第二周作业
一 .总结学过的文本处理工具,文件查找工具,文本处理三剑客, 文本格式化命令(printf)的相关命令及选项,示例。
文本处理工具
nano工具
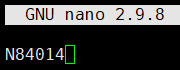
示例:在f1.txt文件中写入N84014保存退出


(Ctrl+X退出)

(yes:保存,no:不保存)
vim工具
选项:
+#:打开文件后,让光标处于第#行的行首
+/PATTERN:让光标处于第一个被PATTERN匹配的行行首
-b file:二进制方式打开文件
-d file1 file2:比较多个文件
-m file:只读打开文件
示例:打开f1.txt文件时光标处于第6行
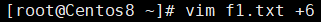
示例:打开f1.txt文件光标处于以s开头行行首

示例:以只读方式打开f1.txt文件
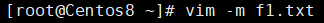
扩展命令模式基本命令
w:保存
q:退出
wq:保存退出
q!:不保存退出
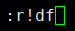
r filename:读取文件内容到当前文件
w filename:写入当前文件内容到文件
!command:执行命令
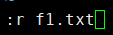
示例:读取f1.txt文件内容到f2.txt文件中
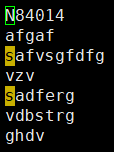
示例:将f1.txt文件的第3-5行内容写入到f3.txt文件中
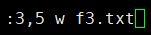
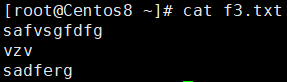
示例:将df命令的结果写入到f3.txt文件中
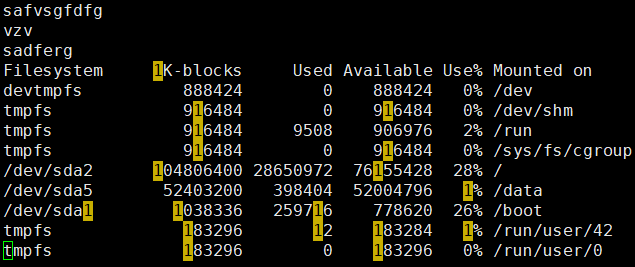
地址定界
#:具体第#行
#,N:第#行到第N行
#,+N:第#行到第#+N行
.:当前行
$:最后一行
%:全文
选项:
d:删除
y:复制
p:粘贴
w filename:将匹配的行写入到文件中
r filename:在匹配的行插入读取文件
示例:匹配f1.txt的第1-3行删除
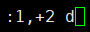
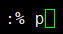
示例:匹配f2.txt的全文复制
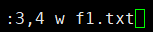
示例:匹配f3.txt的第3-4行写入到f1.txt文件
查找替换
查找替换的分隔符可以为/,#,@
修饰符:
i:忽略大小写
g:全局替换,默认每行只替换第一次
示例:将f1.txt文件的abc替换为123
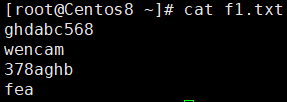

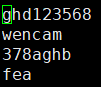
撤销更改
u:撤销上次更改
#u:撤销之前多次更改
可视化模式
v:面向字符
V:面向整行
Ctrl+v:面向块
文件查找工具
locate工具
locate查询系统上预建立的文件数据库/var/lib/mlocate/mlocate.db,文件数据库在系统空闲时自动进行加载,也可以手动使用updatedb命令进行更新
工作特点
查找速度快,非实时查找,根据文件名查找
选项
-i:不区分大小写
-n #:只匹配前#项
-r:使用正则表达式
示例:搜索以不区分大小的.conf结尾的文件,并且只匹配前5项

