

【MySQL主从复制】1、MySQL主从复制原理、搭建
0、为什么需要主从复制
- 在业务复杂的系统中,有这么一个情景,有一句SQL语句需要锁表,导致暂时不能使用读的服务,那么就很影响运作中的业务,使用主从复制,让主库负责写,从库负责读,这样即使主库出现了锁表的情景,通过读从库也可以保证业务的正常运行。
- 做数据的热备
- 架构的扩展。业务量越来越大,I/O访问频率过高,单机无法满足,此时做多库的存储,降低磁盘I/O访问的频率,提高单个机器的I/O性能
1、什么是MySQL的主从复制?
- MySQL主从复制是指数据可以从一个MySQL数据库服务器主节点复制到一个或多个从节点。MySQL默认采用异步复制方式,这样从节点不用一直访问主服务器来更新自己的数据,数据的更新可以在远程连接上进行,从节点可以复制主数据库中的所有数据库或者特定的数据库,或者特定的表
2、MySQL复制原理
- 原理:
- master服务器将数据的改变记录二进制binlog日志,当master上的数据发生改变时,则将其改变写入二进制日志中
- slave服务器会在一定时间间隔内对master二 进制日志进行探测其是否发生改变,如果发生改变,则开始一个I/OThread请求master二进制事件
- 同时主节点为每个I/O线程启动一个dump线程,用于向其发送二进制事件,并保存至从节点本地的中继日志中,从节点将启动SQL线程从中继日志中读取二进制日志,在本地重放,使得其数据和主节点的保持一致,最后I/OThread和SQLThread将进入睡眠状态,等待下一次被唤醒
- 也就是说:
- 从库会生成两个线程,一个I/O线程,一个没有MySQL线程
- I/O线程会去请求主库的binlog,并将得到的binlog写到本地的relay-log(中继日志)文件中
- 主库会生成一个log dump线程,用来给从库I/O线程传binlog
- 从库的SQL线程会读取relay log文件中的日志,并解析成SQL语句主义执行
- 如图:
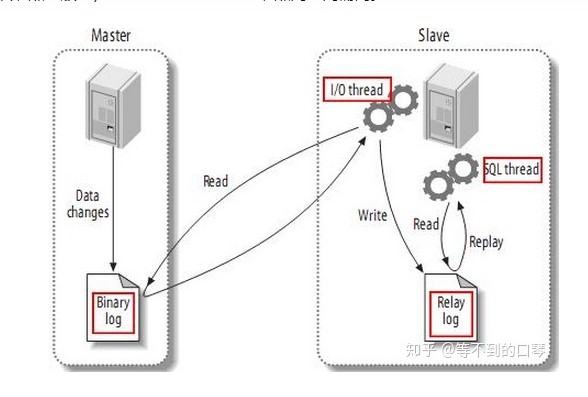
- 注意:
- master将操作语句记录到binlog在日志中,然后授予slave远程连接的权限(master一定要开启binlog二进制日志功能;通常为了数据安全考虑,slave也开启binlog功能)
- slave开启两个线程:I/O线程和mysql线程。其中I/O线程负责读取master的binlog内容到中级日志(relay log)里;SQL线程负责将relay log日志里读出binlog内容,并更新到slave的数据库里,这样就能保证slave数据和master数据保持一致了
- MySQL复制至少需要两个mysql的服务,当然MySQL服务也可以分布在不同的服务器上,也可以在一台服务器上启动多个服务
- MySQL复制最好确保master和slave服务器上的MySQL版本相同(如果不能满足版本一致,那么要保证master主节点的版本低于slave从节点的版本)
- master和slave两节点间的时间需同步
- 具体步骤:
- 从库通过手工执行change master to语句连接主库,提供了连接的用户一切条件(user、password、port、IP),并且让从库知道,二进制日志的起点位置(file名 position号);start slave
- 从库的io线程和主库的dump线程建立连接
- 从库根据change master to语句提供的file名和position号,io线程向主库发起binlog的请求
- 主库dump线程根据从库的请求,将本地binlog以events的方式发给从库io线程
- 从库io线程接收到binlog events,并存放到本地的relay-log中,传送过来的信息,会记录到master.info中
- 从库SQL线程应用relay-log,并且把应用过的记录到relay-log.info中,默认情况下,已经应用过的relay会自动被清理purge
3、MySQL主从形式
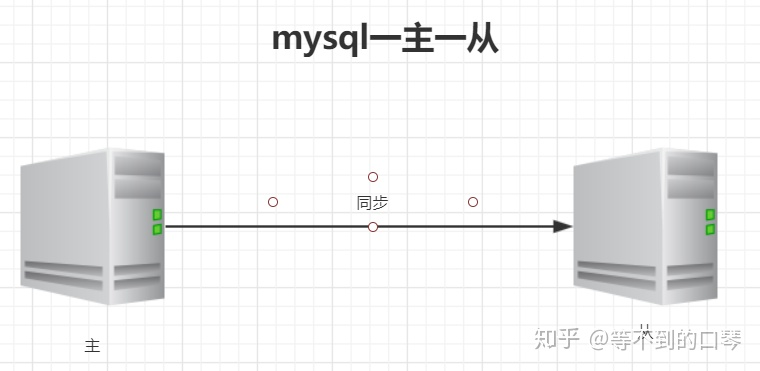
