
【ClickHouse入门】七、ClickHouse分片集群
副本虽然能够提高数据的可用性,降低丢失风险,但是每台服务器实际上必须容纳全量数据,对数据的横向扩容没有解决。
要解决数据水平切分的问题,需要引入分片的概念。通过分片把一份完整的数据进行切分,不同的分片分布到不同的节点上,再通过 Distributed 表引擎把数据拼接起来一同使用。
Distributed 表引擎本身不存储数据,有点类似于 MyCat 之于 MySql,成为一种中间件,通过分布式逻辑表来写入、分发、路由来操作多台节点不同分片的分布式数据。
注意:ClickHouse 的集群是表级别的,实际企业中,大部分做了高可用,但是没有用分片,避免降低查询性能以及操作集群的复杂性。
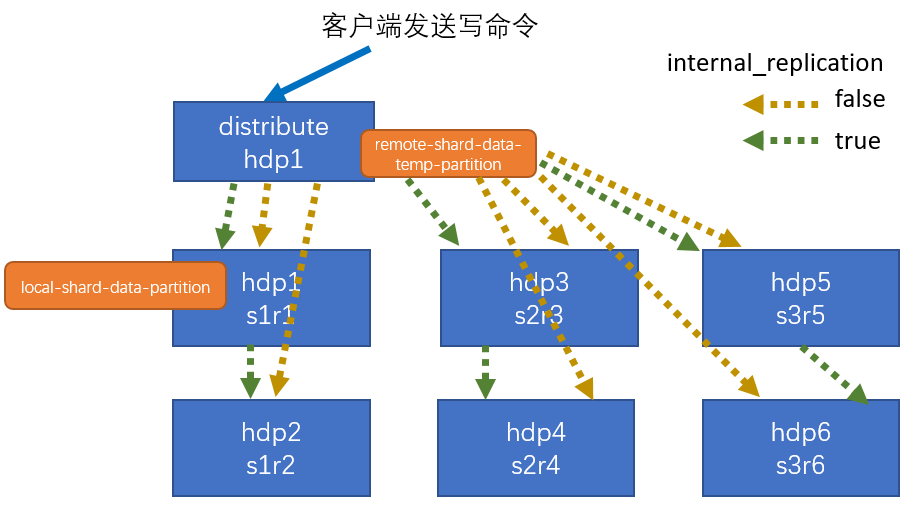
7.1 集群写入流程(3分片,2副本,共六个节点)
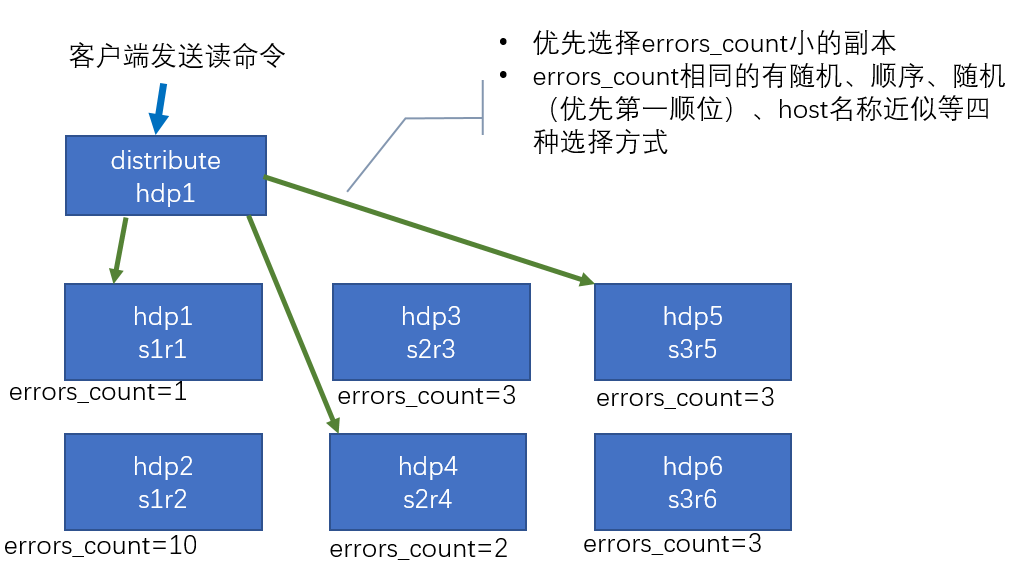
7.2 集群读取流程(3分片,2副本,共六个节点)
7.3 3分片2副本共6个节点集群配置(供参考)
配置的位置还是在之前的/etc/clickhouse-server/config.d/metrika.xml,内容如下
注:也可以不创建外部文件,直接在 config.xml 的<remote_servers>中指定
<remote_servers> <gmall_cluster> <!-- 集群名称--> <shard> <!--集群的第一个分片--> <internal_replication>true</internal_replication> <!--该分片的第一个副本--> <replica> <host>T1</host> <port>9000</port> </replica> <!--该分片的第二个副本--> <replica> <host>T2</host> <port>9000</port> </replica> </shard> <shard> <!--集群的第二个分片--> <internal_replication>true</internal_replication> <replica> <!--该分片的第一个副本--> <host>T3</host> <port>9000</port> </replica> <replica> <!--该分片的第二个副本--> <host>T4</host> <port>9000</port> </replica> </shard> <shard> <!--集群的第三个分片--> <internal_replication>true</internal_replication> <replica> <!--该分片的第一个副本--> <host>T5</host> <port>9000</port> </replica> <replica> <!--该分片的第二个副本--> <host>T6</host> <port>9000</port> </replica> </shard> </gmall_cluster> </remote_servers>
7.4 配置三节点版本集群及副本
7.4.1 集群级副本规划(2个分片,只有一个分片有副本)
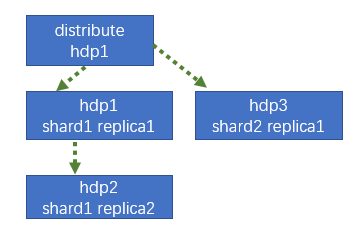
| T1 | T2 | T3 |
|
<macros> <shard>01</shard> <replica>rep1_1</replica> </macros> |
<macros> <shard>01</shard> <replica>rep1_2</replica> </macros> |
<macros> <shard>02</shard> <replica>rep2_1</replica> </macros> |
7.4.2 配置步骤
1)在T1的 /etc/clickhouse-server/config.d目录下创建metrika-shard.xml文件
注:也可以不创建外部文件,直接在 config.xml 的<remote_servers>中指定
<?xml version="1.0"?> <yandex> <remote_servers> <gmall_cluster> <!-- 集群名称--> <shard> <!--集群的第一个分片--> <internal_replication>true</internal_replication> <replica> <!--该分片的第一个副本--> <host>T1</host> <port>9000</port> </replica> <replica> <!--该分片的第二个副本--> <host>T2</host> <port>9000</port> </replica> </shard> <shard> <!--集群的第二个分片--> <internal_replication>true</internal_replication> <replica> <!--该分片的第一个副本--> <host>T3</host> <port>9000</port> </replica> </shard> </gmall_cluster> </remote_servers> <zookeeper-servers> <node index="1"> <host>T1</host> <port>2181</port> </node> <node index="2"> <host>T2</host> <port>2181</port> </node> <node index="3"> <host>T3</host> <port>2181</port> </node> </zookeeper-servers> <macros> <shard>01</shard> <!--不同机器放的分片数不一样--> <replica>rep_1_1</replica> <!--不同机器放的副本数不一样--> </macros> </yandex>