find工具
实时查找工具,通过指定路径完成查找
工作特点:
查找速度慢,精确实时查找,只搜索用户具备读取和执行权限的目录
格式:find 【选项】 【查找路径】 【查找条件】 【处理动作】
指定搜索目录层级:
-maxdepth:最大搜索目录深度
-mindepth:最小搜索目录深度
示例:搜索/var目录下最小2级,最大2级的文件
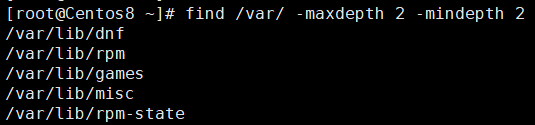
根据文件名查找
-name ’filename‘:支持通配符
-iname ’filename‘:不区分大小写
示例:在/etc目录下查找任意字符+a或b+任意单个字符的文件
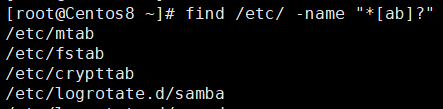
根据属主,属主查找
-user:查找属主
-group:查找属组
-uid:查找属主的uid
-gid:查找属组的gid
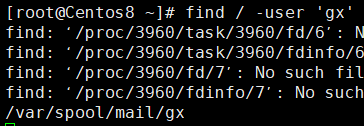
示例:查找属主为gx的文件
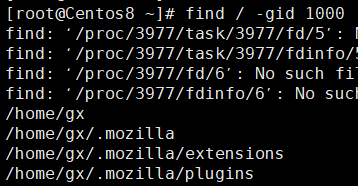
示例:查找属组的gid为1000的文件
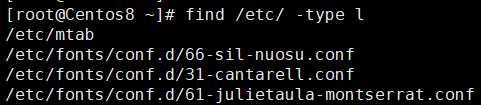
根据文件类型查找
-type f/d/l/b/c/p/s
示例:查找/etc目录下的所有连接文件
根据文件大小查找
-size XX:表示大小为(XX-1,XX]
-size -XX:表示大小为(0,XX)
-size +XX:表示大小为(XX,∞)
示例:在/etc目录下查找文件大小为2-3M的文件

示例:在/var目录下查找文件大小为小于4M的文件

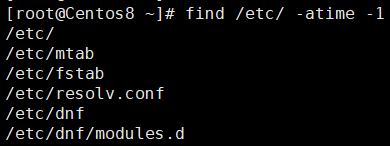
根据时间查找
-atime XX:表示时间为[XX,XX+1)
-atime -XX:表示时间为[0,XX)
-atime +XX:表示时间为[XX+1,∞)
示例:在/etc目录下查找明天到今天的所有文件
根据权限查找
-perm [/|-]XX
XX:表示精确查找
/XX:表示u,g,o任意一类对象的权限中只要有一位能匹配即可
-XX:表示每一类对象的权限都匹配
0:表示不关系该对象
示例:在/var目录下查找权限为600的文件

示例:在/data目录下查找属主权限为可读或可写的文件

示例:在/data目录下查找属主权限为可读,属组权限为可写的文件

处理动作
-print:默认动作,显示至屏幕
-ls:对搜索到的文件执行ll命令
-fls filename:对搜索到的文件信息保存到文件中
-delete:删除搜索到的文件
-ok command {} \;:对搜索到的文件执行该命令,需要交互确认
-exec command {} \;:对搜索到的文件执行该命令,无需交互确认
示例:删除/etc目录下大小为4-5M的文件

示例:搜索/etc目录下以.txt结尾文件的详细信息
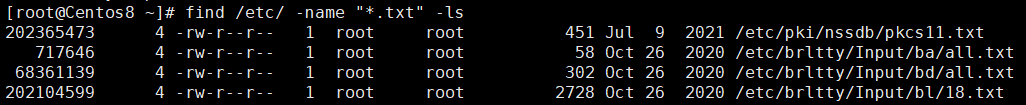
示例:删除/data目录下以.txt结尾的文件

文本处理三剑客之grep
grep用于文本搜索,根据指定的目标对文本进行检测,并输出匹配行
选项:
-m#:匹配#次后停止
-v:显示没有被匹配的行
-i:忽略大小写
-n:显示匹配的行号
-o:仅显示匹配的字符串
-q:静默模式
-A X:显示后X行
-B X:显示前X行
-C X:显示前后X行
-e:多个匹配条件的或关系
-w:匹配整个单词
-E:扩展正则表达式
-r:递归
示例:匹配passwd文件中的root3次,并显示行号

