1 Linux基础
-
用户的概述
windows系统当中有⼀个管理员Administrator,Linux系统有⼀个超级⽤户root
su(switch user)切换⽤户
普通⽤户切换到任何⽤户都需要输⼊密码 root⽤户切换到任何⽤户都不需要输⼊密码 su - username su命令切换⽤户如果不加"-",只是shell层⾯的切换,⽤户的环境变量实际上是没有变的 su -和su - root 是⼀样的,没有区别
目录的结构
“/”表示根⽬录,根⽬录是Linux⽬录结构中的最顶级的⽬录,类似于windows的C:\ D:\
| /boot⽬录 | 存放的是系统的启动配置⽂件和内核⽂件 |
|---|---|
| /dev⽬录 | 存放的是Linux的设备⽂件 |
| /etc⽬录 | 存放的是Linux的配置⽂件 |
| /home⽬录 | 存放的是Linux普通⽤户的家⽬录 |
| /media⽬录 | 挂载点⽬录 |
| /mnt⽬录 | 挂载点⽬录 |
| /run⽬录 | 挂载点⽬录 |
| /opt⽬录 | 存放软件⽂件的⽬录 |
| /proc⽬录 | 存放的是进程⽂件 |
| /srv⽬录 | 存放⼀些资源⽂件 |
| /sys⽬录 | 存放⼀些资源⽂件(系统资源) |
| /tmp⽬录 | 存放的是⼀些临时⽂件(⾮常重要) |
| /usr⽬录 | Linux软件默认安装的⽬录 |
| /var⽬录 | 存放log⽇志⽂件的⽬录(⾮常重要) |
| /root | 是root⽤户的家⽬录 |
-
绝对路径和相对路径
什么是绝对路径:以顶级⽬录开头的路径就是绝对路径,在Linux⾥⾯"/"就是顶级⽬录,以"/"开头的路径就是绝对路径
什么是相对路径:不以"/"开头的路径就是相对路径
“/”目录下的软连接
| /bin->/usr/bin | 存放的是普通⽤户能执⾏的命令 |
|---|---|
| /sbin->/usr/sbin | 存放的是超级⽤户能执⾏的命令 |
| /lib->/usr/lib | 存放的是32位的函数⽂件 |
| /lib64->/usr/lib64 | 存放的是64位的函数⽂件 |
3. 软连接和硬链接
创建方法
软连接:
ln -s oldfile slink
硬链接:
ln oldfile hlink4. 软连接和硬链接的区别
原理上,硬链接和源文件的inode节点号相同,两者互为硬链接。软连接和源文件的inode节点号不同,进而指向的block也不同,软连接block中存放了源文件的路径名。
实际上,硬链接和源文件是同一份文件,而软连接是独立的文件,类似于快捷方式,存储着源文件的位置信息便于指向。
使用限制上,不能对目录创建硬链接,不能对不同文件系统创建硬链接,不能对不存在的文件创建硬链接;可以对目录创建软连接,可以跨文件系统创建软连接,可以对不存在的文件创建软连接。
4.1 硬链接的特点
-
具有相同inode节点号的多个文件互为硬链接文件;
-
删除硬链接文件或者删除源文件任意之一,文件实体并未被删除;
-
只有删除了源文件和所有对应的硬链接文件,文件实体才会被删除;
-
硬链接文件是文件的另一个入口;
-
可以通过给文件设置硬链接文件来防止重要文件被误删;
-
可以通过ls -i看到Index;
-
硬链接文件是普通文件,可以用rm删除;
-
对于静态文件(没有进程正在调用),当硬链接数为0时文件就被删除。注意:如果有进程正在调用,则无法删除或者即使文件名被删除但空间不会释放。
4.2软链接的特点:
-
软链接类似windows系统的快捷方式;
-
软链接里面存放的是源文件的路径,指向源文件;
-
删除源文件,软链接依然存在,但无法访问源文件内容;
-
软链接失效时一般是白字红底闪烁;
-
创建软链接命令 ln -s 源文件 软链接文件;
-
软链接和源文件是不同的文件,文件类型也不同,inode号也不同;
-
软链接的文件类型是“l”,可以用rm删除。
5. 目录的切换
cd(change directory)
cd .. 表示切换到上级⽬录
cd ~ 表示切换到当前shell⽤户的家⽬录,相当于直接cd命令
cd - 表示切换到上次所在的⽬录(重复该命令,会在两个⽬录下反复的切换)
6. 目录的查看
ls [-parameter] [filename]参数:
-
-a 显示所有文件及目录 (ls内定将文件名或目录名称开头为"."的视为隐藏档,不会列出)
-
-l 除文件名称外,亦将文件型态、权限、拥有者、文件大小等资讯详细列出
-
-r 将文件以相反次序显示(原定依英文字母次序)
-
-t 将文件依建立时间之先后次序列出
-
-A 同 -a ,但不列出 "." (目前目录) 及 ".." (父目录)
-
-F 在列出的文件名称后加一符号;例如可执行档则加 "*", 目录则加 "/"
-
-R 若目录下有文件,则以下之文件亦皆依序列出
2 Linux 常用命令(一)文件操作命令
2.1 命令的提示符
[root@localhost ~]#-
[]:这是提示符的分隔符号,没有特殊含义。
-
root:显示的是当前的登录用户。
-
@:分隔符号,没有特殊含义。
-
localhost:当前系统的简写主机名(完整主机名是localhost.localdomain)。
-
~:代表用户当前所在的目录,此例中用户当前所在的目录是家目录。
-
#:命令提示符。超级用户是#,普通用户是$
2.2 命令的基本格式
[root@localhost ~]# 命令 [选项] [参数]选项:是用于调整命令的功能的。
参数:是命令的操作对象,如果省略参数,是因为有默认参数
2.3 ls命令
ls是最常见的目录操作命令,主要作用是显示目录下的内容。
-
命令名称:ls。
-
英文原意:list。
-
所在路径:/bin/ls。
-
执行权限:所有用户。
功能描述:显示目录下的内容。
[root@localhost ~]#ls [选项] [文件名或目录名]
选项:
-a: 显示所有文件
-d: 显示目录信息,而不是目录下的文件
-h: 人性化显示,按照我们习惯的单位显示文件大小
-i: 显示文件的i节点号
-l: 长格式显示
--color=when: 支持颜色输出,when的值默认是always(总显示颜色),也可以是never(从不显示颜色)和auto(自动)示例:
[root@localhost ~]# ls -l
总用量 44
-rw-------. 1 root root 1207 1月14 18:18 anaconda-ks.cfg
#权限 引用计数 所有者 所属组 大小 文件修改时间 文件名-
第一列:权限。
-
第二列:引用计数。文件的引用计数代表该文件的硬链接个数,而目录的引用计数代表该目录有多少个一级子目录。
-
第三列:所有者,也就是这个文件属于哪个用户。默认所有者是文件的建立用户
-
第四列:所属组。默认所属组是文件建立用户的有效组,一般情况下就是建立用户的所在组。
-
第五列:大小。默认单位是字节。
-
第六列:文件修改时间。文件状态修改时间或文件数据修改时间都会更改这个时间,注意这个时间不是文件的创建时间。
-
第七列:文件名。
2.4 touch命令
创建空文件或更新文件时间,这个命令的基本信息如下。
-
命令名称:touch。
-
英文原意:change file timestamps。
-
所在路径:/bin/touch。
-
执行权限:所有用户。
功能描述:修改文件的时间戳。
[root@localhost ~]#touch [文件名或目录名]示例:
[root@localhost ~]# ls -l
total 4
-rw-------. 1 root root 1259 Mar 5 20:59 anaconda-ks.cfg
[root@localhost ~]# touch anaconda-ks.cfg
[root@localhost ~]# ls -l
total 4
-rw-------. 1 root root 1259 Jun 2 10:40 anaconda-ks.cfg2.5 stat命令
stat是查看文件详细信息的命令,而且可以看到文件的这三个时间,其基本信息如下。
-
命令名称:stat。
-
英文原意:display file or file system status。
-
所在路径:/usr/bin/stat。
-
执行权限:所有用户。
功能描述:显示文件或文件系统的详细信息。
[root@localhost ~]# stat [文件名或目录名]示例:
[root@localhost ~]# stat anaconda-ks.cfg
File: ‘anaconda-ks.cfg’
Size: 1259 Blocks: 8 IO Block: 4096 regular file
Device: fd00h/64768d Inode: 33574980 Links: 1
Access: (0600/-rw-------) Uid: ( 0/ root) Gid: ( 0/ root)
Context: system_u:object_r:admin_home_t:s0
Access: 2021-06-02 10:40:37.532019145 +0800
Modify: 2021-06-02 10:40:37.532019145 +0800 #数据修改时间
Change: 2021-06-02 10:40:37.532019145 +0800 #状态修改时间
Birth: -2.6 cat命令
cat命令用来查看文件内容。这个命令的基本信息如下。
-
命令名称:cat。
-
英文原意:concatenate files and print on the standard output。
-
所在路径:/bin/cat。
-
执行权限:所有用户。
功能描述:合并文件并打印输出到标准输出
[root@localhost ~]# cat [选项] [文件名]
选项:
-A: 相当于-vET选项的整合,用于列出所有隐藏符号
-E: 列出每行结尾的回车符$
-n: 显示行号
-T: 把Tab键用^I显示出来
-v: 列出特殊字符示例:
[root@localhost ~]# cat -An anaconda-ks.cfg
1 #version=DEVEL$
2 # System authorization information$
3 auth --enableshadow --passalgo=sha512$
4 # Use CDROM installation media$
5 cdrom$
6 # Use graphical install$
7 graphical$
8 # Run the Setup Agent on first boot$
9 firstboot --enable$
10 ignoredisk --only-use=sda$
11 # Keyboard layouts$
12 keyboard --vckeymap=us --xlayouts='us'$
13 # System language$2.7 more命令
more是分屏显示文件的命令,其基本信息如下。
-
命令名称:more。
-
英文原意:file perusal filter for crt viewin。
-
所在路径:/bin/more。
-
执行权限:所有用户。
功能描述:分屏显示文件内容。
[root@localhost ~]# more [文件名]
more命令比较简单,一般不用什么选项,命令会打开一个交互界面,可以识别一些交互命令。常用的交互命令如下
空格键:向下翻页。
b:向上翻页。
回车键:向下滚动一行。
/字符串:搜索指定的字符串。
q:退出。示例:
[root@localhost ~]# more anaconda-ks.cfg 2.8 less命令
less命令和more命令类似,只是more是分屏显示命令,而less是分行显示命令,其基本信息如下。
-
命令名称:less。
-
英文原意:opposite of more。
-
所在路径:/usr/bin/less。
-
执行权限:所有用户。
功能描述:分行显示文件内容
[root@localhost ~]# less [文件名]
less命令比较简单,一般不用什么选项,命令会打开一个交互界面,可以识别一些交互命令。常用的交互命令如下
空格键:向下翻页。
b:向上翻页。
回车键:向下滚动一行。
/字符串:搜索指定的字符串。
q:退出。示例:
[root@localhost ~]# less anaconda-ks.cfg 2.9 head命令
head是用来显示文件开头的命令,其基本信息如下。
-
命令名称:head。
-
英文原意:output the first part of files。
-
所在路径:/usr/bin/head。
-
执行权限:所有用户。
功能描述:显示文件开头的内容。
[root@localhost ~]# head [选项] [文件名]
选项:
-n 行数: 从文件头开始,显示指定行数
-v: 显示文件名示例:
[root@node-1 ~]# head -n 5 anaconda-ks.cfg
#version=DEVEL
# System authorization information
auth --enableshadow --passalgo=sha512
# Use CDROM installation media
cdrom2.10 tail命令
既然有显示文件开头的命令,就会有显示文件结尾的命令。tail命令的基本信息如下。
-
命令名称:tail。
-
英文原意:output the last part of files。
-
所在路径:/usr/bin/tail。
-
执行权限:所有用户。
功能描述:显示文件结尾的内容。
[root@localhost ~]# tail [选项] [文件名]
选项:
-n 行数: 从文件结尾开始,显示指定行数
-f: 监听文件的新增内容示例:
[root@localhost ~]# tail -n 5 anaconda-ks.cfg
%anaconda
pwpolicy root --minlen=6 --minquality=1 --notstrict --nochanges --notempty
pwpolicy user --minlen=6 --minquality=1 --notstrict --nochanges --emptyok
pwpolicy luks --minlen=6 --minquality=1 --notstrict --nochanges --notempty
%end2.11 ln命令
建立软连接和硬连接指令
-
命令名称:ln。
-
英文原意:make links between file。
-
所在路径:/bin/ln。
-
执行权限:所有用户。
功能描述:在文件之间建立链接。
[root@localhost ~]# ln [选项] 源文件目标文件
选项:
-s: 建立软链接文件。如果不加“-s”选项,则建立硬链接文件
-f: 强制。如果目标文件已经存在,则删除目标文件后再建立链接文件示例:
创建硬链接:
[root@localhost ~]# touch cangls
[root@localhost ~]# ln /root/cangls /tmp/
创建软链接:
[root@localhost ~]# touch bols
[root@localhost ~]# ln -s /root/bols /tmp/
3 Linux 常用命令(二)目录操作命令
3.1 cd命令
cd是切换所在目录的命令,这个命令的基本信息如下。
-
命令名称:cd。
-
英文原意:change directory。
-
所在路径:Shell内置命令。
-
执行权限:所有用户。
功能描述:切换所在目录。
| 特殊符号 | 作用 |
|---|---|
| ~ | 代表用户的家目录 |
| - | 代表上次所在目录 |
| . | 代表当前目录 |
| .. | 代表上级目录 |
3.2 pwd命令
pwd命令是查询所在目录的命令,基本信息如下:
-
命令名称:pwd
-
英文原意:print name of current/working directory
-
所在路径:/bin/pwd
-
执行权限:所有用户。
功能描述:查询所在的工作目录。
[root@localhost ~]# pwd3.3 mkdir命令
mkdir是创建目录的命令,其基本信息如下。
-
命令名称:mkdir。
-
英文原意:make directories。
-
所在路径:/bin/mkdir。
-
执行权限:所有用户。
功能描述:创建空目录。
[root@localhost ~]# mkdir [选项] [目录名]
选项:
-p: 递归建立所需目录示例:
[root@localhost ~]# mkdir -p /test/projec3.4 rmdir命令
既然有建立目录的命令,就一定会有删除目录的命令rmdir,其基本信息如下。
-
命令名称:rmdir。
-
英文原意:remove empty directories。
-
所在路径:/bin/rmdir。
-
执行权限:所有用户。
功能描述:删除空目录。
[root@localhost ~]# rmdir [选项] [目录名]
选项:
-p: 递归删除目录示例:
[root@localhost ~]# rmkir -p /test/projec3.5 rm命令
rm是强大的删除命令,不仅可以删除文件,也可以删除目录。这个命令的基本信息如下。
-
命令名称:rm。
-
英文原意:remove files or directories。
-
所在路径:/bin/rm。
-
执行权限:所有用户。
功能描述:删除文件或目录。
[root@localhost ~]# rm [选项] [文件或目录]
选项:
-f: 强制删除(force)
-i: 交互删除,在删除之前会询问用户
-r: 递归删除,可以删除目录(recursive)示例:
[root@localhost ~]# rm -rf /test/projec3.6 cp命令
cp是用于复制的命令,其基本信息如下:
-
命令名称:cp。
-
英文原意:copy files and directories。
-
所在路径:/bin/cp。
-
执行权限:所有用户。
功能描述:复制文件和目录。
[root@localhost ~]# cp [选项] [源文件目标文件]
选项:
-a: 相当于-dpr选项的集合,这几个选项我们一一介绍
-d: 如果源文件为软链接(对硬链接无效),则复制出的目标文件也为软链接
-i: 询问,如果目标文件已经存在,则会询问是否覆盖
-p: 复制后目标文件保留源文件的属性(包括所有者、所属组、权限和时间)
-r: 递归复制,用于复制目录示例:
[root@localhost ~]# cp /etc/nginx/nginx.conf.default /etc/nginx/nginx.conf3.7 mv命令
mv是用来剪切的命令,其基本信息如下。
-
命令名称:mv。
-
英文原意:move (rename) files。
-
所在路径:/bin/mv。
-
执行权限:所有用户。
功能描述:移动文件或改名。
[root@localhost ~]# mv [选项] [源文件目标文件]
选项:
-f: 强制覆盖,如果目标文件已经存在,则不询问,直接强制覆盖
-i: 交互移动,如果目标文件已经存在,则询问用户是否覆盖(默认选项)
-v: 显示详细信息示例:
[root@localhost ~]# mv /etc/nginx/ /root/
4 Linux 常用命令(三)压缩和解压缩命令
在Linux中可以识别的常见压缩格式有十几种,比如.zip .gz .bz2 .tar .tar.gz .tar.bz2等。
4.1 .zip格式
4.1.1 .zip格式的压缩命令
压缩命令就是zip,其基本信息如下。
-
命令名称:zip。
-
英文原意:package and compress (archive) files。
-
所在路径:/usr/bin/zip。
-
执行权限:所有用户。
功能描述:压缩文件或目录。
[root@localhost ~]# zip [选项] [压缩包名] [源文件或源目录]
选项:
-r: 压缩目录示例:
[root@localhost ~]# zip ana.zip anaconda-ks.cfg4.1.2 .zip格式的解压缩命令
.zip格式的解压缩命令是unzip,其基本信息如下。
-
命令名称:unzip。
-
英文原意:list, test and extract compressed files in a ZIP archive。
-
所在路径:/usr/bin/unzip。
-
执行权限:所有用户。
功能描述:列表、测试和提取压缩文件中的文件。
[root@localhost ~]# unzip [选项] [压缩包名]
选项:
-d: 指定解压缩位置示例:
[root@localhost ~]# unzip -d /tmp/ ana.zip4.2 .gz格式
4.2.1 .gz格式的压缩命令
.gz格式是Linux中最常用的压缩格式,使用gzip命令进行压缩,其基本信息如下。
-
命令名称:gzip。
-
英文原意:compress or expand files。
-
所在路径:/bin/gzip。
-
执行权限:所有用户。
功能描述:压缩文件或目录。
[root@localhost ~]# gzip [选项] [源文件]
选项:
-c: 将压缩数据输出到标准输出中,可以用于保留源文件
-d: 解压缩
-r: 压缩目录示例:
[root@localhost ~]# gzip -c anaconda-ks.cfg > anaconda-ks.cfg.gz
#使用-c选项,但是不让压缩数据输出到屏幕上,而是重定向到压缩文件中
#这样可以在压缩文件的同时不删除源文件4.2.2 .gz格式的解压缩命令
如果要解压缩.gz格式,那么使用gzip -d 压缩包和gunzip 压缩包命令都可以。其基本信息如下。
-
命令名称:gunzip。
-
英文原意:compress or expand files。
-
所在路径:/bin/gunzip。
-
执行权限:所有用户。
功能描述:解压缩文件或目录。
[root@localhost ~]# gzip [选项] [源文件]
选项:
-d: 解压缩
[root@localhost ~]# gunzip [选项] [源文件]示例:
[root@localhost ~]# gunzip install.log.gz
[root@localhost ~]# gzip -d anaconda-ks.cfg.gz4.3 .bz2格式
4.3.1 .bz2格式的压缩命令
.bz2格式是Linux的另一种压缩格式,从理论上来讲,.bz2格式的算法更先进、压缩比更好;而.gz格式相对来讲压缩的时间更快。只支持压缩文件,并不支持压缩目录,.bz2格式的压缩命令是bzip2,其基本信息如下。
-
命令名称:bzip2。
-
英文原意:a block-sorting file compressor。
-
所在路径:/usr/bin/bzip2。
-
执行权限:所有用户。
功能描述:.bz2格式的压缩命令。
[root@localhost ~]# bzip2 [选项] [源文件]
选项:
-k: 压缩时,保留源文件
-v: 显示压缩的详细信息示例:
[root@localhost ~]# bzip2 anaconda-ks.cfg #压缩成.bz2格式
[root@localhost ~]# bzip2 -k install.log.syslog #保留源文件压缩4.3.2 .bz2格式的解压缩命令
.bz2格式可以使用“bzip2 -d 压缩包”命令来进行解压缩,也可以使用“bunzip2 压缩包”命令来进行解压缩。其基本信息如下。
-
命令名称:bunzip2。
-
英文原意:a block-sorting file compressor。
-
所在路径:/usr/bin/bunzip2。
-
执行权限:所有用户。
功能描述:.bz2格式的解压缩命令。
[root@localhost ~]# bzip2 [选项] [源文件]
选项:
-d: 解压缩
-v: 显示压缩的详细信息示例:
[root@localhost ~]# bunzip2 anaconda-ks.cfg.bz2
[root@localhost ~]# bzip2 -d install.log.syslog.bz24.4 .tar格式
4.4.1 .tar格式的打包命令
.tar格式的打包和解打包都使用tar命令,区别只是选项不同。其基本信息如下。
-
命令名称:tar。
-
英文原意:tar。
-
所在路径:/bin/tar。
-
执行权限:所有用户。
功能描述:打包与解打包命令。
[root@localhost ~]# tar [选项] [-f 压缩包名] [源文件或目录]
选项:
-z:通过gzip指令处理备份文件
-j:通过bzip指令处理备份文件
-c: 打包
-f: 指定压缩包的文件名。压缩包的扩展名是用来给管理员识别格式的,所以一定要正确指定扩展名
-v: 显示打包文件过程示例:
[root@localhost ~]# tar -zcvf anaconda-ks.cfg.tar anaconda-ks.cfg #打包,不会压缩4.4.2 .tar格式的解打包命令
.tar格式的解打包也需要使用tar命令,但是选项不太一样。命令格式如下:
[root@localhost ~]# tar [选项] [压缩包]
选项:
-z:通过gzip指令处理备份文件
-j:通过bzip指令处理备份文件
-x: 解打包
-f: 指定压缩包的文件名
-v: 显示解打包文件过程
-t: 测试,就是不解打包,只是查看包中有哪些文件
-C(大) 目录:指定解打包位置示例:
[root@localhost ~]# tar -zxvf anaconda-ks.cfg.tar
5 Linux 常用命令(四)搜索命令
5.1 whereis命令
whereis是搜索系统命令的命令,也就是说,whereis命令不能搜索普通文件,而只能搜索系统命令。其基本信息如下。
-
命令名称:whereis。
-
英文原意:locate the binary, source, and manual page files for a command。
-
所在路径:/usr/bin/whereis。
-
执行权限:所有用户。
功能描述:查找二进制命令、源文件和帮助文档的命令。
[root@localhost ~]# whereis [选项] [命令]示例:
[root@localhost ~]# whereis ls
ls: /usr/bin/ls /usr/share/man/man1/ls.1.gz5.2 which命令
which命令的基本信息如下。
-
命令名称:which。
-
英文原意:shows the full path of (shell) commands。
-
所在路径:/usr/bin/which。
-
执行权限:所有用户。
功能描述:列出命令的所在路径。
[root@localhost ~]# which [选项] [命令]
选项:
-n 指定文件名长度,指定的长度必须大于或等于所有文件中最长的文件名。
-p 与-n参数相同,但此处的包括了文件的路径。
-w 指定输出时栏位的宽度。
-V 显示版本信息示例:
[root@localhost ~]# which ls
alias ls='ls --color=auto'
/usr/bin/ls5.3 find命令
find命令的基本信息如下。
-
命令名称:find。
-
英文原意:search for files in a directory hierarchy。
-
所在路径:/bin/find。
-
执行权限:所有用户。
功能描述:在目录中搜索文件。
[root@localhost ~]# find [搜索路径] [选项] [搜索内容]
选项:
-name: 按照文件名搜索
-iname: 按照文件名搜索,不区分文件名大小写
-inum: 按照inode号搜索
-size: 大小:
-atime [+|-]时间: 按照文件访问时间搜索
-mtime [+|-]时间: 按照文件数据修改时间搜索
-ctime [+|-]时间: 按照文件状态修改时间搜索
-perm 权限模式: 查找文件权限刚好等于“权限模式”的文件
-perm -权限模式: 查找文件权限全部包含“权限模式”的文件
-perm +权限模式: 查找文件权限包含“权限模式”的任意一个权限的文件
-uid 用户ID: 按照用户ID查找所有者是指定ID的文件
-gid 组ID: 按照用户组ID查找所属组是指定ID的文件
-user 用户名: 按照用户名查找所有者是指定用户的文件
-group 组名: 按照组名查找所属组是指定用户组的文件
-nouser: 查找没有所有者的文件
-type d: 查找目录
-type f: 查找普通文件
-type l: 查找软链接文件选项:示例:
[root@localhost ~]# find / -name nginx.conf
/etc/nginx/nginx.confxargs 命令 – 给其他命令传参数的过滤器
常用参数:
| -n | 多行输出 |
|---|---|
| -d | 自定义一个定界符 |
| -I | 指定一个替换字符串{} |
| -t | 打印出 xargs 执行的命令 |
| -p | 执行每一个命令时弹出确认 |
# 例 1:找出 / 目录下以 .conf 结尾的文件,并进行文件分类
find / -name *.conf -type f -print | xargs file
# 配合 tar 命令将找出的文件直接打包
find / -name *.conf -type f -print | xargs tar cjf test.tar.gz
sort命令 – 对文件内容进行排序
常用参数:
| -b | 忽略每行前面开始出的空格字符 |
|---|---|
| -c | 检查文件是否已经按照顺序排序 |
| -d | 除字母、数字及空格字符外,忽略其他字符 |
| -f | 将小写字母视为大写字母 |
| -i | 除040至176之间的ASCII字符外,忽略其他字符 |
| -m | 将几个排序号的文件进行合并 |
| -M | 将前面3个字母依照月份的缩写进行排序 |
| -n | 依照数值的大小排序 |
| -o <输出文件> | 将排序后的结果存入制定的文件 |
| -r | 以相反的顺序来排序 |
| -t <分隔字符> | 指定排序时所用的栏位分隔字符 |
| -k | 指定需要排序的栏位 |
# 以冒号(:)为间隔符,对第3列进行排序:
sort -t : -k 3 -n /etc/passwd
# 输出的第 3 列为 CPU 的耗用百分比,最后一列就是对应的进程。
ps -aux | sort -rnk 3 | head -20
