net.ipv4.tcp_retries2作用介绍
net.ipv4.tcp_retries2 深度解析与优化指南
核心作用与机制
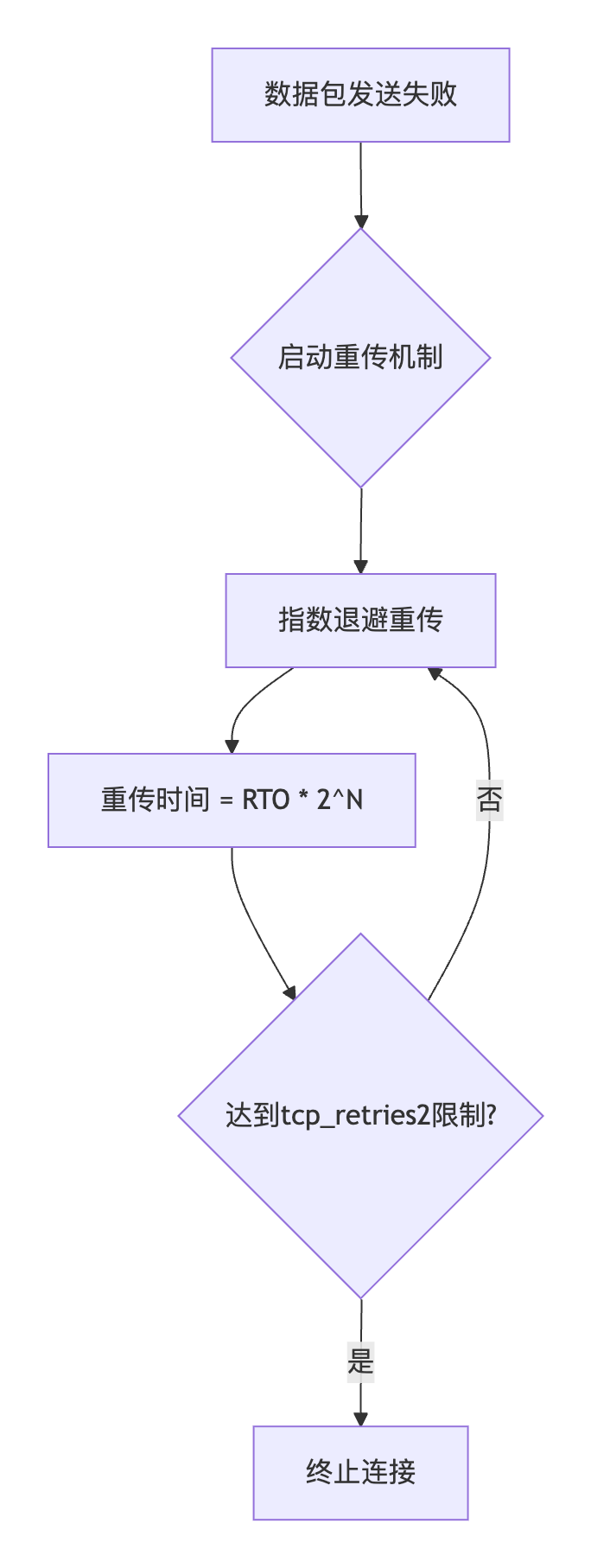
net.ipv4.tcp_retries2 控制已建立连接(ESTABLISHED状态)中数据传输失败时的重传行为。它决定了TCP在一直未收到ACK,放弃连接前尝试重传数据的最大持续时间(而非简单重传次数)。
关键计算公式
def calculate_timeout(retries2):
RTO_MIN = 0.2 # 200ms
RTO_MAX = 120 # 120秒
linear_thresh = 9 # 固定值
if retries2 <= linear_thresh:
return (2**retries2 - 1) * RTO_MIN
else:
return (2**linear_thresh - 1) * RTO_MIN + (retries2 - linear_thresh) * RTO_MAX
默认值与实际效果
| 参数值 | 超时时间 | 适用场景 |
|---|---|---|
| 默认值 15 | ~924.6秒 (15.4分钟) | 通用互联网应用 |
| 值 8 | ~25.5秒 | 低延迟数据中心 |
| 值 5 | ~6.3秒 | 实时系统 |
| 值 3 | ~1.4秒 | 超低延迟交易系统 |
与相关参数的对比
| 参数 | 作用阶段 | 控制对象 | 典型值 |
|---|---|---|---|
tcp_retries2 |
ESTABLISHED | 数据传输 | 15 |
tcp_retries1 |
连接建立/路由 | 路由缓存失效 | 3 |
tcp_syn_retries |
SYN-SENT | SYN重传 | 6 |
tcp_orphan_retries |
FIN-WAIT | 孤儿连接 | 7 |
生产环境优化指南
1. 不同场景推荐值
graph TD
A[网络环境] --> B[同数据中心]
A --> C[跨AZ/跨城]
A --> D[公网/跨国]
B -->|RTT<1ms| E[tcp_retries2=5]
C -->|RTT 10-50ms| F[tcp_retries2=8]
D -->|RTT>100ms| G[tcp_retries2=12]
2. 配置方法
临时修改:
sysctl -w net.ipv4.tcp_retries2=8
永久修改:
echo "net.ipv4.tcp_retries2=8" >> /etc/sysctl.conf
sysctl -p
3. 监控与诊断
关键监控指标:
# 查看TCP超时事件
netstat -s | grep -i "timeout"
# 查看重传统计
nstat -z | grep -E 'TcpRetransSegs|TcpTimeout'
告警阈值建议:
# 每分钟超时事件 > 5
if [ $(netstat -s | grep "connections timed out" | awk '{print $1}') -gt 5 ]; then
alert "High TCP timeout rate"
fi
最佳实践与陷阱规避
1. 黄金组合配置