示例:匹配passwd文件中的BAsh,并忽略大小写

示例:匹配passwd文件并仅显示匹配的ro字符
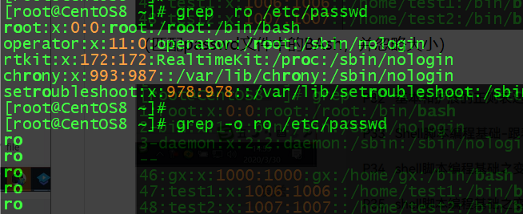
示例:过滤空行或以#开头的行
文本处理三剑客之sed
sed是从文件中读取一行,处理一行,输出一行,再读取处理输出不断重复
格式:sed 【选项】 ’script1;script2;...‘ filename
sed默认会自动打印文件内容
选项:
-n:关闭自动打印
-e:或
-E/r:扩展正则表达式
-i.XX:备份文件并再原处编辑
地址格式:
没有地址,默认对全文处理
单地址:X(指定行),$(最后一行),/正则表达式/
地址范围:
X,N:从X行到N行
X,+N:从X行到X+N行
/正则表达式/,/正则表达式/:从匹配的行到匹配的行
命令格式:
p:打印当前模式空间内容
lp:忽略大小写输出
d:删除模式空间内容
a\text:在指定行后追加文本
i\text:在指定行前插入文本
c\text:替换指定行内容
w filename:写入匹配行到指定文件
r filename:读取指定文件内容到匹配行后
!:匹配行去反
s///:查找替换匹配字符
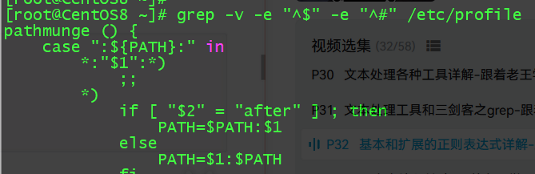
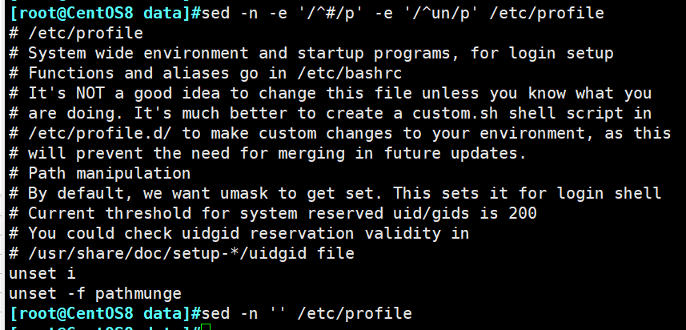
示例:只打印profile文件中以#开头以及un开头的行
示例:打印f1.txt文件的2,3行,并在2,3行后追加gx内容
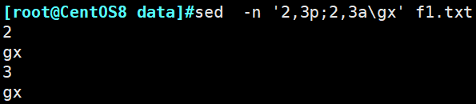
示例:将f1.txt文件中第4至6行外的其他行替换内容
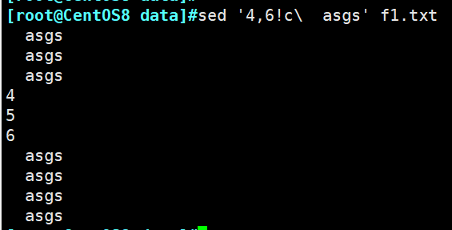
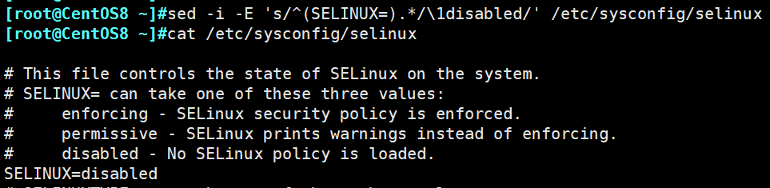
示例:查找selinux文件中以SELINUX开头的行,并将后面的内容修改为disabled
文本格式化工具
printf工具
%s:字符串
%f:浮点格式
%c:ASCII字符
%d:十进制整数
%o:八进制
%x:十六进制
示例:以浮点型显示并换行

