
操作系统(八)—— 零拷贝(zero copy)
概述
第一次听说这个概念是在看kafka原理的时候,因为当时很好奇为什么kafka一个基于磁盘存储的MQ会那么快,当时找到的答案是kafka采用磁盘顺序读写和零拷贝技术,从而使得kafka的吞吐量非常大。本文就介绍一下操作系统中的零拷贝技术原理,之后会介绍kafka是如何使用操作系统的零拷贝技术实现高性能的。
为什么使用零拷贝
为了说明零拷贝的好处,这里先举两个例子,这两个例子都没有使用零拷贝技术,通过这两个例子,大家应该明白为什么要使用零拷贝。
示例一:传统文件访问
看下图
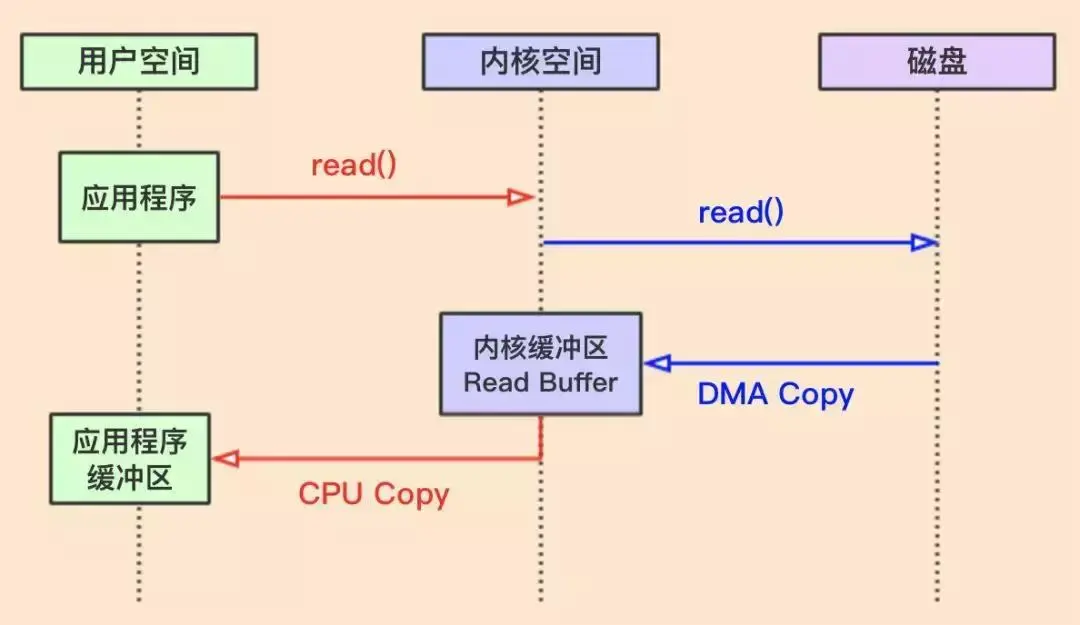
图片来源:零拷贝(zero-copy)
上图过程解析如下:
- 进程向操作系统发起read系统调用,进行上下文切换,切换到内核态,需要将磁盘数据读入内存,自己进入阻塞状态
- 操作系统向磁盘发起请求,磁盘将数据导入到磁盘驱动缓冲区,无需使用CPU,当驱动器缓冲区满了之后,向操作系统发起中断请求,告诉操作系统自己的缓冲区满了
- 操作系统将驱动器缓冲区的数据拷贝到内核缓冲区,此步骤为DMA copy
- 如果内核中的数据少于用户请求数据,重复步骤2和步骤3,直到数据达到要求为止
- 将数据从内核缓冲区拷贝到用户缓冲区,此过程为CPU Copy,同时从系统调用中返回,进行上下文调用,切换到用户态
从上面解析过程可知,传统读操作,总共需要2次上下文切换,3次Copy,图中显示的是两次,一次为DMA Copy,一次为CPU Copy,其实还有一次从磁盘拷贝到驱动器缓冲区,可能是因为这个是无法避免,所以我看很多文章没有提这个。
上面提到一个新的概念DMA Copy,在我的一篇文章有提到,操作系统访问磁盘有三种方式,其中之一就是DMA,下面就介绍一下DMA工作过程。
- 进程向操作系统发起read系统调用,进行上下文切换,切换到内核态,需要将磁盘数据读入内存,自己进入阻塞状态
- CPU收到之后,将请求交给DMA,自己去忙其他事情
- DMA向磁盘发起请求
- 磁盘将数据读到磁盘驱动器缓冲区中,当缓冲区数据满了之后,向操作系统发起中断请求
- DMA将缓冲区的数据复制到内核缓冲区中
- 如果数据少于用户请求数据,重复不走4和步骤5,直到数据达到要求为止,此时DMA向操作系统发起中断请求
- CPU将内核缓冲区的数据拷贝到用户缓冲区
从以上解析过程可以发现,DMA其实就是CPU的一个代理,与磁盘进行交互,因为磁盘速度太慢,CPU直接和磁盘交互太浪费CPU时间,所以搞了一个小弟(DMA),让这个小弟替自己干活。
小结