# /etc/sysctl.conf
net.ipv4.tcp_retries2 = 8 # 重传超时 ~25秒
net.ipv4.tcp_keepalive_time = 30 # 30秒后开始keepalive
net.ipv4.tcp_keepalive_intvl = 5 # 5秒探测间隔
net.ipv4.tcp_keepalive_probes = 3 # 3次探测失败断开
net.ipv4.tcp_fin_timeout = 15 # FIN超时15秒
2. 应用层协同设计
// 应用层超时设置应小于TCP超时
const int TCP_TIMEOUT = sysctl_get("net.ipv4.tcp_retries2") * RTO_MIN * 2;
set_app_timeout(TCP_TIMEOUT * 0.8); // 80% of TCP timeout
3. 常见陷阱规避
-
值过小导致假阳性断开
# 错误配置:在移动网络中使用低值 sysctl -w net.ipv4.tcp_retries2=3 # 可能造成频繁断开 -
值过大导致僵尸连接
# 错误配置:公网应用使用默认15 # 可能导致连接占用资源15分钟 -
忽略网络基础设施
# 在有状态防火墙环境中 # 需确保tcp_retries2 < 防火墙会话超时
内核实现解析(Linux 5.4+)
// 内核源码关键逻辑
static bool retransmits_timed_out(struct sock *sk, unsigned int boundary)
{
unsigned int timeout;
timeout = ((2 << min(boundary, 9)) - 1) * TCP_RTO_MIN;
if (boundary > 9)
timeout += TCP_RTO_MAX * (boundary - 9);
return (tcp_jiffies32 - start_ts) >= timeout;
}
演进历史:
- Linux 4.1+:优化为更精确的毫秒级计算
- Linux 5.0+:引入更智能的动态RTO调整
生产建议:对于现代数据中心应用,推荐设置
tcp_retries2=8(约25秒超时),配合应用层15秒超时,实现快速故障转移。在公网服务中可保持默认值15或调整为12。
注意经查阅资料,net.ipv4.tcp_retries2,并不是指定重传次数的,而是用来计算重传超时时间的
tcp_retries2 的具体计算公式如下:
如果 tcp_retries2 的值小于或等于 9,则计算公式为:
timeout = ((2 << tcp_retries2) - 1) * rto_base;
如果 tcp_retries2 的值大于 9,则计算公式为:
timeout = ((2 << 9) - 1) * rto_base + (tcp_retries2 - 9) * TCP_RTO_MAX;
其中,rto_base 是初始重传超时时间通常为200ms,TCP_RTO_MAX 是最大重传超时时间通常为120s。
然后根据rto退避规则,进行重传,达到超时时间后的,下一个rto断开链接

 浙公网安备 33010602011771号
浙公网安备 33010602011771号