file命令 – 识别文件类型
常用参数:
| -b | 列出辨识结果时,不显示文件名称 (简要模式) |
|---|---|
| -c | 详细显示指令执行过程 |
| -f | 指定名称文件,显示多个文件类型信息 |
| -L | 直接显示符号连接所指向的文件类别 |
| -m | 指定魔法数字文件 |
| -v | 显示版本信息 |
| -z | 尝试去解读压缩文件的内容 |
| -i | 显示MIME类别 |
]# file /etc/kdump.conf
/etc/kdump.conf: ASCII text, with very long lines
5.4 grep命令:补充命令
grep的作用是在文件中提取和匹配符合条件的字符串行。
-
命令名称:grep
-
英文原意:Extract string information from file
-
所在路径: /usr/bin/grep
-
执行权限:所有用户
功能描述:提取文件中的字符串信息
[root@localhost ~]# grep [选项] [搜索内容] [文件名]
选项:
-i: 忽略大小写
-n: 输出行号
-v: 反向查找
--color=auto: 搜索出的关键字用颜色显示示例:
[root@VM-32-17-centos ~]# grep -in root /etc/passwd
1:root:x:0:0:root:/root:/bin/bash
10:operator:x:11:0:operator:/root:/sbin/nologin5.5 管道符:补充命令
命令格式: 命令1 | 命令2,命令1的正确输出作为命令2的操作对象
示例:
[root@localhost ~]# netstat -anput | grep 8080
tcp 0 0 172.17.32.17:57980 172.17.32.17:28080 TIME_WAIT -
tcp 0 0 172.17.32.17:49058 169.254.0.55:8080 TIME_WAIT -
tcp 0 0 172.17.32.17:59366 172.17.32.17:28080 ESTABLISHED 7744/nginx: worker 5.6 命令的别名:补充命令
命令的别名,就是命令的小名,主要是用于照顾管理员使用习惯的。
-
命令名称:alias
-
英文原意:Alias for the command
-
所在路径: /usr/bin/alias
-
执行权限:所有用户
功能描述:命令的别名。
[root@localhost ~]# alias
#查询命令别名
[root@localhost ~]# alias [别名]=['原命令']
#设定命令别名
[root@localhost ~]# unalias [别名]
#删除命令别名示例:
[root@localhost ~]# alias ser='systemctl restart network' #创建别名5.7 常用快捷键:补充命令
| 快捷键 | 作用 |
|---|---|
| Tab键 | 命令或文件补全 |
| Ctrl+A | 把光标移动到命令行开头 |
| Ctrl+E | 把光标移动到命令行结尾 |
| Ctrl+C | 强制终止当前的命令 |
| Ctrl+L | 清屏,相当于clear命令 |
| Ctrl+U | 删除或剪切光标之前的命令 |
| Ctrl+Y | 粘贴ctrl+U剪切的内容 |
5.8 which和whereis的区别
-
whereis命令可以在查找到二进制命令的同时,查找到帮助文档的位置;
-
而which命令在查找到二进制命令的同时,如果这个命令有别名,则还可以找到别名命令。
5.9 find命令和grep命令的区别
-
find命令用于在系统中搜索符合条件的文件名,如果需要模糊查询,则使用通配符进行匹配,通配符是完全匹配(find命令可以通过-regex选项,把匹配规则转为正则表达式规则,但是不建议如此)。
-
grep命令用于在文件中搜索符合条件的字符串,如果需要模糊查询,则使用正则表达式进行匹配,正则表达式是包含匹配。
5.10 通配符和正则表达式
通配符:用于匹配文件名,完全匹配
| 通配符 | 作用 |
|---|---|
| ? | 匹配一个任意字符 |
| * | 匹配0个或任意多个任意字符,也就是可以匹配任何内容 |
| [] | 匹配中括号中任意一个字符。例如,[abc]代表一定匹配一个字符,或者是a,或者是b,或者是c |
| [-] | 匹配中括号中任意一个字符,-代表一个范围。例如,[a-z]代表匹配一个小写字母 |
| [^] | 逻辑非,表示匹配不是中括号内的一个字符。例如,0-9代表匹配一个不是数字的字符 |
正则表达式:用于匹配字符串,包含匹配
| 正则符 | 作用 |
|---|---|
| ? | 匹配前一个字符重复0次,或1次(?是扩展正则,需要使用egrep命令) |
| * | 匹配前一个字符重复0次,或任意多次 |
| [] | 匹配中括号中任意一个字符。例如,[abc]代表一定匹配一个字符,或者是a,或者是b,或者是c |
| [-] | 匹配中括号中任意一个字符,-代表一个范围。例如,[a-z]代表匹配一个小写字母 |
| [^] | 逻辑非,表示匹配不是中括号内的一个字符。例如,^0-9代表匹配一个不是数字的字符 |
| ^ | 匹配行首 |
| $ | 匹配行尾 |
6 Linux 常用命令(五)常用网络命令
6.1 ifconfig命令
ifconfig命令最主要的作用就是查看IP地址的信息,直接输入ifconfig命令即可。在CentOS 7.x中ifconfig命令默认没有安装,如果需要使用,需要安装net-tools软件包。
-
命令名称:ifconfig。
-
英文原意:configure a network interface。
-
所在路径:/sbin/ifconfig。
-
执行权限:超级用户。
功能描述:配置网络接口。
[root@localhost ~]# ifconfig示例:
[root@localhost ~]# ifconfig
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
#标志 最大传输单元
inet 172.17.32.17 netmask 255.255.240.0 broadcast 172.17.47.255
#IP地址 子网掩码 广播地址
inet6 fe80::5054:ff:fe87:22ab prefixlen 64 scopeid 0x20<link>
#IPv6地址(目前没有生效)
ether 52:54:00:87:22:ab txqueuelen 1000 (Ethernet)
#MAC地址
RX packets 181113 bytes 21611036 (20.6 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
#接收的数据包情况
TX packets 181670 bytes 32158693 (30.6 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
#发送的数据包情况
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
#本地回环网卡
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1000 (Local Loopback)
RX packets 34377459 bytes 7285224334 (6.7 GiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 34377459 bytes 7285224334 (6.7 GiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 06.2 ping命令
ping是常用的网络命令,主要通过ICMP协议进行网络探测,测试网络中主机的通信情况。其基本信息如下。
-
命令名称:ping。
-
英文原意:send ICMP ECHO_REQUEST to network hosts。
-
所在路径:/bin/ping。
-
执行权限:所有用户。
功能描述:向网络主机发送ICMP请求。
参数 作用
-c 总共发送次数
-i 每次间隔时间(秒)
-W 最长等待时间(秒)
-l 指定网卡名称
[root@localhost ~]# ping [选项] [ip地址或域名]
选项:
-b: 后面加入广播地址,用于对整个网段进行探测
-c 次数: 用于指定ping的次数
-s 字节: 指定探测包的大小示例:
[root@localhost ~]# ping -b -c 3 www.baidu.com6.3 netstat命令
netstat是网络状态查看命令,既可以查看到本机开启的端口,也可以查看有哪些客户端连接。在CentOS 7.x中netstat命令默认没有安装,如果需要使用,需要安装net-snmp和net-tools软件包。
-
命令名称:netstat。
-
英文原意:Print network connections, routing tables, interface statistics, masquerade connections, and multicast memberships。
-
所在路径:/bin/netstat。
-
执行权限:所有用户。
功能描述:输出网络连接、路由表、接口统计、伪装连接和组播成员。
[root@localhost ~]# netstat [选项]
选项:
-a: 列出所有网络状态,包括Socket程序
-c 秒数: 指定每隔几秒刷新一次网络状态
-n: 使用IP地址和端口号显示,不使用域名与服务名
-p: 显示PID和程序名
-t: 显示使用TCP协议端口的连接状况
-u: 显示使用UDP协议端口的连接状况
-l: 仅显示监听状态的连接
-r: 显示路由表示例:
[root@localhost ~]# netstat -anput
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
#协议 接收队列 发送队列 本机的IP地址:端口号 远程主机的IP:端口号 状态 PID/程序名
tcp 0 0 127.0.0.1:19206 0.0.0.0:* LISTEN 4185/yudian_websvr
tcp 0 0 172.17.32.17:20006 0.0.0.0:* LISTEN 3399/SrvMgr
tcp 0 0 172.17.32.17:28070 0.0.0.0:* LISTEN 3048/conn_mgr
tcp 0 0 127.0.0.1:19207 0.0.0.0:* LISTEN 4264/yudian_websvr
tcp 0 0 127.0.0.1:19208 0.0.0.0:* LISTEN 4211/yudian_websvr
tcp 0 0 172.17.32.17:8008 0.0.0.0:* LISTEN 1161/python3 这个命令的输出较多。
-
Proto:网络连接的协议,一般就是TCP协议或者UDP协议。
-
Recv-Q:表示接收到的数据,已经在本地的缓冲中,但是还没有被进程取走。
-
Send-Q:表示从本机发送,对方还没有收到的数据,依然在本地的缓冲中,一般是不具备ACK标志的数据包。
-
Local Address:本机的IP地址和端口号。
-
Foreign Address:远程主机的IP地址和端口号。
-
State:状态。常见的状态主要有以下几种。
-
LISTEN:监听状态,只有TCP协议需要监听,而UDP协议不需要监听。
-
ESTABLISHED:已经建立连接的状态。如果使用“-l”选项,则看不到已经建立连接的状态。
-
SYN_SENT:SYN发起包,就是主动发起连接的数据包。
-
SYN_RECV:接收到主动连接的数据包。
-
FIN_WAIT1:正在中断的连接。
-
FIN_WAIT2:已经中断的连接,但是正在等待对方主机进行确认。
-
TIME_WAIT:连接已经中断,但是套接字依然在网络中等待结束。
-
CLOSED:套接字没有被使用。
-
在这些状态中,我们最常用的就是LISTEN和ESTABLISHED状态,一种代表正在监听,另一种代表已经建立连接。
6.4 write命令
write命令用于给指定用户发送信息
-
命令名称:write。
-
英文原意:send a message to all user。
-
所在路径:/usr/bin/write。
-
执行权限:所有用户。
功能描述:向其他用户发送信息
[root@localhost ~]# write [用户名] [远程终端]
# 消息内容示例:
[root@localhost ~]#write user1 pts/1
hello
I will be in 5 minutes to restart, please save your data6.5 wall命令
wall命令用于给所有登录用户发送信息
-
命令名称:wall。
-
英文原意:send a message to another user。
-
所在路径:/usr/bin/wall。
-
执行权限:所有用户。
功能描述:向所有用户发送信息
[root@localhost ~]# wall [消息内容]示例:
[root@localhost ~]# wall "I will be in 5 minutes to restart, please save your data"6.6 telnet命令
telnet一般用于检测目标端口是否开放,在CentOS 7.x中netstat命令默认没有安装,如果需要使用,需要安装telnet软件包。
-
命令名称:telnet
-
英文原意:send a message to another user
-
所在路径:/usr/bin/telnet
-
执行权限:所有用户
功能描述:检测服务器端口是否开放
[root@localhost ~]# telnet [ip地址] [端口]示例:
[root@localhost ~]# telenet 192.168.5.5 56
6.7 IO性能工具
top命令
原文链接:https://blog.csdn.net/langzi6/article/details/124805024
| 选项 | 功能 |
|---|---|
| -d | 指定每两次屏幕信息刷新之间的时间间隔,如希望每秒刷新一次,则使用:top -d 1 |
| -p | 通过指定PID来仅仅监控某个进程的状态 |
| -S | 指定累计模式 |
| -s | 使top命令在安全模式中运行。这将去除交互命令所带来的潜在危险 |
| -i | 使top不显示任何闲置或者僵死的进程 |
| -c | 显示整个命令行而不只是显示命令名 |
第1行:系统时间、运行时间、登录终端数、系统负载(3个数值分别为1分钟、5分钟、15分钟内的平均值,数值越小意味着负载越低)。
第2行:进程总数、运行中的进程数、睡眠中的进程数、停止的进程数、僵死的进程数。
第3行:用户占用资源百分比、系统内核占用资源百分比、改变过优先级的进程资源百分比、空闲的资源百分比等。其中数据均为CPU数据并以百分比格式显示,例如“99.9 id”意味着有99.9%的CPU处理器资源处于空闲。
第4行:物理内存总量、内存空闲量、内存使用量、作为内核缓存的内存量。
第5行:虚拟内存总量、虚拟内存空闲量、虚拟内存使用量、已被提前加载的内存量。
第一行:
top - 16:20:38 up 12 days, 5:24, 2 users, load average: 0.04, 0.03, 0.05top:当前时间 up:机器运行了多长时间 users:当前登录用户数 load average:系统负载,即任务队列的平均长度。三个数值分别为 1分钟、5分钟、15分钟前到现在的平均值。
第二行:
Tasks: 127 total, 1 running, 126 sleeping, 0 stopped, 0 zombieTasks:当前有多少进程 running:正在运行的进程数 sleeping:正在休眠的进程数 stopped:停止的进程数 zombie:僵尸进程数 这里running越多,服务器自然压力就越大。
第三行:
%Cpu(s): 0.3 us, 0.7 sy, 0.0 ni, 99.0 id, 0.0 wa, 0.0 hi, 0.0si, 0.0 stus:用户空间占CPU的百分比(像shell程序、各种语言的编译器、各种应用、web服务器和各种桌面应用都算是运行在用户地址空间的进程,这些程序如果不是处于idle状态,那么绝大多数的CPU时间都是运行在用户态) sy: 内核空间占CPU的百分比(所有进程要使用的系统资源都是由Linux内核处理的,对于操作系统的设计来说,消耗在内核态的时间应该是越少越好,在实践中有一类典型的情况会使sy变大,那就是大量的IO操作,因此在调查IO相关的问题时需要着重关注它) ni:用户进程空间改变过优先级(ni是nice的缩写,可以通过nice值调整进程用户态的优先级,这里显示的ni表示调整过nice值的进程消耗掉的CPU时间,如果系统中没有进程被调整过nice值,那么ni就显示为0) id: 空闲CPU占用率 wa: 等待输入输出的CPU时间百分比(和CPU的处理速度相比,磁盘IO操作是非常慢的,有很多这样的操作,比如,CPU在启动一个磁盘读写操作后,需要等待磁盘读写操作的结果。在磁盘读写操作完成前,CPU只能处于空闲状态。Linux系统在计算系统平均负载时会把CPU等待IO操作的时间也计算进去,所以在我们看到系统平均负载过高时,可以通过wa来判断系统的性能瓶颈是不是过多的IO操作造成的) hi: 硬中断占用百分比(硬中断是硬盘、网卡等硬件设备发送给CPU的中断消息,当CPU收到中断消息后需要进行适当的处理(消耗CPU时间)。) si:软中断占用百分比(软中断是由程序发出的中断,最终也会执行相应的处理程序,消耗CPU时间) st:steal time 第四行:
KiB Mem : 1863012 total, 1286408 free, 216532 used, 360072 buff/cachetotal:物理内存总量 free:空闲内存量 used:使用的内存量 buffer/cache:用作内核缓存的内存量 第五行:
KiB Swap: 5242876 total, 7999484 free, 0 used. 1468240 avail Memtotal:交换区内存总量 free:空闲交换区总量 used:使用的交换区总量 buffer/cache:缓冲的交换区总量
-
第四第五行分别是
-
当物理内存不够用的时候,操作系统才会把暂时不用的数据放到Swap中。所以当这个数值变高的时候,说明内存是真的不够用了。
进程信息
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
21829 root 20 0 0 0 0 S 0.7 0.6 129:53.91 java
22559 root 20 0 158920 5628 4268 S 0.3 9.2 139:42.81 java
22598 root 20 0 162112 2208 1540 S 0.3 0.1 0:04.68 fluentd
PID 进程id
USER 进程所有者的用户名
PR 优先级
NI nice值,负值表示高优先级,正值表示低优先级
VIRT 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES
RES 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA
SHR 共享内存大小,单位kb
S 进程状态。D=不可中断的睡眠状态 R=运行 S=睡眠 T=跟踪/停止 Z=僵尸进程
%CPU 上次更新到现在的CPU时间占用百分比
%MEM 进程使用的物理内存百分比
TIME+ 进程使用的CPU时间总计,单位1/100秒
COMMAND 命令名/命令行
sar分析系统性能
原文链接:https://blog.csdn.net/weixin_67510296/article/details/125207042
sar 命令很强大,是分析系统性能的重要工具之一,通过该命令可以全面地获取系统的 CPU、运行队列、磁盘读写(I/O)、分区(交换区)、内存、CPU 中断和网络等性能数据。
| 显示内存状态 | -R |
|---|---|
| 显示I/O速率 | -b |
| 显示换页状态 | -B |
| 显示每个块设备的状态 | -d |
| 状态信息刷新的间隔时间 | -i |
| 显示CPU利用率 | -u |
1. *查看网卡流量*
$ sar -n DEV 1 100 # 查看网卡流量,每秒间隔,输出100次。
| IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s |
|---|
| lo 103.81 103.81 51.24 51.24 0.00 0.00 0.00 |
| eth0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 |
| eth1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 |
| eth2 24020.33 21142.79 30249.59 25842.84 0.00 0.00 0.00 |
| eth3 0.00 0.00 0.00 0.00 0.00 0.00 0.00 |
| eth4 0.15 0.00 0.01 0.00 0.00 0.00 0.00 |
| eth5 0.00 0.00 0.00 0.00 0.00 0.00 0.00 |
| eth6 10.55 2.03 0.73 1.60 0.00 0.00 0.08 |
| eth7 8.62 0.00 0.56 0.00 0.00 0.00 0.08 |
| eth8 0.00 0.00 0.00 0.00 0.00 0.00 0.00 |
| eth9 0.00 0.00 0.00 0.00 0.00 0.00 0.00 |
| bond0 19.17 2.03 1.29 1.60 0.00 0.00 0.16 |
| bond1 24020.48 21142.79 30249.60 25842.84 0.00 0.00 0.00 |
rxpck/s 和 txpck/s 分别是接收和发送的 PPS,单位为包 / 秒。
rxkB/s 和 txkB/s 分别是接收和发送的吞吐量,单位是 KB/ 秒。
rxcmp/s 和 txcmp/s 分别是接收和发送的压缩数据包数,单位是包 / 秒。
默认监控: sar 1 1 // CPU和IOWAIT统计状态
(1) sar -b 1 1 // IO传送速率
(2) sar -B 1 1 // 页交换速率
(3) sar -c 1 1 // 进程创建的速率
(4) sar -d 1 1 // 块设备的活跃信息
(5) sar -n DEV 1 1 // 网路设备的状态信息
(6) sar -n SOCK 1 1 // SOCK的使用情况
(7) sar -n ALL 1 1 // 所有的网络状态信息
(8) sar -P ALL 1 1 // 每颗CPU的使用状态信息和IOWAIT统计状态
(9) sar -q 1 1 // 队列的长度(等待运行的进程数)和负载的状态
(10) sar -r 1 1 // 内存和swap空间使用情况
(11) sar -R 1 1 // 内存的统计信息(内存页的分配和释放、系统每秒作为BUFFER使用内存页、每秒被cache到的内存页)
(12) sar -u 1 1 // CPU的使用情况和IOWAIT信息(同默认监控)
(13) sar -v 1 1 // inode, file and other kernel tablesd的状态信息
(14) sar -w 1 1 // 每秒上下文交换的数目
(15) sar -W 1 1 // SWAP交换的统计信息(监控状态同iostat 的si so)
(16) sar -x 2906 1 1 // 显示指定进程(2906)的统计信息,信息包括:进程造成的错误、用户级和系统级用户CPU的占用情况、运行在哪颗CPU上
(17) sar -y 1 1 // TTY设备的活动状态
(18) 将结果输出到文件(-o)和读取记录信息(-f)
(19) sar -h // 查看帮助
free命令
显示系统内存使用量情况
| -b | 以Byte显示内存使用情况 |
|---|---|
| -k | 以kb为单位显示内存使用情况 |
| -m | 以mb为单位显示内存使用情况 |
| -g | 以gb为单位显示内存使用情况 |
| -s | 持续显示内存 |
| -t | 显示内存使用总合 |
| -h | 以易读的单位显示内存使用情况 |
[root@localhost ~]# free -h
total used free shared buff/cache available
Mem: 972M 165M 121M 7.7M 685M 649M
Swap: 2.0G 264K 2.0G
#以易读的单位显示内存使用量信息,每个10秒刷新一次:
[root@localhost ~]# free -hs
nice进程优先级
nice命令用于调整进程的优先级,语法格式为“nice优先级数字 服务名称”。
在top命令输出的结果中,PR和NI值代表的是进程的优先级,数字越低(取值范围是-20~19),优先级越高。在日常的生产工作中,可以将一些不重要进程的优先级调低,让紧迫的服务更多地利用CPU和内存资源,以达到合理分配系统资源的目的。
例如将bash服务的优先级调整到最高:
*]# nice -n -20 bash*
查看网卡速率
]# ethtool eth2 | grep Speed
Speed: 10000Mb/s
]# ethtool eth6 | grep Speed
Speed: 1000Mb/s
# ethtool ethX //查询ethX网口基本设置
# ethtool –h //显示ethtool的命令帮助(help)
# ethtool –i ethX //查询ethX网口的相关信息
# ethtool –d ethX //查询ethX网口注册性信息
# ethtool –r ethX //重置ethX网口到自适应模式
# ethtool –S ethX //查询ethX网口收发包统计
# ethtool –s ethX [speed 10|100|1000]\ //设置网口速率10/100/1000M
[duplex half|full]\ //设置网口半/全双工
[autoneg on|off]\ //设置网口是否自协商
[port tp|aui|bnc|mii]\ //设置网口类型
7 Linux 常用命令(六)系统记录命令
系统中有一些重要的痕迹日志文件,如/var/log/wtmp、/var/run/utmp、/var/log/btmp、/var/log/lastlog等日志文件,如果你用vim打开这些文件,你会发现这些文件是二进制乱码。
这是由于这些日志中保存的是系统的重要登录痕迹,包括某个用户何时登录了系统,何时退出了系统,错误登录等重要的系统信息。
这些信息要是可以通过vim打开,就能编辑,这样痕迹信息就不准确,所以这些重要的痕迹日志,只能通过对应的命令来进行查看。
7.1 w命令
w命令是显示系统中正在登陆的用户信息的命令,这个命令查看的痕迹日志是/var/run/utmp。其基本信息如下
-
命令名称:w
-
英文原意:Show who is logged on and what they are doing.
-
所在路径:/usr/bin/w
-
执行权限:所有用户
功能描述:显示登录用户,查看其操作信息等
[root@localhost ~]# w示例:
[root@localhost ~]# w
09:54:24 up 5:53, 1 user, load average: 0.19, 0.27, 0.27
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
root pts/0 116.228.98.118 09:52 0.00s 0.01s 0.00s w第一行信息,内容如下:
| 内容 | 说明 |
|---|---|
| 09:54:24 | 系统当前时间 |
| up 5:53, | 系统的运行时间,本机已经运行5小时53分钟 |
| 1 user | 当前登录了一个用户 |
| oad average: 0.19, 0.27, 0.27 | 统在之前1分钟、5分钟、15分钟的平均负载。 如果CPU是单核的,则这个数值超过1就是高负载; 如果CPU是四核的,则这个数值超过4就是高负载 (这个平均负载完全是依据个人经验来进行判断的,一般认为不应该超过服务器CPU的核数) |
第二行信息,内容如下:
| 内容 | 说明 |
|---|---|
| USER | 当前登陆的用户 |
| TTY | 登陆的终端: tty1-6:本地字符终端(alt+F1-6切换) tty7:本地图形终端(ctrl+alt+F7切换,必须安装启动图形界面) pts/0-255:远程终端 |
| FROM | 登陆的IP地址,如果是本地终端,则是空 |
| LOGIN@ | 登陆时间 |
| IDLE | 用户闲置时间 |
| JCPU | 所有的进程占用的CPU时间 |
| PCPU | 当前进程占用的CPU时间 |
| WHAT | 用户正在进行的操作 |
7.2 who命令
who命令和w命令类似,用于查看正在登陆的用户,但是显示的内容更加简单,也是查看/var/run/utmp日志。
-
命令名称:who
-
英文原意:Show who is logged on and what they are doing.
-
所在路径:/usr/bin/who
-
执行权限:所有用户
功能描述:显示登录用户,查看其操作信息等
[root@localhost ~]# who示例:
[root@localhost ~]# who
root pts/0 2021-06-03 09:52 (116.228.98.118)7.3 last命令
last命令是查看系统所有登陆过的用户信息的,包括正在登陆的用户和之前登陆的用户。这个命令查看的是/var/log/wtmp痕迹日志文件。
命令名称:last
英文原意:View the history information of all logged in users.
