
后缀自动机SAM
后缀自动机 \(SAM\)
定义:
后缀自动机就是能接受某个串的所有后缀/字串的自动机。
与 \(AC\) 自动机类似,读入字符串后,建立起来一个自动机。但是建立过程不同。
预先步骤:
考虑自动机上一条由根出发的由节点和转移边构成的有向路径,把路径的转移边上的字符按顺序拼接起来可以得到一个字符串,假设我们称它为 \(S\).
那么就可以说这条路径的终点接受字符串 \(S\).
如果一个自动机上存在一条由根出发的有向路径,使得转移边上的字符按顺序拼接起来,得到 \(S\), 就说 \(S\) 被这个自动机接受。
进行定义:
对于一个字串,在原串中出现在若干的位置,而一个子串 \(S\) 出现的位置的右端点标号组成的集合,我们就叫 \(endpos(S)\). 如图,\(endpos(ab)=\{ 2,5 \}\)
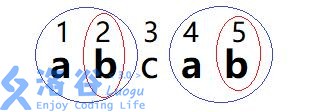
结论:
1. 两个子串的 \(endpos\) 相同,则其中一个子串必然为另一个后缀。
证明:你看上面那个图就行了啊。
2.对于任意两个子串 \(t,p\) ,要么 \(endpos\) 为包含关系,要么并集为空
证明:其实就是结论 \(1\) 的逆命题。
3. 对于 \(endpos\) 相同的子串,归为一个 \(endpos\) 等价类。其中 \(endpos\) 等价类内串的长度连续(按长度从大到小排列依次差 \(1\))。
证明:既然都是后缀,存放的肯定是长度连续的啊。
4. \(endpos\) 等价类个数的级别为 \(O(n)\)
5. 一个类 \(a\) 中,定义最长子串长度为 \(len(a)\) ,最短子串长度为 \(minlen(a)\),设 \(fa(a)\) 表示类 \(a\) 的父亲,则 \(len(fa(a))+1=minlen(a)\) 。
证明:在一个类的最长子串前再添加一个字符,形成的字符串一定是其儿子的一类,而且这个新形成的字符串肯定是它所属的类中最短的。
因此,我们在这棵树中保存每个类 \(len\) 即可,其他长度都能直接推出来。
关键性质:
- 有一个源点,边代表在当前字符串后增加一个字符。
- 每个点代表一个 \(endpos\) 等价类,到达一个点的路径形成的子串必须属于此点的类。
- 点之间有父子关系,到达点 \(i\) 的所有字符串长度必然大于 \(fa(i)\) ,且到达 \(fa(i)\) 的任一字符串必为到达 \(i\) 的任一字符串的后缀。
构造模板:
先上模板,理清一下思路:
int last=1,sz=1;
struct NODE{
int nxt[26];
int len,fa;
NODE(){memset(nxt,0,sizeof(nxt));len=fa=0;}
}st[2000010];
inline void add(int c){
int p=last,np=last=++sz;//p为以c结尾的前缀的倒数第二个节点,np为倒数第一个,即新存放节点
sizes[sz]=1;//endpos[sz]的集合元素大小,新建立节点设为1
st[np].len=st[p].len+1;//当前点最长字符串长度+1
for(;p/*防止跳出根节点*/&&!st[p].nxt[c];p=st[p].fa)
st[p].nxt[c]=np;//把前面一段没有c儿子的节点的c儿子指向p
if(!p)st[np].fa=1;//跳到根节点,把p的parent树上的父亲置为1
else{
int q=st[p].nxt[c];//q从p一直跳parent树得到的第一个有c儿子的节点的c儿子
if(st[q].len==st[p].len+1) //长度为上面的节点长度+1
st[np].fa=q;//如果节点p表示的endpos所对应的字符串集合只有一个字符串,那么把np的parent树父亲设置为p
else{
int nq=++sz;//否则把p节点复制一遍,同时sz要更新
st[nq]=st[q];
st[nq].len=st[p].len+1;
st[q].fa=st[np].fa=nq;//然后把q和np点的父亲指向复制点nq
for(;p&&st[p].nxt[c]==q;p=st[p].fa)
st[p].nxt[c]=nq;//将前面所有本来连接p的点连向nq
}
}
}
int main(){
scanf("%s",s+1);
cd=strlen(s+1);
for(int i=1;i<=cd;i++) add(s[i]-'a');
}
我们进行分区分析:
寻找前缀环节
int p=last;
int np=last=++sz;
sizes[sz]=1;//endpos[sz]的集合元素大小,新建立节点设为1
st[np].len=st[p].len+1;//当前点最长字符串长度+1
\(last\) 是未加入此字符最长的前缀所属的节点的编号,\(sz\) 是当前后缀自动机节点的总数。
此时我们新建立一个节点 \(np\) ,把它能接受的最大字符串长度设为 当前点最长字符串长度 \(+1\)
这就是一开始的建立过程。
for(;p/*防止越界*/&&!st[p].nxt[c];p=st[p].fa)
st[p].nxt[c]=np;//
循环条件是:点 \(p\) 没有一条为 \(c\) 的出边,\(p\) 每一次循环后会跳到 \(fa(p)\).
