C++学习笔记 07 字符串
一、默认编码
ASCII
ASCII可以拓展为很多,比如UTF-8、UTF-16、 UTF-32 还有宽字符(wide string)
当然,字符其实是可以大于一个字节的,在其他语言中(日语、中文)有两个、三个、四个字节的字符。
二、大小
1字节 byte, 就是8bit,= 2^8 = 256 种字符。 如果把英文字母,数字、符号,日文、中文韩文等这些放在一起肯定多余256。这样8bit就不够用了,没有办法适配所有的语言。所以有了UTF-16,就是16位的字符编码,这意味着我们有2的16次方可能性,就是65536。还有其他编码。
但是在C++基础语言中,不使用任何库,只是原始数据类型的话,char是1字节。当你在C++中使用一个字符串,就是普通字符串,普通字符,而不是2字节的宽字符。
我们说的就是一个字节的字符,就是我们日常的英语;而如果使用其他 语言,比如俄语,那就没法使用这个(1个字节字符),你必须使用其他字符编码。
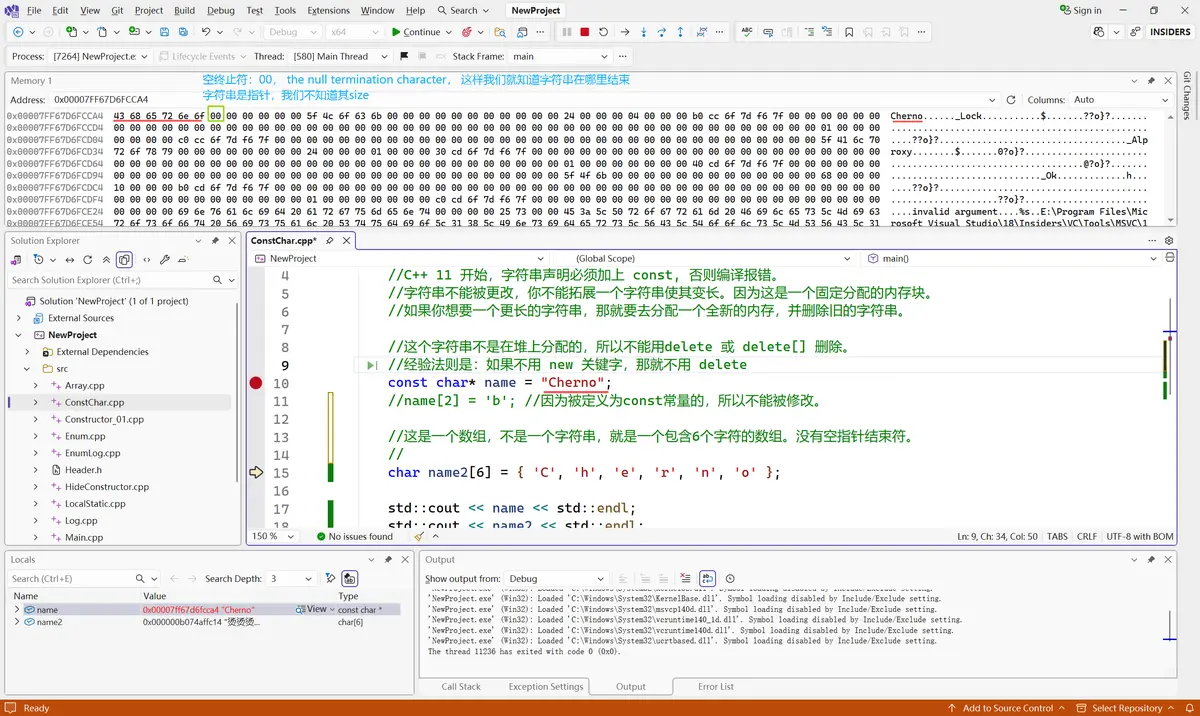
三、指针形式字符串 (字符串终止符:00)
空终止符:00, the null termination character, 这样我们就知道字符串在哪里结束。对于字符串指针变量,我们不知道其size,它是一个指针。那么我们怎么找出其大小呢?这就是能用到空终止符的地方了:字符串从指针的内存地址开始,直到0结束。
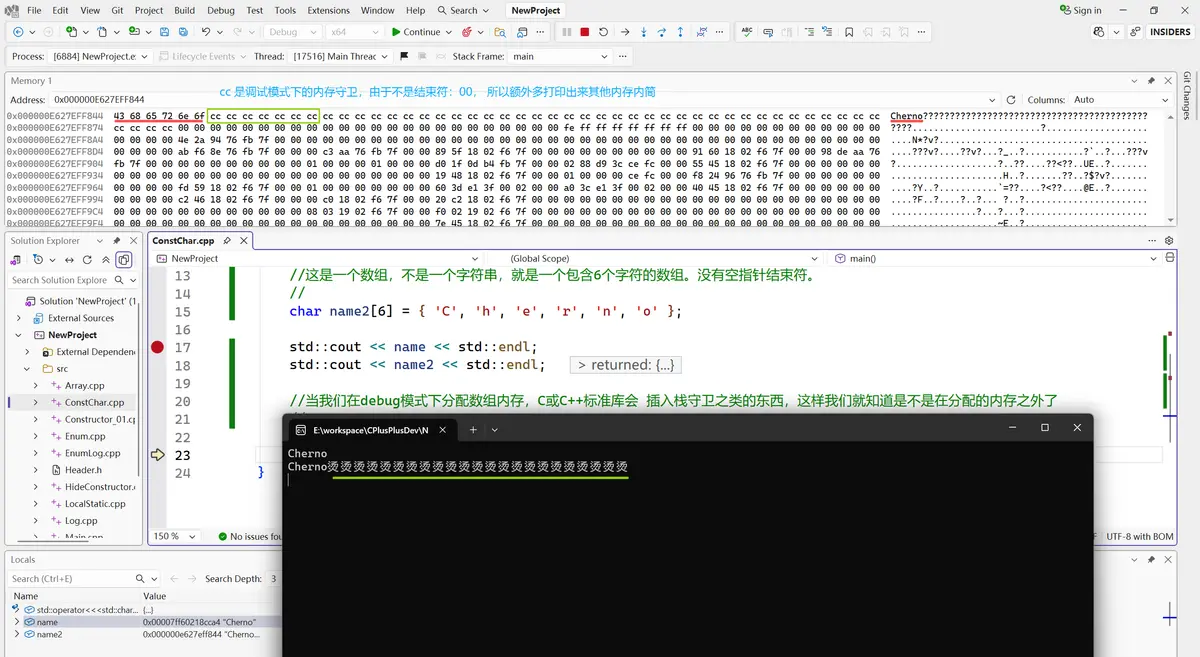
四、纯数组形式的字符串(内存守卫:cc)
char name2[6] = { 'C', 'h', 'e', 'r', 'n', 'o' };
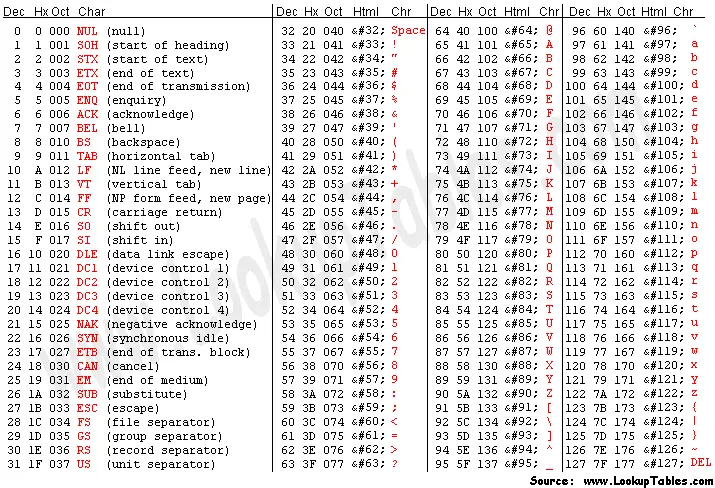
https://www.asciitable.com/asciifull.gif
五、字符串类string
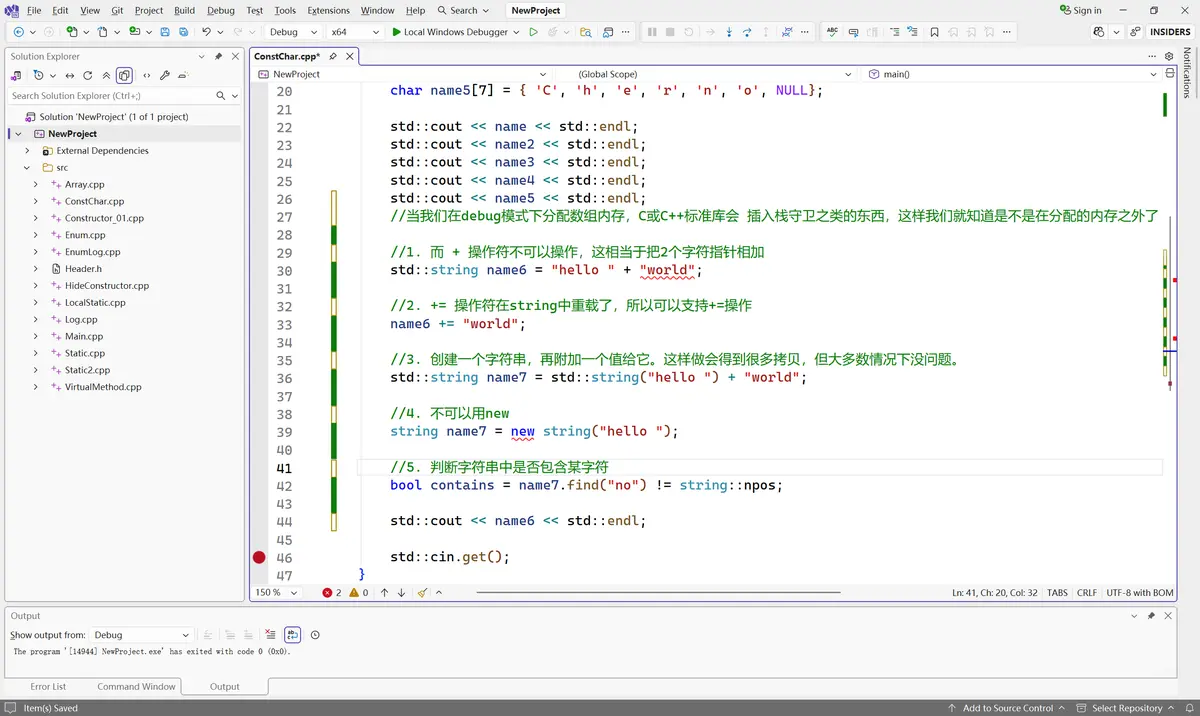