2)将T1的metrika-shard.xml同步到T2和T3
[root@T1 config.d]# scp metrika-shard.xml root@T2:/etc/clickhouse-server/config.d/metrika-shard.xml
[root@T1 config.d]# scp metrika-shard.xml root@T3:/etc/clickhouse-server/config.d/metrika-shard.xml
3)修改T2和T3的metrika-shard.xml的配置
(1)T2:
<macros> <shard>01</shard> <!--不同机器放的分片数不一样--> <replica>rep_1_2</replica> <!--不同机器放的副本数不一样--> </macros>
(2)T3:
<macros> <shard>02</shard> <!--不同机器放的分片数不一样--> <replica>rep_2_1</replica> <!--不同机器放的副本数不一样--> </macros>
4)在T1,T2,T3上修改/etc/clickhouse-server/config.xml
<zookeeper incl="zookeeper-servers" optional="true" /> <include_from>/etc/clickhouse-server/config.d/metrika-shard.xml</include_from>
5)重启3台服务器clickhouse服务
[root@T1 clickhouse-server]# clickhouse restart
6)在T1上执行建表语句
- 会自动同步到T2,T3上
- 集群名字要和配置文件中的一致
- 分片和副本名称从配置文件的宏定义中获取
T1 :) create table st_order_mt on cluster gmall_cluster ( :-] id UInt32, :-] sku_id String, :-] total_amount Decimal(16,2), :-] create_time Datetime :-] ) engine :-] =ReplicatedMergeTree('/clickhouse/tables/{shard}/st_order_mt','{replica}') :-] partition by toYYYYMMDD(create_time) :-] primary key (id) :-] order by (id,sku_id); CREATE TABLE st_order_mt ON CLUSTER gmall_cluster ( `id` UInt32, `sku_id` String, `total_amount` Decimal(16, 2), `create_time` Datetime ) ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/st_order_mt', '{replica}') PARTITION BY toYYYYMMDD(create_time) PRIMARY KEY id ORDER BY (id, sku_id) Query id: 36b3b1df-8e73-4ee7-b9f5-6a0072004271 ┌─host─┬─port─┬─status─┬─error─┬─num_hosts_remaining─┬─num_hosts_active─┐ │ T3 │ 9000 │ 0 │ │ 5 │ 2 │ └──────┴──────┴────────┴───────┴─────────────────────┴──────────────────┘ ┌─host─┬─port─┬─status─┬─error─┬─num_hosts_remaining─┬─num_hosts_active─┐ │ T1 │ 9000 │ 0 │ │ 4 │ 0 │ │ T2 │ 9000 │ 0 │ │ 3 │ 0 │ └──────┴──────┴────────┴───────┴─────────────────────┴──────────────────┘
可以到T2,T3上查看表是否创建成功
T2 :) show tables; SHOW TABLES Query id: bfcf8561-082d-4e31-8956-50f1f557d229 ┌─name─────────┐ │ st_order_mt │ │ t_order_rep2 │ └──────────────┘ 2 rows in set. Elapsed: 0.055 sec.