所在路径:/usr/bin/last
执行权限:所有用户
功能描述:查看系统所有登陆过的用户历史信息
[root@localhost ~]# last示例:
[root@localhost ~]# last
root pts/0 116.228.98.118 Thu Jun 3 09:52 still logged in
reboot system boot 3.10.0-1160.11.1 Thu Jun 3 04:00 - 10:09 (06:09)
reboot system boot 3.10.0-1160.11.1 Wed Jun 2 04:00 - 10:09 (1+06:09)
#系统重启信息记录
root pts/0 116.228.98.118 Mon May 31 09:39 - 09:39 (00:00)
#用户名 终端号 来源IP地址 登陆时间 - 退出时间7.4 lastlog命令
lastlog命令是查看系统中所有用户最后一次的登陆时间的命令,他查看的日志是/var/log/lastlog文件。
-
命令名称:lastlog
-
英文原意:Check the last time a specific user logged in.
-
所在路径:/usr/bin/lastlog
-
执行权限:所有用户
功能描述:检查某特定用户上次登录的时间
[root@localhost ~]# lastlog [选项]
选项:
-b<天数>:显示指定天数前的登录信息;
-h:显示召集令的帮助信息;
-t<天数>:显示指定天数以来的登录信息;
-u<用户名>:显示指定用户的最近登录信息。示例:
[root@localhost ~]# lastlog
Username Port From Latest
root pts/0 116.228.98.118 Thu Jun 3 09:52:50 +0800 2021
bin **Never logged in**
daemon **Never logged in**
adm **Never logged in**
lp **Never logged in**
sync **Never logged in**
shutdown **Never logged in**7.5 lastb命令
lastb命令是查看错误登陆的信息的,查看的是/var/log/btmp痕迹日志:
-
命令名称:lastb
-
英文原意:View the information of wrong login.
-
所在路径:/usr/bin/lastb
-
执行权限:所有用户
功能描述:查看错误登陆的信息
[root@localhost ~]# lastb示例:
[root@localhost ~]# lastb
tomcat ssh:notty 95.111.236.177 Tue Jun 1 03:24 - 03:24 (00:00)
tomcat ssh:notty 95.111.236.177 Tue Jun 1 03:24 - 03:24 (00:00)
user ssh:notty 128.199.6.217 Tue Jun 1 03:24 - 03:24 (00:00)
user ssh:notty 128.199.6.217 Tue Jun 1 03:24 - 03:24 (00:00)
nominati ssh:notty 1.116.139.160 Tue Jun 1 03:24 - 03:24 (00:00)
nominati ssh:notty 1.116.139.160 Tue Jun 1 03:24 - 03:24 (00:00)
user ssh:notty 128.199.6.217 Tue Jun 1 03:23 - 03:23 (00:00)
user ssh:notty 128.199.6.217 Tue Jun 1 03:23 - 03:23 (00:00)
nominati ssh:notty 1.116.139.160 Tue Jun 1 03:23 - 03:23 (00:00)
nominati ssh:notty 1.116.139.160 Tue Jun 1 03:23 - 03:23 (00:00)
user ssh:notty 128.199.6.217 Tue Jun 1 03:23 - 03:23 (00:00)
8 Linux 常用命令(七)挂载命令
8.1 mount命令基本格式
linux所有存储设备都必须挂载使用,包括硬盘
命令名称:mount
命令所在路径:/bin/mount
执行权限:所有用户
命令格式如下:
[root@localhost ~]# mount [-l]
#查询系统中已经挂载的设备,-l会显示卷标名称
[root@localhost ~]# mount –a
#依据配置文件/etc/fstab的内容,自动挂载
[root@localhost ~]# mount [-t 文件系统] [-L 卷标名] [-o 特殊选项] \
设备文件名 挂载点
#\代表这一行没有写完,换行
选项:
-t 文件系统: 加入文件系统类型来指定挂载的类型,可以ext3、ext4、iso9660 等文件系统。具体可以参考表9-1
-L 卷标名: 挂载指定卷标的分区,而不是安装设备文件名挂载
-o 特殊选项: 可以指定挂载的额外选项,比如读写权限、同步异步等,如果不指定则默认值生效。具体的特殊选项| 参数 | 说明 |
|---|---|
| atime/noatime | 更新访问时间/不更新访问时间。访问分区文件时,是否更新文件的访问时间,默认为更新 |
| async/sync | 异步/同步,默认为异步 |
| auto/noauto | 自动/手动,mount –a命令执行时,是否会自动安装/etc/fstab文件内容挂载,默认为自动 |
| defaults | 定义默认值,相当于rw,suid,dev,exec,auto,nouser,async这七个选项 |
| exec/noexec | 执行/不执行,设定是否允许在文件系统中执行可执行文件,默认是exec允许 |
| remount | 重新挂载已经挂载的文件系统,一般用于指定修改特殊权限 |
| rw/ro | 读写/只读,文件系统挂载时,是否具有读写权限,默认是rw |
| suid/nosuid | 具有/不具有SUID权限,设定文件系统是否具有SUID和SGID的权限,默认是具有 |
| user/nouser | 允许/不允许普通用户挂载,设定文件系统是否允许普通用户挂载, 默认是不允许,只有root可以挂载分区 |
| usrquota | 写入代表文件系统支持用户磁盘配额,默认不支持 |
| grpquota | 写入代表文件系统支持组磁盘配额,默认不支持 |
示例:
例1:
[root@localhost ~]# mount
#查看系统中已经挂载的文件系统,注意有虚拟文件系统
/dev/sda3 on / type ext4 (rw)
proc on /proc type proc (rw)
sysfs on /sys type sysfs (rw)
devpts on /dev/pts type devpts (rw,gid=5,mode=620)
tmpfs on /dev/shm type tmpfs (rw)
/dev/sda1 on /boot type ext4 (rw)
none on /proc/sys/fs/binfmt_misc type binfmt_misc (rw)
sunrpc on /var/lib/nfs/rpc_pipefs type rpc_pipefs (rw)
#命令结果是代表:/dev/sda3分区挂载到/目录,文件系统是ext4,权限是读写
例2:修改特殊权限
[root@localhost ~]# mount
#我们查看到/boot分区已经被挂载,而且采用的defaults选项,那么我们重新挂载分区,并采用noexec
#权限禁止执行文件执行,看看会出现什么情况(注意不要用/分区做试验,#不然系统命令也不能执行了)。
…省略部分输出…
/dev/sda1 on /boot type ext4 (rw)
…省略部分输出…
[root@localhost ~]# mount -o remount,noexec /boot
#重新挂载/boot分区,并使用noexec权限
[root@localhost sh]# cd /boot/
[root@localhost boot]# vi hello.sh
#写个shell吧
#!/bin/bash
echo "hello!!"
[root@localhost boot]# chmod 755 hello.sh
[root@localhost boot]# ./hello.sh
-bash: ./hello.sh: 权限不够
#虽然赋予了hello.sh执行权限,但是任然无法执行
[root@localhost boot]# mount -o remount,exec /boot
#记得改回来啊,要不会影响系统启动的
例3:挂载分区
[root@localhost ~]# mkdir /mnt/disk1
#建立挂载点目录
[root@localhost ~]# mount /dev/sdb1 /mnt/disk1
#挂载分区8.2 光盘挂载
光盘挂载的前提依然是指定光盘的设备文件名,不同版本的Linux,设备文件名并不相同:
-
CentOS 5.x以前的系统,光盘设备文件名是/dev/hdc
-
CentOS 6.x以后的系统,光盘设备文件名是/dev/sr0
不论哪个系统都有软连接/dev/cdrom,与可以作为光盘的设备文件名
[root@localhost ~]# mount -t iso9660 /dev/cdrom /mnt/cdrom/
#挂载光盘用完之后记得卸载:
[root@localhost ~]# umount /dev/sr0
[root@localhost ~]# umount /mnt/cdrom
#因为设备文件名和挂载点已经连接到一起,卸载哪一个都可以注意:卸载的时候需要退出光盘目录,才能正常卸载
8.3 挂载U盘
U盘会和硬盘共用设备文件名,所以U盘的设备文件名不是固定的,需要手工查询,查询命令:
[root@localhost ~]# fdisk -l
#查询硬盘然后就是挂载了,挂载命令如下:
[root@localhost ~]# mount -t vfat /dev/sdb1 /mnt/usb/
#挂载U盘。因为是Windows分区,所以是vfat文件系统格式如果U盘中有中文,会发现中文是乱码。Linux要想正常显示中文,需要两个条件:
-
安装了中文编码和中文字体
-
操作终端需要支持中文显示(纯字符终端,是不支持中文编码的)
而我们当前系统是安装了中文编码和字体,而xshell远程终端是Windows下的程序,当然是支持中文显示的。那之所以挂载U盘还出现乱码,是需要在挂载的时候,手工指定中文编码,例如:
[root@localhost ~]# mount -t vfat -o iocharset=utf8 /dev/sdb1 /mnt/usb/
#挂载U盘,指定中文编码格式为UTF-8如果需要卸载,可以执行以下命令:
[root@localhost ~]# umount /mnt/usb/8.4 挂载NTFS分区
8.4.1 Linux的驱动加载顺序:
-
驱动直接放入系统内核之中。这种驱动主要是系统启动加载必须的驱动,数量较少。
-
驱动以模块的形式放入硬盘。大多数驱动都已这种方式保存,保存位置在/lib/modules/3.10.0-862.el7.x86_64/kernel/中。
-
驱动可以被Linux识别,但是系统认为这种驱动一般不常用,默认不加载。如果需要加载这种驱动,需要重新编译内核,而NTFS文件系统的驱动就属于这种情况。
-
硬件不能被Linux内核识别,需要手工安装驱动。当然前提是厂商提供了该硬件针对Linux的驱动,否则就需要自己开发驱动了。
8.4.2 使用NTFS-3G安装NTFS文件系统模块
1)下载NTFS-3G插件
从网站http://www.tuxera.com/community/ntfs-3g-download/下载NTFS-3G插件到Linux服务器上
2)安装NTFS-3G插件
在编译安装NTFS-3G插件之前,要保证gcc编译器已经安装。具体安装命令如下:
[root@localhost ~]# tar -zxvf ntfs-3g_ntfsprogs-2013.1.13.tgz
#解压
[root@localhost ~]# cd ntfs-3g_ntfsprogs-2013.1.13
#进入解压目录
[root@localhost ntfs-3g_ntfsprogs-2013.1.13]# ./configure
#编译器准备。没有指定安装目录,安装到默认位置中
[root@localhost ntfs-3g_ntfsprogs-2013.1.13]# make
#编译
[root@localhost ntfs-3g_ntfsprogs-2013.1.13]# make install
#编译安装安装就完成了,已经可以挂载和使用Windows的NTFS分区了。不过需要注意挂载分区时的文件系统不是ntfs,而是ntfs-3g。挂载命令如下:
[root@localhost ~]# mount -t ntfs-3g 分区设备文件名 挂载点
例如:
[root@localhost ~]# mount –t ntfs-3g /dev/sdb1 /mnt/win
9 Linux 常用命令(八)关机和重启命令
9.1 sync数据同步
Linux sync命令用于数据同步,sync命令是在关闭Linux系统时使用的。
Linux 系统中欲写入硬盘的资料有的时候为了效率起见,会写到 filesystem buffer 中,这个 buffer 是一块记忆体空间,如果欲写入硬盘的资料存于此 buffer 中,而系统又突然断电的话,那么资料就会流失了,sync 指令会将存于 buffer 中的资料强制写入硬盘中。
sync命令的基本信息如下。
-
命令名称:sync。
-
英文原意:flush file system buffers。
-
所在路径:/bin/sync。
-
执行权限:所有用户。
功能描述:刷新文件系统缓冲区。
[root@localhost ~]# sync示例:
[root@localhost ~]# sync9.2 shutdown命令
shutdown 命令可以用来进行关机程序,并且在关机以前传送讯息给所有使用者正在执行的程序,shutdown 也可以用来重开机。其基本信息如下:
命令名称:shutdown。
英文原意:bring the system down。
所在路径:/sbin/shutdown。
执行权限:超级用户。
功能描述:关机和重启
[root@localhost ~]# shutdown [选项] [时间] [警告信息]
选项:
-c: 取消已经执行的shutdown命令
-h: 关机
-r: 重启示例:
[root@localhost ~]# shutdown -h 30 #指定30分钟后关机9.3 reboot命令
reboot命令用于用来重新启动计算机。
命令名称:reboot。
英文原意:bring the system restart。
所在路径:/sbin/reboot。
执行权限:超级用户。
功能描述:关机和重启
[root@localhost ~]# reboot示例:
[root@localhost ~]# reboot9.4 init命令
init是修改Linux运行级别的命令,也可以用于关机和重启。这个命令并不安全,不建议使用。
命令名称:init。
英文原意:Switch operation level。
所在路径:/sbin/init。
执行权限:超级用户。
功能描述:切换运行等级
[root@localhost ~]# init [运行等级]| 运行等级 | 描述 |
|---|---|
| init 0 | 关机 |
| init 1 | 单用户模式 |
| init 2 | 多用户,没有 NFS |
| init 3 | 完全多用户模式(标准的运行级) |
| init 4 | 没有用到 |
| init 5 | X11 (xwindow) 图形化界面模式 |
| init 6 | 重新启动 |
示例:
[root@localhost ~]# init 5 #切换到图形化界面模式9.5 halt和poweroff命令
这两个都是关机命令,直接执行即可。这两个命令不会完整关闭和保存系统的服务,不建议使用。
[root@localhost ~]# halt
#关机
[root@localhost ~]# poweroff
#关机
10 Linux 常用命令(九)帮助命令
10.1 man命令
man是最常见的帮助命令,也是Linux最主要的帮助命令,其基本信息如下。
-
命令名称:man。
-
英文原意:format and display the on-line manual pages。
-
所在路径:/usr/bin/man。
-
执行权限:所有用户。
功能描述:显示联机帮助手册。
[root@localhost ~]# man [选项] [命令]
选项:
-f: 查看命令拥有哪个级别的帮助
-k: 查看和命令相关的所有帮助示例:
[root@localhost ~]# man -f whatis #查看命令拥有哪个级别的帮助
[root@localhost ~]# man -k apropos #查看和命令相关的所有帮助man命令的快捷键
| 快捷键 | 作用 |
|---|---|
| 上箭头 | 向上移动一行 |
| 下箭头 | 向下移动一行 |
| PgUp | 向上翻一页 |
| PgDn | 向下翻一页 |
| g | 移动到第一页 |
| G | 移动到最后一页 |
| q | 退出 |
| /字符串 | 从当前页向下搜索字符串 |
| ?字符串 | 从当前页向上搜索字符串 |
| n | 当搜索字符串时,可以使用n键找到下一个字符串 |
| N | 当搜索字符串时,使用N键反向查询字符串。 也就是说,如果使用“/字符串”方式搜索,则N键表示向上搜索字符串; 如果使用“?字符串”方式搜索,则N键表示向下搜索字符串 |
man命令的帮助级别
| 级别 | 作用 |
|---|---|
| 1 | 普通用户可以执行的系统命令和可执行文件的帮助 |
| 2 | 内核可以调用的函数和工具的帮助 |
| 3 | C语言函数的帮助 |
| 4 | 设备和特殊文件的帮助 |
| 5 | 配置文件的帮助 |
| 6 | 游戏的帮助(个人版的Linux中是有游戏的) |
| 7 | 杂项的帮助 |
| 8 | 超级用户可以执行的系统命令的帮助 |
| 9 | 内核的帮助 |
10.2 info命令
info是最常见的帮助命令,也是Linux最主要的帮助命令,其基本信息如下。
-
命令名称:info。
-
英文原意:format and display the on-line manual pages。
-
所在路径:/usr/bin/info。
-
执行权限:所有用户。
功能描述:显示帮助信息。
[root@localhost ~]# info [命令]示例:
[root@localhost ~]# info lsinfo命令的快捷键
| 快捷键 | 作用 |
|---|---|
| 上箭头 | 向上移动一行 |
| 下箭头 | 向下移动一行 |
| PgUp | 向上翻一页 |
| PgDn | 向下翻一页 |
| Tab | 在有“*”符号的节点间进行切换 |
| 回车 | 进入有“*”符号的子页面,查看详细帮助信息 |
| u | 进入上一层信息(回车是进入下一层信息) |
| n | 进入下一小节信息 |
| p | 进入上一小节信息 |
| ? | 查看帮助信息 |
| q | 退出info信息 |
10.3 help命令
help只能获取Shell内置命令的帮助,其基本信息如下。
-
命令名称:help。
-
英文原意:help。
-
所在路径:Shell内置命令。
-
执行权限:所有用户。
功能描述:显示Shell内置命令的帮助。可以使用type命令来区分内置命令与外部命令
[root@localhost ~]# help [命令]示例:
[root@localhost ~]# help cd10.4 --help选项
--help可以获取Shell外部命令的帮助,其基本信息如下。
-
命令名称:--help。
-
英文原意:help。
-
所在路径:Shell内置命令。
-
执行权限:所有用户。
功能描述:显示外部命令的帮助。
[root@localhost ~]# [命令] --help示例:
[root@localhost ~]# ls --help
12 vim编辑器
12.1 vim编辑器简介
vim是一个全屏幕纯文本编辑器,是vi编辑器的增强版
12.2 vim基本使用
12.2.1 vim的工作模式
vim工作在三种模式之下:
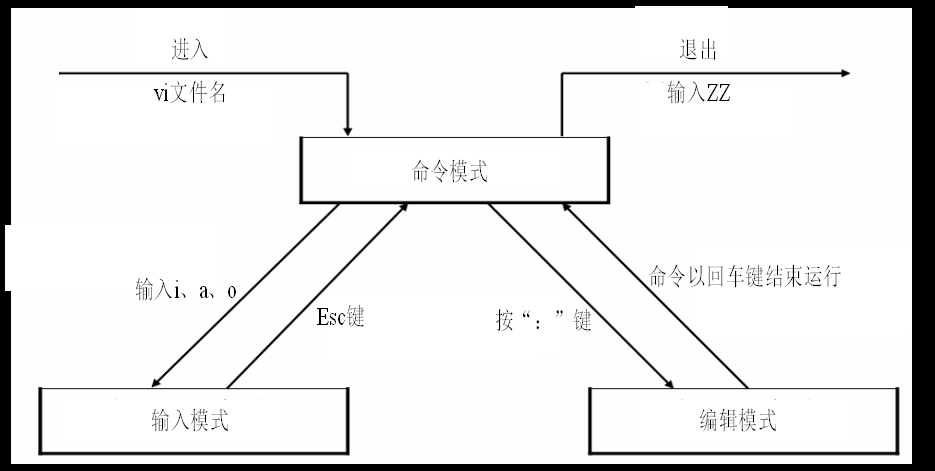
命令模式:是主要使用快捷键的模式。命令模式想要进入输入模式,可以使用以下的方式
| 命令 | 作用 |
|---|---|
| a | 在光标所在字符后面插入 |
| A | 在光标所在行尾插入 |
| i | 在光标所在字符前插入 |
| I | 在光标所在行行首插入 |
| o | 在光标下插入新行 |
| O | 在光标上插入新行 |
输入模式:主要用于文本编辑,和记事本类似,输入数据就好。
末行模式(编辑模式):
| 命令 | 作用 |
|---|---|
| :w | 保存不退出 |
| :q | 不保存退出 |
| :wq | 保存并退出 |
| :! | 强制 |
| :q! | 强制退出且不保存 |
| :wq! | 强制保存并退出 |
12.2.2 命令模式操作
移动光标
1)上下左右移动光标
上、下、左、右方向键移动光标
H、j、k、l 移动光标2)把光标移动到文件头或尾
gg 移动到文件头
G 移动到文件尾(shift+g)3)移动到行首或行尾
^ 移动到行首
$ 移动到行尾4)移动到指定行
:n 移动到第几行删除或剪切
1)删除字母
x 删除单个字母
nx 删除 n 个字母n 是数字,如果打算从光标位置删除连续的10 个字母,可以使用“10x”即可。删除字母并不符合使用习惯,一般习惯在编辑模式中,用“Backspace”键删除字母。
2)删除整行或剪切
dd 删除单行
ndd 删除多行
:n1,n2d 删除指定范围的行删除整行或多行,这是比较常用的删除方法。这里的dd 快捷键既是删除,也是剪切。删除内容
放入了剪切板,如果不粘贴就是删除,如果粘贴就是剪切。粘贴方法如下:
p 粘贴到光标后
P(大) 粘贴到光标前3)从光标所在行删除到文件尾
dG 从光标所在行删除到文件尾“d”是删除行,“G”是文件尾,连起来就是从光标所在行删除到文件尾。如果把光标放在文件首,那么“dG”就变成了删除整篇文档了。
复制
yy 复制单行
nyy 复制多行撤销
u 撤销
ctrl+r 反撤销“u”键能一直撤销到文件打开时的状态,类似Windows 下“ctrl+z”键的作用。 “ctrl+r”能一直反撤销到最后一次操作状态,类似Windows 下“ctrl+y”键的作用。
替换
r 替换光标所在处的字符
R 从光标所在处开始替换字符,按 ESC 结束“r”键替换单一字符,不用进入输入模式,实际使用时,比进入输入模式删除后再修改,要方便。
vim 配置文件
| 设置参数 | 含义 |
|---|---|
| :set nu :set nonu | 显示与取消行号。 |
| :syntax on :syntax off | 是否依据语法显示相关的颜色帮助。在Vim 中修改相关的配置文件或 Shell 脚本文件时(如前面示例的脚本/etc/init.d/sshd),默认会显 示相应的颜色,用来帮助排错。如果觉得颜色产生了干扰,则可以取消 此设置 |
| :set hlsearch :set nohlsearch | 设置是否将查找的字符串高亮显示。默认是set hlsearch 高亮显示 |
| :set ruler :set noruler | 设置是否显示右下角的状态栏。默认是set ruler 显示 |
| :set showmode :set noshowmode | 设置是否在左下角显示如“—INSERT--”之类的状态栏。默认是set showmode 显示 |
| :set list :set nolist | 设置是否显示隐藏字符(Tab 键用“^I”表示,回车符用“$”表示)。 默认是nolist 显示。如果使用set list 显示隐藏字符,类似“cat –A 文件名”。 |
vim 支持更多的设置参数,可以通过“:set all”进行查看。
这些设置参数都只是临时生效,一旦关闭文件再打开,又需要重新输入。如果想要永久生效,需要手工建立vim 的配置文件“~/.vimrc”,把需要的参数写入配置文件就永久生效了。
补充:Windows 下回车符在Linux 中是用“^M$”符号显示,而不是“$”符。这样会导致Windows下编辑的程序脚本,无法在Linux 中执行。这时可以通过命令“dos2unix”,把Windows 格式转为Linux格式,当然反过来“unix2dos”命令就是把Linux 格式转为Windows 格式。这两个命令默认没有安装,需要手工安装才能使用。
查找
/查找内容 从光标所在行向下查找
?查找内容 从光标所在行向上搜索
n 下一个
N 上一个替换
:1,10s/old/new/g 替换1 到10 行的所有old 为new
:%s/old/new/g 替换整个文件的old 为new替换字符串,我举几个例子:在shell 中“#”开头是注释,那我是否可以注释文件的前10 行呢?手工一个一个注释很麻烦,那么批量替换吧:
:1,10s/^/#/g 注释1 到10 行
:1,10s/^#//g 取消注释而在C 语言,PHP 语言等大多数语言中,是使用“//”开头作为注释的,我们当然可以用vim 来写这些程序语言脚本,那么批量加入“//”注释吧:
:1,10s/^/\/\//g 1 到10 行,行首加入//
:1,10s/^\/\///g 取消1 到10 行行首的//12.3 vim 使用技巧
12.3.1 在vim 中导入其他文件内容或命令结果
导入其他文件内容
:r 文件名 把文件内容导入光标位置可以把其他文件的内容导入到光标所在位置
在vim 中执行系统命令
:!命令 在vim 中执行系统命令这里只是在vim 中执行系统命令,但并不把系统命令的结果写入到文件中。主要用于在文件编辑中,查看系统信息,如时间。
导入命令结果
:r !命令 在vim 中执行系统命令,并把命令结果导入光标所在行在vim 中执行系统命令,并把命令结果导入光标所在行。
12.3.2 设定快捷键
:map 快捷键 快捷键执行的命令 自定义快捷键vim 允许自定义快捷键,常用的自定义快捷键如下:
:map ^P I#<ESC> 按“ctrl+p”时,在行首加入注释
:map ^B ^x 按“ctrl+b”时,删除行首第一个字母(删除注释)注意:^P 快捷键不能手工输入,需要执行ctrl+V+P 来定义,或ctrl+V ,然后ctrl+P。^B 快捷键也是一样
12.3.3 字符替换
:ab 源字符 替换为字符 字符替换在vim 编辑中,有时候需要频繁输入某一个长字符串(比如邮箱),这时使用字符串替换,能增加输入效率,例如:
:ab mymail shenchao@163.com 当碰到“mymail”时,转变为邮箱注意:“源字符”不应设置的太短,否则有可能影响输入。
12.3.4 多文件打开
在vim 中可以同时打开两个文件,只要执行如下命令:
[root@localhost ~]# vim -o abc bcd
[root@localhost ~]# vim -O abc bcd
#-o 小写o 会上下分屏打开两个文件
#-O 大写O 会左右分屏打开两个文件这样可以同时打开两个文件,方便操作。如果是“-o”上下打开两个文件,可以通过先按“ctrl+w”,再按“上下箭头”的方式在两个文件之间切换。
如果是“-O”左右打开两个文件,可以通过先按“ctrl+w”,再按“左右箭头”的方式在两个文件之间切换。
13 Linux 软件包介绍
13.1 软件包分类
软件包分类
-
源码包
-
二进制包
13.1.1 源码包
源码包的优点:
-
开源,如果有足够的能力,可以修改源代码
-
可以自由选择所需的功能
-
软件是编译安装,所以更加适合自己的系统,更加稳定也效率更高
-
卸载方便
源码包的缺点:
-
安装过程步骤较多,尤其安装较大的软件集合时(如LAMP环境搭建),容易出现拼写错误
-
编译过程时间较长,安装比二进制安装时间长
-
因为是编译安装,安装过程中一旦报错新手很难解决
13.1.2 二进制包
二进制包分类
-
DPKG包:是由Debian Linux所开发出来的包管理机制,通过DPKG包,Debian Linux就可以进行软件包管理。主要应用在Debian和unbuntu中。
-
RPM包:是由Red Hat公司所开发的包管理系统。功能强大,安装、升级、查询和卸载都非常简单和方便。目前很多Linux都在使用这种包管理方式,包括Fedora、CentOS、SuSE等。我们学习的是CentOS 6.3,所以我们将要学习RPM包管理系统
RPM包的优点:
-
包管理系统简单,只通过几个命令就可以实现包的安装、升级、查询和卸载
-
安装速度比源码包安装快的多
RPM包的缺点:
-
经过编译,不再可以看到源代码
-
功能选择不如源码包灵活
-
依赖性。有时我们会发现需要安装软件包a时需要先安装b和c,而安装b时需要安装d和e。这是需要先安装d和e,再安装b和c,最后才能安装a包。比如说,我买了个漂亮的灯具,打算安装到我们家客厅,可是在安装灯具之前我们家客厅总要有顶棚吧,顶棚总要是做好了防水和刷好油漆了吧,这个装修和安装软件其实类似总要有一定的顺序的。可是有时依赖性会非常繁琐
13.2 rpm包安装
13.2.1 rpm包命名规则
httpd-2.2.15-15.el6.centos.1.i686.rpm| httpd | 软件包名 |
|---|---|
| 2.2.15 | 软件版本 |
| 15 | 软件发布的次数 |
| el6 | 软件发行商。 |
| i686 | 适合的硬件平台。 |
| rpm | rpm包的扩展名 |
包全名:如果操作的是未安装软件包,则使用包全名,而且需要注意绝对路径
包名:如果操作的是已经安装的软件包,则使用包名即可,系统会生产RPM包的数据库/var/lib/rpm/),而且可以在任意路径下操作
13.2.2 依赖性
1)树形依赖 a---->b---->c 2)环形依赖 a---->b---->c---->a 3)函数库依赖 什么是模块依赖?我们举一个例子,尝试安装以下文件:
[root@localhost Packages]# rpm -ivh mysql-connector-odbc-5.2.5-7.el7.x86_64.rpm
错误:依赖检测失败:
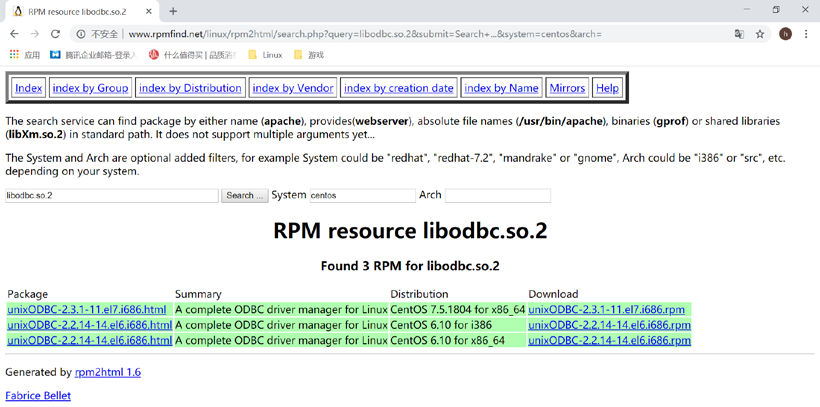
libodbc.so.2()(64bit) 被 mysql-connector-odbc-5.2.5-7.el7.x86_64 需要
libodbcinst.so.2()(64bit) 被 mysql-connector-odbc-5.2.5-7.el7.x86_64 需要发现报错,需要安装“libodbc.so.2”函数库文件,这时会发现在光盘中根本找不到这个文件。那是因为函数库没有单独成包,是包含在某一个软件包中的。而如果要知道在哪个软件包中,需要查询网站
13.2.3 rpm包手工命令安装
1)默认安装位置
| 安装目录 | 描述 |
|---|---|
| /etc/ | 配置文件安装目录 |
| /usr/bin/ | 可执行的命令安装目录 |
| /usr/lib/ | 程序所使用的函数库保存位置 |