完整源码:
#include<iostream>
#include<string>
using namespace std;
int main() {
//C++ 11 开始,字符串声明必须加上 const, 否则编译报错。
//字符串不能被更改,你不能拓展一个字符串使其变长。因为这是一个固定分配的内存块。
//如果你想要一个更长的字符串,那就要去分配一个全新的内存,并删除旧的字符串。
//这个字符串不是在堆上分配的,所以不能用delete 或 delete[] 删除。
//经验法则是:如果不用 new 关键字,那就不用 delete
const char* name = "Cherno";
//name[2] = 'b'; //因为被定义为const常量的,所以不能被修改。
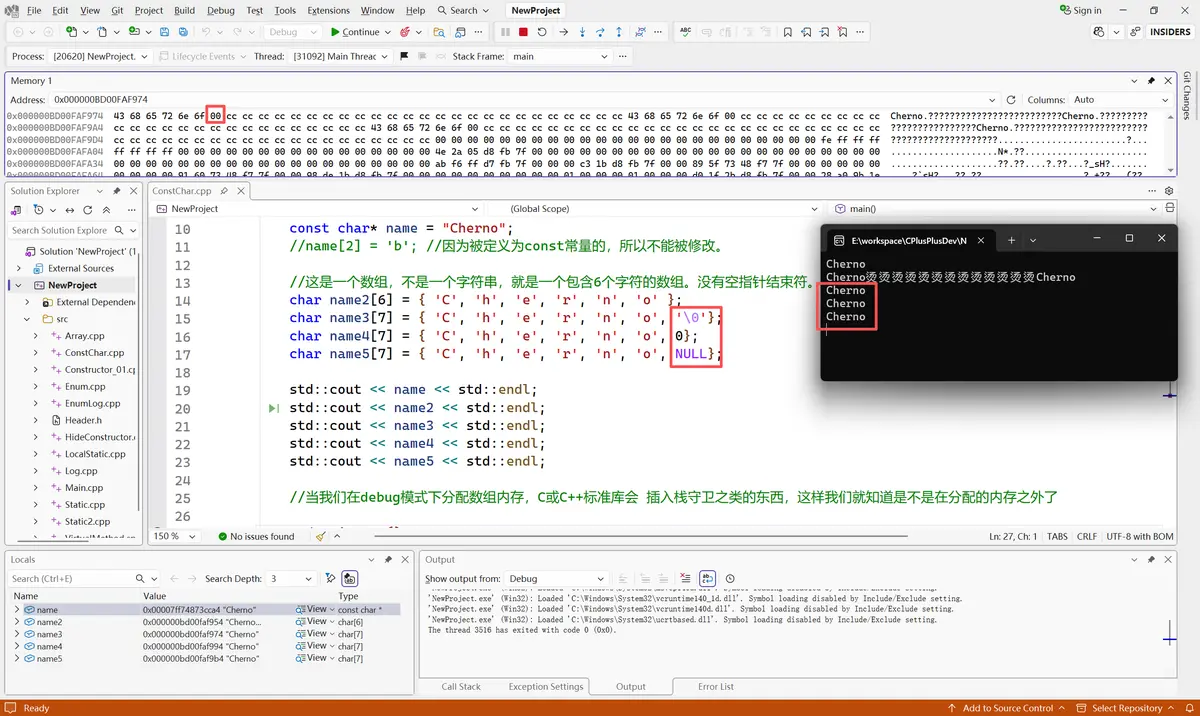
//这是一个数组,不是一个字符串,就是一个包含6个字符的数组。没有空指针结束符。
char name2[6] = { 'C', 'h', 'e', 'r', 'n', 'o' };
char name3[7] = { 'C', 'h', 'e', 'r', 'n', 'o', '\0'};
char name4[7] = { 'C', 'h', 'e', 'r', 'n', 'o', 0};
char name5[7] = { 'C', 'h', 'e', 'r', 'n', 'o', NULL};
std::cout << name << std::endl;
std::cout << name2 << std::endl;
std::cout << name3 << std::endl;
std::cout << name4 << std::endl;
std::cout << name5 << std::endl;
//当我们在debug模式下分配数组内存,C或C++标准库会 插入栈守卫之类的东西,这样我们就知道是不是在分配的内存之外了
