ELK搭建记录
一、Elasticsearch
1、新建用户
新版本的elasticsearch 不允许使用root用户
useradd els
2、下载软件
分别包括 elasticsearch-7.8.0 filebeat-7.8.0 kibana-7.8.0 logstash-7.8.0
解压缩文件到指定目录,这里放置到/home/app/下面,然后做软连接。
3、elasticsearch硬件要求
I、硬盘
- 固态盘 SSD
- 修改调度算法,可以使用
deadline或者noop。deadline 调度程序基于写入等待时间进行优化, noop 只是一个简单的 FIFO 队列。
- 修改调度算法,可以使用
- 机械硬盘
- 选择高性能服务器硬盘,如15k RPM 驱动器
- 使用RAID
- 使用 RAID 0 是提高硬盘速度的有效途径,对机械硬盘和 SSD 来说都是如此。没有必要使用镜像或其它 RAID 变体,因为高可用已经通过 replicas 内建于 Elasticsearch 之中。
- 避免使用网络附加存储(NAS)
II、内存
-
64 GB 内存的机器是非常理想的, 但是32 GB 和16 GB 机器也是很常见的。少于8 GB 会适得其反(你最终需要很多很多的小机器),大于64 GB 的机器也会有问题,GC的时候会增加时间。
-
如果不需要对分词字符串做聚合计算,堆内存越小,Elasticsearch(更快的 GC)和 Lucene(更多的内存用于缓存)的性能越好
-
确保堆内存最小值(
Xms)与最大值(Xmx)的大小是相同的,防止程序在运行时改变堆内存大小, 这是一个很耗系统资源的过程 -
标准的建议是把 50% 的可用内存作为 Elasticsearch 的堆内存,保留剩下的 50%给非堆内存使用
-
即便你有足够的内存,也尽量不要超过 32 GB。因为它浪费了内存,降低了CPU 的性能,还增加了 GC 的时间。
-
查看JVM指针压缩支持的最大值
JAVA_HOME=`/usr/libexec/java_home -v 1.7` java -Xmx32600m -XX:+PrintFlagsFinal 2> /dev/null | grep UseCompressedOops bool UseCompressedOops := true JAVA_HOME=`/usr/libexec/java_home -v 1.7` java -Xmx32766m -XX:+PrintFlagsFinal 2> /dev/null | grep UseCompressedOops bool UseCompressedOops = false调整
-Xmx32600m中的值,来测试内存指针压缩使用的临界值,看系统到底设置多大内存合适。
-
-
避免使用交换分区
III、CPU
- 对CPU要求不高,选择更多的核心的会比主频高的好一点
IV、网络
- 低延时能帮助确保节点间能容易的通讯,大带宽能帮助分片移动和恢复
- 避免集群跨越多个数据中心。绝对要避免集群跨越地域
4、配置elasticsearch
.