| /usr/share/doc/ | 基本的软件使用手册保存位置 |
| /usr/share/man/ | 帮助文件保存位置 |
2)RPM包安装
安装命令:
[root@localhost ~]# rpm -ivh httpd-2.2.15-15.el6.centos.1.i686.rpm
#注意一定是包全名。如果跟包全名的命令要注意路径,因为软件包在光盘当中
选项:
-i install安装(install)
-v 显示更详细的信息(verbose)
-h 打印"#"显示安装进度(hash)服务启动:
[root@localhost ~]# systemctl restart httpd3)RPM包升级
[root@localhost ~]# rpm –Uvh 包全名
选项:
-U(大写) 升级安装,如果没有安装过,系统直接安装。如果安装过的版本较旧,则升级到新版本(upgrade)
-F(大写) 升级安装,如果没有安装过,则不会安装。必须安装有较旧版本,才能升级(freshen)4)卸载
[root@localhost ~]# rpm -e 包名
选项:
--nodeps 不检查依赖性
-e 卸载5)查询
查询软件包是否安装
[root@localhost ~]# rpm –q 包名
选项:
-q: 查询(query)查询系统中的所有安装软件包
[root@localhost ~]# rpm -qa
选项:
-a:所有(all)查询软件包的详细信息
[root@localhost ~]# rpm –qi 包名
选项:
-i: 查询软件信息(information)
-p: 查询没有安装的软件包(package)查询软件包中的文件列表
[root@localhost ~]# rpm –ql 包名
选项:
-l: 列出软件包中所有的文件列表和软件所安装的目录(list)
-p: 查询没有安装的软件包信息(package)查询系统文件属于哪个RPM包
[root@localhost ~]# rpm –qf 系统文件名
选项:
-f: 查询系统文件属于哪个软件包(file)查询软件包所依赖的软件包
[root@localhost ~]# rpm –qR 包名
选项:
-R: 查询软件包的依赖性(requires)6)验证
[root@localhost ~]# rpm –Va
选项:
-a 校验本机已经安装的所有软件包
-V 校验指定RPM包中的文件(verify)
-f 校验某个系统文件是否被修改| 验证内容 | 描述 |
|---|---|
| S | 文件大小是否改变 |
| M | 文件的类型或文件的权限(rwx)是否被改变 |
| 5 | 文件MD5校验和是否改变(可以看成文件内容是否改变) |
| D | 设备的主从代码是否改变 |
| L | 文件路径是否改变 |
| U | 文件的属主(所有者)是否改变 |
| G | 文件的属组是否改变 |
| T | 文件的修改时间是否改变 |
| 配置文件类型 | 描述 |
|---|---|
| c | 配置文件(config file) |
| d | 普通文档(documentation) |
| g | “鬼”文件(ghost file),比较少见 |
| l | 授权文件(license file) |
| r | 描述文件(read me) |
7)数字证书
传统的校验方法只能对已经安装的RPM包中的文件进行校验,但是如果RPM包本身就被动过手脚,那么校验就不能解决问题了。安全性较高的场景下就必须使用数字证书验证
数字证书有如下特点:
-
首先必须找到原厂的公钥文件,然后进行安装
-
再安装RPM包是,会去提取RPM包中的证书信息,然后和本机安装的原厂证书进行验证
-
如果验证通过,则允许安装;如果验证不通过,则不允许安装并警告
数字证书位置
#系统中的数字证书位置
[root@localhost ~]# ll /etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-7数字证书导入
[root@localhost ~]# rpm --import /etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-7
选项:
--import 导入数字证书查询系统已安装证书
[root@localhost ~]# rpm -qa | grep gpg-pubkey13.2.4 rpm包在线安装(yum安装)
1)yum源文件解析
yum源配置文件保存在/etc/yum.repos.d/目录中,文件的后缀名一定是“.repo”。也就是说,yum源配置文件只要扩展名是“.repo”就会生效。
[root@localhost ~]# ll /etc/yum.repos.d/
total 40
-rw-r--r--. 1 root root 1664 Oct 23 2020 CentOS-Base.repo
-rw-r--r--. 1 root root 649 Oct 23 2020 CentOS-Debuginfo.repo
-rw-r--r--. 1 root root 314 Oct 23 2020 CentOS-fasttrack.repo
-rw-r--r--. 1 root root 630 Oct 23 2020 CentOS-Media.repo
-rw-r--r--. 1 root root 8515 Oct 23 2020 CentOS-Vault.repo这个目录中有5个yum源配置文件,默认情况下CentOS-Base.repo文件生效。我们打开这个文件看看,命令如下
[base]
name=CentOS-$releasever - Base
mirrorlist=http://mirrorlist.centos.org/?release=$releasever&arch=$basearch&repo=os&infra=$infra
#baseurl=http://mirror.centos.org/centos/$releasever/os/$basearch/
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-7
…省略部分输出…-
[base]:容器名称,一定要放在[ ]中。
-
name:容器说明,可以自行更改。
-
baseurl:我们的yum源服务器的地址。默认是CentOS官方的yum源服务器
-
enabled:此容器是否生效,如果不写或写成enabled=1则表示此容器生效,写成enabled=0则表示此容器不生效
-
gpgcheck:如果为1则表示RPM的数字证书生效;如果为0则表示RPM的数字证书不生效。
-
gpgkey:数字证书的公钥文件保存位置。不用修改。
2)搭建阿里云网络yum源
[root@localhost ~]# vim /etc/yum.repos.d/aliyun.repo
[Aliyun]
name = Aliyun
enable = 1
baseurl = http://mirrors.aliyun.com/centos/$releasever/os/$basearch/
gpgcheck = 1
gpgkey = http://mirrors.aliyun.com/centos/RPM-GPG-KEY-CentOS-7
[root@localhost ~]# yum clean all &&yum repolist 3)yum命令
查询
# 查询yum源服务器上所有可安装的软件包列表。
[root@localhost ~]# yum list
# 查询yum源服务器中是否包含某个软件包
[root@localhost ~]# yum list 包名
# 搜索yum源服务器上所有和关键字相关的软件包。
[root@localhost ~]# yum search 关键字
# 查询指定软件包的信息
[root@localhost ~]# yum info 包名安装
[root@localhost ~]# yum -y install 包名
选项:
install 安装
-y 自动回答yes。如果不加-y,那么每个安装的软件都需要手工回答yes升级
[root@localhost ~]# yum -y update 包名
选项:
update: 升级
-y: 自动回答yes卸载
[root@localhost ~]# yum remove 包名4)yum组管理命令
查询可以安装的软件组
[root@localhost ~]# yum grouplist查询软件组内包含的软件
[root@localhost ~]# yum groupinfo 软件组名安装软件组
[root@localhost ~]# yum groupinstall 软件组名卸载软件组
[root@localhost ~]# yum groupremove 软件组名13.3 源码包安装
13.3.1 如何选择哪种软件包
-
如果软件包是给大量客户提供访问,建议使用源码包安装,如LAMP环境搭建,因为源码包效率更高。
-
如果软件包是给Linux底层使用,或只给少量客户访问,建议使用rpm包安装,因为rpm包简单。
13.3.2 源码包是从哪里来
rpm包是光盘中直接包含的,所以不需要用户单独下载。而源码包是通过官方网站下载的,如果需要使用,是需要单独下载的。
13.3.3 安装过程
13.3.4 删除
源码包没有删除命令,如果需要删除,直接删除安装目录即可。
13.3.5 打入补丁
1)补丁的生成
[root@localhost ~]# diff 选项 old new
#比较old和new文件的不同
选项:
-a 将任何文档当做文本文档处理
-b 忽略空格造成的不同
-B 忽略空白行造成的不同
-I 忽略大小写造成的不同
-N 当比较两个目录时,如果某个文件只在一个目录中,则在另一个目录中视作空 文件
-r 当比较目录时,递归比较子目录
-u 使用同一的输出格式2)示例
[root@localhost ~]# mkdir test
#建立测试目录
[root@localhost ~]# cd test
#进入测试目录
[root@localhost test]# vi old.txt
our
school
is
atguigu
#文件old.txt,为了一会输出便于比较,每行分开
[root@localhost test]# vi new.txt
our
school
is
atguigu
in
Beijing
#文件new.txt比较下两个文件的不同,并生成补丁文件“txt.patch”,命令如下:
[root@localhost test]# diff -Naur /root/test/old.txt /root/test/new.txt > txt.patch
#比较两个文件的不同,同时生成txt.patch补丁文件
[root@localhost test]# vi txt.patch
#查看下这个文件
--- /root/test/old.txt 2021-6-4 05:51:14.347954373 +0800
#前一个文件
+++ /root/test/new.txt 2021-6-4 05:50:05.772988210 +0800
#后一个文件
@@ -2,3 +2,5 @@
school
is
atguigu
+in
+beijing#后一个文件比前一个文件多两行(+表示)
3)打入补丁
[root@localhost test]# patch –pn < 补丁文件
#按照补丁文件进行更新
选项:
-pn n为数字。代表按照补丁文件中的路径,指定更新文件的位置。“-pn”说明下。补丁文件是要打入旧文件的,但是你当前所在的目录和补丁文件中的记录的目录是不一定匹配的,所以就需要“-pn”来同步两个目录。
比如我当前是在“/root/test”目录中(我要打补丁的旧文件就在当前目录下),补丁文件中记录的文件目录为“/root/test/old.txt”,这时如果写入“-p1”(在补丁文件目录中取消一级目录)那么补丁文件就会打入“/root/test/root/test/old.txt”文件中,这显然是不对的。那如果写入的是“-p2”(在补丁文件目录中取消二级目录)那么补丁文件打入的就是“/root/test/test/old.txt”,这显然也不对。如果写入的是“-p3”(在补丁文件目录中取消三级目录)那么补丁文件就是打入的“/root/test/old.txt”,我们的old.txt文件就在这个目录下,所以就应该是“-p3”。
那么更新下“old.txt”文件,命令如下:
[root@localhost test]# patch -p3 < txt.patch
patching file old.txt
#给old.txt文件打补丁
[root@localhost test]# cat old.txt
#查看下old.txt的内容吧。
our
school
is
atguigu
in
Beijing
#多出来了in Beijing两行13.4 脚本安装程序
脚本程序包并不多见,所以在软件包分类中并没有把它列为一类。它更加类似于Windows下的程序安装,有一个可执行的安装程序,只要运行安装程序,然后进行简单的功能定制选择(比如指定安装目录等),就可以安装成功,只不过是在字符界面下完成的。
目前常见的脚本程序以各类硬件的驱动居多。Atlassian 系列软件均是采用脚本安装程序
可以参考:
14 Linux-用户管理
14.1 用户相关文件
14.1.1 /etc/passwd 用户信息文件
root:x:0:0:root:/root:/bin/bash第一列: 用户名
第二列: 密码位
第三列: 用户ID
-
0 超级用户UID。如果用户UID为0,代表这个账号是管理员账号。那Linux中如何把普通用户升级成为管理员呢?就是把其他用户的UID修改为0就可以了,这点和Windows是不同的。不过不建议建立多个管理员账号。
-
1-499 系统用户(伪用户)UID。这些UID账号是系统保留给系统用户的UID,也就是说UID是1-499范围内的用户是不能登录系统的,而是用来运行系统或服务的。其中1-99是系统保留的账号,系统自动创建。100-499 是预留给用户创建系统账号的。
-
500-60000 普通用户UID。建立的普通用户UID从500开始,最大到60000。这些用户足够使用了,但是如果不够也不用害怕,2.6.x内核以后的Linux系统用户UID已经可以支持232这么多了。
第四列:组ID GID 添加用户时,如果不指定用户所属的初始组,那么会建立和用户名相同的组
第五列: 用户说明
第六列: 用户家目录 ~
第七列: 登录shell /bin/bash
如何把普通用户变成超级用户?
可以把用户UID改为014.1.2 /etc/shadow 影子文件
root:$6$9w5Td6lg$bgpsy3olsq9WwWvS5Sst2W3ZiJpuCGDY.4w4MRk3ob/i85fI38RH15wzVoomff9isV1PzdcXmixzhnMVhMxbv0:15775:0:99999:7:::第一列: 用户名
第二列: 加密密码 我们也可以在密码前人为的加入“!”或“”改变加密值让密码暂时失效,使这个用户无法登陆,达到暂时禁止用户登录的效果。 注意所有伪用户的密码都是“!!”或“”,代表没有密码是不能登录的。当然我新创建的用户如果不设定密码,它的密码项也是“!!”,代表这个用户没有密码,不能登录
第三列: 密码最近更改时间, 1970年1月1日作为标准时间
# 时间戳转日期
[root@localhost ~]# date -d "1970-01-01 15775 days"
2013年 03月 11日 星期一 00:00:00 CST
# 日期转时间戳
[root@localhost ~]# echo $(($(date --date="2013/03/11" +%s)/86400+1))
15775第四列: 两次密码的修改间隔时间(和第3字段相比)
第五例: 密码有效期(和第3字段相比)
第六列: 密码修改到期前的警告天数(和第5字段相比)
第七列: 密码过期后的宽限天数(和第5字段相比)
第八列: 密码失效时间 这里同样要写时间戳,也就是用1970年1月1日进行时间换算。如果超过了失效时间,就算密码没有过期,用户也就失效无法使用了 第九列: 保留
14.1.3 /etc/group 组信息文件
root:x:0:root第一列: 组名
第二列: 组密码位
第三列: GID
第四列: 此组中支持的其他用户.附加组是此组的用户
初始组:每个用户初始组只能有一个,初始组只能有一个,一般都是和用户名相同的组作为初始组
附加组:每个用户可以属于多个附加组。要把用户加入组,都是加入附加组、
14.2 用户管理命令
14.2.1 添加用户
1)手工删除用户 手工删除用户试验:手工删除,如果可以正常建立用户,证明用户删除干净。
/etc/passwd
/etc/shadow
/etc/group
/etc/gshadow
/home/user1
/var/spool/mail/user1 邮箱2) useradd命令
[root@localhost ~]# useradd 选项 用户名
选项:
-u 550 指定UID
-g 组名 指定初始组 不要手工指定
-G 组名 指定附加组,把用户加入组,使用附加组
-c 说明 添加说明
-d 目录 手工指定家目录,目录不需要事先建立
-s shell /bin/bash.示例:
[root@localhost ~]# groupadd lamp1
#先手工添加lamp1用户组,因为一会要把lamp1用户的初始组指定过来,如果不事先建立,会报错用户组不存在
[root@localhost ~]# useradd -u 550 -g lamp1 -G root -d /home/lamp1 \ -c "test user" -s /bin/bash lamp1
#建立用户lamp1的同时指定了UID(550),初始组(lamp1),附加组(root),家目录(/home/lamp1),用户说明(test user)和用户登录shell(/bin/bash)
[root@localhost ~]# grep "lamp1" /etc/passwd /etc/shadow /etc/group
#同时查看三个文件
/etc/passwd:lamp1:x:550:502:test user:/home/lamp1:/bin/bash
#用户的UID、初始组、用户说明、家目录和登录shell都和命令手工指定的一致
/etc/shadow:lamp1:!!:15710:0:99999:7:::
#lamp1用户还没有设定密码
/etc/group:root:x:0:lamp1
#lamp1用户加入了root组,root组是lamp1用户的附加组
/etc/group:lamp1:x:502:
#GID502的组是lamp1组
[root@localhost ~]# ll -d /home/lamp1/
drwx------ 3 lamp1 lamp1 4096 1月 6 01:13 /home/lamp1/
#家目录也建立了啊。不需要手工建立家目录3) useradd默认值
useradd添加用户时参考的默认值文件主要有两个,分别是/etc/default/useradd和/etc/login.defs-
/etc/default/useradd
[root@localhost ~]# vi /etc/default/useradd
# useradd defaults file
GROUP=100
HOME=/home
INACTIVE=-1
EXPIRE=
SHELL=/bin/bash
SKEL=/etc/skel
CREATE_MAIL_SPOOL=yesGROUP=100 这个选项是建立用户的默认组,也就是说添加每个用户时,用户的初始组就是GID为100的这个用户组。目前我们采用的机制私有用户组机制。 HOME=/home 这个选项是用户的家目录的默认位置,所以所有的新建用户的家目录默认都在/home/下。 INACTIVE=-1 这个选项就是密码过期后的宽限天数,也就是/etc/shadow文件的第七个字段。如果是天数,比如10代表密码过期后10天后失效;如果是0,代表密码过期后立即失效;如果是-1,则代表密码永远不会失效。这里默认值是-1,所以所有新建立的用户密码都不会失效。 EXPIRE= 这个选项是密码失效时间,也就是/etc/shadow文件的第八个字段。也就说用户到达这个日期后就会直接失效。当然这里也是使用时间戳来表示日期的。默认值是空,所以所有新建用户没有失效时间,永久有效。 SHELL=/bin/bash 这个选项是用户的默认shell的。/bin/bash是Linux的标志shell,所以所有新建立的用户默认都具备shell赋予的权限。 SKEL=/etc/skel 这个选项就是定义用户的模板目录的位置,/etc/skel/目录中的文件都会复制到新建用户的家目录当中。 CREATE_MAIL_SPOOL=yes 这个选项定义是否给新建用户建立邮箱,默认是创建,也就是说所有的新建用户系统都会新建一个邮箱,放在/var/spool/mail/下和用户名相同。
-
/etc/login.defs
#这个文件有些注释,把注释删除掉,文件内容就变成下面这个样子了
MAIL_DIR /var/spool/mail
PASS_MAX_DAYS 99999
PASS_MIN_DAYS 0
PASS_MIN_LEN 5
PASS_WARN_AGE 7
UID_MIN 500
UID_MAX 60000
GID_MIN 500
GID_MAX 60000
CREATE_HOME yes
UMASK 077
USERGROUPS_ENAB yes
ENCRYPT_METHOD SHA512MAIL_DIR /var/spool/mail 这行指定了新建用户的默认邮箱位置。比如user1用户的邮箱是就是/var/spool/mail/user1。 PASS_MAX_DAYS 99999 这行指定的是密码的有效期,也就是/etc/shadow文件的第五字段。代表多少天之后必须修改密码,默认值是99999。
PASS_MIN_DAYS 0 这行指定的是两次密码的修改间隔时间,也就是/etc/shadow文件的第四字段。代表第一次修改密码之后,几天后才能再次修改密码。默认值是0。
PASS_MIN_LEN 5 这行代表密码的最小长度,默认不小于5位。但是我们现在用户登录时验证已经被PAM模块取代,所以这个选项并不生效。
PASS_WARN_AGE 7 这行代表密码修改到期前的警告天数,也就是/etc/shadow文件的第六字段。代表密码到底有效期前多少天开始进行警告提醒,默认值是7天。
UID_MIN 500 UID_MAX 60000 这两行代表创建用户时,最小UID和最大的UID的范围。我们2.6.x内核开始,Linux用户的UID最大可以支持232这么多,但是真正使用时最大范围是60000。还要注意如果我手工指定了一个用户的UID是550,那么下一个创建的用户的UID就会从551开始,哪怕500-549之间的UID没有使用(小于500的UID是给伪用户预留的)。
GID_MIN 500 GID_MAX 60000 这两行指定了GID的最小值和最大值之间的范围。
CREATE_HOME yes 这行指定建立用户时是否自动建立用户的家目录,默认是建立
UMASK 077 这行指定的是建立的用户家目录的默认权限,因为umask值是077,所以新建的用户家目录的权限是700,umask的具体作用和修改方法我们可以参考下一章权限设定章节。
USERGROUPS_ENAB yes 这行指定的是使用命令userdel删除用户时,是否删除用户的初始组,默认是删除。
ENCRYPT_METHOD SHA512 这行指定Linux用户的密码使用SHA512散列模式加密,这是新的密码加密模式,原先的Linux只能用DES或MD5方式加密
14.2.2 设定密码
[root@localhost ~]# passwd [选项] [用户名]
选项:
-l: 暂时锁定用户。仅root用户可用
-u: 解锁用户。仅root用户可用
--stdin: 可以将通过管道符输出的数据作为用户的密码。主要在批量添加用户时使用
[root@localhost ~]# passwd
#passwd直接回车代表修改当前用户的密码也可以使用字符串作为密码:
[root@localhost ~]# echo "123" | passwd --stdin user1
更改用户 user1 的密码为123。可以通过命令,把密码修改日期归零(shadow第3字段).这样用户一登陆就要修改密码,例如:
[root@localhost ~]# chage -d 0 user114.2.3 用户信息修改
usermod命令是修改已经添加的用户的信息的,命令如下:
[root@localhost ~]# usermod [选项] 用户名
选项:
-u UID: 修改用户的UID
-d 家目录: 修改用户的家目录。家目录必须写绝对路径
-c 用户说明: 修改用户的说明信息,就是/etc/passwd文件的第五个字段
-g 组名: 修改用户的初始组,就是/etc/passwd文件的第四个字段
-G 组名: 修改用户的附加组,其实就是把用户加入其他用户组
-s shell: 修改用户的登录Shell。默认是/bin/bash
-e 日期: 修改用户的失效日期,格式为“YYYY-MM-DD”。也就是/etc/shadow 文件的第八个字段
-L: 临时锁定用户(Lock)
-U: 解锁用户(Unlock)14.2.4 删除用户
[root@localhost ~]# userdel [-r] 用户名
选项:
-r: 在删除用户的同时删除用户的家目录示例:
[root@localhost ~]# userdel -r zhangsan14.2.5 切换用户身份
su命令可以切换成不同的用户身份,命令格式如下:
[root@localhost ~]# su [选项] [用户名]
选项:
-: 选项只使用“-”代表连带用户的环境变量一起切换
-c 命令: 仅执行一次命令,而不切换用户身份“-”不能省略,它代表切换用户身份时,用户的环境变量也要切换成新用户的环境变量。
14.3 组管理命令
14.3.1 添加用户组:groupadd
添加用户组的命令是groupadd,命令格式如下:
[root@localhost ~]# groupadd [选项] [组名]
选项:
-g GID: 指定组ID示例:
[root@localhost ~]# groupadd group1
#添加group1组
[root@localhost ~]# grep "group1" /etc/group
group1:x:502:14.3.2 删除用户组:groupdel
groupdel命令用于删除用户组,命令格式如下:
[root@localhost ~]# groupdel [组名]示例:
[root@localhost ~]# groupdel testgrp
#删除testgrp组不过需要注意,要删除的组不能是其他用户的初始组,也就是说这个组中没有初始用户才可以删除。如果组中有附加用户,则删除组时不受影响。
14.3.3 把用户添加进组或从组中删除:gpasswd
其实gpasswd命令是用来设定组密码并指定组管理员的,不过我们在前面已经说了,组密码和组管理员功能很少使用,而且完全可以被sudo命令取代,所以gpasswd命令现在主要用于把用户添加进组或从组中删除。命令格式如下:
[root@localhost ~]# gpasswd [选项] [组名]
选项:
-a 用户名: 把用户加入组
-d 用户名: 把用户从组中删除示例:
[root@localhost ~]# groupadd grouptest
#添加组grouptest
[root@localhost ~]# gpasswd -a user1 grouptest
Adding user user1 to group grouptest
#把用户user1加入grouptest组
[root@localhost ~]# grep "user1" /etc/group
user1:x:501:
grouptest:x:505:user1
#查看一下,user1用户已经作为附加用户加入grouptest组
[root@localhost ~]# gpasswd -d user1 grouptest
Removing user user1 from group grouptest
#把用户user1从组中删除
[root@localhost ~]# grep "grouptest" /etc/group
grouptest:x:505:
#组中没有user1用户了14.3.4 改变有效组:newgrp
每个用户可以属于一个初始组(用户是这个组的初始用户),也可以属于多个附加组(用户是这个组的附加用户)。既然用户可以属于这么多用户组,那么用户在创建文件后,默认生效的组身份是哪个呢?当然是初始用户组的组身份生效了,因为初始组是用户一旦登录就直接获得的组身份。
也就是说,用户在创建文件后,文件的属组是用户的初始组,因为用户的有效组默认是初始组。既然用户属于多个用户组,那么能不能改变用户的有效组呢?使用命令newgrp就可以切换用户的有效组。命令格式如下:
[root@localhost ~]# newgrp [组名]举个例子,我们已经有了普通用户user1,默认会建立user1用户组,user1组是user1用户的初始组。我们再把user1用户加入group1组,那么group1组就是user1用户的附加组。
当user1用户创建文件test1时,test1文件的属组是user1组,因为user1组是user1用户的有效组。通过newgrp命令就可以把user1用户的有效组变成group1组,当user1用户创建文件test2时,就会发现test2文件的属组就是group1组。命令如下:
[root@localhost ~]# groupadd group1
#添加组group1
[root@localhost ~]# gpasswd -a user1 group1
Adding user user1 to group group1
#把user1用户加入group1组
[root@localhost ~]# grep "user1" /etc/group
user1:x:501:
group1:x:503:user1
#user1用户既属于user1组,也属于group1组
[root@localhost ~]# su – user1
#切换成user1身份,超级用户切换成普通用户不用密码
[user1@localhost ~]$ touch test1
#创建文件test1
[user1@localhost ~]$ ll test1
-rw-rw-r-- 1 user1 user1 0 6月 14 05:43 test1
#test1文件的默认属组是user1组
[user1@localhost ~]$ newgrp group1
#切换user1用户的有效组为group1组
[user1@localhost ~]$ touch test2
#创建文件test2
[user1@localhost ~]$ ll test2
-rw-r--r-- 1 user1 group1 0 6月 14 05:44 test2
#test2文件的默认属组是group1组通过这个例子明白有效组的作用了,其实就是当用户属于多个组时,在创建文件时哪个组身份生效。使用newgrp命令可以在多个组身份之间切换。
15 Linux 权限管理
15.1 ACL权限
15.1.1 ACL概述
ACL是用于解决用户对文件身份不足的问题的
15.1.2 开启ACL
[root@localhost ~]# dumpe2fs -h /dev/sda3
#dumpe2fs命令是查询指定分区详细文件系统信息的命令
选项:
-h 仅显示超级块中信息,而不显示磁盘块组的详细信息。
...省略部分输出...
