
基于pytorch实现的手写数字识别
这两天一直在学pytorch和CNN,用LeNet-5和MNIST练练手,我魔改了很多也有比LeNet-5结果更好一点的,不过还是觉得经典永流传~
闲话不多说,LeNet-5结构如下:
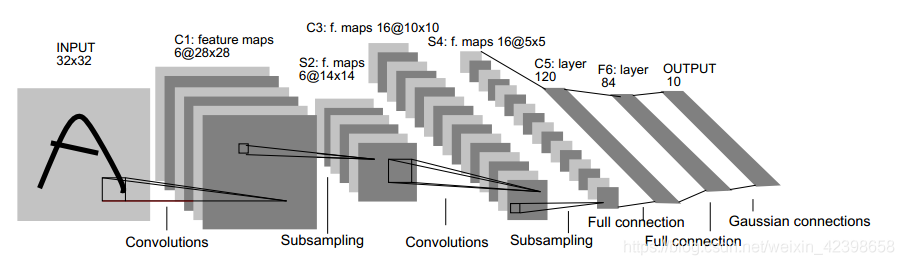
网络结构图里都给的很清晰了,注意S4卷积之后到C5这里,其实是一个卷积操作,用的是120个5*5的卷积核来得到120层,之后才能拉伸再接全连接层,我在这里卡了很久想不通为什么直接拉伸会报错,只能说还是太嫩了。
简单说一下为什么要用卷积而不是直接全连接层:主要还是为了减少参数的个数,卷积有一个好处是参数共享,也就是说,无论上一层有多复杂,到这一层都是共用这5*5个参数,有效减少参数量,加快训练速度。池化在我的理解中一是为了进一步减少参数,二是提取2*2大小里一个主要的特征,增强了所谓的平移不变性(就是希望图像稍微移动也不影响)。
代码如下:
1.导入所需要的库/包,成为一个合格的调参侠的第一步
1 #1.导入库 2 import numpy as np 3 import torch 4 import torch.nn as nn 5 import torch.nn.functional as F 6 import torch.optim as optim 7 from torchvision import datasets,transforms
2.定义一些超参和图像预处理的方法
#2.定义超参和pipeline
Batch_size=4096 #根据自己情况来,我这里是6GB显存
Epoch=50 #迭代次数
#选择是用GPU还是CPU,我这里的cuda已经配置好了所以用了GPU
Device=torch.device("cuda" if torch.cuda.is_available() else "cpu")
#pipeline用来预处理图像
pipeline=transforms.Compose([
transforms.ToTensor(), #转化成人见人爱的tensor
transforms.Normalize((0.1307,),(0.3081,)) #归一化处理加快训练速度,两个数字分别是均值和标准差,由官方文档给出
])
3.下载数据集并分别加载训练集和测试集
这里用的是torch的MNIST,大概有60000张图片用来训练,10000张图片用来测试,值得一提的是每张灰度图图片大小都是28*28*1
from torch.utils.data import DataLoader train_set=datasets.MNIST("data",train=True,download=True,transform=pipeline) test_set=datasets.MNIST("data",train=False,download=True,transform=pipeline) train_loader=DataLoader(train_set,batch_size=Batch_size,shuffle=True) #shuffle是选择是否随机打乱 test_loader=DataLoader(test_set,batch_size=Batch_size,shuffle=True)
运行下面这几行可以查看一下其中的一张图片
#可以先看一下图像 with open("./data/MNIST/raw/t10k-images-idx3-ubyte","rb") as f: file=f.read() image1=[int(str(item).encode("ascii"),16)for item in file[16:16+784]] #这是官方文档给的格式,16开始到16+28*28*1是第一张图像 #print(image1) #全是一堆灰度值,没什么意思 #import cv2 image1_np=np.array(image1,dtype=np.uint8).reshape(28,28,1) #cv2.imwrite("1.jpg",image1_np) #会在文件夹里生成一个图片,没什么影响 import matplotlib.pyplot as plt #不得不说还是plt好用,我先用了PIL难写死了,cv2的话会跳出来一个新的窗口,不够帅我不喜欢 #import matplotlib.image as mping plt.imshow(image1_np)
4.定义模型。
这里有一个问题,MNIST的图片是28*28*1,而LeNet-5一开始的输入为32*32*1,所以我干脆加了两层padding让他第一次卷积之后大小和LeNet-5一致,也算是偷个懒吧
#4.定义模型 class Digit(nn.Module): def __init__(self): super().__init__() self.conv1=nn.Conv2d(1,6,5,padding=2) #灰度图片的通道1,输出通道10,卷积核大小5 self.conv2=nn.Conv2d(6,16,5) #出现奇怪的问题哈哈哈,因为MNIST图像大小为28*28*1,原本的LeNet-5是32*32*1 self.conv3=nn.Conv2d(16,120,5) #所以在conv1这里加了padding模拟一下 self.fc1=nn.Linear(120,84) #全连接层,输入通道120,输出通道84 self.fc2=nn.Linear(84,10) def forward(self,x): input_size=x.size(0) #x的格式是batch_size*1*28*28 x=self.conv1(x) #卷积层 x=F.relu(x) #激活函数relu,不要用sigmoid很慢 x=F.max_pool2d(x,2,2) #最大池化2*2 x=self.conv2(x) x=F.relu(x) x=F.max_pool2d(x,2,2) x=self.conv3(x) x=F.relu(x) x=x.view(input_size,-1) #拉伸成一个长条~ x=self.fc1(x) #全连接层输入b_s*120,输出b_s*84 x=F.relu(x) x=self.fc2(x) #输入b_x*84,输出b_s*10 output=F.softmax(x,dim=1) #计算分类概率 return output
5.定义优化方法
我这边是直接用了别人建议的Adam
#5.定义优化方法,就用Adam model=Digit().to(Device) optimizer=optim.Adam(model.parameters())
6.定义训练方法
#6.定义训练方法 def train_model(model,Device,train_loader,optimizer,epoch): #模型训练 model.train() for batch_index,(data,label) in enumerate(train_loader): data,label=data.to(Device),label.to(Device) #梯度初始化为0,每次迭代之前一定要初始化,否则会一直累计之前的梯度,这里卡了我很久吃了大亏 optimizer.zero_grad() output=model(data) loss=F.cross_entropy(output,label) #pred=output.max(1,keepdim=True)[1] #找到最大概率对应的下标,这个在测试环节再加上就行了 loss.backward() optimizer.step() if batch_index %3000 ==0: print("Train Epoch:{}\t Loss : {:6f}".format(epoch,loss.item()))
7。定义测试方法
#7.定义测试方法 def test_model(model,device,test_loader): model.eval() acc=0.0 test_loss=0.0 with torch.no_grad(): for data,label in test_loader: data,label=data.to(device),label.to(device) output=model(data) test_loss += F.cross_entropy(output,label).item() pred= output.max(1,keepdim=True)[1] acc+=pred.eq(label.view_as(pred)).sum().item() #学艺不精了,这行抄网上的,我试了几次都和预期的有很大差别 test_loss/=len(test_loader.dataset) print("Test Loss :{:4f},Acc : {:3f}\n".format(test_loss,100.0*acc/len(test_loader.dataset)) )
8.调用,跑模型,测试
#8.调用开始跑 for epoch in range(1,1+Epoch): train_model(model,Device,train_loader,optimizer,epoch) test_model(model,Device,test_loader)
9.这里其实应该再加一个画图环节,但我画图用的不太熟练,下次一定hhh。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号