示例:每个字符串加括号,并且每行显示两个字符

示例:以右对齐,宽度为5格式显示字符串

二. 总结文本处理的grep命令相关的基本正则和扩展正则表达式。
基本正则表达式
字符匹配
.:匹配任意单个字符
[]:匹配指定范围内任意单个字符
[^]:匹配指定范围外任意单个字符
[:alnum:]:匹配字母和数字
[:alpha:]:匹配任意字母
[:lower:]:匹配小写字母
[:upper:]:匹配大写字母
匹配次数
用于指定前面的字符出现的次数
*:匹配前面字符任意次,包括0次,贪婪模式:尽可能长的匹配
.*:匹配任意长度任意字符
\?:匹配前面字符0或1次
\+:匹配前面字符至少1次
\{n\}:匹配前面字符n次
\{n,m\}:匹配前面字符n到m次
\{n,\}:匹配前面字符至少n次
\{,n\}:匹配前面字符至多n次
位置锚定
用于定位出现的位置
^:锚定行首
$:锚定行尾
^PATTERN$:匹配整行
^$:空行
\<:锚定词首
\>:锚定词尾
分组其他
用()将多个字符绑定在一起,当作一个整体处理,分组括号内匹配到的内容会被正则表达式记录到变量中,这些变量的命名方式为\1,\2...。\|表示或者
扩展正则表达式
与基本正则表达式一致,只是少了\更加直观
注意:匹配词首和词尾时,扩展正则表达式依然需要加\
三. 总结变量命名规则,不同类型变量(环境变量,位置变量,只读变量,局部变量,状态变量)如何使用。
变量命名规则
不能使用程序中的保留字,if,else,for,while等
只能使用数字、字符及下划线,且不能以数字开头,不支持短横线
见名知义,用英文单词命名,不要用简写
统一命名规则,驼峰命名法filename,大驼峰FileName,小驼峰fileName
变量名大写
局部变量小写
函数名小写
环境变量
使子进程继承父进程的变量,但是无法让父进程使用子进程的变量
一旦子进程修改从父进程继承的变量,将会以新的值传递给孙子进程
一般在系统配置文件中使用,脚本中较少使用
声明并赋值:export name=value
位置变量
bash shell中内置的变量,在脚本代码中调用通过命令行传递给脚本的参数
$1,$2,...:对应第一个,第二个参数
$0:命令本身
$*:传递给脚本所有参数,全部参数合为一个字符串
$@:传递给脚本所有参数,每个参数为独立字符串
$#:传递给脚本参数的个数
只读变量
只能声明定义,后续不能修改和删除
readonly name=value
局部变量
用于shell进程中某个代码片段,通常指函数
状态变量
状态变量$?会记录上一次命令的执行结果,$?的值为0表示执行成功,值为1-255表示执行失败
用户可以在脚本中自行定义退出状态码,一般用来定义不同的错误原因
exit XX,脚本一旦遇到exit命令,会立即停止,退出状态码为exit后设置的数值
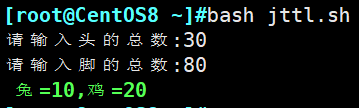
四. 通过shell编程完成,30鸡和兔的头,80鸡和兔的脚,分别有几只鸡,几只兔?