//1. 而 + 操作符不可以操作,这相当于把2个字符指针相加
std::string name6 = "hello " + "world";
//2. += 操作符在string中重载了,所以可以支持+=操作
name6 += "world";
//3. 创建一个字符串,再附加一个值给它。这样做会得到很多拷贝,但大多数情况下没问题。
std::string name7 = std::string("hello ") + "world";
//4. 不可以用new
string name7 = new string("hello ");
//5. 判断字符串中是否包含某字符
bool contains = name7.find("no") != string::npos;
std::cout << name6 << std::endl;
std::cin.get();
}
九、其他字符串类型数据
#include<iostream>
#include<stdio.h>
int main() {
const char name1[8] = "Cherno";
const char name2[8] = "Che\0rno"; //终止符
std::cout << strlen(name1) << std::endl; //6
std::cout << strlen(name2) << std::endl; //3
const char* name3 = "Cherno"; //ASCII
const wchar_t* nameWide = L"Cherno"; //宽字符
const char16_t* name16 = u"Cherno"; //Unicode 16
const char32_t* name32 = U"Cherno"; //Unicode 32
const char8_t* nameUtf8 = u8"Cherno"; //C++20引入 UTF-8
//不允许追加,报错
std::string nameStr = "hello " + "world";
//正确方式
std::string nameStr = std::string("hello ") + "world";
//可追加的字符串 C++14
using namespace std::string_literals;
//在后面加s
std::string nameStr = "hello "s + "world";
//字符串追加
std::wstring wideStringAppend= L"hello "s + L"world";
std::u16string unicode16Str= u"hello "s + u"world";
std::u32string unicode32Str= U"hello "s + U"world";
//报错, Why?
std::u8string utf8Str = u8"hello " + u8"world";
//只读不可更改的,不可追加
std::wstring_view wideStrView = L"hello ";
std::u16string_view u16StrView = u"hello ";
std::u32string_view u32StrView = U"hello ";
std::u8string_view utf8StrView = u8"hello ";
std::u8string_view utf8StrView = u8"hello ";
//以R的形式写换行
const char* zhuanYiStr = R"(Line1
Line2
Line3
)";
//传统的C的方式换行
const char* zhuanYiStr = "Line1\n"
"Line2\n"
"Line3\n"
;
//字符串字面量总是存储在只读
std::cin.get();
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号