- 一主一从
- 主主复制

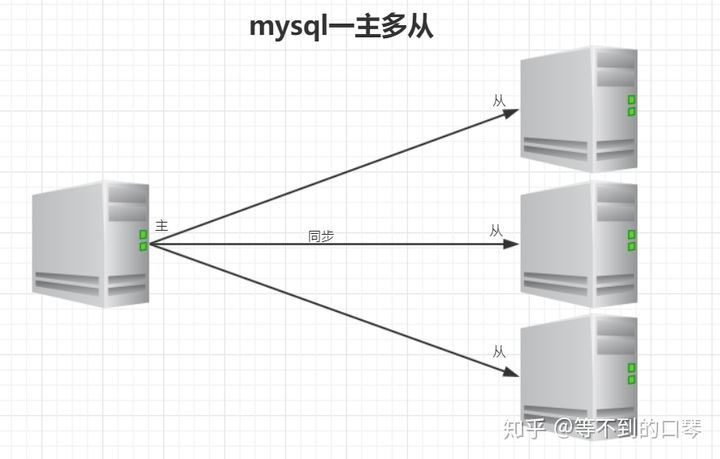
- 一主多从
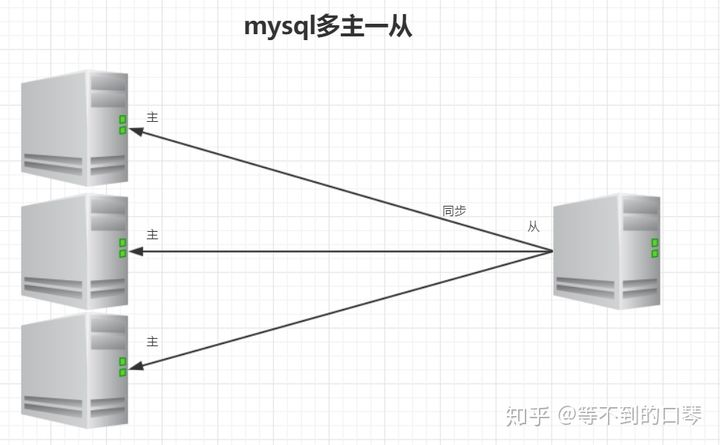
- 多主一从
- 联级复制
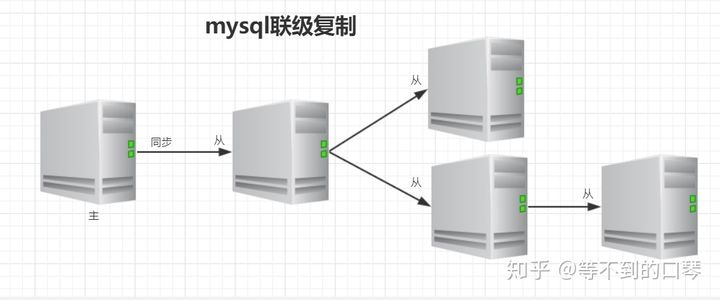
4、MySQL主从同步延时分析
- MySQL的主从复制都是单线程的操作,主库对所有DDL和DML产生的日志写进binlog,由于binlog是顺序写,所以效率很高;slave的sql thread线程将主库的DDL和DML操作事件在slave中重放。DML和DDL的IO操作是随机的,不是顺序,所以成本要高很多,另一方面,由于sql thread也是单线程的,当主库的并发较高时,产生的DML数量超过slave的SQL thread所能处理的速度,或者当slave中有大型query语句产生了锁等待,那么延迟就产生了。
- 解决方法:
- 业务的持久化层的实现采用分库架构,MySQL服务可平行扩展,分散压力
- 单个库读写分离,一主多从,主写从读,分散压力。这样从库压力比主库高,保护主库
- 服务的基础架构在业务和mysql之间加入memcache或者redis的cache层。降低MySQL的读压力
- 不同业务的MySQL物理上存放不同机器,分散压力
- 使用比主库更好的硬件设备作为slave,MySQL压力小,延迟自然会变小
- 使用更加强劲的硬件设备
5、MySQL主从复制安装配置
- 基础设置准备
# 操作系统
centos7
# mysql版本
5.7
# 两台服务器
node1:47.94.132.145(主)
node2:39.100.120.203(从)- 安装MySQL数据库
- centos安装mysql
1、安装wget命令
yum install wget -y
2、给Centos添加rpm源,并且选择较新的源
wget dev.mysql.com/get/mysql-community-release-el7-5.noarch.rpm
3、安装下载好的rpm文件
yum install -y mysql-community-release-el7-5.noarch.rpm
4、安装成功之后,会在/etc/yum.repos.d/文件夹下增加两个文件
mysql-community-source.repo
mysql-community.repo
5、vi mysql-community.repo
[mysql56-community]
enabled=0
[mysql57-community-dmr]
enabled=1
6、使用yum安装mysql
yum install mysql-community-server -y
如果报错,报错详情:Error:Unable to find a match: mysql-community-server
解决方案:先禁用本地的 MySQL 模块在安装即可
yum module disable mysql -y //禁用
再执行 yum install mysql-community-server -y
7、启动mysql服务并设置开机启动
# 启动mysql服务器
service mysqld start
# 设置mysql开机启动
chkconfig mysqld on
如果报错,报错详情为:service: command not found
解决方案:
yum list | grep initscripts # 会出现initscripts.x86_64
yum install initscripts -y
8、获取mysql的临时密码
grep "password" /var/log/mysqld.log
9、使用临时密码登录
mysql -uroot -p
10、修改密码
set global validate_password_polict=0;
set global validate_password_length=1;
