YeYuan-DiversifyingLatentFlowsForDiverseHumanMotionPrediction-ECCV
DLow: Diversifying Latent Flows for Diverse Human Motion Prediction #paper
1. paper-info
1.1 Metadata
- Author:: [[Ye Yuan]], [[Kris Kitani]]
- 作者机构:: Carnegie Mellon University
- Keywords:: #HMP , #CVAE
- Journal:: #ECCV
- Date:: [[2020-07-22]]
- 状态:: #Done
- 链接:: http://arxiv.org/abs/2003.08386
- 修改时间:: 2022.10.29
1.2Abstract
Deep generative models are often used for human motion prediction as they are able to model multi-modal data distributions and characterize diverse human behavior. While much care has been taken into designing and learning deep generative models, how to efficiently produce diverse samples from a deep generative model after it has been trained is still an under-explored problem. To obtain samples from a pretrained generative model, most existing generative human motion prediction methods draw a set of independent Gaussian latent codes and convert them to motion samples. Clearly, this random sampling strategy is not guaranteed to produce diverse samples for two reasons: (1) The independent sampling cannot force the samples to be diverse; (2) The sampling is based solely on likelihood which may only produce samples that correspond to the major modes of the data distribution. To address these problems, we propose a novel sampling method, Diversifying Latent Flows (DLow), to produce a diverse set of samples from a pretrained deep generative model. Unlike random (independent) sampling, the proposed DLow sampling method samples a single random variable and then maps it with a set of learnable mapping functions to a set of correlated latent codes. The correlated latent codes are then decoded into a set of correlated samples. During training, DLow uses a diversity-promoting prior over samples as an objective to optimize the latent mappings to improve sample diversity. The design of the prior is highly flexible and can be customized to generate diverse motions with common features (e.g., similar leg motion but diverse upper-body motion). Our experiments demonstrate that DLow outperforms state-of-the-art baseline methods in terms of sample diversity and accuracy. Our code is released on the project page: https://www.ye-yuan.com/dlow.
Human motion prediction 、Deep generative model