Default mount options: user_xattr acl
...省略部分输出...如果没有开启,手工开启分区的ACL权限:
[root@localhost ~]# mount -o remount,acl /
#重新挂载根分区,并挂载加入acl权限也可以通过修改/etc/fstab文件,永久开启ACL权限:
[root@localhost ~]# vi /etc/fstab
UUID=c2ca6f57-b15c-43ea-bca0-f239083d8bd2 / ext4 defaults,acl 1 1
#加入acl
[root@localhost ~]# mount -o remount /
#重新挂载文件系统或重启动系统,使修改生效15.1.3 ACL基本命令
15.1.4 最大有效权限mask
[root@localhost /]# setfacl -m m:rx project/
#设定mask权限为r-x。使用“m:权限”格式
[root@localhost /]# getfacl project/
# file: project/
# owner: root
# group: tgroup
user::rwx
group::rwx #effective:r-x
mask::r-x
#mask权限变为了r-x
other::---15.1.5 删除ACL 权限
[root@localhost /]# setfacl -x u:st /project/
#删除指定用户和用户组的ACL权限
[root@localhost /]# setfacl -b project/
#会删除文件的所有的ACL权限15.2 sudo 授权
/sbin/
给普通用户赋予部分管理员权限
/usr/sbin/
在此目录下命令只有超级用户才能使用
15.2.1 root 身份
visudo 赋予普通用户权限命令,命令执行后和vi一样使用
root ALL=(ALL) ALL
#用户名 被管理主机的地址=(可使用的身份) 授权命令(绝对路径)
%wheel ALL=(ALL) ALL
#%组名 被管理主机的地址=(可使用的身份) 授权命令(绝对路径)
%wheel ALL=(ALL) NOPASSWD: ALL # 组内sudo免密执行-
用户名/组名:代表root给哪个用户或用户组赋予命令,注意组名前加“%”
-
用户可以用指定的命令管理指定IP地址的服务器。如果写ALL,代表可以管理任何主机,如果写固定IP,代表用户可以管理指定的服务器。(这里真的很奇怪啊,超哥一直认为这里的IP地址管理的是登录者来源的IP地址,查了很多资料也都是这样的。直到有一天超哥查看“man 5 sudoers”帮助,才发现大家原来都理解错误了,这里的IP指定的是用户可以管理哪个IP地址的服务器。那么如果你是一台独立的服务器,这里写ALL和你服务器的IP地址,作用是一样的。而写入网段,只有对NIS服务这样用户和密码集中管理的服务器才有意义)。如果我们这里写本机的IP地址,不代表只允许本机的用户使用指定命令,而代表指定的用户可以从任何IP地址来管理当前服务器。
-
可使用身份:就是把来源用户切换成什么身份使用,(ALL)代表可以切换成任意身份。这个字段可以省略
-
授权命令:代表root把什么命令授权给普通用户。默认是ALL,代表任何命令,这个当然不行。如果需要给那个命令授权,写入命令名即可,不过需要注意一定要命令写成绝对路径
15.2.2 举例
示例1:
# 授权用户user1可以重启服务器
[root@localhost ~]# visudo
user1 ALL= /sbin/shutdown –r now
[user1@localhost ~]$ sudo -l
#查看可用的授权示例2:
再举个例子,授权一个用户管理你的Web服务器,不用自己插手是不是很爽,以后修改设置更新网页什么都不用管,一定Happy死了,Look:
首先要分析授权用户管理Apache至少要实现哪些基本授权:
-
可以使用Apache管理脚本
-
可以修改Apache配置文件
-
可以更新网页内容
假设Aapche管理脚本程序为/etc/rc.d/init.d/httpd 。为满足条件一,用visudo进行授权:
[root@localhost ~]# visudo
user1 192.168.0.156=/etc/rc.d/init.d/httpd reload,\
/etc/rc.d/init.d/httpd configtest授权用户user1可以连接192.168.0.156上的Apache服务器,通过Apache管理脚本重新读取配置文件让更改的设置生效(reload)和可以检测Apache配置文件语法错误(configtest),但不允许其执行关闭(stop)、重启(restart)等操作。(“\”的意思是一行没有完成,下面的内容和上一行是同一行。)
为满足条件二,同样使用visudo授权:
[root@localhost ~]# visudo
user1 192.168.0.156=/binvi /etc/httpd/conf/httpd.conf授权用户user1可以用root身份使用vi编辑Apache配置文件。
以上两种sudo的设置,要特别注意,很多朋友使用sudo会犯两个错误:第一,授权命令没有细化到选项和参数;第二,认为只能授权管理员执行的命令。
条件三则比较简单,假设网页存放目录为/var/www/html ,则只需要授权user1对此目录具有写权限或者索性更改目录所有者为user1即可。如果需要,还可以设置user1可以通过FTP等文件共享服务更新网页。
示例3:
授权aa用户可以添加其他普通用户
aa ALL=/usr/sbin/useradd 赋予aa添加用户权限.命令必须写入绝对路径
aa ALL=/usr/bin/passwd 赋予改密码权限,取消对root的密码修改
aa ALL=/usr/bin/passwd [A-Za-z]*, !/usr/bin/passwd "", !/usr/bin/passwd root
aa身份
sudo /usr/sbin/useradd ee 普通用户使用sudo命令执行超级用户命令
15.3 文件特殊权限SetUID、SetGID、Sticky BIT
15.3.1 SetUID
1)SetUID是什么
-
只有可以执行的二进制程序才能设定SUID权限
-
命令执行者要对该程序拥有x(执行)权限
-
命令执行者在执行该程序时获得该程序文件属主的身份(在执行程序的过程中灵魂附体为文件的属主)
-
SetUID权限只在该程序执行过程中有效,也就是说身份改变只在程序执行过程中有效
2)举例
[root@localhost ~]# ll /etc/passwd
-rw-r--r-- 1 root root 1728 1月 19 04:20 /etc/passwd
[root@localhost ~]# ll /etc/shadow
---------- 1 root root 1373 1月 19 04:21 /etc/shadow因为
[root@localhost ~]# ll /usr/bin/passwd
-rwsr-xr-x 1 root root 25980 2月 22 2012 /usr/bin/passwd/usr/bin/passwd命令拥有特殊权限SetUID ,也就是在属主的权限位的执行权限上是s。可以这样来理解它:当一个具有执行权限的文件设置SetUID权限后,用户执行这个文件时将以文件所有者的身份执行。
/usr/bin/passwd命令具有SetUID权限,所有者为root(Linux中的命令默认所有者都是root),也就是说当普通用户使用passwd更改自己密码的时候,那一瞬间突然灵魂附体了,实际是在用passwd命令所有者root的身份在执行passwd命令,root当然可以将密码写入/etc/shadow文件(不要忘记root这个家伙是superman什么事都可以干),所以普通用户也可以修改/etc/shadow文件,命令执行完成后该身份也随之消失
如果取消SetUID权限,则普通用户就不能修改自己的密码了
3)危险的 SetUID
[root@localhost ~]# chmod u+s /usr/bin/vim
[root@localhost ~]# ll /usr/bin/vim
-rwsr-xr-x 1 root root 1847752 4月 5 2012 /usr/bin/vim4)有几点建议:
-
关键目录应严格控制写权限。比如“/”、“/usr”等;
-
用户的密码设置要严格遵守密码三原则;
-
对系统中默认应该具有SetUID权限的文件作一列表,定时检查有没有这之外的文件被设置了SetUID权限。
5)检测SetUID的脚本
[root@localhost ~]# vi suidcheck.sh
#!/bin/bash
# Author: shenchao (E-mail: shenchao@atguigu.com)
find / -perm -4000 -o -perm -2000 > /tmp/setuid.check
#搜索系统中所有拥有SUID和SGID的文件,并保存到临时目录中。
for i in $(cat /tmp/setuid.check)
#做循环,每次循环取出临时文件中的文件名
do
grep $i /root/suid.list > /dev/null
#比对这个文件名是否在模板文件中
if [ "$?" != "0" ]
#如果在,不报错
then
echo "$i isn't in listfile! " >> /root/suid_log_$(date +%F)
#如果文件名不再模板文件中,则报错。并把报错报错到日志中
fi
done
rm -rf /tmp/setuid.check
#删除临时文件
[root@localhost ~]# chmod u+s /bin/vi
#手工给vi加入SUID权限
[root@localhost ~]# ./suidcheck.sh
#执行检测脚本
[root@localhost ~]# cat suid_log_2021-06-28
/bin/vi isn't in listfile!
#报错了,vi不再模板文件中。代表vi被修改了SUID权限 15.3.2 SetGID
1)针对文件的作用
SGID即可以针对文件生效,也可以针对目录生效,这和SUID明显不同。如果针对文件,SGID的含义如下:
-
只有可执行的二进制程序才能设置SGID权限
-
命令执行者要对该程序拥有x(执行)权限
-
命令执行在执行程序的时候,组身份升级为该程序文件的属组
-
SetGID权限同样只在该程序执行过程中有效,也就是说组身份改变只在程序执行过程中有效
[root@localhost ~]# ll /var/lib/mlocate/mlocate.db
-rw-r----- 1 root slocate 1838850 6月 20 04:29 /var/lib/mlocate/mlocate.db大家发现属主权限是r、w,属组权限是r,但是其他人权限是0:
[root@localhost ~]# ll /usr/bin/locate
-rwx--s--x 1 root slocate 35612 8月 24 2010 /usr/bin/locate当普通用户user1执行locate命令时,会发生如下事情:
-
/usr/bin/locate是可执行二进制程序,可以赋予SGID
-
执行用户user1对/usr/bin/locate命令拥有执行权限
-
执行/usr/bin/locate命令时,组身份会升级为slocate组,而slocate组对/var/lib/mlocate/mlocate.db数据库拥有r权限,所以普通用户可以使用locate命令查询mlocate.db数据库
-
命令结束,user1用户的组身份返回为user1组
2)针对目录的作用
如果SGID针对目录设置,含义如下:
-
普通用户必须对此目录拥有r和x权限,才能进入此目录
-
普通用户在此目录中的有效组会变成此目录的属组
-
若普通用户对此目录拥有w权限时,新建的文件的默认属组是这个目录的属组
这样写的实在太难看明白了,举个例子:
[root@localhost ~]# cd /tmp/
#进入临时目录做此实验。因为临时目录才允许普通用户修改
[root@localhost tmp]# mkdir dtest
#建立测试目录
[root@localhost tmp]# chmod g+s dtest
#给测试目录赋予SGID
[root@localhost tmp]# ll -d dtest/
drwxr-sr-x 2 root root 4096 1月 20 06:04 dtest/
#SGID已经生效
[root@localhost tmp]# chmod 777 dtest/
#给测试目录权限,让普通用户可以写
[root@localhost tmp]# su – user1
#切换成普通用户user1
[user1@localhost ~]$ cd /tmp/dtest/
#普通用户进入测试目录
[user1@localhost dtest]$ touch abc
#普通用户建立abc文件
[user1@localhost dtest]$ ll
总用量 0
-rw-rw-r-- 1 user1 root 0 1月 20 06:07 abc
#abc文件的默认属组不再是user1用户组,而变成了dtest组的属组root15.3.3 Sticky BIT
Sticky BIT粘着位,也简称为SBIT。SBIT目前仅针对目录有效,它的作用如下:
-
粘着位目前只对目录有效
-
普通用户对该目录拥有w和x权限,即普通用户可以在此目录拥有写入权限
-
如果没有粘着位,因为普通用户拥有w权限,所以可以删除此目录下所有文件,包括其他用户建立的文件。一但赋予了粘着位,除了root可以删除所有文件,普通用户就算拥有w权限,也只能删除自己建立的文件,但是不能删除其他用户建立的文件。
15.3.4 设定文件特殊权限
特殊权限这样来表示:
-
4代表SUID
-
2代表SGID
-
1代表SBIT
[root@localhost ~]# chmod 4755 ftest
#赋予SUID权限
[root@localhost ~]# chmod 2755 ftest
#赋予SGID权限
[root@localhost ~]# mkdir dtest
[root@localhost ~]# chmod 1755 dtest/
#SBIT只对目录有效,所以建立测试目录,并赋予SBIT15.4 文件系统属性chattr 权限
15.4.1 命令格式
[root@localhost ~]# chattr [+-=] [选项] 文件或目录名
选项:
+: 增加权限
-: 删除权限
=: 等于某权限
i: 如果对文件设置i属性,那么不允许对文件进行删除、改名,也不能添加和修改数据;如果对目录设置i属性,那么只能修改目录下文件的数据,但不允许建立和删除文件。
a: 如果对文件设置a属性,那么只能在文件中增加数据,但是不能删除也不能修改数 据;如果对目录设置a属性,那么只允许在目录中建立和修改文件,但是不允许删 除
e: Linux中绝大多数的文件都默认拥有e属性。表示该文件是使用ext文件系统进行存储的,而且不能使用“chattr -e”命令取消e属性。15.4.2 查看文件系属性lsattr
[root@localhost ~]# lsattr 选项 文件名
选项:
-a 显示所有文件和目录
-d 若目标是目录,仅列出目录本身的属性,而不是子文件的15.4.3 举例
示例1:
#给文件赋予i属性
[root@localhost ~]# touch ftest
#建立测试文件
[root@localhost ~]# chattr +i ftest
[root@localhost ~]# rm -rf ftest
rm: 无法删除"ftest": 不允许的操作
#赋予i属性后,root也不能删除
[root@localhost ~]# echo 111 >> ftest
-bash: ftest: 权限不够
#也不能修改文件的数据
#给目录赋予i属性
[root@localhost ~]# mkdir dtest
#建立测试目录
[root@localhost dtest]# touch dtest/abc
#再建立一个测试文件abc
[root@localhost ~]# chattr +i dtest/
#给目录赋予i属性
[root@localhost ~]# cd dtest/
[root@localhost dtest]# touch bcd
touch: 无法创建"bcd": 权限不够
#dtest目录不能新建文件
[root@localhost dtest]# echo 11 >> abc
[root@localhost dtest]# cat abc
11
#但是可以修改文件内容
[root@localhost dtest]# rm -rf abc
rm: 无法删除"abc": 权限不够
#不能删除示例2:
[root@localhost ~]# mkdir -p /back/log
#建立备份目录
[root@localhost ~]# chattr +a /back/log/
#赋予a属性
[root@localhost ~]# cp /var/log/messages /back/log/
#可以复制文件和新建文件到指定目录
[root@localhost ~]# rm -rf /back/log/messages
rm: 无法删除"/back/log/messages": 不允许的操作
#但是不允许删除
16 Linux-文件系统管理
16.1 硬盘结构
16.1.1 硬盘的逻辑结构
每个扇区的大小事固定的,为512Byte。扇区也是磁盘的最小存贮单位。
硬盘的大小是使用“磁头数×柱面数×扇区数×每个扇区的大小”这样的公式来计算的,其中
-
磁头数(Heads)表示硬盘总共有几个磁头,也可以理解成为硬盘有几个盘面,然后乘以二;
-
柱面数(Cylinders)表示硬盘每一面盘片有几条磁道;
-
扇区数(Sectors)表示每条磁道上有几个扇区;每个扇区的大小一般是512Byte。
16.1.2 硬盘接口
IDE硬盘接口(Integrated Drive Electronics,并口,即电子集成驱动器)也称作“ATA硬盘”或“PATA硬盘”,是早期机械硬盘的主要接口,ATA133硬盘的理论速度可以达到133MB/s(此速度为理论平均值),IDE硬盘接口
SATA接口(Serial ATA,串口)是速度更高的硬盘标准,具备了更高的传输速度,并具备了更强的纠错能力。目前已经是SATA三代,理论传输速度达到600MB/s(此速度为理论平均值)
SCSI接口(Small Computer System Interface,小型计算机系统接口)广泛应用在服务器上,具有应用范围广、多任务、带宽大、CPU占用率低及支持热插拔等优点,理论传输速度达到320MB/s
16.2 文件系统
16.2.1 Linux文件系统的特性
super block(超级块):
记录整个文件系统的信息,包括block与inode的总量,已经使用的inode和block的数量,未使用的inode和block的数量,block与inode的大小,文件系统的挂载时间,最近一次的写入时间,最近一次的磁盘检验时间等。
date block(数据块,也称作block):
用来实际保存数据的(柜子的隔断),block的大小(1KB、2KB或4KB)和数量在格式化后就已经决定,不能改变,除非重新格式化(制作柜子的时候,隔断大小就已经决定,不能更改,除非重新制作柜子)。
每个blcok只能保存一个文件的数据,要是文件数据小于一个block块,那么这个block的剩余空间不能被其他文件是要;要是文件数据大于一个block块,则占用多个block块。
Windows中磁盘碎片整理工具的原理就是把一个文件占用的多个block块尽量整理到一起,这样可以加快读写速度。
inode(i节点,柜子门上的标签):
用来记录文件的权限(r、w、x),文件的所有者和属组,文件的大小,文件的状态改变时间(ctime),文件的最近一次读取时间(atime),文件的最近一次修改时间(mtime),文件的数据真正保存的block编号。每个文件需要占用一个inode。
16.2.2 Linux常见文件系统
| 文件系统 | 描述 |
|---|---|
| ext | Linux中最早的文件系统,由于在性能和兼容性上具有很多缺陷,现在已经很少使用 |
| ext2 | 是ext文件系统的升级版本,Red Hat Linux 7.2版本以前的系统默认都是ext2文件系统。于1993年发布,支持最大16TB的分区和最大2TB的文件(1TB=1024GB=1024×1024KB) |
| ext3 | 是ext2文件系统的升级版本,最大的区别就是带日志功能,以便在系统突然停止时提高文件系统的可靠性。支持最大16TB的分区和最大2TB的文件 |
| ext4 | 是ext3文件系统的升级版。ext4 在性能、伸缩性和可靠性方面进行了大量改进。ext4的变化可以说是翻天覆地的,比如向下兼容ext3、最大1EB文件系统和16TB文件、无限数量子目录、Extents连续数据块概念、多块分配、延迟分配、持久预分配、快速FSCK、日志校验、无日志模式、在线碎片整理、inode增强、默认启用barrier等。它是CentOS 6.x的默认文件系统 |
| xfs | XFS最早针对IRIX操作系统开发,是一个高性能的日志型文件系统,能够在断电以及操作系统崩溃的情况下保证文件系统数据的一致性。它是一个64位的文件系统,后来进行开源并且移植到了Linux操作系统中,目前CentOS 7.x将XFS+LVM作为默认的文件系统。据官方所称,XFS对于大文件的读写性能较好。 |
| swap | swap是Linux中用于交换分区的文件系统(类似于Windows中的虚拟内存),当内存不够用时,使用交换分区暂时替代内存。一般大小为内存的2倍,但是不要超过2GB。它是Linux的必需分区 |
| NFS | NFS是网络文件系统(Network File System)的缩写,是用来实现不同主机之间文件共享的一种网络服务,本地主机可以通过挂载的方式使用远程共享的资源 |
| iso9660 | 光盘的标准文件系统。Linux要想使用光盘,必须支持iso9660文件系统 |
| fat | Windows下的fat16文件系统,在Linux中识别为fat |
| vfat | Windows下的fat32文件系统,在Linux中识别为vfat。支持最大32GB的分区和最大4GB的文件 |
| NTFS | Windows下的NTFS文件系统,不过Linux默认是不能识别NTFS文件系统的,如果需要识别,则需要重新编译内核才能支持。它比fat32文件系统更加安全,速度更快,支持最大2TB的分区和最大64GB的文件 |
| ufs | Sun公司的操作系统Solaris和SunOS所采用的文件系统 |
| proc | Linux中基于内存的虚拟文件系统,用来管理内存存储目录/proc |
| sysfs | 和proc一样,也是基于内存的虚拟文件系统,用来管理内存存储目录/sysfs |
| tmpfs | 也是一种基于内存的虚拟文件系统,不过也可以使用swap交换分区 |
16.3 常用的硬盘管理命令
16.3.1 df命令
[root@localhost ~]# df –ahT
选项:
-a 显示特殊文件系统,这些文件系统几乎都是保存在内存中的。如/proc,因为是挂载在内存中,所以占用量都是0
-h 单位不再只用KB,而是换算成习惯单位
-T 多出了文件系统类型一列示例:
[root@localhost ~]# df -Th
文件系统 类型 容量 已用 可用 已用% 挂载点
/dev/mapper/centos-root xfs 50G 17G 34G 34% /
devtmpfs devtmpfs 3.8G 0 3.8G 0% /dev
tmpfs tmpfs 3.8G 196K 3.8G 1% /dev/shm
tmpfs tmpfs 3.8G 402M 3.4G 11% /run
tmpfs tmpfs 3.8G 0 3.8G 0% /sys/fs/cgroup
/dev/sda2 xfs 1014M 142M 873M 14% /boot
/dev/sda1 vfat 200M 12M 189M 6% /boot/efi
/dev/sdb ext4 917G 39G 832G 5% /data
/dev/mapper/centos-home xfs 53G 33M 53G 1% /home
tmpfs tmpfs 774M 0 774M 0% /run/user/016.3.2 du命令
[root@localhost ~]# du [选项] [目录或文件名]
选项:
-a 显示每个子文件的磁盘占用量。默认只统计子目录的磁盘占用量
-h 使用习惯单位显示磁盘占用量,如KB,MB或GB等
-s 统计总占用量,而不列出子目录和子文件的占用量示例:
[root@localhost home]# du -sh
24K .du与df的区别:du是用于统计文件大小的,统计的文件大小是准确的;df是用于统计空间大小的,统计的剩余空是准确的
lsof | grep deleted”查看被删除的文件,然后一个进程一个进程的手工kill也是可以的
16.3.3 fsck文件系统修复命令
[root@localhost ~]# fsck –y /dev/sdb1
#自动修复16.3.4 dumpe2fs显示磁盘状态
[root@localhost ~]# dumpe2fs [磁盘]示例:
[root@localhost ~]# dumpe2fs /dev/sdb
Filesystem volume name: <none> # 卷标名
Last mounted on: /data # 挂载点
Filesystem UUID: 49d9b3c7-7dae-44df-a25f-8998ec4db3a0
Filesystem magic number: 0xEF53
Filesystem revision #: 1 (dynamic)
Filesystem features: has_journal ext_attr resize_inode dir_index filetype needs_recovery extent 64bit flex_bg sparse_super large_file huge_file uninit_bg dir_nlink extra_isize
Filesystem flags: signed_directory_hash
Default mount options: user_xattr acl # 挂载参数
Filesystem state: clean # 文件系统状态,正常
Errors behavior: Continue
Filesystem OS type: Linux
Inode count: 61054976 # inode总数
Block count: 244190646 # 块总数
Reserved block count: 12209532
Free blocks: 237455710
Free inodes: 60989955
First block: 0
Block size: 4096 # 块大小
Fragment size: 4096
Group descriptor size: 64
Reserved GDT blocks: 1024
Blocks per group: 32768
Fragments per group: 32768
Inodes per group: 8192
Inode blocks per group: 512
Flex block group size: 16
Filesystem created: Tue Jun 15 10:03:27 2021
Last mount time: Thu Jun 24 17:36:23 2021
Last write time: Thu Jun 24 17:36:23 2021
Mount count: 2
Maximum mount count: -1
Last checked: Tue Jun 15 10:03:27 2021
Check interval: 0 (<none>)
Lifetime writes: 893 GB
Reserved blocks uid: 0 (user root)
Reserved blocks gid: 0 (group root)
First inode: 11
Inode size: 256 # inode的大小
...