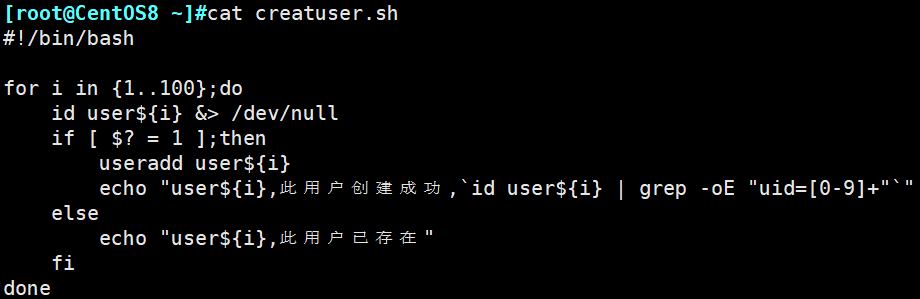
五. 结合编程的for循环,条件测试,条件组合,完成批量创建100个用户,
1)for遍历1..100
2)先id判断是否存在
3)用户存在则说明存在,用户不存在则添加用户并说明已添加。
六. 磁盘存储术语总结: head, track, sector, sylinder.
head
磁头,一个盘面对应一个磁头
track
磁道,盘面上的每一圈就是一个磁道
sector
扇区,把每个磁道按512字节大小再进行划分,每一部分就是一个扇区,每个磁道上的扇区数量是不一致的
cylinder
磁头移动的时候,是一起移动的,所有磁道组合而成的就是柱面
七. 总结MBR,GPT结构。
MBR
MBR分区中一块硬盘最多有4个主分区,也可以是3个主分区+1个逻辑分区,每个分区不超过2T
0磁道0扇区总共512字节,前446字节用于存放启动引导程序,64字节为分区表,每16字节标识一个分区,2字节的标识位.
GPT
GPT分区支持128个分区,使用128位UUID表示磁盘和分区,GPT分区表自动备份在头和尾两份,并有CRC校验位
GPT分区结构为4个区域:GPT头,分区表,GPT分区,备份区域
八. 总结学过的分区,文件系统管理,SWAP管理相关的命令及选项,示例
fdisk, parted, mkfs, tune2fs, xfs_info, fsck, mount, umount, swapon, swapoff
fdisk
用于管理MBR分区
常用选项:
-b:指定扇区大小
-l:显示分区
-t:只显示指定类型的分区
常用子命令:
p:打印分区表
n:创建新分区
d:删除分区
t:更改分区类型
w:保存退出
q:不保存退出
示例:创建新分区,保存退出
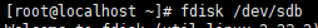

示例:修改分区3的分区类型为swap分区
parted
常用选项:
-l:显示分区信息
常用子命令:
mktable:指定分区类型
mkpart:新建分区
rm:删除人去
name:重命名分区,只有gpt分区支持
resizepart:重置分区大小,只能修改结束位置,不能修改其实位置
print:打印分区信息
示例:设置/dev/sdb分区类型为MBR分区

