
BeautifulSoup
爬虫学习
BeautifulSoup()
第一步,查看网页源代码,看页面格式,分析网页结构
第二步,使用requests库,得到网页源代码
第三步,使用BeautifulSoup(), ' soup = BeautifulSoup(response,'lxml') '
第四步,con = soup.finf_all()
...
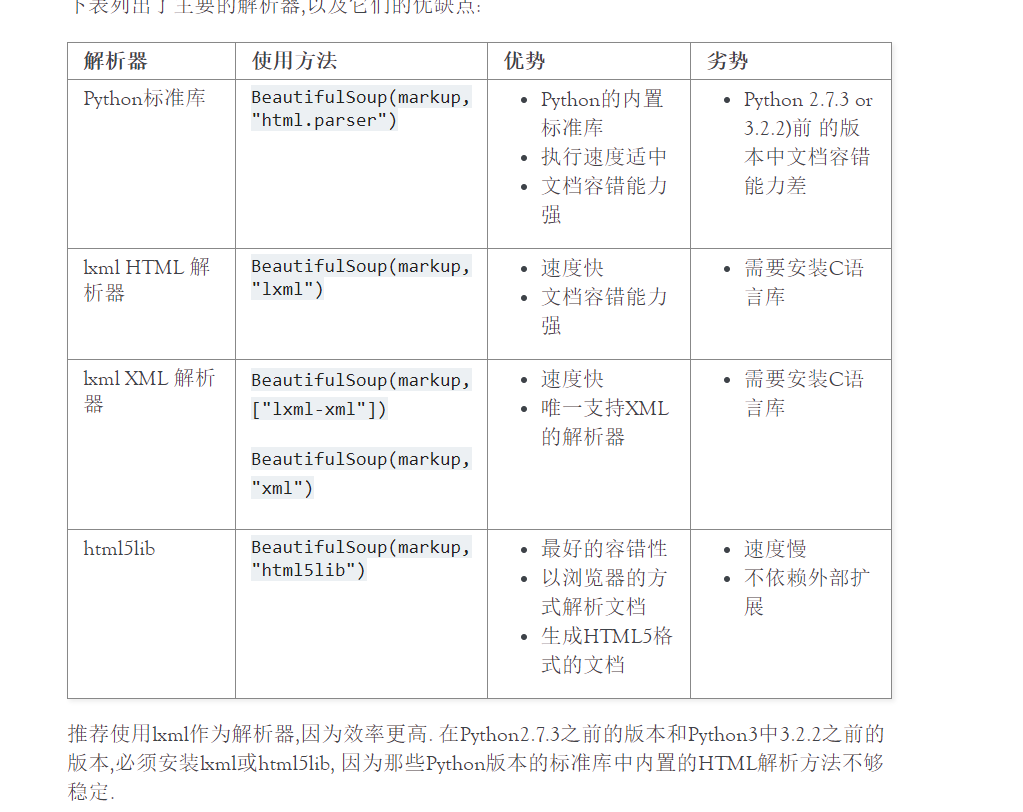
BeautifulSoup()解析器,(一般选择 ‘lxml’)

爬虫学习
BeautifulSoup()
第一步,查看网页源代码,看页面格式,分析网页结构
第二步,使用requests库,得到网页源代码
第三步,使用BeautifulSoup(), ' soup = BeautifulSoup(response,'lxml') '
第四步,con = soup.finf_all()
...
BeautifulSoup()解析器,(一般选择 ‘lxml’)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号