

Ollama:国内镜像
1. 引言
Ollama 是一个开源的大型语言模型(LLM)服务工具,它允许用户在本地机器上运行和部署大型语言模型。Ollama 设计为一个框架,旨在简化在 Docker 容器中部署和管理大型语言模型的过程,使得这一过程变得简单快捷。用户可以通过简单的命令行操作,快速在本地运行如 Llama 3 这样的开源大型语言模型。
下面以本地运行Llama 3中文模型为例来说明。
2. Ollama基于模型文件构建自定义模型
2.1 模型下载
(1) HF 上选择排名最高的模型
模型列表官网地址:Models - Hugging Face
模型列表国内镜像(推荐):Models - Hugging Face
在模型列表页面按照关键字llama chinese搜索,并按照趋势排序,可以看到中文版模型:
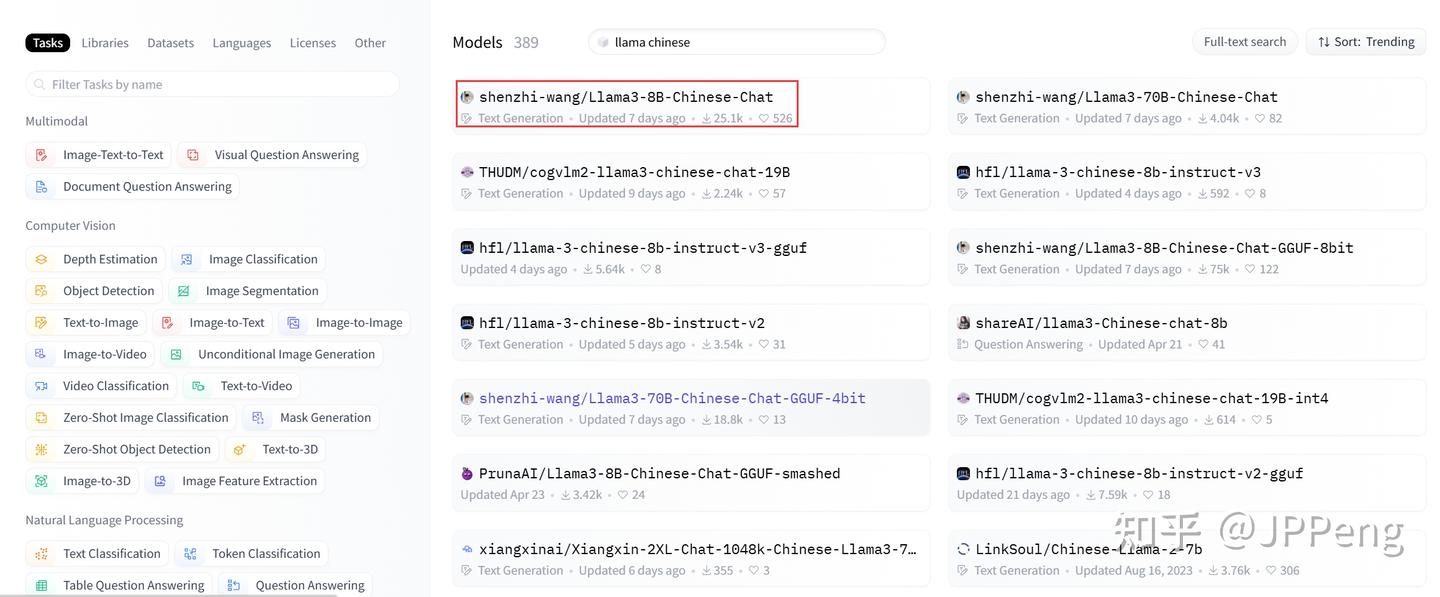
可以看出,第一名模型的下载数量和点赞数量,比第二名要多好多,我们就选择shenzhi-wang这位作者发布的模型。
通过 GGUF 量化模型安装(推荐):GGUF 安装比较简单,下载单个文件即可:
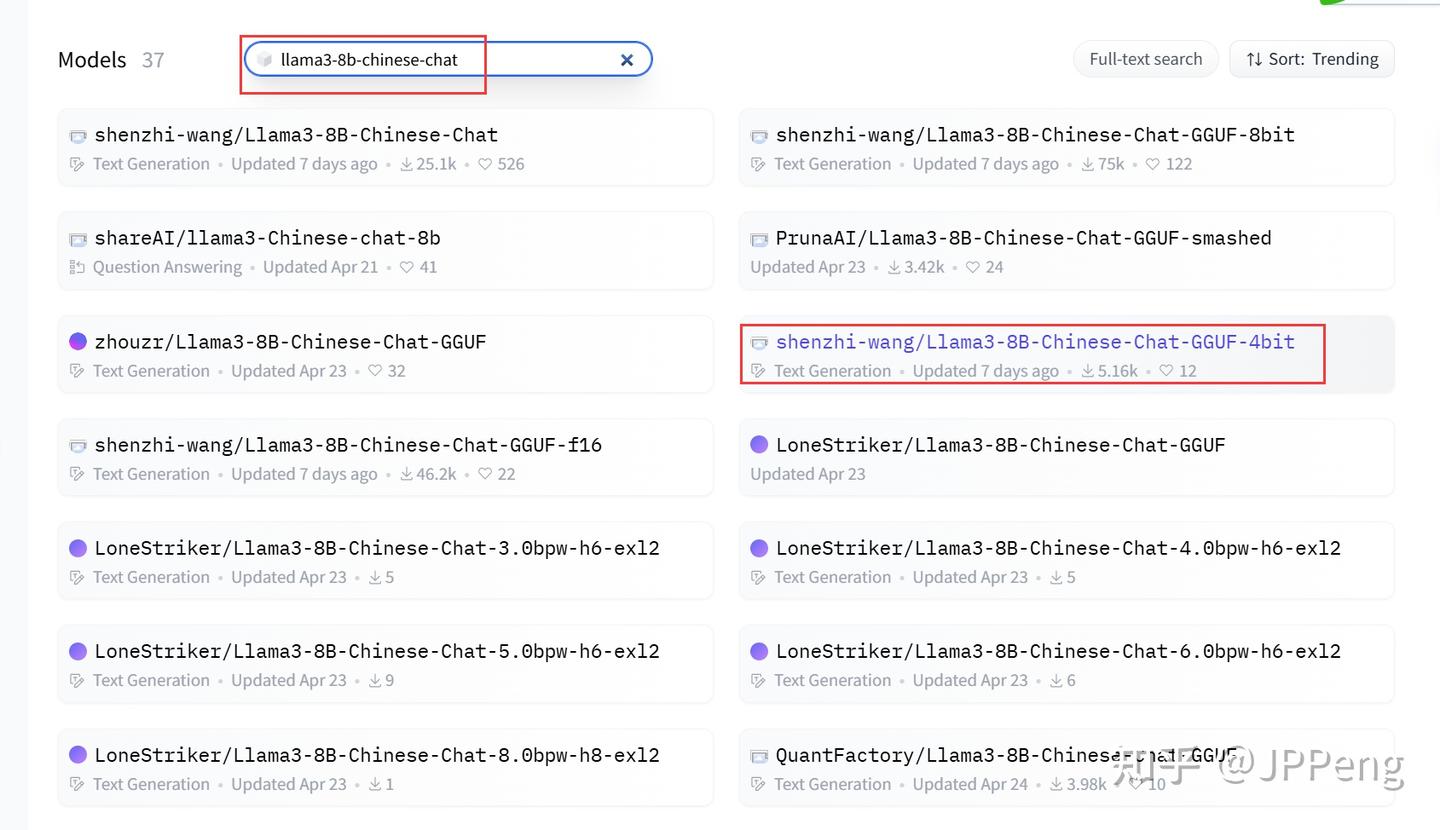
下载好模型文件后,创建本地模型文件Modelfile。假定形形如下的目录结构:
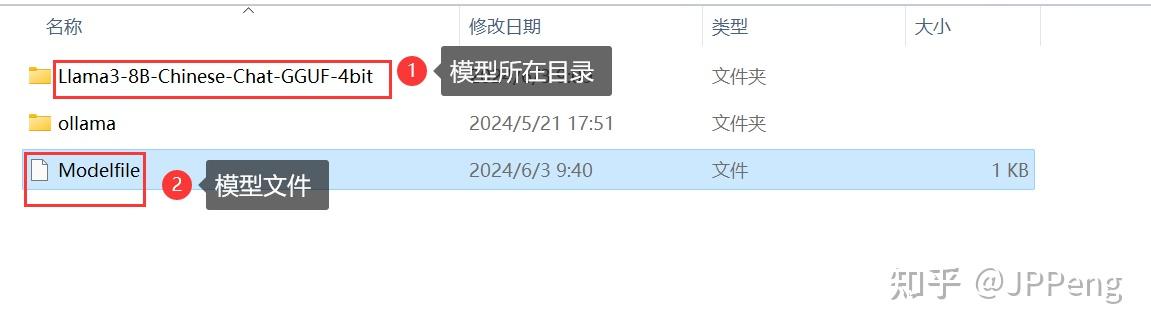
Modelfile文件内容如下:
# Modelfile
FROM "./Llama3-8B-Chinese-Chat-GGUF-4bit/Llama3-8B-Chinese-Chat-q4_0-v2_1.gguf"创建大模型:
ollama create Llama3-8B-Chinese -f Modelfile运行大模型:
ollama run Llama3-8B-Chinese但是,在运行模型后,输入相关问题进行测试,发现模型返回结果很混乱,回答了一些无关的内容,而且内容很多,没完没了。必须按Ctrl+C中断模型响应。
感觉是模型无法判断问题答案应该在何时结束,是配置文件出现了问题。
在这里的解决方法是从下面在线命令安装方式安装模型后,通过复制在线安装模型的配置文件进行定制,最后模型文件内容如下:
# Modelfile
FROM "./Llama3-8B-Chinese-Chat-GGUF-4bit/Llama3-8B-Chinese-Chat-q4_0-v2_1.gguf"
# set the temperature to 1 [higher is more creative, lower is more coherent]
# PARAMETER temperature 1
# 许多聊天模式需要提示模板才能正确回答。默认提示模板可以使用TEMPLATE中的Modelfile指令指定
# TEMPLATE "[INST] {{ .Prompt }} [/INST]"
TEMPLATE "
{{ if .System }}<|start_header_id|>system<|end_header_id|>
{{ .System }}<|eot_id|>{{ end }}{{ if .Prompt }}<|start_header_id|>user<|end_header_id|>
{{ .Prompt }}<|eot_id|>{{ end }}<|start_header_id|>assistant<|end_header_id|>