Most existing generative huamn motion prediction methods can not efficiently produce diverse samples. 两个原因:
- The independent sampling cannot force the samples to be diverse
- The sampling is based solely on likelihood which may only produce samples that correspond to the mayor models of the data distribution.
contributions: - a novel sampling method---Diversifying Latent Flows(DLow)
- a diversity-promoting prior
1.3 Introduction
- 领域:
- Diversity Human motion prediction:由于人体动作的多样性,导致预测麻烦,并且预测多样性的人体动作很重要。
- 之前的方法:
Deep generative model生成动作序列。- 问题:
- 潜变量随机采样,无法达到多样性。
- 原因:
- 采样独立,无法集中多样性。
- 采样优化是基于似然函数的,也就是说采样的只会集中于数据的主要特征,而忽略了边缘特征。
- 问题:
- 针对问题,作者提出的方法:
- 一种新的采样方法--
Diversitying Latent Flows - 针对采样独立的问题:通过一个可学习的确定性映射函数,将随机变量映射成一组相关联的潜在变量,然后通过预训练生成模型的
decoder生成多样性的动作序列。 - 针对基于似然函数的优化函数无法捕捉到边缘特征的问题:作者提出了一种新的优化函数
a diversity-promoting prior,该函数是基于采样距离的能量函数。
- 一种新的采样方法--
- contribution
- 提出了一种新的采样方法,能够在一个预训练生成模型上进行采样。
- 提出了基于多样性的优化函数,能够平衡多样性和精确性。
- 该方法能够通过控制
diversity-promoting prior来控制动作的生成。
2. Diversifying Latent Flows(DLow)
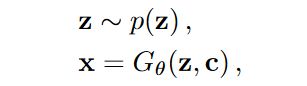
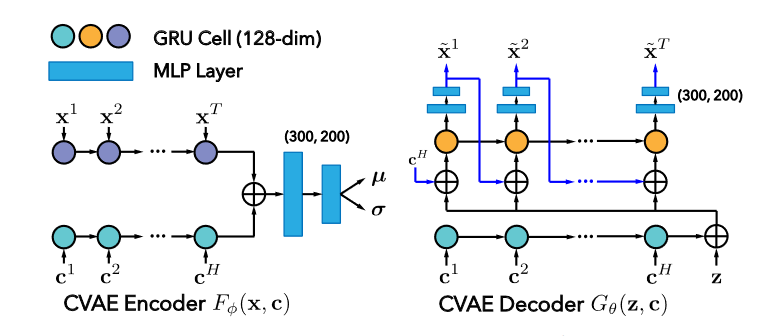
未经改进过的生成网络的数学表示如图2-1, 通过采样\(z\),加上条件\(c\),在经过学习好的网络\(G_\theta\) 就可以生成出新样本。这样的模型生成出来的数据多样性不高。主要原因是因为\(z\)是由\(encoder\) 产生,而且是基于分布的似然函数去优化的,导致学习到的分布丢失了多余的特征,失去了多样性。
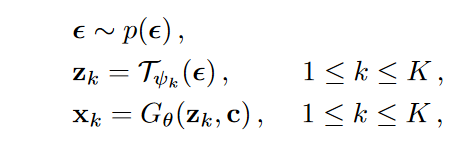
\(p(\epsilon ) \in Gaussian, distribution\)
\(\tau _{\psi _1},...,\tau _{\psi _K}\) 是latent mapping function, 参数\(\psi = \left \{ \psi_1, \psi _2,...,\psi_K \right \}\)
图2-2 是本文的DLow方法。在latent code之上加了一个mapping function,增加了潜变量的多样性。

图2-3 为整个生成模型,由DLow得到latent z,然后和条件c 一起送入CVAE decoder中, 不同的\(z\)会产生不同的动作序列,从而保障了多样性。
2.1 DLow sampling
\(p_\theta (X|Z,c)\)是由decoder\(G_\theta(z,c)\)学习的条件概率分布。
\(r_\psi (Z|c)\)是由\(p(\epsilon )\) 通过mapping function\(\tau _{\psi _1},...,\tau _{\psi _K}\) 学习而来。
因为decoder的参数固定,所以只有\(\psi\)为参数。
optimization: loss function 推导
\(p(x)\): diverity-promoting prior,
文章中最小化采样分布\(r_\psi(X|c)\) 与diverity-promoting prior \(p(x)\) 之间的交叉熵为优化目标,如公式(1);但是这样生成出的\(X\)会产生很大的偏差,因为此时的latent code z与生成模型需要的\(z\) 差距较大,所以在(1)的基础上加上约束得到(2), 该KL散度约束能够使得新生成的\(Z\)尽可能的与生成模型原有的\(Z\)一致。这一项也是控制多样性与准确性之间的关键变量,然后将带有约束条件的最小化问题用拉格朗日公式描述得到(3)
简写:
\(\beta\) 是可以自己设置的超参数,如果\(\beta\)很大,说明该\(KL\)在优化目标占大头,也就是生成出的\(Z\)会与原生成模型的\(Z\) 保持一致,然后精确度就会更高,多样性就会降低;\(\beta\)偏小时,结果相反,多样性就会增加。
