

python(31)——【sys模块】【json模块 & pickle模块】
一、sys模块
import sys sys.argv #命令行参数List,第一个元素是程序本身路径 sys.exit() #退出程序,正常退出时exit(0) sys.version #获取python解释程序的版本信息 sys.maxint #最大的int值 sys.path #返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 sys.platform #返回操作系统平台的名称
1. sys.argv (非常重要)
应用:我们之前需要做判断是在程序执行过程中进行逻辑判断和选择。如果需求是在程序还没有执行时,对用户操作进行判断,即直接对程序进行操作和选择
sys_module.py内容如下:
import sys print(sys.argv)
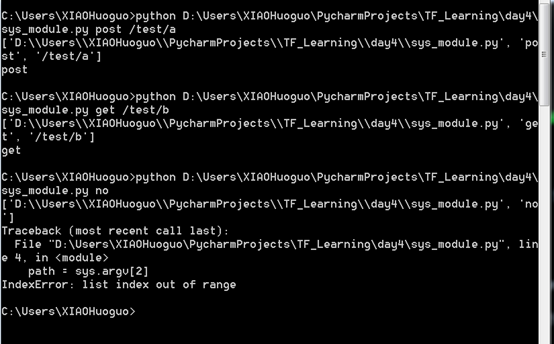
在终端来执行sys_module.py,命令行后可添加参数(第一个参数为用户要执行的操作,第二个参数为路径),执行结果如下:

sys.arge提供了一个在命令行后面添加参数的机制,通过对相关参数进行解析,可对用户操作在程序执行前进行判断。
sys_module.py内容如下:
import sys print(sys.argv) command = sys.argv[1] path = sys.argv[2] if command == 'post': print('post') elif command == 'get': print('get')
#终端执行结果如下:
2. 关于环境变量的问题
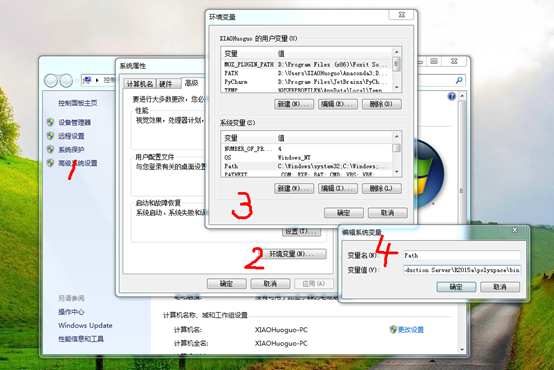
关于环境变量的修改
#临时修改环境变量方法
import sys sys.path.append()
#永久修改环境变量方法(如下图所示)
关于from...import...的补充
cal.py的内容如下:
A = 5.20
if __name__=='__main__':
def add_cal(x,y):
return x + y + A
TEST.py的内容如下:
from cal import A
if __name__=='__main__':
print(A)
TEST.py和cal.py的关系如下图所示:
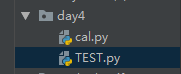
执行TEST.py结果如下:5.2
TEST.py和cal.py的关系如下图所示:
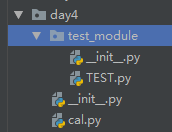
执行TEST.py结果报错,因此需要在TEST.py中人为的添加绝对路径
__file__ == 文件名(但是在pycharm会自动加入绝对路径)
思路一:利用sys.path.append()直接进行绝对路径的添加
import sys sys.path.append('D:/Users/XIAOHuoguo/PycharmProjects/TF_Learning/day4') from cal import A if __name__=='__main__': print(A)
#结果分析:虽然程序可以正常执行,但是程序可移植性较差
思路二:利用os.path.dirname(path) #返回path的目录,其实就是os.path.split(path)的第一个元素
import sys import os BASE_DIR = os.path.dirname(os.path.dirname(__file__)) sys.path.append(BASE_DIR) from cal import A if __name__=='__main__': print(A)
#结果分析:虽然程序可以正常执行,但是__file__==文件名,只是pycharm自动添加绝对路径,因此该程序无法再终端执行,会报错
思路三:通过sys.path.abspath()来获取绝对路径
import sys import os BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) sys.path.append(BASE_DIR) from cal import A if __name__ == '__main__': print(A)
#结果分析:程序可以再pycharm和终端正常执行,且可移植性能较好
3. 进度条的实现
import sys import time for i in range(50): sys.stdout.write('*') #向屏幕打印操作,print的内部就是sys.stdout.write()操作 time.sleep(0.1) sys.stdout.flush() #动态刷新(不添加该语句,则直接全部打印)
二、 json模块 & pickle模块
1. json
- 如果我们要在不同编程语言之间传递对象,就必须把对象序列化为标准格式,比如XML,但更好的方法是序列化为JSON,
- 因为JSON表示出来就是一个字符串,可以被所有语言读取,也方便地存储到磁盘或者通过网络传输
- JSON不仅是标准格式,并且比XML更快,而且可以直接在web页面中读取,非常方便
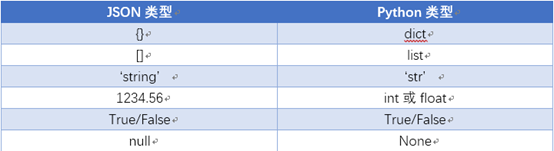
2. JSON表示的对象就是标准的JavaScript语言的对象,JSON和Python内置的数据类型对应如下:
3. 序列化
- 我们把对象(变量)从内存中变成可存储或传输的过程称之为序列化。在Python中叫pickling,在其他语言中被称之为serialization,marshalling等,都是一个意思
- 序列化之后,就可以把序列化后的内容写入磁盘,或者通过网络传输到别的机器上
- 反过来,把变量内容从序列化的对象重新读到内存里称之为反序列化,即unpickling。
回顾:通过eval()实现数据交换
#对文件进行写操作(只能写入字符串类型) dic = '{"name": "xhg"}' f = open('hello', 'w') f.write(dic) f.close()
#对文件进行读操作(读初字典name键对应的值xhg) f_read = open('hello', 'r') data = f_read.read() print(type(data)) data = eval(data) print(data["name"]) f_read.close() #执行结果: <class 'str'> xhg #结果分析:对文件进行读操作,读出的数据类型为字符串,通过eval()对数据处理,将字符串转换为字典,再进行键值对处理。
上述过程可以通过json模块和pickle模块来进行实现
#利用json进行写操作(序列化) import json dic = {'name': 'xhg'} data = json.dumps(dic) print(data) print(type(data)) #执行结果: {"name": "xhg"} <class 'str'> #结果分析:data是json字符串,是所有语言都支持的规范 .json字符串最明显的特征是:各种引号变为双引号。json.dumps()之后,所有数据类型均转化为json字符串(加载成字符串) #json字符串最明显的特征是:各种引号变为双引号。 dic = {'name': 'alex'} ----> {"name": "alex"} i = 8 ----> "8" s = 'hello' ----> "hello" l = [11, 22] ----> "[11, 22]"
#利用json模块对文件进行写操作(序列化) import json dic = {'name': 'xxx'} print(type(dic)) #<class 'dict'> data = json.dumps(dic) print(type(data)) #<class 'str'> f = open('hello','w') f.write(data) f.close()
#利用json模块对文件进行读操作(读初字典name键对应的值xhg)(反序列化) import json f_read = open('hello', 'r') data = json.loads(f_read.read()) print(type(data)) print(data) print(data['name']) f_read.close() #执行结果: <class 'dict'> {'name': 'xxx'} xxx #结果分析:json.loads()读出来的数据是最初的数据类型
4. dump & dumps load & loads 区别
#dumps() import json dic = {'name': 'xhg'} f = open('hello','w') data = json.dumps(dic) f.write(data) f.close() #dump() import json dic = {'name': 'xxx'} f = open('hello','w') json.dump(dic, f) f.close()
#结论:
#dump() <----> json.dumps();f.write()
#dump()相当于进行了两步操作,load & loads区别同dump & dumps区别,建议使用dumps()和loads()
#提示:并不是只有dumps()之后可以才可以使用loads(),只要你写入的字符串符合json字符串的规定(双引号),就可以使用loads()
5.pickle模块
- pickle模块也是用来做数据交换的,与json模块的区别如下:
- pickle结果是字节,json结果是字符串
- json写进去是可读的(字符串),pickle写进去是不可读的(字节)
- pickle支持的数据类型更多
#利用pickle模块对文件进行写操作(序列化) import pickle dic = {'name': 'alex', 'age': 18, 'sex': 'female'} print(type(dic)) #<class 'dict'> j = pickle.dumps(dic) print(type(j)) #<class 'bytes'> f = open('test_pickle', 'wb') #注意w是写入str,wb是写入bytes,j是‘bytes’ f.write(j) f.close() #利用pickle模块对文件进行读操作(反序列化) import pickle f = open('test_pickle', 'rb') data = pickle.loads(f.read()) print(data['age'])

 浙公网安备 33010602011771号
浙公网安备 33010602011771号