以上过程比较浪费的一点是从内核缓冲区拷贝到用户缓冲区,这个过程基本什么事情都没有干,只是一个拷贝,而且需要CPU参与,如果数据量非常大,这个过程是非常浪费时间的,而且在内存中保存两份数据,也浪费空间,而零拷贝要的事情是什么呢?就是能不能把这个过程给避免了,在内存中只保留一份数据,让用户空间和内核空间共享,但是从磁盘缓冲区拷贝内存这个步骤是无法避免的,所以零拷贝并不是真的是0次拷贝,而是尽量减小拷贝的次数,算是一种优化拷贝过程的方法。

上面介绍的传统的读请求,其实写请求也是一样,先从用户缓冲区拷贝到内核缓冲区,之后再写到磁盘上,也是两次复制,如果让用户缓冲区和内核缓冲区共享就可以减少一次复制,实际上kafka也是这样做的,调用的是操作系统提供的系统调用mmap,mmap可以让磁盘文件直接映射到内存,并且用户空间和内核空间共享同一个缓冲区,在向kafka中写数据的时候就是这个过程。
示例二:发送数据到网络
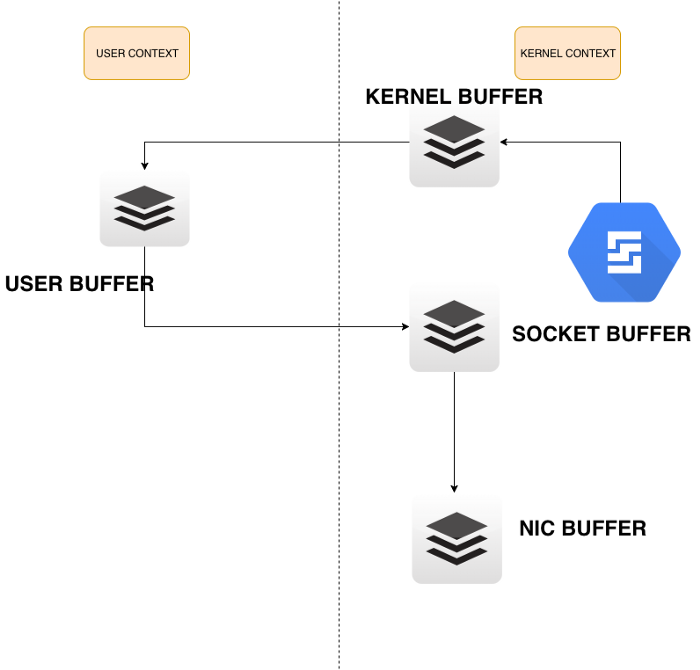
图片来源:Zero-Copy in Linux
上图过程解析如下:
- 将磁盘数据通过DMA拷贝到内核缓冲区(为了简写,就不写磁盘驱动器缓冲区了)
- CPU将内核缓冲区数据拷贝到用户缓冲区
- CPU将用户缓冲区数据拷贝到socket缓冲区
- DMA将socket缓冲区数据拷贝到网卡
以上过程总共发生了四次上下文切换,四次拷贝,四次上下文切换如下
- 从用户空间发起read系统调用,去磁盘获取数据,从用户态切换到内核态,发生第一次上下文切换
- 当数据准备好之后,从内核态把数据拷贝到用户态,发生第二次上下文切换
- 把数据从用户缓冲区拷贝到内核socket缓冲区,发生第三次上下文切换
- 发送完之后,重进进入用户态正常执行,发生第四次上下文切换
小结
大家可能发现,在四次拷贝过程中,第二次和第三次好像什么也没有做,就是转了一个圈,那能不能把第二次和第三次给优化掉,直接从内核缓冲区拷贝到网卡呢?答案是可以的,使用操作系统提供的接口就可以实现,比如linux的sendfile,实际上在消费者从kafka中消费数据的时候就是使用sendfile优化的。
零拷贝的几种方法
下面会介绍几种常见的零拷贝技术,以及他们的特点。
第一种方法:mmap
英文Memory Mapped Files,简称mmap,从英文名称就可以看出叫做内存映射文件,就是把磁盘上的一个文件通过DMA拷贝到内存,然后对内存文件的操作就像直接操作磁盘文件一样,由于文件在内存中以页的方式存储,当有些页被修改之后,需要把脏页刷新回磁盘,这时不需要像传统的方式发起write系统调用,这时可以直接将内存中的脏页刷新回磁盘,无需CPU参与,无需上下文切换。