2.2 Latent Mapping functions
\(\tau _{\psi _k(\epsilon )}\)能够将高斯分布\(p(\epsilon)\)转变为边缘潜变量分布\(r_\psi (z_k|c)\) ,并且在该映射依然以\(c\)(原始输入序列)为条件。在理想情况下,\(r_\psi (z_k|c)\) 与\(p(z_k)\)相似,也为一个高斯分布。
\(\epsilon\)的维度为\(n_z\);\(b_k \in \mathbb{R}^{n_z}\)是一个向量,类似于偏置;\(n_z\)是latent code z的维度; \(A_k\in \mathbb{R} ^{n_z\times n_z}\)为非奇异矩阵non-singular matrix。
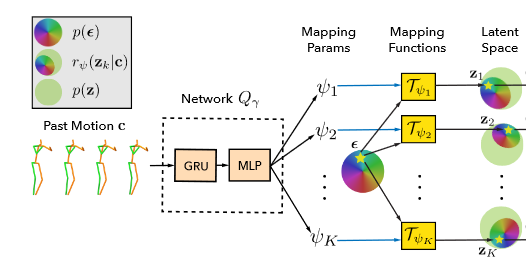
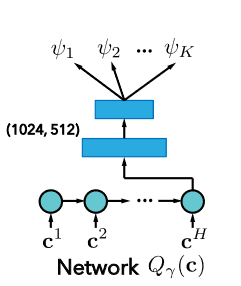
作者通过K-head network\(\mathcal{Q}_r(c)\) 输出\(\psi_1,...,\psi_K\) ,这些参数能够通过\((3)\) 学习。\(\mathcal{Q}_r(c)\)的网络结构如图2-5
经过该可逆仿射变换之后invertible affine transformation之后,\(r_\psi (z_k|c) \in \mathcal{N} (b_k, A_kA_k^T)\) ,由于两个高斯分布的KL值可以求解,于是:
\(KL\)最小时,\(r_\psi (z_k|c) = p(z_k)\) 可以推出\(A_kA_k^T=I, b_k=0\) ,此时\(A_k\)是一个正交矩阵,说明该空间内的所有旋转或反射操作都可以最小化\(KL\; divergence\) .。
2.3 Diversity-Promoting Prior
我们可以通过energy function\(E(X)\)来定义\(p(X)\):
\(S\)是归一化常数,忽略该常数,\(L_{prior}\)可以写作:
为了能够促进采样多样化,作者基于pairwise distance metirc\(\mathcal{D}\) 设计了\(E:=E_d\)
在后文中,作者通过使用不同的E方程式,来控制不同动作的生成。
思考: 如果仅仅要达到多样性的效果,为何要重新重c中学习潜变量Z?为何不直接在原有的Z中加入mapping function,感觉也可以达到多样性的效果;在我理解看来,就是在原有的基础上,加入了噪声,使得多样性增加。但是 作者在后面介绍了该方法可以控制动作生成(eg. we want leg motion to be similar but upper-body motion to be diverse across motion samples)
3. Diverse Human Motion Prediction
\(c \in \mathbb{R} ^{H\times V}\) denote the pase motion of H time steps
\(X\in \mathbb{R} ^{T\times V}\) denote the future motion over a future time horizon of T.
the goal of diverse human motion prediction is to generate a diverse set of future motions \(X={x_1, ...,x_K}\)
作者在一个预训练生成模型上加入DLow从而生成多样化的动作序列。
CVAE: 预训练模型
can capture the multi-modal distribution of the future trajectory \(x\) and can learn the future trajectory distribution \(p_\theta(x|c)\)
3.1 Diversity Sampling with DLow
可以通过使用不同的\(E(x)\)来达到不同的目的 ,作者举了两个列子:
- improve sample accuracy
- enable new applications such as controllable motion prediction
3.1.1 Reconstruction Energy
在(6)的基础上修改prior energy function E,增加了重构误差reconstruction term \(E_r\)
加入重构误差之后,可以通过修改\(\lambda_r\)来平衡多样性和精确性。
3.1.2 Controllable Motion Prediction
Another possible design of the diversitypromoting prior p(X) is one that promotes diversity in a certain subspace of the sample space. In the context of human motion prediction, we may want certain body parts to move similarly but other parts to move differently.