├── config
│ ├── elasticsearch.keystore
│ ├── elasticsearch.yml
│ ├── jvm.options
│ ├── jvm.options.d
│ ├── log4j2.properties
│ ├── role_mapping.yml
│ ├── roles.yml
│ ├── users
│ └── users_roles
-
修改jvm.options
配置java虚拟机使用的内存, 正式环境中应:
- Xms 和 Xmx 设置成相同的值;
- Xmx 不要超过机器内存的 50%,并且不要设置超过 30GB。
-Xms256m -Xmx256m -
修改elasticsearch.yml
因为是测试环境,这里没有配置集群。
path.data: /home/app/elasticsearch/data path.logs: /home/app/elasticsearch/logs network.host: 0.0.0.0 http.port: 9200 # 如果不配置下面两行的话,上面指定0.0.0.0的时候会报错 transport.host: localhost transport.tcp.port: 9300 xpack.ml.enabled: false http.cors.enabled: true http.cors.allow-origin: "*"创建启动需要的目录
mkdir -p /home/app/elasticsearch/{data,logs}
5、启动elasticsearch
可以使用 bin/elasticsearch 前台启动
# 加参数可以放到后台运行
-d, --daemonize Starts Elasticsearch in the background
使用systemd管理启动
[Unit]
Description=elasticsearch
After=network.target
After=network-online.target
Wants=network-online.target
Documentation=https://www.elastic.co/
[Service]
# Type=notify
Type=simple
User=els
Group=els
LimitNOFILE=100000
LimitNPROC=100000
WorkingDirectory=/home/app/elasticsearch/
ExecStart=/home/app/elasticsearch/bin/elasticsearch
Restart=no
PrivateTmp=true
#Restart=on-failure
#RestartSec=5
#LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
6、查看状态
# curl localhost:9200
{
"name" : "node-1",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "gWkawGONTtOtT_I6-YqYgA",
"version" : {
"number" : "7.8.0",
"build_flavor" : "default",
"build_type" : "tar",
"build_hash" : "757314695644ea9a1dc2fecd26d1a43856725e65",
"build_date" : "2020-06-14T19:35:50.234439Z",
"build_snapshot" : false,
"lucene_version" : "8.5.1",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
7、配置上的优化建议
A、集群名
cluster.name: elasticsearch_production
B、节点名字
节点启动的时候会随机启动一个名字, 这样不方便管理和识别。
node.name: elasticsearch_005_data
C、数据存储路径
# 注意:你可以通过逗号分隔指定多个目录。
path.data: /path/to/data1,/path/to/data2
path.logs: /path/to/logs
path.plugins: /path/to/plugins
D、最小主节点数
防止集群发生脑裂的情况,使用公式计算最少候选节点个数(master 候选节点个数 / 2) + 1
# 在配置文件中指定
discovery.zen.minimum_master_nodes: 2
# 通过API设置
# 这将成为一个永久的配置,并且无论你配置项里配置的如何,这个将优先生效
PUT /_cluster/settings
{
"persistent" : {
"discovery.zen.minimum_master_nodes" : 2
}
}
E、集群恢复方面的配置
如果不增加配置的情况下,加入集群中有的节点需要短暂停机维护,这时集群中其他节点会发现,数据不再均匀分布,其他节点会立即进行重新分片复制。如果维护节点又重新加入集群,这时,它会发现自己的数据已经在其他节点存在,那就会将本地删除,然后整个集群重新进行平衡。如果数据量大的情况下,来回移动数据,节点会消耗磁盘和网络带宽。
使用下面的配置,缓解上面提到的问题
# 下面配置项不支持动态调整,只能在配置文件或者是在命令行里指定
gateway.recover_after_nodes: 8 # 存在8个及以上节点的时候不进行数据恢复