mmap具体流程
- 进程启动映射过程,并在虚拟地址空间创建映射区域
- 调用系统调用函数mmap,实现虚拟地址空间和物理地址空间的映射
- 进程发起对映射空间的访问,引发缺页中断,将磁盘上的数据拷贝到内存中
以上过程中只在第三步进程需要使用这一页的数据,比如进行read或者write操作时,才会把磁盘上的数据通过DMA将磁盘数据拷贝到内核缓冲区。在第二步处于用户空间的进程直接将虚拟地址空间映射到内核缓冲区,无需将处于内核的数据拷贝到用户进程。除此之外,处于内核空间的缓冲区可以被映射到多个进程,也就是说多个进程可以通过共享内存,而无需在内存中保存多份重复数据,多个进程共享数据的过程如下。
- 进程A读取某一页的数据,发现内存中没有,引发缺页中断,DMA将磁盘数据拷贝到内存
- 进程B也需要同一页的数据,引发缺页中断,这时并不会再去磁盘读取,而是直接将虚拟地址空间映射到进程A刚刚访问物理地址空间上
是不是觉得mmap很牛批,但mmap也不是万能的,即便是少了一次复制过程,如果对磁盘进行随机读写的话,速度也是慢的一匹,顺序读写还可以,而且写到mmap的数据并没有刷到磁盘,在程序主动调用flush的时候,操作系统才会把缓冲区的数据刷到磁盘,Kafka提供了一个参数——producer.type来控制是不是主动flush;如果Kafka写入到mmap之后就立即flush然后再返回Producer叫同步(sync);写入mmap之后立即返回Producer不调用flush叫异步(async)。
第二种方法:sendfile
针对上面的示例二,通过sendfile系统调用可以解决这个问题,在linux 2.1时,采用如下做法:
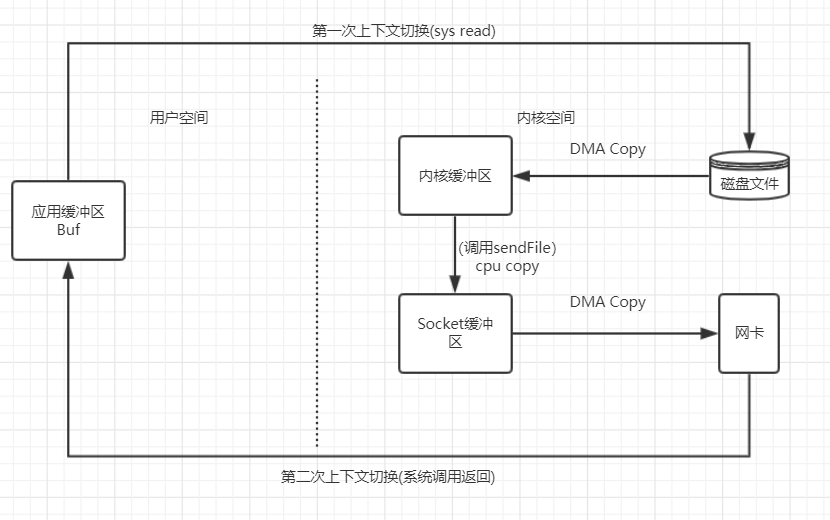
图片来源:Linux Zero-copy(零拷贝)
从上图可以看出,这个优化只是把从内核空间拷贝到用户空间的过程给去掉了,但是在内核内部,依然需要从内核缓冲区拷贝到socket缓冲区,而且这个拷贝是CPU Copy,这个过程也是其实也是不需要的,又没有做什么别的工作,纯粹就是拷贝。
从linux 2.4之后,上面那个CPU Copy就给干掉了,如下图:
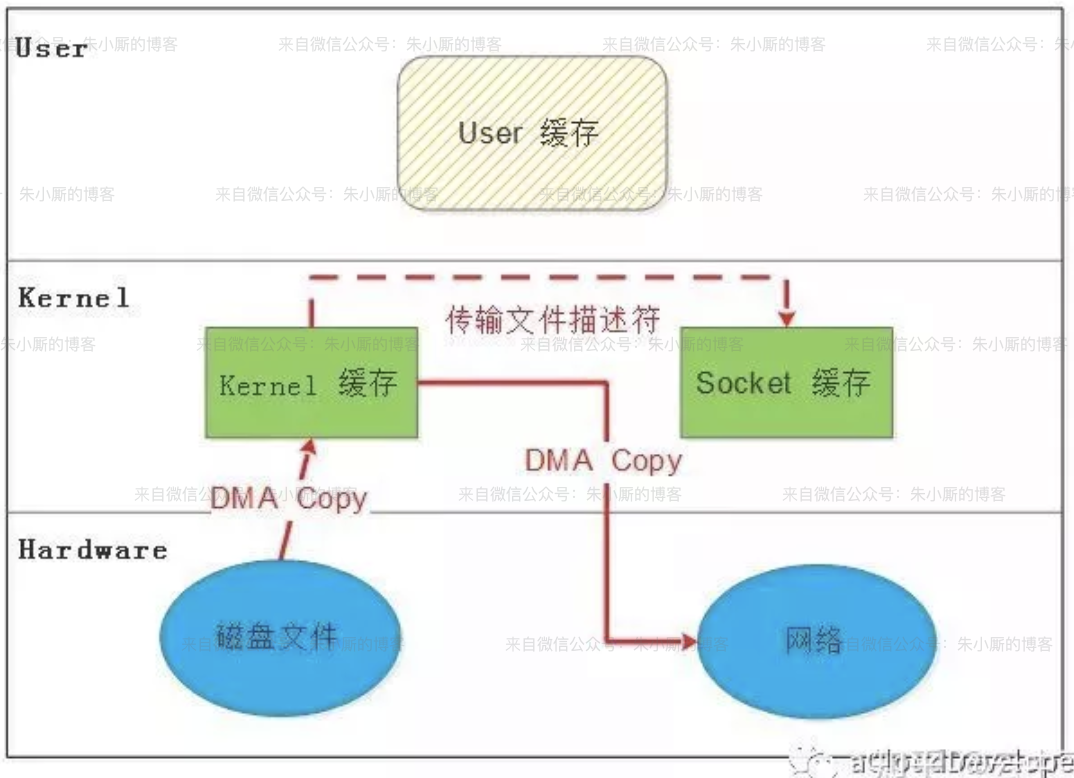
从图中可以看出,从内核缓冲区向socket缓冲区依然有复制过程,但是只是复制了文件描述符(定义:内核(kernel)利用文件描述符(file descriptor)来访问文件。文件描述符是非负整数。打开现存文件或新建文件时,内核会返回一个文件描述符。读写文件也需要使用文件描述符来指定待读写的文件。),数据其实是直接从内核缓冲区拷贝到网卡的。