Group 0: (Blocks 0-32767) [ITABLE_ZEROED] # 第一个数据组的内容
Checksum 0x0553, unused inodes 8181
主 superblock at 0, Group descriptors at 1-117
保留的GDT块位于 118-1141
Block bitmap at 1142 (+1142), Inode bitmap at 1158 (+1158)
Inode表位于 1174-1685 (+1174)
23400 free blocks, 8182 free inodes, 1 directories, 8181个未使用的inodes
可用块数: 9367-9370, 9372-32767
可用inode数: 11-8192
...16.3.5 stat查看文件的详细时间
[root@localhost ~]# stat [文件名]示例:
[root@localhost ~]# stat uninstall_cluster.sh
文件:"uninstall_cluster.sh"
大小:919 块:8 IO 块:4096 普通文件
设备:fd00h/64768d Inode:110630885 硬链接:1
权限:(0755/-rwxr-xr-x) Uid:( 0/ root) Gid:( 0/ root)
环境:unconfined_u:object_r:admin_home_t:s0
最近访问:2021-06-29 09:12:42.185316283 +0800
最近更改:2021-06-29 09:12:33.638316688 +0800
最近改动:2021-06-29 09:12:39.985316387 +0800
创建时间:-16.3.6 判断文件类型
file 文件名 判断文件类型
type 命令名 判断命令类型16.4 fdisk命令手工分区流程介绍
16.4.1 查看系统所有硬盘及分区
[root@localhost ~]# fdisk -l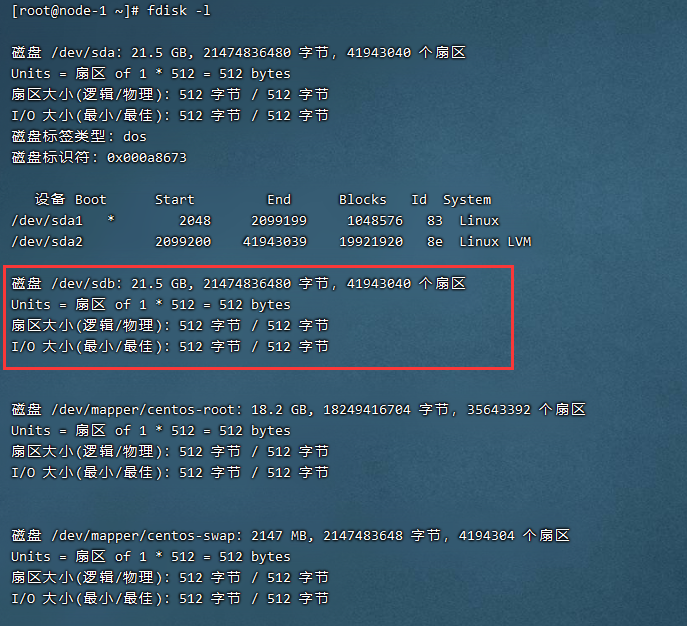
16.4.2 选择硬盘进行分区
[root@localhost ~]# fdisk 硬盘名称fdisk交互指令说明:
| 命令 | 说明 |
|---|---|
| a | 设置可引导标记 |
| b | 编辑bsd磁盘标签 |
| c | 设置DOS操作系统兼容标记 |
| d | 删除一个分区 |
| l | 显示已知的文件系统类型。82为Linux swap分区,83为Linux分区 |
| m | 显示帮助菜单 |
| n | 新建分区 |
| o | 建立空白DOS分区表 |
| p | 显示分区列表 |
| q | 不保存退出 |
| s | 新建空白SUN磁盘标签 |
| t | 改变一个分区的系统ID |
| u | 改变显示记录单位 |
| v | 验证分区表 |
| w | 保存退出 |
| x | 附加功能(仅专家) |
常见流程:
n→p主→1分区号→起始柱面→分区大小+100M→w
n→e扩展→2分区号→124起始柱面→1024柱面(所有剩余空间都分配给扩展分区)
n→l逻辑→不用指定分区号→124起始柱面→+100M(指定大小)→-w
有时因为系统的分区表正忙,则需要重新启动系统之后才能使新的分区表生效。
Command (m for help): w # 保存退出
The partition table has been altered!
Calling ioctl() to re-read partition table.
WARNING: Re-reading the partition table failed with error 16:
Device or resource busy.
The kernel still uses the old table.
The new table will be used at the next reboot. # 要求重启动,才能格式化
Syncing disks.16.4.3 强制重读所有分区文
强制重读所有分区文件,重新挂载分区文件内所有分区。这不是分区必须命令,如果没有提示重启,可以不执行,也可以重启系统
(Warning: Unable to open /dev/hdc read-write (Read-only file system). /dev/hdc has been opened read-only.光盘只读挂载,不是错误,不用紧张)如果这个命令不存在请安装parted-2.1-18.el6.i686这个软件包
16.4.4 格式化建立文件系统
[root@localhost ~]# mkfs [选项] 分区设备文件名
选项:
-t 文件系统: 指定格式化成哪个文件系统,如ext2,ext3,ext4
示例:
[root@localhost ~]# mkfs -t ext4 /dev/sdb1mkfs命令非常简单易用,不过是不能调整分区的默认参数的(比如块大小是4096),这些默认参数除非特殊情况,否则不需要调整,如果想要调整就需要使用mke2fs命令进行重新格式化,命令格式如下:
[root@localhost ~]# mke2fs [选项] 分区设备文件名
选项:
-t 文件系统: 指定格式化成哪个文件系统,如ext2,ext3,ext4
-b 字节: 指定block块的大小
-i 字节: 指定“字节/inode”的比例,也就是多少个字节分配一个inode
-j: 建立带有ext3日志功能的文件系统
-L 卷标名: 给文件系统设置卷标名,就不使用e2label命令设定了
示例:
[root@localhost ~]# mke2fs -t ext4 /dev/sdb216.4.5 建立挂载点
[root@localhost ~]# mkdir -p /data/disk1 ------ /dev/sdb116.4.6 挂载硬盘分区
[root@localhost ~]# mount /dev/sdb1 /data/disk116.4.7 查看挂载信息
[root@localhost ~]# mount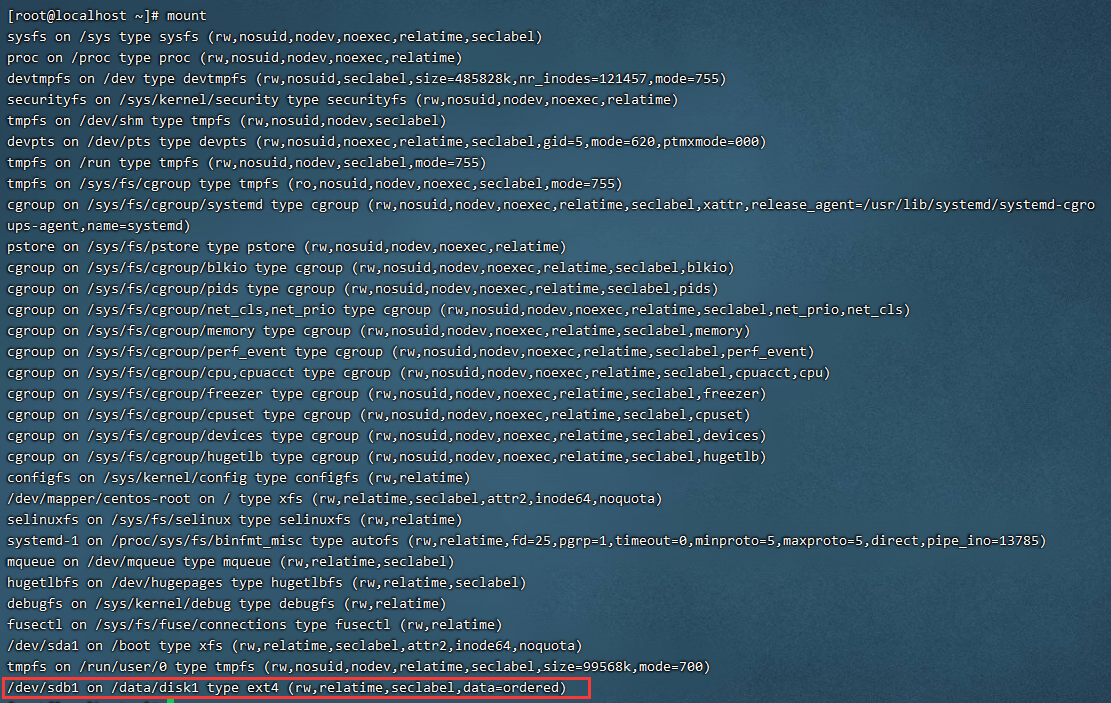
16.4.8 自动挂载
修改分区自动挂载文件
vim /etc/fstab 注意:此文件直接参与系统启动,如果修改错误,系统启动报错
-
第一列: 设备文件名
-
第二列 挂载点
-
第三列 文件系统
-
第四列 挂载选项
-
第五列 1 是否可以被备份 0不备份 1 每天备份 2不定期备份
-
第六列 2 是否检测磁盘fsck 0不检测 1启动时检测 2启动后检测
也可以使用UUID进行挂载,UUID(硬盘通用唯一识别码,可以理解为硬盘的ID)
这个字段在CentOS 5.5的系统当中是写入分区的卷标名或分区设备文件名的,现在变成了硬盘的UUID。这样做的好处是当硬盘增加了新的分区,或者分区的顺序改变,再或者内核升级后,任然能够保证分区能够正确的加载,而不至于造成启动障碍,可以使用dumpe2fs命令查看到硬盘的uuid
[root@localhost ~]# dumpe2fs /dev/sdb1
16.4.9 挂载测试
重启服务器或使用 mount -a 重新挂载所有内容,进行测试
16.5 /etc/fstab/文件修复
重启服务器后出现该错误
一般这种情况很有可能是fstab文件编写问题,导致无法正常开机,可以进入应急模式进行恢复后重启,输入root用户的密码
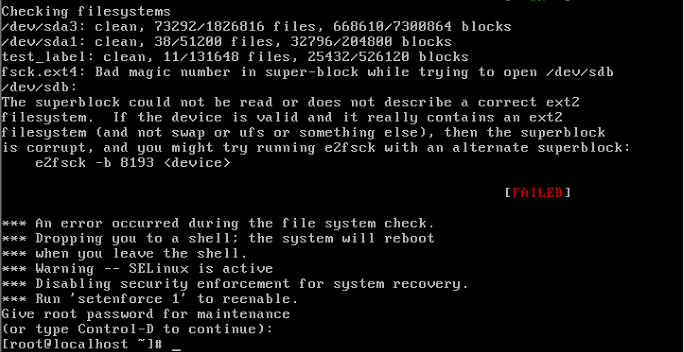
修改/etc/fstab文件
出现这个错误是应为没有写的权限,那么只要把/分区重新挂载下,挂载为读写权限,就可以正常修改
[root@localhost ~]# mount -o remount,rw /再去修改/etc/fstab文件,修改完成后,即可正常启动
16.6 parted命令分区
Linux系统中有两种常见的分区表MBR分区表(主引导记录分区表)和GPT分区表(GUID分区表),其中:
-
MBR分区表:支持的最大分区是2TB(1TB=1024GB);最多支持4个主分区,或3个主分区1个扩展分区
-
GPT分区表:支持最大18EB的分区(1EB=1024PB=1024*1024TB);最多支持128个分区,其中1个系统保留分区,127个用户自定义分区
16.6.1 parted交互模式
[root@localhost ~]# parted /dev/sdb
#打算继续划分/dev/sdb硬盘
GNU Parted 2.1
使用 /dev/sdb
Welcome to GNU Parted! Type 'help' to view a list of commands.
(parted) ←parted的等待输入交互命令的位置| parted交互命令 | 说 明 |
|---|---|
| check NUMBER | 做一次简单的文件系统检测 |
| cp [FROM-DEVICE] FROM-NUMBER TO-NUMBER | 复制文件系统到另外一个分区 |
| help [COMMAND] | 显示所有的命令帮助 |
| mklabel,mktable LABEL-TYPE | 创建新的磁盘卷标(分区表) |
| mkfs NUMBER FS-TYPE | 在分区上建立文件系统 |
| mkpart PART-TYPE [FS-TYPE] START END | 创建一个分区 |
| mkpartfs PART-TYPE FS-TYPE START END | 创建分区,并建立文件系统 |
| move NUMBER START END | 移动分区 |
| name NUMBER NAME | 给分区命名 |
| print [devices|free|list,all|NUMBER] | 显示分区表,活动设备,空闲空间,所有分区 |
| quit | 退出 |
| rescue START END | 修复丢失的分区 |
| resize NUMBER START END | 修改分区大小 |
| rm NUMBER | 删除分区 |
| select DEVICE | 选择需要编辑的设备 |
| set NUMBER FLAG STATE | 改变分区标记 |
| toggle [NUMBER [FLAG]] | 切换分区表的状态 |
| unit UNIT | 设置默认的单位 |
| Version | 显示版本 |
16.6.2 查看分区
(parted) print
#输入print指令
Model: VMware, VMware Virtual S (scsi) # 硬盘参数,是虚拟机
Disk /dev/sdb: 21.5GB # 硬盘大小
Sector size (logical/physical): 512B/512B # 扇区大小
Partition Table: msdos # 分区表类型,就是MBR分区表
Number Start End Size Type File system 标志
1 32.3kB 5379MB 5379MB primary
2 5379MB 21.5GB 15.1GB extended
5 5379MB 7534MB 2155MB logical ext4
6 7534MB 9689MB 2155MB logical ext4
#看到了我们使用fdisk分的区,其中1分区没有格式化,2分区是扩展分区不能格式化使用print可以查看分区表信息,包括硬盘参数,硬盘大小,扇区大小,分区表类型和分区信息。分区信息总共七列,分别是:
-
Number:分区号
-
Start:分区起始位置,这里不再像fdisk用柱面表示,而是使用Byte更加直观
-
End:分区结束位置
-
Size:分区大小
-
Type:分区类型
-
File system:文件系统类型。我不是说parted不支持ext4文件系统吗?注意,我一直都是说parted不能直接把分区直接格式化成ext4文件系统,但是它是可以识别的。
-
标志:Flags,就是分区的标记
16.6.3 修改成GPT分区表
(parted) mklabel gpt
#修改分区表命令
警告: 正在使用 /dev/sdb 上的分区。 #由于/dev/sdb 分区已经挂载,所以有警告,注意如果强制修改,原有分区及数据会消失
忽略/Ignore/放弃/Cancel? ignore # 输入ignore 忽略报错
警告: The existing disk label on /dev/sdb will be destroyed and all data on this disk will
be lost. Do you want to continue?
是/Yes/否/No? yes # 输入yes
警告: WARNING: the kernel failed to re-read the partition table on /dev/sdb (设备或资源
忙). As a result, it may not reflect all of
your changes until after reboot. # 下次重启后,才能生效
(parted) print # 查看下分区表
Model: VMware, VMware Virtual S (scsi)
Disk /dev/sdb: 21.5GB
Sector size (logical/physical): 512B/512B
Partition Table: gpt # 分区表已经变成GPT
Number Start End Size File system Name 标志
# 所有的分区都消失了修改了分区表,如果这块硬盘已经有分区了,那么原有分区和分区中的数据都会消失,而且需要重启系统才会生效。
转换分区表的目的是为了支持大于2TB 的分区,如果分区并没有大于2TB,那么这步是可以不执行的。
注意:一定要把/etc/fstab 文件中和原有分区的内容删除掉,才能重启动。要不系统启动就一定会报错的。
16.6.4 建立分区
因为修改过了分区表,所以/dev/sdb 中的所有数据都消失了,所以我们可以重新对这块硬盘分区了。不过建立分区时,默认文件系统就只能建立成ext2 了,命令如下:
(parted) mkpart
#输入创建分区命令,后面不要参数,全部靠交互指定
分区名称? []? disk1 # 分区名称,我起名叫disk1
文件系统类型? [ext2]? # 文件系统类型,直接回车,使用默认ext2
起始点? 1MB # 分区从1MB 开始
结束点? 5GB # 分区到5GB 结束
#分区完成
(parted) print # 查看分区
Model: VMware, VMware Virtual S (scsi)
Disk /dev/sdb: 21.5GB
Sector size (logical/physical): 512B/512B
Partition Table: gpt
Number Start End Size File system Name 标志
1 1049kB 5000MB 4999MB disk1 # 分区1 已经出现现在的print 查看的分区,和第一次查看MBR 分区表的分区时有些不一样了,少了Type 这个字段,也就是分区类型的字段,多了Name 分区名字段。
分区类型是标识主分区、扩展分区和逻辑分区的,不过这种标识只在MBR 分区表中使用,我们现在已经变成了GPT 分区表了,所以就不再有Type 类型了。也就说折磨我们很久的主分区、扩展分区和逻辑分区的概念不再有用了。
16.6.5 建立文件系统
分区分完了,还需要进行格式化。
(parted) mkfs
#格式化命令(很奇怪也是mkfs,但是这只是parted 的交互命令)
WARNING: you are attempting to use parted to operate on (mkfs) a file system.
parted's file system manipulation code is not as robust as what you'll find in
dedicated, file-system-specific packages like e2fsprogs. We recommend
you use parted only to manipulate partition tables, whenever possible.
Support for performing most operations on most types of file systems
will be removed in an upcoming release.
警告: The existing file system will be destroyed and all data on the partition will be lost.
Do you want to continue?