# 等待 5 分钟,或者10 个节点上线后,才进行数据恢复,这取决于哪个条件先达到。
gateway.expected_nodes: 10
gateway.recover_after_time: 5m
# 这三个设置可以在集群重启的时候避免过多的分片交换。这可能会让数据恢复从数个小时缩短为几秒钟。
F、最好使用单播替换组播
使用单播,你可以为 Elasticsearch 提供一些它应该去尝试连接的节点列表。 当一个节点联系到单播列表中的成员时,它就会得到整个集群所有节点的状态,然后它会联系 master 节点,并加入集群。
如果你使用 master 候选节点作为单播列表,你只要列出三个就可以了。 这个配置在 elasticsearch.yml 文件中:
discovery.zen.ping.unicast.hosts: ["host1", "host2:port"]
8、集群备份
要备份你的集群,你可以使用 snapshot API。这个会拿到你集群里当前的状态和数据然后保存到一个共享仓库里,第一次全量备份,以后增量备份。支持的备份仓库:
- 共享文件系统,比如 NAS
- Amazon S3
- HDFS (Hadoop 分布式文件系统)
- Azure Cloud
A、创建仓库
PUT _snapshot/my_backup
{
"type": "fs",
"settings": {
"location": "/mount/backups/my_backup" ,
"max_snapshot_bytes_per_sec" : "50mb",
"max_restore_bytes_per_sec" : "50mb"
}
}
# 给我们的仓库取一个名字,在本例它叫 my_backup
# 我们指定仓库的类型应该是一个共享文件系统。
# 最后,提供一个已挂载的设备作为目的地址。
# max_snapshot_bytes_per_sec 这个参数控制快照数据进入仓库的限流。默认是每秒 20mb 。
# max_restore_bytes_per_sec 当时,这个参数控制从仓库恢复数据的过程会被限流。默认是每秒 20mb。
# 注意:共享文件系统路径必须确保集群所有节点都可以访问到。
# 新建用PUT,更新用POST
B、快照所有打开的索引
# 备份所有打开的索引到 my_backup 仓库里,并命名快照为 snapshot_1
# 调用会立刻返回,然后快照会在后台运行
PUT _snapshot/my_backup/snapshot_1
# 添加一个 wait_for_completion 会阻塞调用直到快照完成。注意大型快照会花很长时间才返回。
PUT _snapshot/my_backup/snapshot_1?wait_for_completion=true
C、快照指定索引
# 只会备份 index1 和 index2 了
PUT _snapshot/my_backup/snapshot_2
{
"indices": "index_1,index_2"
}
D、查看快照相关的信息
# 获取指定快照信息
GET _snapshot/my_backup/snapshot_2
# 获取所有快照信息
GET _snapshot/my_backup/_all
E、删除快照
DELETE _snapshot/my_backup/snapshot_2
用 API 删除快照很重要,而不能用其他机制(比如手动删除,或者用 S3 上的自动清除工具)。因为快照是增量的,有可能很多快照依赖于过去的段。delete API 知道哪些数据还在被更多近期快照使用,然后会只删除不再被使用的段。
但是,如果你做了一次人工文件删除,你将会面临备份严重损坏的风险,因为你在删除的是可能还在使用中的数据。
F、监控快照进度
# 这个 API 用的是快照机制相同的线程池。如果快照非常大的分片,状态更新的间隔会很大,因为 API 在竞争相同的线程池资源
GET _snapshot/my_backup/snapshot_3
# _status API 立刻返回,然后给出详细的多的统计值输出
GET _snapshot/my_backup/snapshot_3/_status
G、取消一个快照
# 这个会中断快照进程。然后删除仓库里进行到一半的快照。
DELETE _snapshot/my_backup/snapshot_3
9、恢复备份
A、恢复快照
# 默认行为是把这个快照里存有的所有索引都恢复
POST _snapshot/my_backup/snapshot_1/_restore
# 恢复指定索引
POST /_snapshot/my_backup/snapshot_1/_restore
{
"indices": "index_1",
"rename_pattern": "index_(.+)",
"rename_replacement": "restored_index_$1"
}
# 只恢复 index_1 索引,忽略快照中存在的其余索引。
# 查找所提供的模式能匹配上的正在恢复的索引。
# 然后把它们重命名成替代的模式。
# 这个恢复 index_1 到你集群里,但是会重命名成了 restored_index_1 。
restore 命令也会立刻返回,恢复进程会在后台进行。如果你更希望你的 HTTP 调用阻塞直到恢复完成,添加 wait_for_completion 标记
POST _snapshot/my_backup/snapshot_1/_restore?wait_for_completion=true
B、查看恢复进度
这个 API 可以为你在恢复的指定索引单独调用:
GET restored_index_3/_recovery
或者查看你集群里所有索引,可能包括跟你的恢复进程无关的其他分片移动:
GET /_recovery/