然后将所有点 \(p\) 以及 \(p\) 的父亲节点的 \(c\) 出边,都设置为新的节点 \(np\).

就像这张图,我们添加了 \(b\) ,向 \(p\) 走,找到 \(abcd\) 节点,没有 \(b\) 出边,继续找父亲到 \(b\) 节点,也没有 \(b\) 的出边,然后继续向原点走,发现有 \(b\) 的出边,循环停止。
\(np\) 所能接受最短的字符串长度,等于点 \(p\) 在爬上来的链上的儿子接受的最短字符串长度 \(+1\) ,也就是点 \(p\) 接受的最长字符串长度 \(+2\).
标记父亲环节:
情况一:我们遍历完了旧串的后缀,且它们 \(+c\) 都不是旧串的子串,就说明 \(c\) 之前没有出现过,因此直接祖先设为原点 \(1\)。
if(!p) st[np].fa=1;
情况二:
也分两种情况,不过我们先定义 \(q\) 为自动机上有 \(c\) 这个出边所到达的点
int q=st[p].nxt[c];
- 我们正好找到了一个不重不漏接受新串的所有后缀的节点集合。
像上图一样,我们的 \(np\) 节点搜索后正好找到了 \(b(标号为q)\) 节点,正好能接受。
因此,我们直接把新节点的父亲设置为 \(q\) 即可。
此时满足 \(np\) 接受的最短字符串长度等于点 \(q\) 接受的最长字符串长度加 \(1\),也就是说,点 \(q\) 接受的最长字符串的长度是点 \(p\) 接受的最长字符串的长度加 \(1\).
数学计算一下(这里都是长度)则是:
\(lenmax(p)=lenmin(np)+2\),且 \(lenmax(q)+1=lenmin(np)\)
因此这么判断是可以的
if(st[q].len==st[p].len+1) st[np].fa=q;
- 并不能完全接受

在这个例子中,我们知道点 \(q\) 接受了最长的出现在原串中的新串后缀。
但与此同时,\(q\) 还存有一些更长的串。
为了保证拥有完美接受新串所有后缀的节点集合,我们需要把 \(q\) 点拆开。
首先,新建立一个节点 \(nq\) ,作为存放这些后缀的点。
int nq=++sz;
我们知道点 \(q\) 能够接受最长的出现在原串中的新串后缀(本图中是 \(”bc”\))是因为点 \(p\) 向它连了一条关于新字符的转移边。
以及该串的后缀去掉最后一个字符后,一定是点 \(p\) 接受的最长的串的一个后缀。
在本图中 \(bc\) 和 \(c\) 去掉最后一个字符 \(c\) 后都是 \(b\) 的后缀)
为了让 \(np\) 接受需要的串,我们要访问 \(p\) 到其祖先的一条链,将指向 \(q\) 的关于新字符的转移边改为指向 \(nq\) 即可。
st[nq]=st[q];
此时,我们需要把 \(nq\) 接受的最大字符串长度改为 \(len(p)+1\) ,等于是在后面多加了一个字符 \(c\) 的新长度。
st[nq].len=st[p].len+1;
最后,确定节点父亲。

从图中看, \(np\) 和 \(q\) 的父亲我们都需要设置成 \(nq\).