ALTER USER 'root'@'localhost' IDENTIFIED BY '123456';
13、修改远程访问权限
grant all privileges on *.* to 'root'@'%' identifyed by '123456' with grant option;
flush privileges;- docker安装mysql
1、首先拉取docker镜像,我们这里使用5.7版本的mysql
docker pull mysql:5.7
2、启动主从数据库服务器
docker run -p 3339:3306 --name node1 -e MYSQL_ROOT_PASSWORD=123456 -d mysql:5.7 # 主节点
docker run -p 3339:3306 --name node2 -e MYSQL_ROOT_PASSWORD=123456 -d mysql:5.7 # 从节点
3、进入到主节点服务器下
cd /etc/mysql切换到/etc/mysql目录下; 然后vi my.cnf对my.cnf进行编辑。此时会报出bash: vi: command not found,需要我们在docker容器内部自行安装vim。使用apt-get install vim命令安装vim, 会报错,错误详情为Unable to locate package vim
执行apt-get update,然后再次执行apt-get install vim即可成功安装vim- 在两台数据库中分别创建数据库
# 注意:两台必须全部执行
create database msb;- 在主(node1)服务器进行如下配置:
# 修改配置文件,执行以下命令打开mysql配置文件
vi /etc/my.cnf
# 在mysqld模块下添加如下配置信息
log-bin=master-bin # 二进制文件名称
binlog-format=ROW # 二进制日志格式,有row、statement、mixed三种格式;row指的是把改变的内容复制过去,而不是把命令在从服务器上执行一遍;statement指的是在主服务器上执行的SQL语句,在从服务器上执行同样的语句。MySQL默认采用基于语句的复制,效率比较高。mixed指的是默认采用基于语句的复制,一旦发现基于语句的无法精确的复制时,就会采用基于行的复制。
server-id=1 # 要求各个服务器的id必须不一致
binlog-do-db=msb # 同步的数据库名称
# 重启mysql[centos]
service mysqld restart
# 重启mysql[docker]
service mysql restart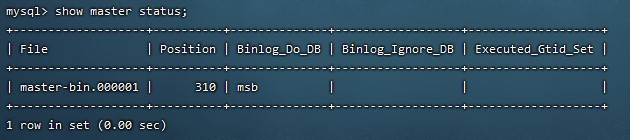
- 配置从服务器登录主服务器的账号授权
# 调整MySQL密码验证规则, 避免密码过于简单,不符合MySQL密码规范
set global validate_password_policy=0;
set global validate_password_length=1;
# 授权操作
grant replication slave on *.* to 'root'@'%' identified by '123456';
# 刷新权限
flush privileges;- 从服务器的配置
# 修改配置文件,执行以下命令打开mysql配置文件
vi /etc/my.cnf
# 在mysqld模块中添加如下配置信息
log-bin=master-bin # 二进制文件名称
binlog-format=ROW # 二进制日志格式,有row、statement、mixed三种格式;row指的是把改变的内容复制过去,而不是把命令在从服务器上执行一遍;statement指的是在主服务器上执行的SQL语句,在从服务器上执行同样的语句。MySQL默认采用基于语句的复制,效率比较高。mixed指的是默认采用基于语句的复制,一旦发现基于语句的无法精确的复制时,就会采用基于行的复制。
server-id=2 # 要求各个服务器的id必须不一致
- 重启从服务器并进行相关配置