C、取消恢复
DELETE /restored_index_3
如果 restored_index_3 正在恢复中,这个删除命令会停止恢复,同时删除所有已经恢复到集群里的数据。
二、kibana
主要功能,从Elasticsearch中获取数据,然后进行分析绘图。
1、配置kibana
config
└── kibana.yml
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.hosts: ["http://localhost:9200"]
elasticsearch.preserveHost: true
kibana.index: ".kibana"
kibana.defaultAppId: "home"
i18n.locale: "zh-CN"
xpack.reporting.encryptionKey: "7ccc4d8b359dcd6b5e8f98a7e8c16c3b"
xpack.security.session.idleTimeout: "1d"
2、启动kibana
-
可以使用
bin/kibana -c config/kibana.yml -
使用systemd管理启动
kabana.service[Unit] Description=kibana After=network.target After=network-online.target Wants=network-online.target Documentation=https://www.elastic.co/kibana [Service] Type=simple User=els Group=els LimitNOFILE=100000 LimitNPROC=100000 WorkingDirectory=/home/app/kibana/ ExecStart=/home/app/kibana/bin/kibana -c /home/app/kibana/config/kibana.yml Restart=no PrivateTmp=true #Restart=on-failure #RestartSec=5 #LimitNOFILE=65536 [Install] WantedBy=multi-user.target
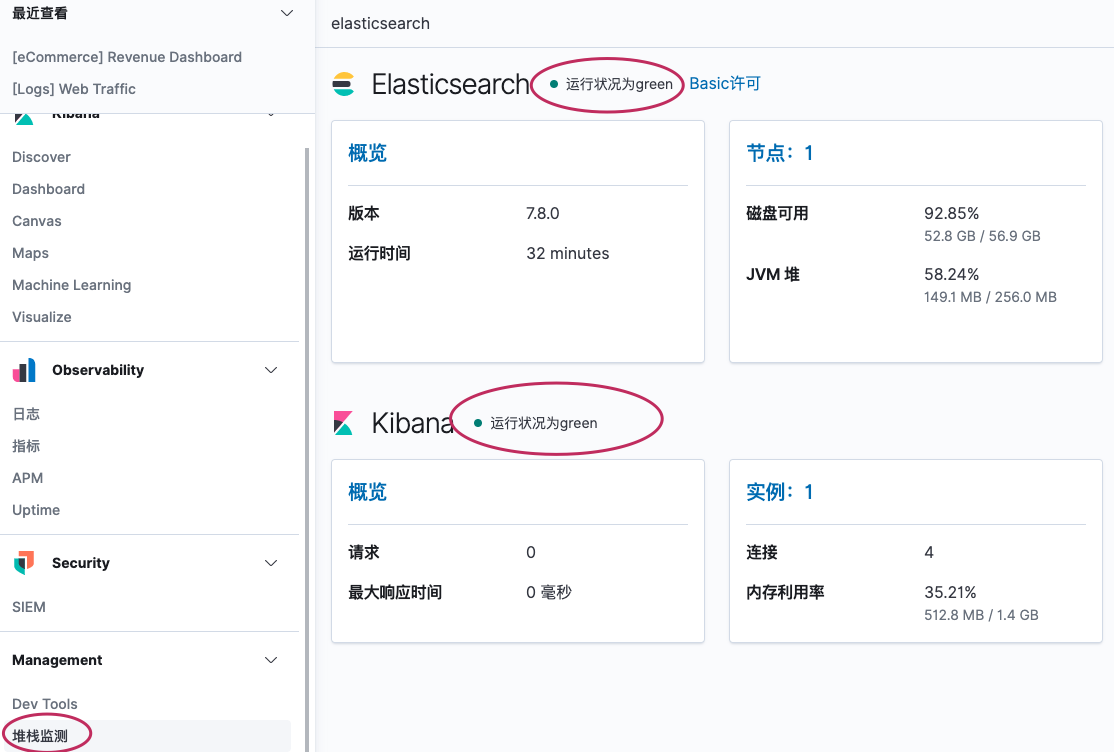
3、查看监控状态
三、Filebeat
主要功能是收集指定位置的数据存储到指定位置
1、配置filebeat
/home/app/filebeat/filebeat.yml
filebeat.inputs:
- type: log
enabled: false
paths:
- /var/log/*.log
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
setup.template.settings:
index.number_of_shards: 1
setup.kibana:
host: "localhost:5601"
output.elasticsearch:
hosts: ["localhost:9200"]
processors:
- add_host_metadata: ~
- add_cloud_metadata: ~
- add_docker_metadata: ~
- add_kubernetes_metadata: ~
logging.level: error
2、启动filebeat
可以使用./filebeat -c filebeat.yml 启动
3、常用的input方式
https://www.elastic.co/guide/en/beats/filebeat/current/configuration-filebeat-options.html
-
log
filebeat.inputs: - type: log enabled: true paths: - /var/log/system.log - /var/log/wifi.log - type: log paths: - "/var/log/apache2/*" fields: apache: true fields_under_root: true - type: log paths: - "/var/log/apache2/*" include_lines: ['sometext'] exclude_lines: ['^DBG'] exclude_files: ['\.gz$']-
常用参数
-
encoding
-
exclude_lines
-
include_lines
-
exclude_files
-
multiline
-
ignore_older
-
json
json.keys_under_root: true json.add_error_key: true json.message_key: log
-
-
4、常用的output
转换输出的格式
output.console:
codec.json:
pretty: true
escape_html: false
output.console:
codec.format:
string: '%{[@timestamp]} %{[message]}'
5、常用处理器
- 添加标签
processors:
- add_fields:
target: project
fields:
name: myproject
id: '574734885120952459'
-
添加tags
如果已经存在,则追加到后面
processors: - add_tags: tags: [web, production] target: "environment" -