将人体关节点分为两个部分\(J_s\)和\(J_d\), 我们希望采样后的\(X\)在\(J_s\)关节点保持相似,而多样性发生在\(J_d\) 。
将采样的\(x_k\)分为两部分:\(x_k=(x_k^s, x_k^d)\),分布表示\(J_s\)和\(J_d\)关节的表征。
所以:\(X_s = \left \{ X_1^s,...,X_K^s \right \}\) 和\(\left \{ X_1^d,...,X_K^d \right \}\)
修改先验\(p(x)\):
还可以通过参考动作采样\(x_{ref}\)去生成需要的特征。将\(x_{ref}\)当做第一次采样\(x_1\) ,通过CVAE encoder计算出对应的\(z_{ref} = F^\mu_\phi(x_{ref},c)\) ,然后通过\(\tau _{\psi_1}^{-1}\) 计算出\(z_{ref}\)对应的\(\epsilon _{ref}\) 。在\(\epsilon _{ref}\) 已知的情况下,可以生成包含\(x_ref\)的\(X\) .
4. Experiments
- Datasets
- Human3.6M
- HumanEva-I
- Baselines
- Deterministic motion prediction methods
- ERD
- acLSTM
- Stochastic motion prediction methods
- CVAE based methods:
- Pose-Know
- MT-VAE
- CGAN based mothods:
- HP_GAN
- CVAE based methods:
- Diversity-promoting methods for generative models
- Best-of-Many
- GMVAE
- DeLiGAN