T3 :) show tables; SHOW TABLES Query id: 6fdb4891-4015-4f81-95a2-2b814c0f5ad3 ┌─name─────────┐ │ st_order_mt │ │ t_order_rep2 │ └──────────────┘ 2 rows in set. Elapsed: 0.002 sec.
7)在T1上创建Distribute分布式表
T1 :) create table st_order_mt_all2 on cluster gmall_cluster :-] ( :-] id UInt32, :-] sku_id String, :-] total_amount Decimal(16,2), :-] create_time Datetime :-] )engine = Distributed(gmall_cluster,default, st_order_mt,hiveHash(sku_id)); CREATE TABLE st_order_mt_all2 ON CLUSTER gmall_cluster ( `id` UInt32, `sku_id` String, `total_amount` Decimal(16, 2), `create_time` Datetime ) ENGINE = Distributed(gmall_cluster, default, st_order_mt, hiveHash(sku_id)) Query id: fdfb9a76-b995-4583-9148-1a441d898761 Connecting to localhost:9000 as user default. Connected to ClickHouse server version 21.7.3 revision 54449. ┌─host─┬─port─┬─status─┬─error─┬─num_hosts_remaining─┬─num_hosts_active─┐ │ T1 │ 9000 │ 0 │ │ 2 │ 0 │ │ T2 │ 9000 │ 0 │ │ 1 │ 0 │ │ T3 │ 9000 │ 0 │ │ 0 │ 0 │ └──────┴──────┴────────┴───────┴─────────────────────┴──────────────────┘ 3 rows in set. Elapsed: 0.129 sec.
参数含义:
Distributed(集群名称,库名,本地表名,分片键)
分片键必须是整型数字,所以用hiveHash函数转换,也可以rand()
8)在T1上插入测试数据
T1 :) insert into st_order_mt_all2 values :-] (201,'sku_001',1000.00,'2020-06-01 12:00:00') , :-] (202,'sku_002',2000.00,'2020-06-01 12:00:00'), :-] (203,'sku_004',2500.00,'2020-06-01 12:00:00'), :-] (204,'sku_002',2000.00,'2020-06-01 12:00:00'), :-] (205,'sku_003',600.00,'2020-06-02 12:00:00'); INSERT INTO st_order_mt_all2 VALUES Query id: 600afac8-4bc1-4afb-8ccd-8bf68a303030 Ok. 5 rows in set. Elapsed: 0.014 sec.
9)通过查询分布式表和本地表观察输出结果
(1)分布式表
SELECT * FROM st_order_mt_all2;
(2)本地表
select * from st_order_mt;
(3)观察数据的分布
st_order_mt_all2:
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐ │ 202 │ sku_002 │ 2000.00 │ 2020-06-01 12:00:00 │ │ 203 │ sku_004 │ 2500.00 │ 2020-06-01 12:00:00 │ │ 204 │ sku_002 │ 2000.00 │ 2020-06-01 12:00:00 │ └─────┴─────────┴──────────────┴─────────────────────┘ ┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐ │ 205 │ sku_003 │ 600.00 │ 2020-06-02 12:00:00 │ └─────┴─────────┴──────────────┴─────────────────────┘ ┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐ │ 201 │ sku_001 │ 1000.00 │ 2020-06-01 12:00:00 │ └─────┴─────────┴──────────────┴─────────────────────┘
T1: st_order_mt
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐ │ 202 │ sku_002 │ 2000.00 │ 2020-06-01 12:00:00 │ │ 203 │ sku_004 │ 2500.00 │ 2020-06-01 12:00:00 │ │ 204 │ sku_002 │ 2000.00 │ 2020-06-01 12:00:00 │ └─────┴─────────┴──────────────┴─────────────────────┘
T2: st_order_mt
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐ │ 202 │ sku_002 │ 2000.00 │ 2020-06-01 12:00:00 │ │ 203 │ sku_004 │ 2500.00 │ 2020-06-01 12:00:00 │ │ 204 │ sku_002 │ 2000.00 │ 2020-06-01 12:00:00 │ └─────┴─────────┴──────────────┴─────────────────────┘
T3: st_order_mt
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐ │ 205 │ sku_003 │ 600.00 │ 2020-06-02 12:00:00 │ └─────┴─────────┴──────────────┴─────────────────────┘ ┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐ │ 201 │ sku_001 │ 1000.00 │ 2020-06-01 12:00:00 │ └─────┴─────────┴──────────────┴─────────────────────┘

 浙公网安备 33010602011771号
浙公网安备 33010602011771号