# 重启mysql[centos]
service mysqld restart
# 重启mysql[docker]
service mysql restart
# 连接主服务器
change master to master_host='47.94.132.145', master_user='root', master_password='root', master_port=8091, master_log_file='master-bin.000001', master_log_pos=310;
# 用于查看主从同步状态
show slave status\G- 连接主服务器语句解释:
- master_host: Master 的IP地址
- master_user: 在 Master 中授权的用于数据同步的用户
- master_password: 同步数据的用户的密码
- master_port: Master 的数据库的端口号
- master_log_file: 指定 Slave 从哪个日志文件开始复制数据,即上文中提到的 File 字段的值
- master_log_pos: 从哪个 Position 开始读,即上文中提到的 Position 字段的值
- master_connect_retry: 当重新建立主从连接时,如果连接失败,重试的时间间隔,单位是秒,默认是60秒。
- 正常情况下,SlaveIORunning 和 SlaveSQLRunning 都是No,因为我们还没有开启主从复制过程。
- 开启主从复制过程:
start slave # 开启主从复制过程
# 再次查询主从同步状态
show slave status \G;
# SlaveIORunning 和 SlaveSQLRunning 都是Yes,说明主从复制已经开启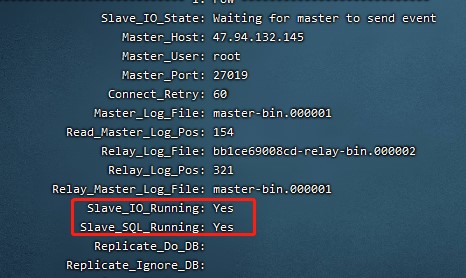
- 主从复制排错:
- 使用start slave开启主从复制过程后,如果SlaveIORunning一直是Connecting,则说明主从复制一直处于连接状态,这种情况一般是下面几种原因造成的,我们可以根据Last_IO_Error提示进行排除:
- 网络不通(检查ip、端口)
- 密码不对(检查是否创建用于同步的用户和用户密码是否正确)
- pos不对(检查Master的Position)
6、测试主从复制
# 主库操作
# 创建表
create table user(id int, age int);
# 添加数据
insert into user values(1, 1);
# 查看数据
select * from user;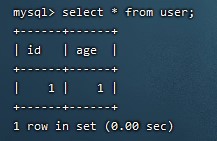
# 从库操作
# 查看表
show tables;
# 查看数据
select * from user;
# 在从库插入数据,在主库不会同步的
7、遇到问题
- 问题描述:
- ERROR 3021 (HY000): This operation cannot be performed with a running slave io thread
- 解决方案:
# 停止已经绑定的从库
stop slave
# 重新连接主服务器
change master to master_host='47.94.132.145', master_user='root', master_password='root', master_port=8091, master_log_file='master-bin.000001', master_log_pos=310;
# 然后重启
start slave- 从库binlog落后主库binlog
- 从库记录的已经从主库给我传送的binlog事件的坐标,一般在繁忙的生产环境下会落后于主库
show master status\G --- 主
show slave status \G --- 从
Master_Log_File: mysql-bin.000007