{{ .Response }}<|eot_id|>
"
SYSTEM "
You are a helpful assistant.
"
PARAMETER stop <|start_header_id|>
PARAMETER stop <|end_header_id|>
PARAMETER stop <|eot_id|>
PARAMETER temperature 0.6
PARAMETER top_p 0.9运行如下命令,删除模型,并重新安装、运行模型。
# 查看安装模型名称
ollama list
# 删除自定义安装的模型
ollama rm Llama3-8B-Chinese:latest
# 重新创建模型
ollama create Llama3-8B-Chinese -f Modelfile
# 运行模型
ollama run Llama3-8B-Chinese模型运行测试问题回答与在线安装模型结果一致。终于搞定。
2.2 使用在线Ollama命令安装
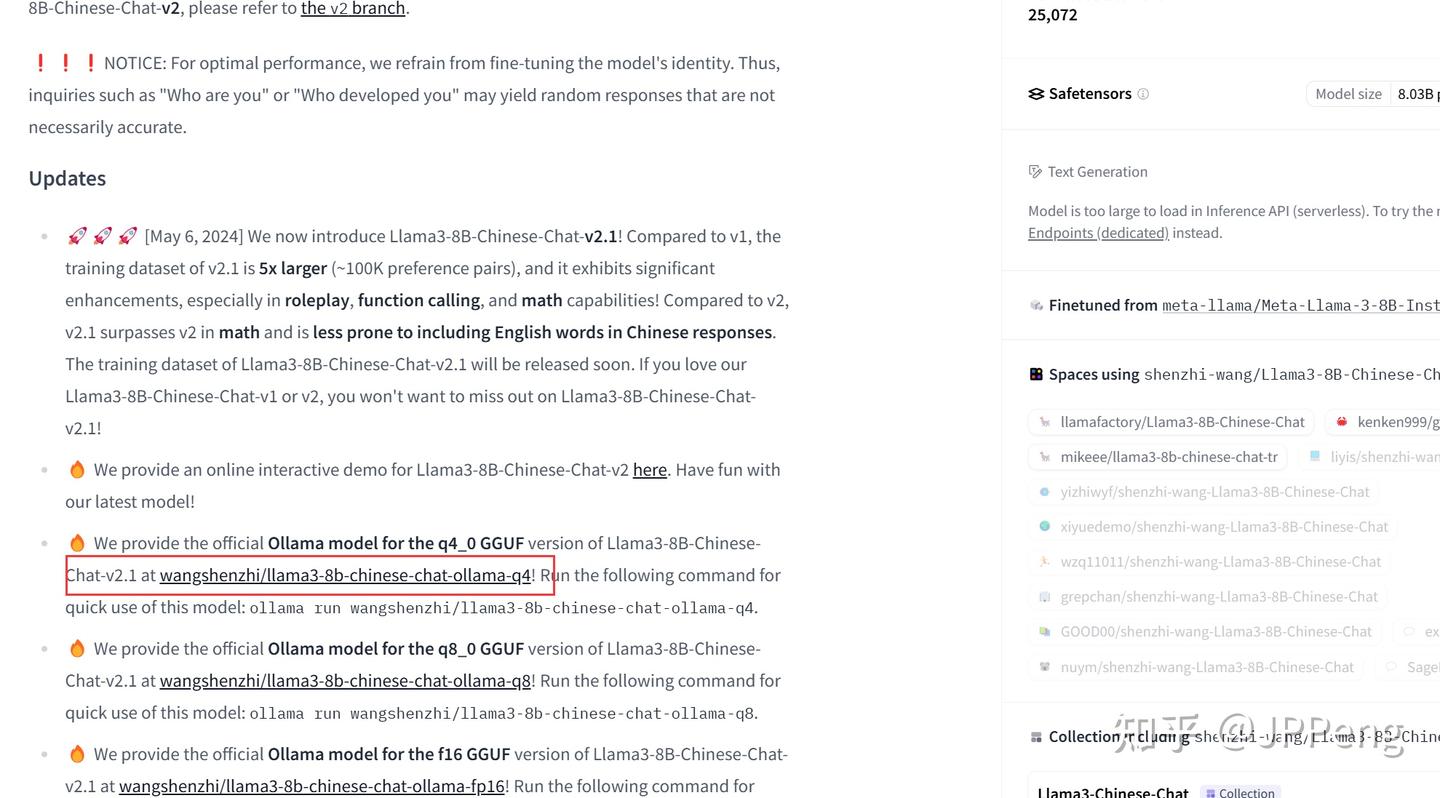
点击链接,直接跳到了Ollama管理的模型界面:
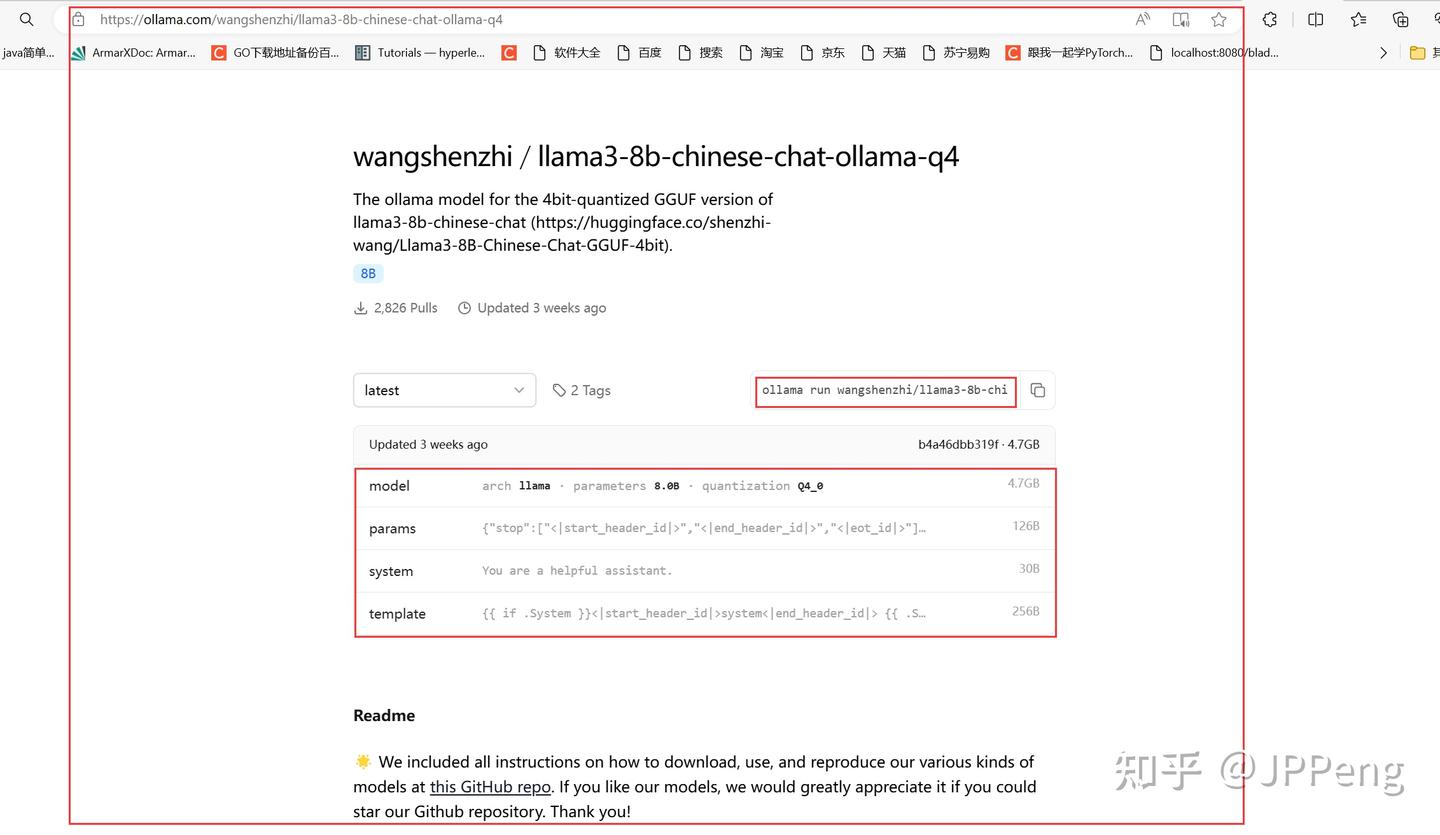
在命令行下,直接输入以下命令:
ollama run wangshenzhi/llama3-8b-chinese-chat-ollama-q4安装完成后,可以使用如下命令,查看安装的模型:
ollama list
使用如下命令查看指定模型的配置信息:
ollama show wangshenzhi/llama3-8b-chinese-chat-ollama-q4:latest --modelfile获得模型配置信息如下:
ollama show wangshenzhi/llama3-8b-chinese-chat-ollama-q4:latest --modelfile
# Modelfile generated by "ollama show"
# To build a new Modelfile based on this, replace FROM with:
# FROM wangshenzhi/llama3-8b-chinese-chat-ollama-q4:latest
FROM D:\models\ollama\blobs\sha256-242ac8dd3eabcb1e5fcd3d78912eaf904f08bb6ecfed8bac9ac9a0b7a837fcb8
TEMPLATE "
{{ if .System }}<|start_header_id|>system<|end_header_id|>
{{ .System }}<|eot_id|>{{ end }}{{ if .Prompt }}<|start_header_id|>user<|end_header_id|>
{{ .Prompt }}<|eot_id|>{{ end }}<|start_header_id|>assistant<|end_header_id|>
{{ .Response }}<|eot_id|>
"
SYSTEM "
You are a helpful assistant.
"
PARAMETER stop <|start_header_id|>
PARAMETER stop <|end_header_id|>
PARAMETER stop <|eot_id|>
PARAMETER temperature 0.6
PARAMETER top_p 0.9 基于上面的模型配置信息,完善了基于模型文件的配置信息。
3. Ollama模型运行信息管理
使用以下命令查看可运行的模型:
#运行命令及结果
ollama list
NAME ID SIZE MODIFIED
Llama3-8B-Chinese:latest f5b8c39e0381 4.7 GB 2 hours ago
wangshenzhi/llama3-8b-chinese-chat-ollama-q4:latest b4a46dbb319f 4.7 GB 2 hours ago
qwen:4b d53d04290064 2.3 GB 12 days ago使用如下命令查看模型的运行情况:
#运行命令及结果
ollama ps
NAME ID SIZE PROCESSOR UNTIL
Llama3-8B-Chinese:latest f5b8c39e0381 5.4 GB 100% GPU 4 minutes from now但是注意到一个事实,在模型调用结束的一小段时间后,再使用上面的命令去查看运行情况,会发现不再有运行模型。就算再到正在进行模型对话的界面,输入问题,会发现即使是上面问过的同样问题,都要等待一小段时间,实际上就是模型在没有调用的情况下,会自动进入非活动状态,当接受到新的请求后,需要重新激活运行模型。
问题:在配置文件的什么位置,可以设置这个超时时间?
参考链接
[1] 基于Llama 3搭建中文版(Llama3-Chinese-Chat)大模型对话聊天机器人
[2] 模型列表国内镜像(推荐):Models - Hugging Face

 浙公网安备 33010602011771号
浙公网安备 33010602011771号