st[q].fa=st[np].fa=nq;
又因为 \(nq\) 节点现在作为 \(p\) 存放 \(c\) 出边的点,我们要把原来指向 \(p\) 的点都变成指向 \(nq\) ,因此:
for(;p&&st[p].nxt[c]==q;p=st[p].fa)
st[p].nxt[c]=nq;//将前面所有本来连接p的点连向nq
总体代码:
else{
int nq=++sz;//否则把p节点复制一遍,同时sz要更新
st[nq]=st[q];
st[nq].len=st[p].len+1;
st[q].fa=st[np].fa=nq;//然后把q和np点的父亲指向复制点nq
for(;p&&st[p].nxt[c]==q;p=st[p].fa)
st[p].nxt[c]=nq;//将前面所有本来连接p的点连向nq
}
特殊性质进行拓扑序
按照 \(len\) , 桶排序之后也就是 \(Parent\) 树的 \(BFS\) 序/自动机的拓扑序
将 \(parent\) 树从叶子到根/自动机反拓扑序用 \(A[1]..A[sz]\) 表示出来
for(int i=1;i<=sz;i++) t[st[i].len]++;
for(int i=1;i<=sz;i++) t[i]+=t[i-1];
for(int i=1;i<=sz;i++) A[t[st[i].len]--]=i;
求 \(size\):
for(int i=sz;i>=1;i--) sizes[st[A[i]].fa]+=sizes[A[i]];
使用:
1. 判断子串:(你直接用 \(KMP\) 不行吗)
问题:给定文本 \(T\),给定字符串 \(P\),问 \(P\) 是否是 \(T\) 的子串。
我们直接在后缀自动机上跑边,跑完串还没有跑出边界,则为原串的子串。
2.求不同的子串个数:
问题:给定字符串 \(s\) ,判断有多少不同的子串:
先对于每个节点进行树形建边.
利用后缀自动机树形结构,每个节点对应的子串数量是:\(len(i)-len(ver[i])\) ,对所有节点求和就行了。
我们在题中记录的有 \(sizes[x]\) 和 \(st[x].len\) ,表示在 \(x\) 这个集合内的相同字符串个数以及长度。
但是我们还没有进行树的搜索,对其进行累加。
因此,对于每个 \((st[x].fa,x)\) ,我们依次建边,跑深搜,累加 \(sizes[x]\)
\(S\) 的任意子串都对应 \(SAM\) 中的一条路径,所以路径条数 \(sizes\) 就是子串个数
累加原因:跑到的点,一定包含上面点字符串作为前缀,所以肯定也出现了 \(fa[x]\) 所代表的字符串,所以可以进行累加。
long long ans=0;
void dfs(int x){
for(int i=head[x];i;i=nxt[i]){
int y=ver[i];
dfs(y);
sizes[x]+=sizes[y];
}
if(sizes[x]!=1) ans=max(ans,sizes[x]*st[x].len);
}
int main(){
......
for(int i=2;i<=sz;i++) add(st[i].fa,i);
}
3. 不同子串的总长度:
问题:给定一个字符串 \(S\) ,计算不同子串的总长度。
每个节点对应的所有后缀长度是 \(\frac{len(i)* (len(i)+1)}{2}\) ,减去连接节点对应值就是该店的净贡献,加和即可。
4. 字典序第 \(k\) 大子串:
问题:给定一个字符串 \(S\)。多组询问,每组询问给定一个数 \(K_i\) ,查询 \(S\) 的所有子串中字典序第 \(K_i\) 大的子串。
解决这个问题的思路可以从解决前两个问题的思路发展而来。
字典序第 \(k\) 大的子串对应于 \(SAM\) 中字典序第 \(k\) 大的路径.