是/Yes/否/No? yes # 警告你格式化数据会丢失,
分区编号? 1
文件系统类型? [ext2]? # 指定文件系统类型
(parted) print # 格式化完成,查看下
Model: VMware, VMware Virtual S (scsi)
Disk /dev/sdb: 21.5GB
Sector size (logical/physical): 512B/512B
Partition Table: gpt
Number Start End Size File system Name 标志
1 1049kB 5000MB 4999MB ext2 disk1 # 拥有了文件系统16.6.6 调整分区大小
parted 命令还有一大优势,就是可以调整分区的大小(windows 中也可以实现,不过要不需要转换成动态磁盘,要不需要依赖第三方工具,如硬盘分区魔术师)。起始Linux 中LVM 和RAID 是可以支持分区调整的,不过这两种方法也可以看成是动态磁盘方法,我们在下一个章节中介绍。使用parted命令调整分区要更加简单。
注意:parted 调整已经挂载使用的分区时,是不会影响分区中的数据的,也就是说数据不会丢失。但是一定要先卸载分区,再调整分区大小,否则数据是会出现问题的。还有要调整大小的分区必须已经建立了文件系统(格式化),否则会报错
(parted) resize
分区编号? 1 # 指定要修改的分区编号
起始点? [1049kB]? 1MB # 分区起始位置
结束点? [5000MB]? 6GB # 分区结束位置
(parted) print # 查看下
Model: VMware, VMware Virtual S (scsi)
Disk /dev/sdb: 21.5GB
Sector size (logical/physical): 512B/512B
Partition Table: gpt
Number Start End Size File system Name 标志
1 1049kB 6000MB 5999MB ext2 disk1 # 分区大小改变16.6.7 删除分区
(parted) rm
#删除分区命令
分区编号? 1 # 指定分区号
(parted) print # 查看下
Model: VMware, VMware Virtual S (scsi)
Disk /dev/sdb: 21.5GB
Sector size (logical/physical): 512B/512B
Partition Table: gpt
Number Start End Size File system Name 标志 # 分区消失还有件事要注意,parted中所有的操作都是立即生效,没有保存生效的概念。这点和fdisk交互命令明显不同,所以所做的所有操作大家要倍加小心。
那么到底使用fdisk进行分区?还是parted命令呢?这个完全看个人习惯,我们更加习惯fdisk命令。
16.7 分配swap分区
16.7.1 分区,并修改为swap分区ID
[root@localhost ~]# fdisk /dev/sdb
# 拿/dev/sdb分区
Command (m for help): t # 修改分区的系统ID
Selected partition 1 # 只有一个分区,所以不用选择分区了
Hex code (type L to list codes): 82 改为swap的ID
Changed system type of partition 1 to 82 (Linux swap / Solaris)16.7.2 格式化
[root@localhost ~]# mkswap /dev/sdb1
Setting up swapspace version 1, size = 522076 KiB
no label, UUID=c3351dc3-f403-419a-9666-c24615e170fb16.7.3 激活交换空间
[root@localhost ~]# swapon 分区设备文件名
示例:
[root@localhost ~]# swapon /dev/sdb116.7.4 开机自动挂载
加入新swap分区的相关内容,可以使用UUID来进行自动挂载
/dev/sdb1 swap swap defaults 0 0
17 高级文件系统管理
17.1 磁盘配额
17.1.1 磁盘配额概念
-
用户配额和组配额
-
磁盘容量限制和文件个数限制
-
软限制和硬限制
-
宽限时间
如果用户的空间占用数处于软限制和硬限制之间,统会在用户登陆时警告用户磁盘将满,,这个时间就是宽限时间,默认是7天。如果达到了宽限时间,用户的磁盘占用量还超过软限制,那么软限制就会升级为硬限制。
17.1.2 磁盘配额条件
-
内核必须支持磁盘配额
[root@localhost ~]# grep CONFIG_QUOTA /boot/config-2.6.32-279.el6.i686 CONFIG_QUOTA=y CONFIG_QUOTA_NETLINK_INTERFACE=y # CONFIG_QUOTA_DEBUG is not set CONFIG_QUOTA_TREE=y CONFIG_QUOTACTL=y -
系统中必须安装了quota工具,我们的Linux默认是安装了quota工具的,查看命令如下
[root@localhost ~]# rpm -qa | grep quota quota-3.17-16.el6.i686 -
要支持磁盘配额的分区必须开启磁盘配额功能,这个功能需要手工开启,不再是默认就开启的
17.1.3 磁盘配额规划
开始磁盘配额实验,首先来规划下实验:
-
磁盘配额是限制的普通用户在分区上使用磁盘空间和文件个数的,所以需要指定一个分区。那么手工建立一个5GB的/dev/sdb1分区,把它挂载到/disk目录当中。
-
需要建立被限制的用户和用户组。那么假设需要限制user1、user2和user3用户,这三个用户属于test用户组。
-
其中test组磁盘容量硬限制为500MB,软限制450MB,文件个数不做限制。user1用户为了便于测试,磁盘容量硬限制为50MB,软限制为40MB,文件个数硬限制限制为10个,软限制为8个。user2和user3用户磁盘容量硬限制为250MB,软限制为200MB,文件个数不做限制。
-
发现user1、user2和user3用户加起来的磁盘容量限制为550MB,超过了test组的磁盘容量限制500MB。这样的话,某个用户可能达不到自己的用户限制,而达到组限制时就不能再写入数据了。也就是说,如果用户限制和组限制同时存在,那么哪个限制更小,哪个限制优先生效。
-
系统宽限时间改为8天。
17.1.4 磁盘配额步骤
1)分5GB的/dev/sdb1分区,并将它挂载到/disk目录当中
2)建立需要做限制的用户和用户组
[root@localhost ~]# groupadd test
[root@localhost ~]# useradd -G test user1
[root@localhost ~]# useradd -G test user2
[root@localhost ~]# useradd -G test user3
[root@localhost ~]# passwd user1
[root@localhost ~]# passwd user2
[root@localhost ~]# passwd user33)在分区上开启磁盘配额功能
[root@localhost ~]# mount -o remount,usrquota,grpquota /disk
#重新挂载/disk分区,并加入用户和用户组的磁盘配额功能我们要想永久生效,则需要修改/etc/fstab文件,改成:
[root@localhost ~]# vi /etc/fstab
/dev/sdb1 /disk ext4 defaults,usrquota,grpquota 0 0
…省略部分输出…
[root@localhost ~]# mount –o remount /disk
#修改配置文件如果想要生效,必须重启系统,否则也需要把分区重新挂载一遍。4)建立磁盘配额的配置文件
[root@localhost ~]# quotacheck [选项] [分区名]
选项:
-a:扫描/etc/mtab文件中所有启用磁盘配额功能的分区。如果加入此参数,命令后面
就不需要加入分区名了
-c:不管原有的配置文件,重新扫描并建立新的配置文件
-u:建立用户配额的配置文件,也就是生成aquota.user文件
-g:建立组配额的配置文件,会生成aquota.group文件
-v:显示扫描过程
-m:强制以读写的方式扫描文件系统,和-M类似。一般扫描根分区时使用。
-f:强制扫描文件系统,并写入新的配置文件。一般扫描新添加的硬盘分区时使用
[root@localhost ~]# quotacheck -avug需要关闭SELinux,否则会报错
[root@localhost ~]# ll /disk/
总用量 24
-rw------- 1 root root 6144 6月 17 01:08 aquota.group
-rw------- 1 root root 6144 6月 17 01:08 aquota.user
#/disk目录中两个配额配置文件已经建立如果需要给根分区开启配额功能,需要:
[root@localhost ~]# vi /etc/fstab
UUID=c2ca6f57-b15c-43ea-bca0-f239083d8bd2 / ext4 defaults,usrquota,grpquota 1 1
#开启/分区的配额功能
[root@localhost ~]# mount -o remount /
#重新挂载/分区
[root@localhost ~]# quotacheck -avugm如果自动扫描/分区建立配额配置文件时,因为/分区已经挂载成读写系统,而quotacheck需要把分区先挂载成只读分区,然后建立配置文件,最后再挂载回来,所以不能直接在/分区建立配置文件。这时就需要使用-m强制以读写方式扫描文件系统了
5)设置用户和组的配额限制
[root@localhost ~]# edquota [选项] [用户名或组名]
选项:
-u 用户名: 设定用户配额
-g 组名: 设定组配额
-t: 设定宽限时间
-p: 复制配额限制。如果已经设定好某个用户的配额限制,其他用户的配额限制如果和这个用户相同,那么可以直接复制配额限制,而不用都手工指定给user1用户设定的配额限制是:磁盘空间软限制是40MB,硬限制是50MB;文件个数的软限制是8个,硬限制是10个(稍微小一点,一会测试时方便测试)。命令如下:
[root@localhost ~]# edquota -u user1
#edquota命令进入之后,就是标准的vi操作方法
Disk quotas for user user1 (uid 500):
#磁盘配额是设定用户user1(UID是500)
Filesystem blocks soft hard inodes soft hard
/dev/sdb1 0 0 0 0 0 0
#分区名 已占用容量 软限制 硬限制 已占用文件数 软限制 硬限制
Disk quotas for user user1 (uid 500):
Filesystem blocks soft hard inodes soft hard
/dev/sdb1 0 40000 50000 0 8 10
#不用对齐,是七列就行再给user2用户配置限额,user2用户要求是空间软限制250MB,硬限制250MB,文件个数不做限制:
[root@localhost ~]# edquota -u user2
Disk quotas for user user2 (uid 501):
Filesystem blocks soft hard inodes soft hard
/dev/sdb1 0 250000 300000 0 8 10接下来给test组配置限额,test组要求是空间软限制是450MB,硬限制500MB,文件个数不做限制:
[root@localhost ~]# edquota -g test
Disk quotas for group test (gid 500):
Filesystem blocks soft hard inodes soft hard
/dev/sdb1 0 450000 500000 0 8 06) 配额复制
user3用户的配额值和user2用户完全一样,就可以使用user2用户作为模板进行复制。这样如果需要建立大量的配额值一致的用户时,就会非常方便,不用一个个手工建立了。复制命令如下:
[root@localhost ~]# edquota -p user2 -u user3
#命令 -p 源用户 -u 目标用户7)修改宽限时间
要求把宽限时间改为8天,修改命令如下:
[root@localhost ~]# edquota –t
Grace period before enforcing soft limits for users:
Time units may be: days, hours, minutes, or seconds
Filesystem Block grace period Inode grace period
/dev/sdb1 8days 8days
# 分区名 容量的宽限时间 个数的宽限时间8)启动和关闭配额
配额的配置完成,接下来只需要启动配额就大功告成了,启动命令如下:
[root@localhost ~]# quotaon [选项] [分区名]
选项:
-a:依据/etc/mtab文件启动所有的配额分区。如果不加-a,后面就一定要指定分区名
-u:启动用户配额
-g:启动组配额
-v:显示启动过程的信息
[root@localhost ~]# quotaon -vug /disk/
/dev/sdb1 [/disk]: group quotas turned on
/dev/sdb1 [/disk]: user quotas turned on
#启动/disk分区的配额
[root@localhost ~]# quotaon –avug
#这条命令也可以关闭配额的命令如下:
[root@localhost ~]# quotaoff [选项] [分区名]
选项
-a:依据/etc/mtab文件关闭所有的配额分区。如果不加-a,后面就一定要指定分区名
-u:关闭用户配额
-g:关闭组配额
[root@localhost ~]# quotaoff –a
#依据/etc/mtab文件关闭配额分区17.1.5 磁盘配额查询
-
quota查询用户或用户组配额:
[root@localhost ~]# quota [选项] [用户名或组名] 选项: -u 用户名: 查询用户配额 -g 组名: 查询组配额 -v: 显示详细信息 -s: 以习惯单位显示容量大小,如M,G [root@localhost ~]# quota -uvs user1 -
repquota查询文件系统配额:
[root@localhost ~]# repquota [选项] [分区名] 选项: -a: 依据/etc/mtab文件查询配额。如果不加-a选项,就一定要加分区名 -u: 查询用户配额 -g: 查询组配额 -v: 显示详细信息 -s: 以习惯单位显示容量大小 [root@localhost ~]# repquota –augvs
17.1.6 验证测试
[user1@localhost disk]$ dd if=/dev/zero of=/disk/testfile bs=1M count=60
#建立testfile文件,指定大小60MB17.1.7 非交互设定用户磁盘配额
[root@localhost ~]# setquota -u 用户名 容量软限制 容量硬限制 个数软限制 \
个数硬限制 分区名
[root@localhost ~]# useradd user4
[root@localhost ~]# passwd user4
#建立用户
[root@localhost ~]# setquota -u user4 10000 20000 5 8 /disk
#设定用户在/disk分区的容量软限制为10MB,硬限制20MB。文件个数软限制5个,硬限制#8个。这个命令在写脚本批量设置时更加方便。当然写脚本时也可以先建立一个模板的用户,设定好磁盘配额,再进行配额复制,也是可以的。
17.2 LVM逻辑卷管理
17.2.1 LVM简介
LVM是Logical Volume Manager的简称,中文就是逻辑卷管理。
-
物理卷(PV,Physical Volume):就是真正的物理硬盘或分区。
-
卷组(VG,Volume Group):将多个物理卷合起来就组成了卷组,组成同一个卷组的物理卷可以是同一个硬盘的不同分区,也可以是不同硬盘上的不同分区。我们可以把卷组想象为一个逻辑硬盘。
-
逻辑卷(LV,Logical Volume):卷组是一个逻辑硬盘,硬盘必须分区之后才能使用,这个分区我们称作逻辑卷。逻辑卷可以格式化和写入数据。我们可以把逻辑卷想象成为分区。
-
物理扩展(PE,Physical Extend):PE是用来保存数据的最小单元,我们的数据实际上都是写入PE当中,PE的大小是可以配置的,默认是4MB。
17.2.2 建立LVM的步骤
-
首先需要把物理硬盘分成分区,当然也可以是整块物理硬盘。
-
然后把物理分区建立成为物理卷(PV),也可以直接把整块硬盘都建立为物理卷。
-
接下来把物理卷整合成为卷组(VG)。卷组就已经可以动态的调整大小了,可以把物理分区加入卷组,也可以把物理分区从卷组中删除。
-
最后就是把卷组再划分成为逻辑卷(LV),当然逻辑卷也是可以直接调整大小的。我们说逻辑卷可以想象成为分区,所以也需要格式化和挂载。
17.2.3 物理卷管理
1)硬盘分区
创建方式就是使用fdisk交互命令,不过需要注意的是分区的系统ID不再是Linux默认的分区ID号83了,而要改成LVM的ID号8e。
2)建立物理卷
[root@localhost ~]# pvcreate [设备文件名]建立物理卷时,即可以把整块硬盘都建立成物理卷,也可以把某个分区建立成物理卷。如果要把整块硬盘都建立成物理卷,命令如下
[root@localhost ~]# pvcreate /dev/sdb在我们的使用中,是要把分区建立成为物理卷,所以执行以下命令:
[root@localhost ~]# pvcreate /dev/sdb5注意:将整块物理硬盘创建为物理卷(PV)时,不需要对其进行硬盘分区操作
3)查看物理卷
[root@localhost ~]# pvscan
PV /dev/sdb5 lvm2 [1.01 GiB]
PV /dev/sdb6 lvm2 [1.01 GiB]
PV /dev/sdb7 lvm2 [1.01 GiB]
Total: 3 [3.03 GiB] / in use: 0 [0 ] / in no VG: 3 [3.03 GiB]可以看到在我的系统中,/dev/sdb5-7这三个分区是物理卷。最后一行的意思是:总共3个物理卷[大小] / 使用了0个卷[大小] / 空闲3个卷[大小]。
pvdisplay可以查看到更详细的物理卷状态,命令如下:
[root@localhost ~]# pvdisplay
"/dev/sdb5" is a new physical volume of "1.01 GiB"
--- NEW Physical volume ---
PV Name /dev/sdb5 # PV名
VG Name # 属于的VG名,还没有分配,所以空白
PV Size 1.01 GiB # PV的大小
Allocatable NO # 是否已经分配
PE Size 0 # PE大小,因为还没有分配,所以PE大小也没有指定
Total PE 0 # PE总数
Free PE 0 # 空闲PE数
Allocated PE 0 # 可分配的PE数
PV UUID CEsVz3-f0sD-e1w0-wkHZ-iaLq-O6aV-xtQNTB # PV的UUID4)删除物理卷
[root@localhost ~]# pvremove /dev/sdb717.2.4 卷组管理
1)建立卷组
[root@localhost ~]# vgcreate [选项] 卷组名 物理卷名
选项:
-s PE大小:指定PE的大小,单位可以是MB,GB,TB等。如果不写默认PE大小事4MB三个物理卷/dev/sdb5-7,先把/dev/sdb5和/dev/sdb6加入卷组,留着/dev/sdb7一会实验调整卷组大小,命令如下:
[root@localhost ~]# vgcreate -s 8MB scvg /dev/sdb5 /dev/sdb6
Volume group "scvg" successfully created2)查看卷组
查看卷组的命令同样是两个,vgscan主要是查看系统中是否有卷组,命令如下:
[root@localhost ~]# vgscan
Reading all physical volumes. This may take a while...
Found volume group "scvg" using metadata type lvm2
#scvg的卷组确实存在vgdisplay可以查看卷组的详细状态的,命令如下:
[root@localhost ~]# vgdisplay
--- Volume group ---
VG Name scvg # 卷组名
System ID
Format lvm2
Metadata Areas 2
Metadata Sequence No 1
VG Access read/write # 卷组访问状态
VG Status resizable # 卷组状态
MAX LV 0 # 最大逻辑卷数
Cur LV 0
Open LV 0
Max PV 0 # 最大物理卷数
Cur PV 2 # 当前物理卷数
Act PV 2
VG Size 2.02 GiB # 卷组大小
PE Size 8.00 MiB # PE大小
Total PE 258 # PE总数
Alloc PE / Size 0 / 0 # 已用PE数量/大小
Free PE / Size 258 / 2.02 GiB # 空闲PE数量/大小
VG UUID Fs0dPf-LV7H-0Ir3-rthA-3UxC-LX5c-FLFriJ3)增加卷组容量
[root@localhost ~]# vgextend scvg /dev/sdb7
Volume group "scvg" successfully extended
#把/dev/sdb7物理卷也加入scvg卷组
[root@localhost ~]# vgdisplay
--- Volume group ---
VG Name scvg
System ID
Format lvm2
Metadata Areas 3
Metadata Sequence No 2
VG Access read/write
VG Status resizable
MAX LV 0
Cur LV 0
Open LV 0
Max PV 0
Cur PV 3
Act PV 3
VG Size 3.02 GiB # 卷组容量增加
PE Size 8.00 MiB
Total PE 387 # PE总数增加
Alloc PE / Size 0 / 0
Free PE / Size 387 / 3.02 GiB
VG UUID Fs0dPf-LV7H-0Ir3-rthA-3UxC-LX5c-FLFriJ4)减小卷组容量
[root@localhost ~]# vgreduce scvg /dev/sdb7
Removed "/dev/sdb7" from volume group "scvg"
#在卷组中删除/dev/sdb7物理卷
[root@localhost ~]# vgreduce -a
#删除所有的未使用物理卷5)删除卷组
[root@localhost ~]# vgremove scvg
Volume group "scvg" successfully removed卷组删除之后,才能删除删除物理卷。还要注意的是scvg卷组还没有添加任何的逻辑卷,那如果拥有了逻辑卷,记得先删除逻辑卷再删除卷组。还记得我刚说的吗?删除就是安装的反过程,每一步都不能跳过。
17.2.5 逻辑卷管理
1)建立逻辑卷
[root@localhost ~]# lvcreate [选项] [-n 逻辑卷名] 卷组名
选项:
-L 容量:指定逻辑卷大小,单位MB,GB,TB等
-l 个数:按照PE个数指定逻辑卷大小,这个参数需要换算容量,太麻烦
-n 逻辑卷名:指定逻辑卷名建立一个1.5GB的userlv逻辑卷吧,建立命令如下:
[root@localhost ~]# lvcreate -L 1.5G -n userlv scvg
Logical volume "userlv" created
#在scvg卷组中建立1.5GB的userlv逻辑卷建立完逻辑卷之后,还要格式化和挂载之后逻辑卷才能正常使用。格式化和挂载命令和操作普通分区时是一样的,不过需要注意的是逻辑卷的设备文件名是/dev/卷组名/逻辑卷名,如我们的userlv的设备文件名就是“/dev/scvg/userlv”,具体命令如下:
[root@localhost ~]# mkfs -t ext4 /dev/scvg/userlv
#格式化
[root@localhost ~]# mkdir /disklvm
[root@localhost ~]# mount /dev/scvg/userlv /disklvm/
#建立挂载点,并挂载
[root@localhost ~]# mount
…省略部分输出…
/dev/mapper/scvg-userlv on /disklvm type ext4 (rw)
#已经挂载了当然如果需要开机自动挂载,也要修改/etc/fstab文件。
2)查看逻辑卷
同样的查看命令是两个,第一个命令lvscan只能看到系统中是否拥有逻辑卷,命令如下:
[root@localhost ~]# lvscan
ACTIVE '/dev/scvg/userlv' [1.50 GiB] inherit
#能够看到激活的逻辑卷,大小事1.5GBlvdisplay可以看到逻辑卷的详细信息,命令如下:
[root@localhost ~]# lvdisplay
--- Logical volume ---
LV Path /dev/scvg/userlv # 逻辑卷设备文件名
LV Name userlv # 逻辑卷名
VG Name scvg # 所属的卷组名
LV UUID 2kyKmn-Nupd-CldB-8ngY-NsI3-b8hV-QeUuna
LV Write Access read/write
LV Creation host, time localhost, 2021-06-18 03:36:39 +0800
LV Status available
# open 1
LV Size 1.50 GiB # 逻辑卷大小
Current LE 192
Segments 2
Allocation inherit
Read ahead sectors auto
- currently set to 256
Block device 253:03)调整逻辑卷大小
[root@localhost ~]# lvresize [选项] 逻辑卷设备文件名
选项:
-L 容量:安装容量调整大小,单位KB,GB,TB等。使用+代表增加空间,-号代表减少空间。如果直接写容量,代表设定逻辑卷大小为指定大小。
-l 个数:按照PE个数调整逻辑卷大小可以先在/disklvm中建立点文件,一会调整完大小,查看数据是否会丢失:
[root@localhost ~]# cd /disklvm/
[root@localhost disklvm]# touch testf
[root@localhost disklvm]# mkdir testd
[root@localhost disklvm]# ls
lost+found testd testf刚刚的userlv的大小事1.5GB,scvg中还有1.5GB的空闲空间,那么增加 userlv 逻辑卷的大小到2.5GB
[root@localhost disklvm]# lvresize -L 2.5G /dev/scvg/userlv
Extending logical volume userlv to 2.50 GiB
Logical volume userlv successfully resized
#增加userlv逻辑卷的大小到2.5GB
#当然命令也可以这样写 [root@localhost disklvm]# lvresize -L +1G /dev/scvg/userlv
[root@localhost ~]# lvdisplay
--- Logical volume ---
LV Path /dev/scvg/userlv
LV Name userlv
VG Name scvg
LV UUID 2kyKmn-Nupd-CldB-8ngY-NsI3-b8hV-QeUuna
LV Write Access read/write
LV Creation host, time localhost, 2021-06-18 03:36:39 +0800
LV Status available
# open 1
LV Size 2.50 GiB # 大小改变了
Current LE 320
Segments 3
Allocation inherit
Read ahead sectors auto
- currently set to 256
Block device 253:0逻辑卷的大小已经改变了,但是好像存在些问题:
[root@localhost disklvm]# df -h /disklvm/
文件系统 容量 已用 可用 已用%% 挂载点
/dev/mapper/scvg-userlv 1.5G 35M 1.4G 3% /disklvm怎么/disklvm分区的大小还是1.5GB啊?刚刚只是逻辑卷的大小改变了,如果需要让分区使用这个新逻辑卷,还要使用resize2fs命令来调整分区的大小。不过这里就体现了LVM的优势,不需要卸载分区,直接就能调整分区的大小。resize2fs命令如下:
[root@localhost ~]# resize2fs [选项] [设备文件名] [调整的大小]
选项:
-f: 强制调整
设备文件名:指定调整哪个分区的大小
调整的大小:指定把分区调整到多大,要加M,G等单位。如果不加大小,会使用整个分区那么已经把逻辑卷调整到了2.5GB,这时就需要把整个逻辑卷都加入/disklvm分区,命令如下:
[root@localhost ~]# resize2fs /dev/scvg/userlv
resize2fs 1.41.12 (17-May-2010)
Filesystem at /dev/scvg/userlv is mounted on /disklvm; on-line resizing required
old desc_blocks = 1, new_desc_blocks = 1
Performing an on-line resize of /dev/scvg/userlv to 655360 (4k) blocks.
The filesystem on /dev/scvg/userlv is now 655360 blocks long.