转换 Convert
可以对指定字段进行转换
支持的类型包括:
integer,long,float,double,string,boolean, andip.processors: - convert: fields: - {from: "src_ip", to: "source.ip", type: "ip"} - {from: "src_port", to: "source.port", type: "integer"} ignore_missing: true fail_on_error: false-
fields(必须)
这是要转换的字段列表。 列表中至少必须包含一项。 列表中的每个项目都必须具有一个指定源字段的from键。 to键是可选的,它指定在何处分配转换后的值。 如果省略to,那么from字段就地更新。 类型键指定将值转换为的数据类型。 如果省略type,则处理器将复制或重命名该字段,而不进行任何类型转换。
-
ignore_missing(可选)
如果为true,则在事件中未找到from键时,处理器将继续下一个字段。 如果为false,则处理器返回错误,并且不处理其余字段。 默认为false。
-
fail_on_error(可选)
如果值为 false 类型转换失败将被忽略,处理器继续下一个字段。 默认值为“ true”。
-
tag(可选)
标示当前处理器
-
mode
当同时定义了from和to时,mode选项将控制类型转换成功后是copy还是rename该字段。 默认为copy。
-
-
拷贝 filelds
processors: - copy_fields: fields: - from: message to: event.original fail_on_error: false ignore_missing: truefieldsList of
fromandtopairs to copy from and to.fail_on_error可选)如果设置为true,则在发生错误的情况下将还原对事件的更改,并返回原始事件。 如果设置为false,则在发生错误时也将继续处理。 默认为true。
ignore_missing(可选)是否忽略缺少源字段的事件。 默认值为false,如果缺少字段,则将无法处理事件
-
Decode csv fileds
processors: - decode_csv_fields: fields: message: decoded.csv separator: "," ignore_missing: false overwrite_keys: true trim_leading_space: false fail_on_error: true -
decode json fileds
processors: - decode_json_fields: fields: ["field1", "field2", ...] process_array: false max_depth: 1 target: "" overwrite_keys: false add_error_key: true
四、Logstath
1、安装
[elk-7.x]
name=Elastic repository for 7.x packages
baseurl=https://mirrors.tuna.tsinghua.edu.cn/elasticstack/7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
yum install logstash
或者二进制安装,使用openjdk启动的时候报错。使用oracal Java就没报错。
2、配置
https://www.elastic.co/guide/en/logstash/current/plugins-codecs-json.html
# 基本格式
input {
stdin{}
}
filter{
}
output {
stdout{
codec => "rubydebug"
}
}
五、测试收集nginx日志
- 日志格式
# 因为当时配置的时候没有按标准格式来设置。所以需要特殊处理
log_format main '$clientRealIp - $remote_user [$time_local] $request '
'$status $body_bytes_sent $request_time $upstream_response_time $upstream_addr $http_referer '
'$http_user_agent $http_x_forwarded_for ';
- filebeat 完整配置
filebeat.inputs:
- type: log
enabled: true
paths:
- /home/testlog/access/access_log.*
tags: "nginx-access"
fields:
project: nginx-access
logname: nginx-log
fields_under_root: true
processors:
- drop_fields:
fields: ["log","input","host","agent","@metadata","ecs"]
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
reload.period: 10s
setup.template.settings:
index.number_of_shards: 1
index.codec: best_compression