- DSF
- Deterministic motion prediction methods
- Metrics
- Average Pairwise Distance (APD)
- Average Displacement Error (ADE)
- Final Displacement Error (FDE)
- Multi-Modal ADE (MMADE)
- Multi-Modal FDE (MMFDE)
- Implementation Details

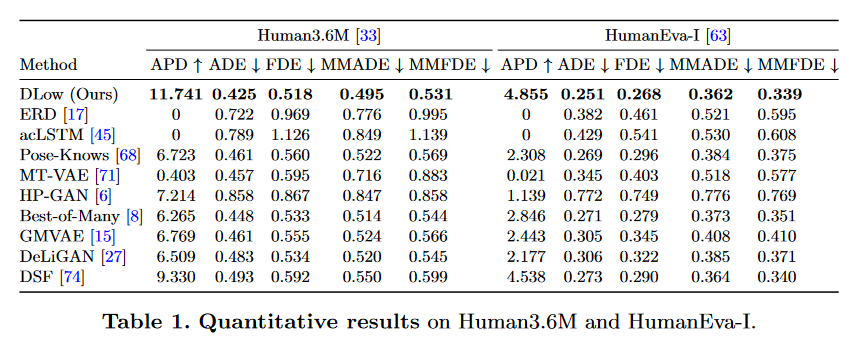
4.1 Quantitative Results
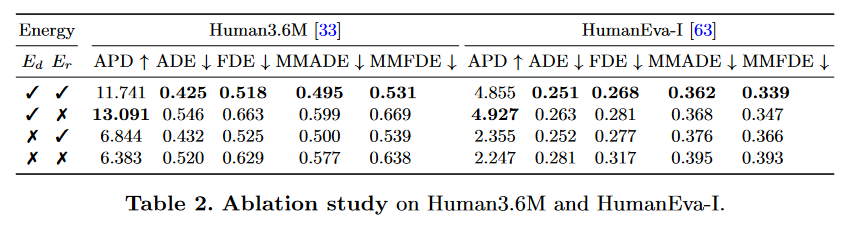
4.2 Ablation Study
4.3 Qualitative Results
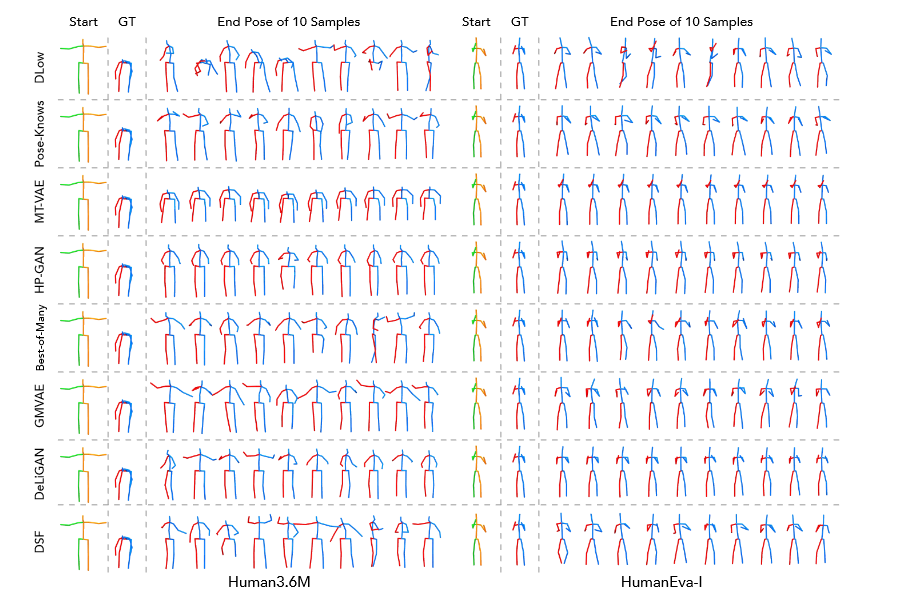
- Diversity vs. Likelihood
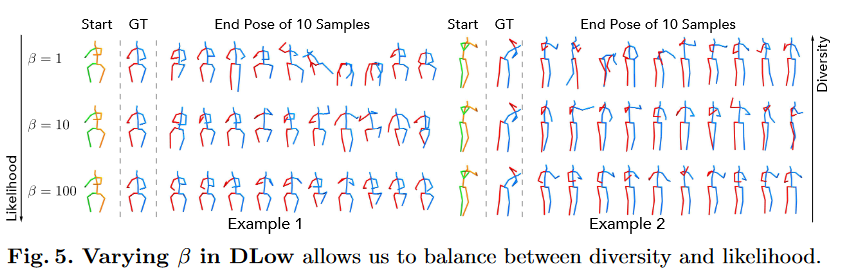
- Effect of varying
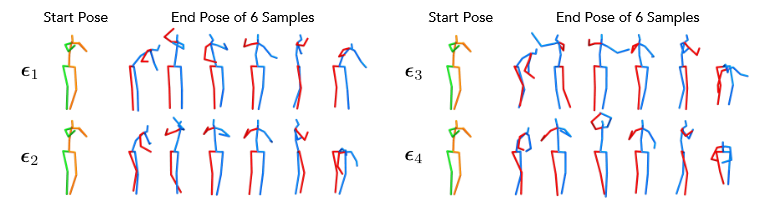
- Controllable Motion Prediction
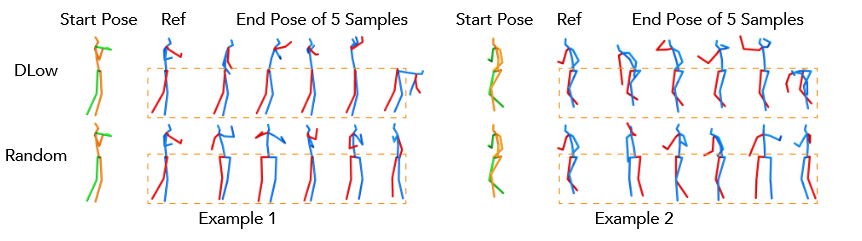
5. 总结
DLow的主要贡献是学习特征映射,用变换函数来实现学习潜在空间中的多模态(数据的多种模式),从而实现 diverse prediction。之所以不使用预训练模型训练好的z,我觉得是因为该z自包含了共有特征,无法通过变换函数学习到多余的边缘特征。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号