示例:创建新分区
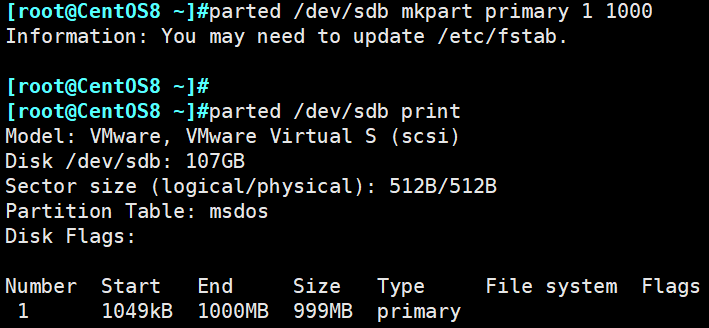
示例:删除/dev/sdb的分区3

示例:修改分区1的大小,结束位置为1050M
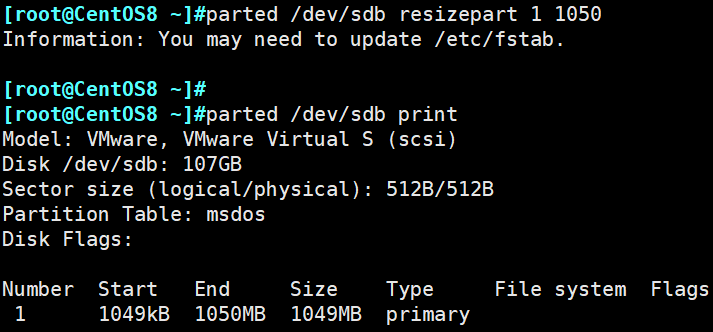
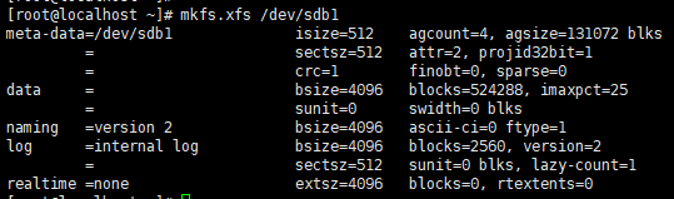
mkfs
用于创建文件系统
选项:
-t:指定文件类型
-b:指定块大小
-L:指定卷标
-m:指定为管理员预留空间百分比
示例:创建sdb1分区的文件系统为xfs
tune2fs
用于修改ext系列文件系统可调整参数的值
选项:
-l:查看指定文件系统信息
-L:修改卷标
-m:修改预留空间百分比
-U:修改UUID
示例:修改sdb1文件系统的预留空间百分比为10%

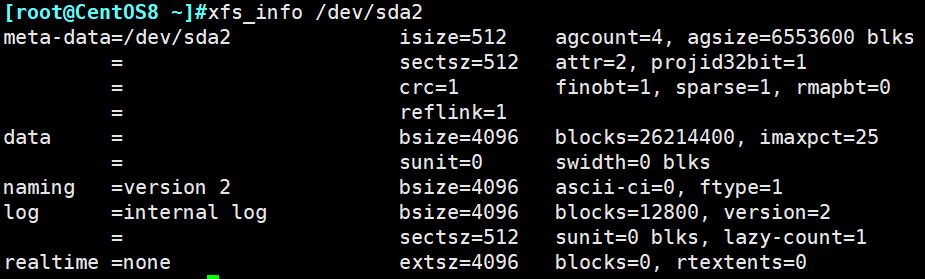
xfs_info
用于显示已挂载xfs文件系统信息
示例:查看sda2文件系统信息
fsck
用于修复设备的文件系统
选项
-t:修复文件系统类型
-a:自动修复
-r:交互式修复
示例:修复sdb1分区的ext4文件系统

mount
用于挂载设备
选项:
-a:自动挂载fstab中所有支持自动挂载的设备
-r:以只读方式挂载
-w:以读写方式挂载
-o:挂载选项列表
-o选项:
remount:重新挂载
ro/rw:只读/读写
示例:将sdb1挂载到/test1目录
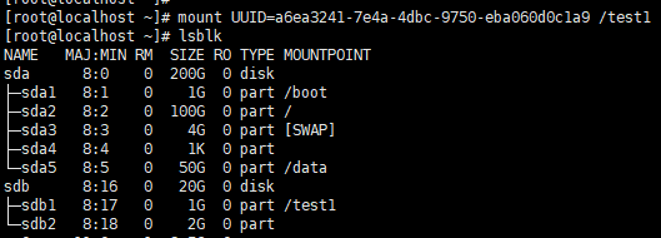
示例:以只读方式挂载sdb1到/test目录

umount
用于取消挂载
示例:取消挂载点/test1
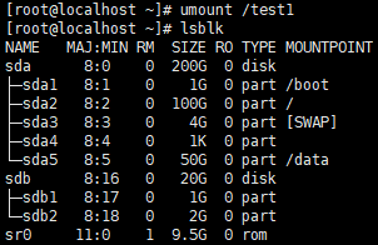
swapon
用于启用swap分区
选项
-a:启用fstab中所有swap分区
-d:根据条件禁用
-p:指定swap的优先级,值越大越优先
-s:查看使用的swap分区的摘要信息
-v:查看swap详细信息
示例:启用所有swap分区,查看当前使用swap的摘要信息

示例:修改sdb2的swap优先级为10

swapoff
用于禁用swap分区
选项
-a:禁用fstab中所有swap分区
示例:禁用sdb2设备的swap

 浙公网安备 33010602011771号
浙公网安备 33010602011771号