#_source.enabled: false
setup.kibana:
host: "localhost:5601"
output.console:
enabled: false
pretty: true
output.elasticsearch:
enabled: false
hosts: ["localhost:9200"]
indices:
- index: "nmb_log_%{[project]:default}-%{+yyyy.MM.dd}"
when.contains:
project: "nginx-access"
output.redis:
enabled: true
hosts: ["localhost"]
password: ""
timeout: 5
key: "nginx-access"
db: 0
datatype: list
codec.format:
#string: '%{[@timestamp]} %{[message]}'
string: '%{[message]}'
processors:
- add_host_metadata: ~
- add_cloud_metadata: ~
- add_docker_metadata: ~
- add_kubernetes_metadata: ~
logging.level: info
logging.files:
path: ${path.config}/logs
name: filebeat.log
keepfiles: 7
permissions: 0644
monitoring.enabled: false
logging.metrics.enabled: false
setup.template.name: "nmb_log"
setup.template.pattern: "nmb_log*"
setup.template.enabled: true
setup.template.overwrite: true
setup.ilm.enabled: false
setup.ilm.overwrite: false
- logstash配置
input {
redis {
id => "nginx_access_redis"
data_type => "list"
key => "nginx-access"
host => "127.0.0.1"
port => 6379
db => 0
threads => 5
type => "nginxlog"
}
# stdin{ type => "nginxlog"}
}
#
filter{
if [type] == "nginxlog" {
grok {
patterns_dir => ["./patterns"]
match => {
"message" => "%{IP:clientip} %{NGUSER:ident} %{NGUSER:auth} \[%{HTTPDATE:logdate}\] %{WORD:match} %{URIPATHPARAM:request} HTTP/%{NUMBER:httpversion} %{NUMBER:status:int} (?:%{NUMBER:bytes}|-) (?:%{NUMBER}|-) (?:%{NUMBER}|-) %{HOSTPORT:proxyserv} (?:(%{URI:referrer}|-|%{QS:referrer})) %{ALL:agent}"
}
overwrite => [ "message" ]
}
# 用日志中的时间替换采集时间
date{
match=>["logdate","dd/MMM/yyyy:HH:mm:ss Z"]
target => "@timestamp"
}
geoip {
database => "/home/app/logstash/config/geoip/GeoLite2-City.mmdb"
source => 'clientip'
fields => ["country_name", "city_name", "location"]
# remove_field => ["[geoip][latitude]", "[geoip][longitude]"
}
#有无法解析的地址就删除
if "_geoip_lookup_failure" in [tags] { drop { } }
mutate {
#convert => [ "[geoip][coordinates]", "float"]
#convert => [ "status","integer" ]
#convert => [ "bytes","integer" ]
remove_field => [ "host","tags","ident","@version","auth","proxyserv","logdate","message"]
}
}
}
output{
elasticsearch {
hosts => "127.0.0.1:9200"
index => "logstash-%{type}-%{+YYYY.MM.dd}"
template_overwrite => true
}
## stdout{
## codec => "rubydebug"
## }
}
patterns/nginxlog
NGUSERNAME [a-zA-Z\.\@\-\+_%]+
NGUSER %{NGUSERNAME}
HTTPDATE %{MONTHDAY}/%{MONTH}/%{YEAR}:%{TIME} %{INT}
URI %{URIPROTO}://?(?:%{URIHOST})?(?:%{URIPATHPARAM})?