因此在计算每个状态的路径数后,我们可以很容易地从 \(SAM\) 的根开始找到第 \(K\) 大的路径。
有一题原题:
本质不同:一个字符串出现多次都算成一次。
可相同:一个字符串出现次数就是有多少个这个字符串。
我们知道对应字符串的 \(size[i]\) 等于该字符串的出现个数,对于每个节点,有式子:
\(T==1 ? (sum[i]=sizes[i]):(sum[i]=sizes[i]=1)\)
通过枚举加和后通过 \(dfs\) 对对应字符串进行寻找,输出即可。
\(dfs\) 代码如下:
void print(int x,int k){
if(k<=sizes[x]) return;
k-=sizes[x];
for(int i=0;i<26;i++){
int R=st[x].nxt[i];
if(!R) continue;
if(k>sum[R]){
k-=sum[R]; continue;
}
putchar(i+'a');
print(R,k);
return;
}
}
5.最小循环移位
问题:给定一个字符串 \(S\)。找出字典序最小的循环移位
所以问题简化为在 \(S+S\) 对应的后缀自动机上寻找最小的长度为 \(|S|\) 的路径。
我们从初始状态开始,贪心地访问最小的字符即可
6.出现次数:
我的评价是,看第二条的例题。
7. 第一次出现的位置
给定一个文本串 \(T\) ,多组查询。每次查询字符串 \(P\) 在字符串 \(T\) 中第一次出现的位置.
为了解决这一问题,我们需要预处理 \(firstpos\) ,找到自动机中所有状态的出现位置,即,对每个状 \(v\) 我们希望找到一个位置 \(firstpos[v]\).
代表其第一次出现的位置。换句话说,我们希望预先找出每个 \(endpos(v)\) 中的最小元素(我们无法明确记录整个 \(endpos\) 集合)。
维护这些 \(firstpos\) 的最简单方法是在构建自动机时一并计算,当我们创建新的状态 \(cur\) 时,一旦进入函数 \(sa_extend()\),就确定该值:
\(firstpos(cur)=len(cur)-1\) (如果我们的下标从 \(0\) 开始)。
当拷贝节点 \(q\) 时,令:
\(firstpos(clone)=firstpos(q)\),(因为只有一个别的可能值—— \(firstpos(cur)\) ,显然更大)。
这样就得到了查询的答案—— \(firstpos(t)-length(P)+1\),其中 \(t\) 是模式串 \(P\) 对应的状态。
更多情况:后缀自动机 (SAM)
例题:
基本上属于板子,因为后缀自动机是一个在线算法,因此每一次统计就可以了。
关键代码:
ans=ans+st[np].len-st[st[np].fa].len;//每个节点对应的字串数量
因为后缀不好处理,因此我们可以把其转化成求前缀。
那么我们就反着对 \(a,b\) 进行插入字符串,记录其种类,我们可以很简单进行一个容斥:
其中 \(a_i\) 重新进行了排列,使其与 \(b\) 尽量匹配(用 \(SAM\) 好处理)
我们就可以根据贪心来使其匹配,匹配不上的继续匹配。
代码(匹配部分):
void ans(){
int res=0;
for(int i=sz;i;i--){
int minn=min(sizes[rev[i]][0],sizes[rev[i]][1]);//最小不需要改动的
res+=minn*min(st[rev[i]].len,K);//长度不能长于K
sizes[rev[i]][0]-=minn;
sizes[rev[i]][1]-=minn;
sizes[st[rev[i]].fa][0]+=sizes[rev[i]][0];//不能匹配的再上传继续匹配
sizes[st[rev[i]].fa][1]+=sizes[rev[i]][1];
}
cout<<K*(n-K+1)-res<<endl;
}
广义AC自动机板子
根据是否能加边进行深搜的 \(SAM\) 构造,然后答案就是
回文自动机(没学到时候补)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号