第三种方法:splice
上面的sendfile已经可以实现0次CPU 拷贝了,但是在linux2.6的时候又新增了一个新的系统调用splice,为什么要新增splice呢?下面是linus大佬的解释:
- the pipe _is_ the buffer. The reason sendfile() sucks is that sendfile cannot work with <n> different buffer representations. sendfile() only works with _one_ buffer representation, namely the "page cache of the file". By using the page cache directly, sendfile() doesn't need any extra buffering, but that's also why sendfile() fundamentally _cannot_ work with anything else. You cannot do "sendfile" between two sockets to forward data from one place to another, for example. You cannot do sendfile from a streaming device.
上面这段话的大致意思是sendfile()非常的烂(sucks),因为sendfile只能将数据从文件拷贝到别的缓冲区,比如把文件拷贝到socket缓冲区,而不能从一个socket缓冲区拷贝到另一个socket缓冲区或者别的场景。
splice和sendfile不同,他可以适用于任意两个文件描述符之间互相通信。通过管道实现,两个缓冲区中间连接一个管道,但是并不是把第一个缓冲区的数据拷贝到pipe,而是将指针(引用)拷贝进去。
总结
零拷贝其实最主要的优化就是CPU Copy减少为0,因为拷贝过程非常浪费CPU时间,所以尽量把这个时间减小,引入DMA作为CPU的一个代理,也是为了让CPU可以做别的事情,因为像磁盘这样的设备性能太差,如果让CPU直接访问,那就太浪费了。

前几篇文章一直在介绍进程,零拷贝之前一直没有搞清楚是什么,最近正好在学习操作系统,所以就顺便学了一下,下一篇介绍操作系统文件管理。
参考:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号