Read_Master_Log_Pos: 729- 落后太远的原因:
- 硬件条件有关的,机器磁盘IO性能不足。主要还是网络问题,网络传输的性能。主库存放二进制日志的存储性能太低,建议binlog日志存在SSD中。主库dump线程太繁忙,主要发生在一主多从的环境下。从库IO线程太忙。人为控制(delay节点、延时节点)
- 主库update,从库迟迟的没有更新
- 特殊情况:日志已经传过来,数据并没有同步
- 一般情况:
- 没开启SQL线程
- 传的东西有问题(比如你要做的事情,已经提前做了,不想重复做了,然后他就死了)
- SQL线程忙
- 人为控制了[delay(从库)节点、延时节点,一般生产设置为3-6小时之间,可以保证过去3-6小时之间的误操作,可以避免]
- 主从复制延时配置(从库配置)
- 操作步骤:
- 停止从库复制
mysql>stop slave;- 修改延时参数,master_delay,单位为s(秒)
mysql>CHANGE MASTER TO MASTER_DELAY = 30;- 启动从库复制
mysql>start slave;- 查看配置是否生效
mysql> show slave status \G
……
SQL_Delay: 30- 从库安全配置(其他用户只读)
- 修改my.cnf配置文件,添加只读参数
read_only = 1 # 控制普通用户
innodb_read_only = 1 # 控制root用户,正常情况不要加- 添加完成后重启数据库
# centos方式
service mysqld restart
# docker方式
service mysql restartmysql> show variables like '%read_only%';
+------------------+-------+
| Variable_name | Value |
+------------------+-------+
| innodb_read_only | OFF |
| read_only | ON |
| tx_read_only | OFF |
+------------------+-------+
3 rows in set (0.00 sec)- 主从复制故障及解决(跳过错误)
- 命令行设置:
stop slave; # 临时停止同步开关。
set global sql_slave_skip_counter = 1; #<==将同步指针向下移动一个,如果多次不同步,可以重复操作。
start slave; # 开启复制- 在配置文件修改,设置要跳过的pos
/etc/my.cnf
slave-skip-errors = 1032,1062,1007- 在mysql中可以跳过某些错误,但是最好的解决办法,重新搭建主从复制
- Slave_*_Running:
- Slave_IO_Running I/O 线程正在运行、未运行还是正在运行但尚未连接到主服务器。可能值分别为Yes、No 或 Connecting。
- Slave_SQL_Running SQL线程当前正在运行、未运行,可能值分别为Yes、No
- 主服务器日志坐标:Master_Log_File 和 Read_Master_Log_Pos 标识主服务器二进制日志中 I/O 线程已经传输的最近事件的坐标。如果Master_Log_File和Read_Master_Log_Pos 的值远远落后于主服务器上的那些值,这表示主服务器与从属服务器之间事件的网络传输可能存在延迟。
- 中继日志坐标:
- Relay_Log_File 和 Relay_Log_Pos 列标识从属服务器中继日志中 SQL 线程已经执行的最近事件的坐标。
- 这些坐标对应于 Relay_Master_Log_File 和 Exec_Master_Log_Pos 列标识的主服务器二进制日志中的坐标。
- 如果 Relay_Master_Log_File 和 Exec_Master_Log_Pos 列的输出远远落后于 Master_Log_File 和Read_Master_Log_Pos 列(表示 I/O 线程的坐标)