#已经调整了分区大小
[root@localhost ~]# df -h /disklvm/
文件系统 容量 已用 可用 已用%% 挂载点
/dev/mapper/scvg-userlv 2.5G 35M 2.4G 2% /disklvm
#分区大小已经是2.5GB了
[root@localhost ~]# ls /disklvm/
lost+found testd testf
#而且数据并没有丢失4)删除逻辑卷
[root@localhost ~]# lvremove 逻辑卷设备文件名删除userlv这个逻辑卷,记得删除时要先卸载。命令如下:
[root@localhost ~]# umount /dev/scvg/userlv
[root@localhost ~]# lvremove /dev/scvg/userlv
信息安全
chage命令 – 设置账户密码有效期
| -M | 密码保持有效的最大天数 |
|---|---|
| -W | 提前收到警告信息的天数 |
| -E | 帐号到期的日期 |
| -d | 上一次更改的日期 |
| -l | 显示当前的设置 |
···sh
[root@zmedu-17 day05]# chage --help
用法:chage [选项] 登录
选项:
-d, --lastday 最近日期 将最近一次密码设置时间设为“最近日期”
-E, --expiredate 过期日期 将帐户过期时间设为“过期日期” 0表示马上过期,-1表示永不过期
-h, --help 显示此帮助信息并推出
-I, --inactive INACITVE 过期 INACTIVE 天数后,设定密码为失效状态
-l, --list 列出用户以及密码的有效期
-m, --mindays 最小天数 将两次改变密码之间相距的最小天数设为“最小天数”
-M, --maxdays MAX_DAYS 密码保持有效的最大天数
-R, --root CHROOT_DIR chroot 到的目录
-W, --warndays 警告天数 密码过期前,提前收到警告信息的天数
# 常用的:
-l:列出用户的以及密码的有效期限
-m:修改密码的最小天数
-M:修改密码的最大天数
-I:密码过期后,锁定帐号的天数
-d:指定密码最后修改的日期
-E:有效期,0表示立即过期,-1表示永不过期
-W:密码过期前,开始警告天数
# 常用示例
$ chage -l root
Last password change : Nov 27, 2022 # 最近一次密码修改时间
Password expires : never # 密码过期时间
Password inactive : never # 密码失效时间
Account expires : never # 帐户过期时间
Minimum number of days between password change : 0 # 两次改变密码之间相距的最小天数
Maximum number of days between password change : 99999 # 两次改变密码之间相距的最大天数
Number of days of warning before password expires : 7 # 在密码过期之前警告的天数
pam_tally2 --user boco4a --reset # 重置登录次数
chage -I -1 boco4a # 密码不失效
chage -E -1 boco4a # 不过期passwd命令 – 修改用户的密码值
| 选项 | 说明 |
|---|---|
| -d | 删除密码 |
| -f | 强迫用户下次登录时必须修改密码 |
| -w | 密码要到期提前警告的天数 |
| -k | 更新只能发送在过期之后 |
| -l | 停止账号使用 |
| -S | 显示密码信息 |
| -u | 启用已经被停止的账户 |
| -x | 指定密码最长存活期 |
| -g | 修改群组密码 |
| -i | 密码过期后多少天停用账户 |
| –help | 显示帮助信息 |
| –version | 显示版本信息 |
vim /etc/login.defs
chattr 锁定配置文件
选项
-i 不可变
-a 可追加,不可删除
“+ -” 控制方式
# 锁定配置文件,此时不能更改密码
[root@localhost ~]# chattr +i /etc/passwd /etc/shadow
[root@localhost ~]# lsattr /etc/passwd /etc/shadow # 查看配置文件状态属性
[root@localhost ~]# passwd zhangyi # 更改zhangyi的密码,发现无法更改密码
# 解锁配置文件
[root@localhost ~]# chattr -i /etc/passwd /etc/shadow
[root@localhost ~]# lsattr /etc/passwd /etc/shadow # 查看配置文件状态属性
[root@localhost ~]# passwd zhangyi # 更改zhangyi的密码,发现可以更改密码iptables
4表分别是filter表、nat表、raw表、mangle表
5链分别是INPUT链、OUTPUT链、FORWARD链、PREROUTING链、POSTROUTING链。防火墙规则要求写在特定表的特定链中:
4张表
raw : 高级功能,如:网址过滤。
mangle :数据包修改(QOS),用于实现服务质量。
nat : 地址转换,用于网关路由器。
filter : 包过滤,用于防火墙规则。
5条链
规则链名包括(也被称为五个钩子函数(hook functions)):
INPUT链 : 入站。
OUTPUT链 : 出站
FORWARD链 : 处理转发数据包。
PREROUTING链 :用于目标地址转换(DNAT)。
POSTOUTING链 :用于源地址转换(SNAT)。
我们现在用的比较多个功能有3个:
filter 定义允许或者不允许的,只能做在3个链上:INPUT ,FORWARD ,OUTPUT
nat 定义地址转换的,也只能做在3个链上:PREROUTING ,OUTPUT ,POSTROUTING
mangle功能:修改报文原数据,是5个链都可以做:PREROUTING,INPUT,FORWARD,OUTPUT,POSTROUTING
*●* *包过滤匹配流程*
- 顺序比对,匹配即停止(LOG除外)
- 若无任何匹配,则按该链的默认策略处理
*●* *注意事项/整体规律*
-可以不指定表,默认为filter表
-可以不指定链,默认为对应表的所有链
-如果没有匹配的规则,则使用防火墙默认规则
-选项/链名/目标操作用大写字母,其余都小写
格式
iptables -t [表名] 选项 [链名] [条件] -j [动作]
| 参数 | 作用 |
|---|---|
| -P | 设置默认策略:iptables -P INPUT (DROP |
| -F | 清空规则链 |
| -L | 查看规则链 |
| -A | 在规则链的末尾加入新规则 |
| -I | num在规则链的头部加入新规则 |
| -D | num 删除某一条规则 |
| -s | 匹配来源地址IP/MASK,加叹号"!"表示除这个IP外。 |
| -d | 匹配目标地址 |
| -i | 网卡名称 匹配从这块网卡流入的数据 |
| -o | 网卡名称 匹配从这块网卡流出的数据 |
| -p | 匹配协议,如tcp,udp,icmp |
| --dport num | 匹配目标端口号 |
| --sport num | 匹配来源端口号 |
常用管理选项
iptables实战
7.1 配置允许ssh端口连接
$ iptables -A INPUT -s 192.168.1.0/24 -p tcp --dport 22 -j ACCEPT
# 22为你的ssh端口, -s 192.168.1.0/24表示允许这个网段的机器来连接,其它网段的ip地址是登陆不了你的机器的。 -j ACCEPT表示接受这样的请求7.2 允许本地回环地址可以正常使用
$ iptables -A INPUT -i lo -j ACCEPT
$ iptables -A OUTPUT -o lo -j ACCEPT
# 本地圆环地址就是那个127.0.0.1,是本机上使用的,它进与出都设置为允许7.3 设置默认规则
$ iptables -P INPUT DROP # 配置默认的不让进
$ iptables -P FORWARD DROP # 默认的不允许转发
$ iptables -P OUTPUT ACCEPT # 默认的可以出去7.4 配置白名单
$ iptables -A INPUT -p all -s 192.168.1.0/24 -j ACCEPT # 允许机房内网机器可以访问
$ iptables -A INPUT -p tcp -s 183.121.3.7 --dport 3380 -j ACCEPT # 允许183.121.3.7_访问本机的3380端口7.5 开启相应的服务端口
$ iptables -A INPUT -p tcp --dport 80 -j ACCEPT # 开启80端口,因为web对外都是这个端口
$ iptables -A INPUT -p icmp --icmp-type 8 -j ACCEPT # 允许被ping
$ iptables -A INPUT -m state --state ESTABLISHED,RELATED -j ACCEPT # 已经建立的连接得让它进来7.6 保存iptables规则
$ cp /etc/sysconfig/iptables /etc/sysconfig/iptables.bak # 任何改动之前先备份,请保持这一优秀的习惯
$ iptables-save > /etc/sysconfig/iptables
$ cat /etc/sysconfig/iptables7.7 禁止某个IP访问
$ iptables -I INPUT -p tcp -s 192.168.1.253 -i ens33 -j DROP
$ iptables -A INPUT -p tcp ! -s 192.168.1.1 -i ens33 -j DROP
$ iptables -A INPUT -p tcp ! -s 192.168.1.0/24 -i ens33 -j DROP选项解释: -s # 指定源地址或网段(192.168.1.0/24)。 ! 取反; -d # 指定目的地址(nat表prerouting); -i # 进入的网络接口(ens33,ens37); -o # 出去的网络接口(ens33,ens37);
7.8 禁止初跳板机以外的IP访问
$ iptables -I INPUT -p tcp ! -s 192.168.1.1 -j DROP7.9 匹配端口范围
$ iptables -I INPUT -p tcp -m multiport --dport 21,22,23,24 -j DROP
$ iptables -I INPUT -p tcp --dport 3306:8809 -j ACCEPT
$ iptables -I INPUT -p tcp --dport 18:80 -j DROP
$ iptables -A INPUT -s 127.0.0.1 -d 127.0.0.1 -j ACCEPT # 允许本地回环接口(即运行本机访问本机)
$ iptables -A INPUT -m state --state ESTABLISHED,RELATED -j ACCEPT # 允许已建立的或相关连的通行
$ iptables -A OUTPUT -j ACCEPT # 允许所有本机向外的访问
$ iptables -A INPUT -p tcp --dport 22 -j ACCEPT # 允许访问22端口
$ iptables -A INPUT -p tcp --dport 21 -j ACCEPT # 允许ftp服务的21端口
$ iptables -A INPUT -j reject # 禁止其他未允许的规则访问
$ iptables -A FORWARD -j REJECT # 禁止其他未允许的规则访问7.10 匹配ICMP类型
$ iptables -A INPUT -p icmp --icmp-type 8
# 例:iptables -A INPUT -p icmp --icmp-type 8 -j DROP
$ iptables -A INPUT -p icmp -m icmp --icmp-type any -j ACCEPT
$ iptables -A FORWARD -s 192.168.1.0/24 -p icmp -m icmp --icmp-type any -j ACCEPT7.10.1 举例
$ iptables -I INPUT -s 192.168.1.200 -j DROP # 封掉190.168.1.200
$ iptables -I INPUT -p icmp --icmp-type 8 -s 192.168.1.10 -j ACCEPT
$ iptables -I INPUT 2 -p icmp ! -s 192.168.1.1 --icmp-type 8 -j DROP # 只允许192.168.1.1 192.168.1.10可以ping
$ iptables -I INPUT -p tcp --dport 3306 -j DROP # 将3306端口封掉
$ iptables -A INPUT -p tcp -m tcp -s 192.168.0.8 -j DROP # 屏蔽恶意主机(比如,192.168.0.8
$ iptables -I INPUT -s 123.45.6.7 -j DROP # 屏蔽单个IP的命令
$ iptables -I INPUT -s 123.0.0.0/8 -j DROP # 封整个段即从123.0.0.1到123.255.255.254的命令
$ iptables -I INPUT -s 124.45.0.0/16 -j DROP # 封IP段即从123.45.0.1到123.45.255.254的命令
$ iptables -I INPUT -s 123.45.6.0/24 -j DROP # 封IP段即从123.45.6.1到123.45.6.2547.11 端口映射
$ iptables -t nat -A PREROUTING -d 10.0.1.61 -p tcp --dport 9000 -j DNAT --to-destination 172.16.1.7:22
命令拆解:
表:nat
链:PREROUTING
源IP:10.0.1.61
源端口:9000
协议:tcp
动作:DNAT
目标IP:172.16.1.7
目标端口:22
$ iptables -t nat -A PREROUTING -d 210.14.67.127 -p tcp --dport 2222 -j DNAT --to-dest 192.168.188.115:22
# 本机的 2222 端口映射到内网 虚拟机的22 端口7.12 IP映射
$ iptables -t nat -A PREROUTING -d 10.0.1.62 -j DNAT --to-destination 172.16.1.7
# 将10.0.1.62的访问请求转发到172.16.1.77.13 启动网络转发规则
$ iptables -A FORWARD -o eth0
# 只对 OUTPUT,FORWARD,POSTROUTING 三个链起作用7.14 字符串匹配
比如,我们要过滤所有TCP连接中的字符串test,一旦出现它我们就终止这个连接,我们可以这么做:
iptables -A INPUT -p tcp -m string --algo kmp --string "test" -j REJECT --reject-with tcp-reset
iptables -L7.15 阻止Windows蠕虫
$ iptables -I INPUT -j DROP -p tcp -s 0.0.0.0/0 -m string --algo kmp --string "cmd.exe"7.16 防止SYN洪水
$ iptables -A INPUT -p tcp --syn -m limit --limit 5/second -j ACCEPT7.17 列出已设置的规则
iptables -L [-t 表名] [链名]
系统审计
什么是审计
-
基于事先配置的规则生成日志,记录可能发生在系统上的事件
-
审计不会为系统提供额外的安全保护,但是会发现并记录违反安全策略的人及其对应的行为
审计能记录的日志内容:
-
日期与事件、事件结果
-
出发事件的用户
-
所有认证机制的使用都可以被记录,如ssh
-
对关键文件数据的修改行为等
审计的案例:
-
监控文件访问
-
监控系统调用
-
记录用户运行的命令
-
审计可以监控网络访问行为
-
ausearch,根据条件过滤审计日志 -
aureport,生成审计报告
yum -y install audit
systemctl start auditd
systemctl enable auditd
123| 文件 | 说明 |
|---|---|
/var/log/audit/audit.log |
日志文件 |
/etc/audit/auditd.conf |
配置文件 |
/etc/audit/rules.d/audit.rules |
规则文件 |
auditctl -h # 查看帮助
auditctl -l # 查看规则
auditctl -s # 查看状态
auditctl -D # 删除所有规则
12341)定义临时规则
定义文件系统规则,语法:
auditctl -w path -p permission -k key_name
1-
path为需要审计的文件或目录
-
权限可以是r/w/x/a(a:文件或目录的属性发生改变)
-
key_name为可选项,方便区分哪些规则生成特定的日志项
例:
auditctl -w /etc/passwd -p wa -k passwd_change
auditctl -w /usr/sbin/fdisk -p x -k disk_part
auditctl -w /etc -p w -k etc_change
1232)定义永久规则
vim /etc/audit/rules.d/audit.rules # 规则文件
-w /etc/passwd -p wa -k passwd_change # 写到文件末尾
-w /usr/sbin/fdisk -p x -k disk_part
-w /etc -p w -k etc_change
1234-
日志查询
ausearch -k KEY_NAME
ausearch -k passwd_change
ausearch -k disk_part
ausearch -k etc_change
查询结果解析:
1.执行的命令是什么 comm="fdisk" exe="/usr/sbin/fdisk"
2.谁执行的 uid=0
3.执行成功了吗 success=yes
4.什么时间执行的 time->Sat Feb 8 22:20:37 2020
123456789服务安全
1)nginx:
1.删除不需要的模块
./configure --without-http_autoindex_module # 取消默认模块的安装
./configure --help # 查看默认安装的模块
/usr/local/nginx/sbin/nginx -V # 查看编译时的选项
1232.修改版本信息
vim /nginx-1.12.2/src/http/ngx_http_header_filter_module.c
49 static u_char ngx_http_server_string[] = "Server: tomcat" CRLF;
50 static u_char ngx_http_server_full_string[] = "Server: tomcat" NGINX_VER CRL F;
51 static u_char ngx_http_server_build_string[] = "Server: tomcat" NGINX_VER_BU ILD CRLF;
重新编译安装 ./configure && make && make install
vim /usr/local/nginx/conf/nginx.conf
38 server_tokens off;
curl -i IP # 测试
123456783.限制并发
ngx_http_limit_req_module 该模块可以降低DDos攻击风险(默认安装)
vim /usr/local/nginx/conf/nginx. conf
http{
....
limit_req_zone $binary_remote_addr zone=one:10m rate=1r/s; #
server {
listen 80;
server name localhost;
limit_req zone=one burst=5;
....
123456789-
语法:limit_req_zone key zone=name:size rate=rate;
-
将客户端IP信息存储名称为one的共享内存,空间为10M 1M可以存储8千个IP的信息,10M存8万个主机
-
每秒钟仅接受1个请求,多余的放入漏斗
-
漏斗超过5个则报错
4.拒绝非法请求
-
常见HTTP请求方法 HTTP定义了很多方法,实际应用中一般仅需要
get和post
| 请求方法 | 功能描述 |
|---|---|
| GET | 请求指定的页面信息,并返回实体主体 |
| HEAD | 类似于get请求,只不过返回的响应中没有具体的内容, 用于获取报头 |
| POST | 向指定资源提交数据进行处理请求(例如提交表单或者 上传文件) |
| DELETE | 请求服务器删除指定的页面 |
| PUT | 向服务器特定位置上传资料 |
vim /usr/local/nginx/conf/nginx.conf
server {
if ($request_method !~ ^(GET|POST)$) { # 除GET和POST以外的访问请求返回错误码444
return 444;
}
....
/usr/local/nginx/sbin/nginx -s reload
12345678测试:
curl -i -X GET 192.168.4.51 # 正常访问
curl -i -X HEAD 192.168.4.51 # 访问不到
125.防止buffer溢出
-
防止客户端请求溢出
-
有效降低Dos攻击风险
vim /usr/local/nginx/conf/nginx.conf
http{
client_body_buffer_size 1K;
client_header_buffer_size 1k;
client_max_body_size 16k;
large_client_header_buffers 4 4k;
....
}
123456782) tomcat安全
yum -y install java-1.8.0-openjdk-devel
tar -xf apache-tomcat-8.0.30.tar.gz
mv apache-tomcat-8.0.30 /usr/local/tomcat
/usr/local/tomcat/bin/startup.sh
12341.隐藏版本信息
cd /usr/local/tomcat/lib/
jar -xf catalina.jar
cd org/apache/catalina/util/
vim ServerInfo.properties
server.info=nginx-1.12/8.0.30 # 伪装,访问报错时显示
server.number=1.12.2
server.built=Dec 1 2015 22:30:46 UTC
vim +69 /usr/local/tomcat/conf/server.xml
<Connector port="8080" protocol="HTTP/1.1"
connectionTimeout="20000"
redirectPort="8443" server="apache" /> # 手写server项,修改头部信息
/usr/local/tomcat/bin/shutdown.sh
/usr/local/tomcat/bin/startup.sh
12345678910111213测试:
echo tomcat > /usr/local/tomcat/webapps/ROOT/test.html
curl -I 192.168.4.51:8080/test.html
curl -I 192.168.4.51:8080
curl 192.168.4.51:8080/test.html
123452.删除默认页面
rm -rf /usr/local/tomcat/webapps/*
mkdir /usr/local/tomcat/webapps/ROOT
123.降权运行
useradd tomcat
chown -R tomcat:tomcat /usr/local/tomcat/
su - tomcat -c '/usr/local/tomcat/bin/startup.sh'
ps aux | grep java # 查看进程
12343) 数据库安全(mariadb)
] yum -y install mariadb mariadb-server
] systemctl start mariadb
] mysqladmin -uroot -p password 123456 # 设置密码,直接回车
1231.初始化安全脚本
] mysql_secure_installation # 安全优化脚本,根据提示输入选项
输入旧密码,配置新root密码
Remove anonymous users?(删除匿名账户)
Disallow root login remotely?(禁止root远程登录)
Remove test database(删除测试数据库)
Reload privilege(刷新权限)
1234562.密码安全
mysqladmin -uroot -p password PASSWORD
> set password for root@localhost=password("PASSWORD");
> update mysql.user set password=password("PASSWORD") where user="root" and host="localhost";
> flush privileges;
rm -rf ~/.mysql_history
history -c
rm -rf ~/.bash_history
12345673.数据安全
-
-
创建可以远程登录的账户
mysql -uroot -pPASSWORD
> grant select,insert,update,delete on gamedb.* to USER@'IP' identified by 'PASSWORD';
12-
通过抓包查看当前是否有客户端访问数据库服务器
[root@mysql] tcpdump -i ens33 tcp port 3306
1-
通过aide检测和audit审计记录数据库数据操作
vim /etc/aide.conf
/var/lib/mysql/ FIPSR
vim /etc/audit/rules.d/audit.rules
-w /var/lib/mysql/ -p rwxa -k mysql_data
1234打补丁
1)创建补丁文件diff
diff逐行比较
-u # 输出统一内容的头部信息(打补丁使用)
-r # 递归对比目录中的所有资源(对目录创建补丁文件时使用)
-a # 所有文件视为文本(包括二进制程序)
-N # 无文件视为空文件(有新文件时使用)
1234
] diff -u OLD_FILE NEW_FILE > NAME.patch
] cat test1.sh
#!/bin/bash
echo "hello world"
] cat test2.sh
#!/bin/bash
echo "hello world"
echo "hello sha a "
] diff -u test1.sh test2.sh > bd.patch
] cat bd.patch
--- test1.sh 2020-02-10 22:05:20.369676422 +0800
+++ test2.sh 2020-02-10 22:06:24.283682070 +0800
@@ -1,2 +1,3 @@
#!/bin/bash
echo "hello world"
+echo "hello sha a "
123456789101112131415162)打补丁patch
patch -pNUM < 补丁文件.patch
1-p指定删除补丁文件中多少层路径前缀,文件中为绝对路径时,注意根路径也算一层
] yum -y install patch
] head -2 bd.patch
--- test1.sh 2020-02-10 22:05:20.369676422 +0800
+++ test2.sh 2020-02-10 22:06:24.283682070 +0800
] patch -p0 < bd.patch
# 补丁文件中路径为当前路径,必须进入存放旧文件的目录下进行补丁
] cat test1.sh # 显示内容和test2相同,补丁成功
12345673)对目录打补丁
[root@patch ~] diff -uraN source1 source2 > dir.patch # 创建补丁文件,source1旧版本目录,source2新版本目录
[root@patch ~] head -3 dir.patch
diff -urNa source1/find source2/find
--- /root/source1/find 2020-02-10 22:52:21.003925683 +0800
+++ /root/source2/find 2020-02-10 22:57:53.495955066 +0800
[root@patch ~] ls
source1 dir.patch
[root@patch ~] patch -p2 < dir.patch # 删除文件中的"/root/"这两层路径
12345678补丁文件中旧路径为当前路径下的source1下的文件,所以打补丁时需要进入到source1所在目录进行补丁,也可以:
[root@patch ~] cd source1
[root@patch source1] patch -p3 < ../dir.patch
12
探测
sar分析系统性能
sar 命令很强大,是分析系统性能的重要工具之一,通过该命令可以全面地获取系统的 CPU、运行队列、磁盘读写(I/O)、分区(交换区)、内存、CPU 中断和网络等性能数据。
1. *查看网卡流量*
$ sar -n DEV 1 100 # 查看网卡流量,每秒输出一次,输出100次。
| IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s |
|---|
| lo 103.81 103.81 51.24 51.24 0.00 0.00 0.00 |
| eth0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 |
| eth1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 |
| eth2 24020.33 21142.79 30249.59 25842.84 0.00 0.00 0.00 |
| eth3 0.00 0.00 0.00 0.00 0.00 0.00 0.00 |
| eth4 0.15 0.00 0.01 0.00 0.00 0.00 0.00 |
| eth5 0.00 0.00 0.00 0.00 0.00 0.00 0.00 |
| eth6 10.55 2.03 0.73 1.60 0.00 0.00 0.08 |
| eth7 8.62 0.00 0.56 0.00 0.00 0.00 0.08 |
| eth8 0.00 0.00 0.00 0.00 0.00 0.00 0.00 |
| eth9 0.00 0.00 0.00 0.00 0.00 0.00 0.00 |
| bond0 19.17 2.03 1.29 1.60 0.00 0.00 0.16 |
| bond1 24020.48 21142.79 30249.60 25842.84 0.00 0.00 0.00 |
rxpck/s 和 txpck/s 分别是接收和发送的 PPS,单位为包 / 秒。
rxkB/s 和 txkB/s 分别是接收和发送的吞吐量,单位是 KB/ 秒。
rxcmp/s 和 txcmp/s 分别是接收和发送的压缩数据包数,单位是包 / 秒。
*查看网卡速率*
ethtool eth2 | grep Speed
tcpdump命令 – 监听网络流量
原文链接:https://blog.csdn.net/weixin_36338224/article/details/10703521
option 可选参数: 将在后边一一解释。 proto 类过滤器: 根据协议进行过滤,可识别的关键词有: tcp, udp, icmp, ip, ip6, arp, rarp,ether,wlan, fddi, tr, decnet direction 类过滤器:根据数据流向进行过滤,可识别的关键字有:src, dst,同时你可以使用逻辑运算符进行组合,比如 src or dst type 类过滤器: 可识别的关键词有:host, net, port, portrange,这些词后边需要再接参数。
# 基本命令
tcpdump [选项][过滤条件]
监控[选项]如下:
-i,指定监控的网络接口(默认监听第一个网卡)
-A,转换为 ACSII 码,以方便阅读
-w,将数据包信息保存到指定文件
-r,从指定文件读取数据包信息
# 持续抓包21并保存:并且过滤21端口,直到您键入Ctrl + c为止。
$ tcpdump -i ens33 -A -w ftp.cap host 192.168.2.5 and tcp port 21
# 再开一个窗口
$ ftp 192.168.2.5 # /账号:tom/密码:123 退出
$ tcpdump -A -r ftp.cap | egrep '(USER|PASS)'
.Uj6.Ud.USER tom
23:26:05.782332 IP 192.168.2.200.34430 > node1.ftp: Flags [P.], seq 11:21, ack 55, win 229, options [nop,nop,TS val 22375951 ecr 22375212], length 10: FTP: PASS 123理解 tcpdump 的输出
# 内容
21:26:49.013621 IP 172.20.20.1.15605 > 172.20.20.2.5920: Flags [P.], seq 49:97, ack 106048, win 4723, length 48
# 从上面的输出来看,可以总结出:
第一列:时分秒毫秒 21:26:49.013621
第二列:网络协议 IP
第三列:发送方的ip地址+端口号,其中172.20.20.1是 ip,而15605 是端口号
第四列:箭头 >, 表示数据流向
第五列:接收方的ip地址+端口号,其中 172.20.20.2 是 ip,而5920 是端口号
第六列:冒号
第七列:数据包内容,包括Flags 标识符,seq 号,ack 号,win 窗口,数据长度 length,其中 [P.] 表示 PUSH 标志位为 1,更多标识符见下面
traceroute命令 – 追踪网络数据包传输路径
语法格式:traceroute [参数] 域名或IP地址
| 参数 | 描述 |
|---|---|
| -d | 使用Socket层级的排错功能 |
| -f | 设置数据包的存活数值(TTL) |
| -F | 设置勿离断位 |
| -g | 设置来源路由网关 |
| -i | 使用指定的网卡发送出数据包 |
| -1 | 使用ICMP回应取代UDP资料信息 |
| -m | 检测数据包的最大存活数值(TTL) |
| -n | 直接使用IP地 址 而非主机名称 |
| -P | 设置UDP传输协议的通信端口 |
| -r | 直接将数据包送到远端主机上 |
| -S | 设置本地主机送出数据包的IP地址 |
| -t | 设置检测数据包的TOS数值 |
| -V | 详细显示指令的执行过程 |
| -W | 设置等待远端主机回报的时间 |
| -X | 开启或关闭数据包的正确性检验 |
端口探测
1、使用telnet判断
]# telnet 192.168.1.30 8080
Trying 192.168.1.30...
Connected to 192.168.1.30. #看到Connected就连接成功了
Escape character is '^]'.
Protocol mismatch. 协议不匹配
Connection closed by foreign host. 连接被外部主机关闭2、使用ssh判断
用法: ssh -v -p port username@ip -v 调试模式(会打印日志). -p 指定端口
username 可以随意
# 端口存在
]# ssh 192.168.1.30 -p 8080
ssh_exchange_identification: Connection closed by remote host远程主机关闭连接
# 端口不存在
]# ssh 192.168.1.30 -p 80
ssh: connect to host 192.168.1.30 port 80: Connection refused 连接拒绝3、使用wget判断
# 不存在
[root@test apache-tomcat-9.0.6]# wget 192.168.1.30:80
--2021-04-26 17:30:19-- http://192.168.1.30/
正在连接 192.168.1.30:80... 失败:拒绝连接。
# 端口存在
[root@test apache-tomcat-9.0.6]# wget 192.168.1.30:8080
--2021-04-26 17:30:31-- http://192.168.1.30:8080/
正在连接 192.168.1.30:8080... 已连接。
已发出 HTTP 请求,正在等待回应... 404
2021-04-26 17:30:31 错误 404:(没有描述)。4、nmap端口扫描工具
Nmap 用于端口扫描,网络安全专家攻击的阶段之一,是有史以来最好的网络安全专家工具。它主要是一个命令行工具,后来被开发基于 Linux 或 Unix 的操作系统,现在可以使用 Windows 版本的 Nmap。
# nmap超详细使用
nmap -sT 192.168.227.133 # TCP扫描
nmap -sU 192.168.227.133 # UDP扫描
nmap -sS 192.168.227.1 # SYN半开放扫描
nmap -n -sP 192.168.4.0/24 #检查那些主机可以ping通
nmap -p 8080 #
# 主机发现
-sL 仅仅是显示,扫描的IP数目,不会进行任何扫描
-sn ping扫描,即主机发现
-Pn 不检测主机存活
-PS/PA/PU/PY[portlist] TCP SYN Ping/TCP ACK Ping/UDP Ping发现
-PE/PP/PM 使用ICMP echo, timestamp and netmask 请求包发现主机
-PO[prococol list] 使用IP协议包探测对方主机是否开启
-n/-R 不对IP进行域名反向解析/为所有的IP都进行域名的反响解析
# 扫描技巧
-sS/sT/sA/sW/sM TCP SYN/TCP connect()/ACK/TCP窗口扫描/TCP Maimon扫描
-sU UDP扫描
-sN/sF/sX TCP Null,FIN,and Xmas扫描
--scanflags 自定义TCP包中的flags
-sI zombie host[:probeport] Idlescan(闲置扫描)
-sY/sZ SCTP INIT/COOKIE-ECHO 扫描
-sO 使用IP protocol 扫描确定目标机支持的协议类型
-b “FTP relay host” 使用FTP bounce scan
# 指定端口和扫描顺序
-p 特定的端口 -p80,443 或者 -p1-65535
-p U:PORT 扫描udp的某个端口, -p U:53
-F 快速扫描模式,比默认的扫描端口还少
-r 不随机扫描端口,默认是随机扫描的
--top-ports "number" 扫描开放概率最高的number个端口,出现的概率需要参考nmap-services文件,ubuntu中该文件位于/usr/share/nmap.nmap 默认扫前1000个
--port-ratio "ratio" 扫描指定频率以上的端口
-T < 0-5 > 设置时间模板(越高越快)
“s”(秒) “m”(分钟),或“h”(小时)的价值(如30米)。
]# nmap -T4 –sS –Pn 10.212.222.120
实例
nmap -sS -T4 http://www.fakefirewall.com //探测端口开放状态
nmap -sF -T4 http://www.fakefirewall.com // FIN扫描识别端口是否关闭
nmap -sA -T4 http://www.fakefirewall.com // ACK扫描判断端口是否被过滤
nmap -sW -p- -T4 http://docsrv.caldera.com //发送ACK包探测目标端口(只适合TCPIP协议栈)
5、使用专用工具tcping进行访问:
下载软件地址:https://elifulkerson.com/projects/tcping.php
总结
三个工具的共同点是:1.以tcp协议为基础;2.能访问指定端口. 遵循这两点可以找到很多工具

 浙公网安备 33010602011771号
浙公网安备 33010602011771号