ALL .*
先启动filebeat将日志文件存储到redis,然后启动logstash消费日志。
-
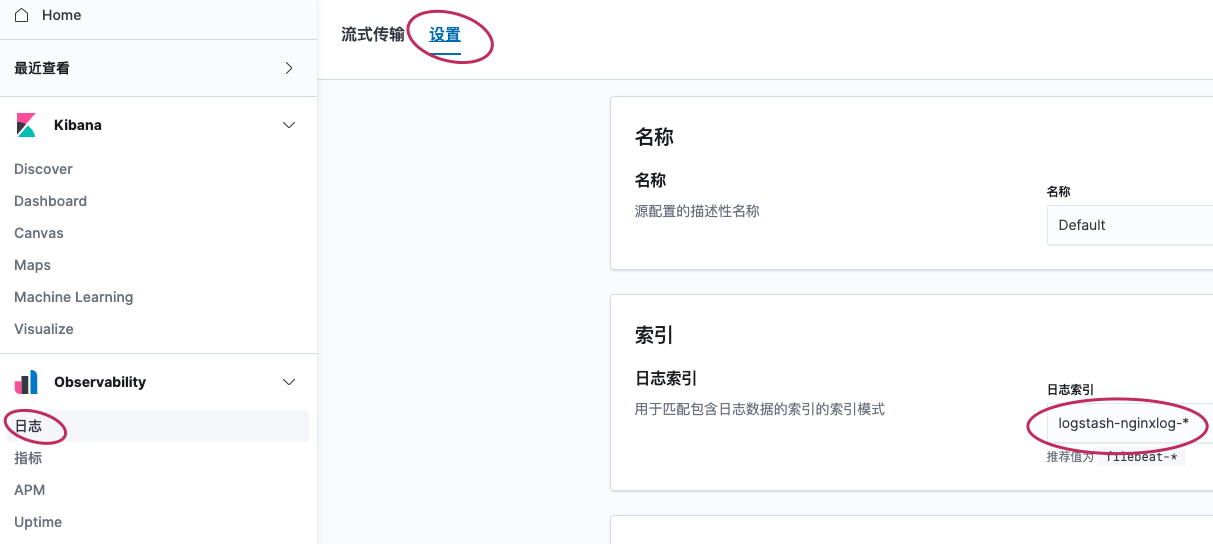
kibana中查看
- 设置

六、metricbeat组件
metricbeat是一个收集系统指标的软件,可以将数据放入elasticsearch中,同时导入kibana图表
1、修改配置文件
metricbeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
setup.template.settings:
index.number_of_shards: 1
index.codec: best_compression
setup.kibana:
host: "localhost:5601"
output.elasticsearch:
hosts: ["localhost:9200"]
indices:
- index: "metricbeat-7.8.0-%{+yyyy.MM.dd}"
setup.ilm.enabled: false
processors:
- add_host_metadata: ~
- add_cloud_metadata: ~
- add_docker_metadata: ~
- add_kubernetes_metadata: ~
logging.level: error
logging.files:
path: ${path.config}/logs/metricbeat
name: metricbeat
keepfiles: 7
permissions: 0644
2、启动
-
导入kibana图表(可选)
metricbeat -e setup -
启动
``metricbeat -c metricbeat.yml`
配置systemd管理 metricbeat.service
[Unit] Description=metricbeat service After=network.target After=network-online.target Wants=network-online.target [Service] Type=simple WorkingDirectory=/home/app/metricbeat ExecStart=/home/app/metricbeat/metricbeat -c /home/app/metricbeat/metricbeat.yml Restart=on-failure [Install] WantedBy=multi-user.target RequiredBy=docker.service
七、grafana绘图
grafana是一款功能非常强大也是最常用的监控展示框架。可以读取多种源来绘制图形。
1、读取上面Elasticsearch中的监控数据
------------------------------------------------
自信来源于充分的准备和对规则的理解
1、不要总问别人为什么,要问自己凭什么
2、做任何事的时候要仔细,给别人意见的时候能让别人一目了然,可以快速的给出意见及结果。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号