- 这表示 SQL 线程(而不是 I/O 线程)中存在延迟。即,它表示复制日志事件快于执行这些事件
- 单一主从需要改变的地方
- 从库的作用:
- 相当于实时备份
- 使用从库备份
- 一主多从应对读多的业务需求
- 如果,从库只做备份服务器用,那么主库的压力会不减反增。因为,所有的业务都在主库实现,读和写、dump线程读取并投递binlog
- 解决方案:
- 可不可以挪走一部分读业务到从库,读写分离
- 一主多从应对读多的业务需求,一旦发展成这个架构,dump线程投递binlog的压力更大
- 多级主从采用中间库缓解主库dump的压力,会出现中间库缓解主库dump的压力,会出现中间库瓶颈的问题,选择blackhole引擎,看性能与安全的权衡
- 难保证
- 双主模型:缓解,数据一致性
- 环状复制
8、同步主库已有数据到从库
- 如果在设置主从同步前,主服务器上已有大量数据,可以使用mysqldump进行数据备份并还原到从服务器以实现数据的复制:
- 主库仓库
- 停止主库的数据更新操作
mysql>flush tables with read lock;- 新开终端,生成主数据库的备份(导出数据库)
mysqldump -uroot -ptest123 cmdb > cmdb.sql- 将备份文件传到从库
scp cmdb.sql root@192.168.8.11:/root/- 主库解锁
mysql>unlock tables;- 从库操作:
- 停止从库slave
mysql>slave stop;- 新建数据库cmdb
mysql> create database cmdb default charset utf8;- 导入数据
mysql -uroot -ptest123 cmdb<cmdb.sql - 此时主从库的数据完全一致,如果对主库进行增删改操作,从库会自动同步进行操作。
9、mysql正确清理binlog日志的两种方法
- MySQL中binlog日志记录了数据库中数据的变动,便于对数据的基于时间点和基于位置的恢复,但是binlog也会日渐增大,占用很大的磁盘空间,因此,要对binlog使用正确安全的方法清理掉一部分没用的日志
- 方法一:手动清理binlog
- 查看主库和从库正在使用的binlog是哪个文件
show master status \G
show slave status \G- 在删除binlog日志之前,首先对binlog日志备份,以防万一
- 开始删除binlog
purge master logs before'2016-09-01 17:20:00'; # 删除指定日期以前的日志索引中binlog日志文件
purge master logs to 'mysql-bin.000022'; # 删除指定日志文件的日志索引中binlog日志文件- 注意:
- 时间和文件名一定不可以写错,尤其是时间中的年和文件名中的序号,以防不小心将正在使用的binlog删除。切勿删除正在使用的binlog。
- 方法二:通过设置binlog过期的时间,使系统自动删除binlog文件
mysql> show variables like 'expire_logs_days';
+------------------+-------+
| Variable_name | Value |
+------------------+-------+
| expire_logs_days | 0 |
+------------------+-------+
mysql> set global expire_logs_days = 30; # 设置binlog多少天过期- 注意:过期时间设置的要适当,对主从复制,要看从库的延迟决定过期时间,避免主库binlog还未传到从库便因过期而删除,导致主从不一致
本文来自博客园,作者:郭祺迦,转载请注明原文链接:https://www.cnblogs.com/guojie-guojie/p/16159415.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号