 |
| 2 | radiansdict.copy() 返回一个字典的浅复制 |
| 3 | radiansdict.fromkeys() 创建一个新字典,以序列seq中元素做字典的键,val为字典所有键对应的初始值 |
| 4 | radiansdict.get(key, default=None) 返回指定键的值,如果键不在字典中返回 default 设置的默认值 |
| 5 | key in dict 如果键在字典dict里返回true,否则返回false |
| 6 | radiansdict.items() 以列表返回可遍历的(键, 值) 元组数组 |
| 7 | radiansdict.keys() 返回一个迭代器,可以使用 list() 来转换为列表 |
| 8 | radiansdict.setdefault(key, default=None) 和get()类似, 但如果键不存在于字典中,将会添加键并将值设为default |
| 9 | radiansdict.update(dict2) 把字典dict2的键/值对更新到dict里 |
| 10 | radiansdict.values() 返回一个迭代器,可以使用 list() 来转换为列表 |
| 11 | pop(key[,default]) 删除字典给定键 key 所对应的值,返回值为被删除的值。key值必须给出。 否则,返回default值。 |
| 12 | popitem() 随机返回并删除字典中的最后一对键和值。 |
集合
集合(set)是一个无序的不重复元素序列。
可以使用大括号 { } 或者 set() 函数创建集合,注意:创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。
创建格式:
parame = {value01,value02,...}
或者
set(value)
>>> basket = {'apple', 'orange', 'apple', 'pear', 'orange', 'banana'}
>>> print(basket) # 这里演示的是去重功能
{'orange', 'banana', 'pear', 'apple'}
>>> 'orange' in basket # 快速判断元素是否在集合内
True
>>> 'crabgrass' in basket
False
>>> # 下面展示两个集合间的运算.
...
>>> a = set('abracadabra')
>>> b = set('alacazam')
>>> a
{'a', 'r', 'b', 'c', 'd'}
>>> a - b # 集合a中包含而集合b中不包含的元素
{'r', 'd', 'b'}
>>> a | b # 集合a或b中包含的所有元素
{'a', 'c', 'r', 'd', 'b', 'm', 'z', 'l'}
>>> a & b # 集合a和b中都包含了的元素
{'a', 'c'}
>>> a ^ b # 不同时包含于a和b的元素
{'r', 'd', 'b', 'm', 'z', 'l'}
集合内置方法完整列表
| add() | 为集合添加元素 |
| clear() | 移除集合中的所有元素 |
| copy() | 拷贝一个集合 |
| difference() | 返回多个集合的差集 |
| difference_update() | 移除集合中的元素,该元素在指定的集合也存在。 |
| discard() | 删除集合中指定的元素 |
| intersection() | 返回集合的交集 |
| intersection_update() | 返回集合的交集。 |
| isdisjoint() | 判断两个集合是否包含相同的元素,如果没有返回 True,否则返回 False。 |
| issubset() | 判断指定集合是否为该方法参数集合的子集。 |
| issuperset() | 判断该方法的参数集合是否为指定集合的子集 |
| pop() | 随机移除元素 |
| remove() | 移除指定元素 |
| symmetric_difference() | 返回两个集合中不重复的元素集合。 |
| symmetric_difference_update() | 移除当前集合中在另外一个指定集合相同的元素,并将另外一个指定集合中不同的元素插入到当前集合中。 |
| union() | 返回两个集合的并集 |
| update() | 给集合添加元素 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号