
索引优化的注意点
索引优化
-
type是range,extra里存在using filesort,范围条件查询后的索引会失效。
创建除了范围查询字段的联合索引可以解决。
-
左连接查询时,右表建索引,右连接查询时,左表建索引。
join语句的优化
-
尽可能的减少join语句中的nestedLoop的循环次数:“永远用小结果集驱动大结果集”。
如果使用大结果集驱动小的,会增加IO,结果也一样。
-
优先优化NestedLoop的内层循环:保证Join语句中被驱动表上的Join条件字段已经被索引。
-
当无法保证被驱动表的Join条件字段被索引且内存资源充足的前提下,不要太吝啬JoinBuffer的设置。
索引失效
-
全值匹配我最爱。
按照创建的某个索引的全部字段来匹配。
-
最左前缀法则。
如果索引了多个列,要遵守最左前缀法则,指的是查询从索引的最左前列开始并且不跳过索引中的列,就是带头大哥不能死。如果索引字段a,b,c,使用a,b做为查询,那么会使用部分索引。
-
不在索引列上做操作(计算、函数、(自动or手动)类型转换),会导致索引失效转向全表扫描。
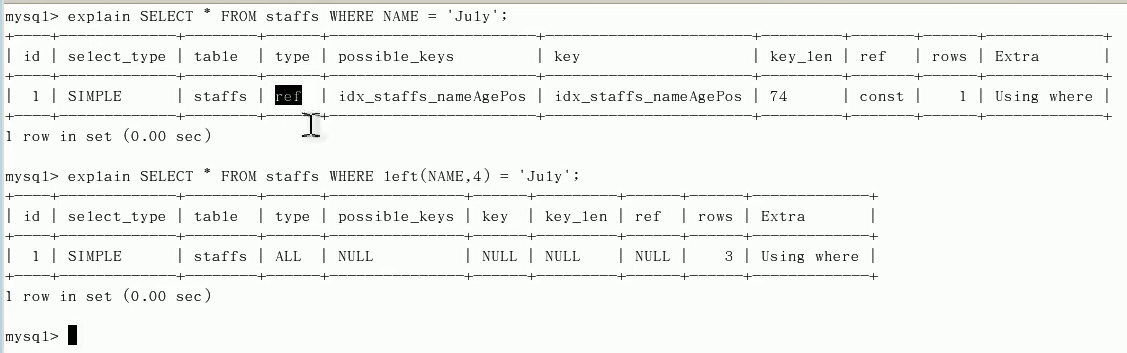
-
存储引擎不能使用索引中范围条件右边的列。
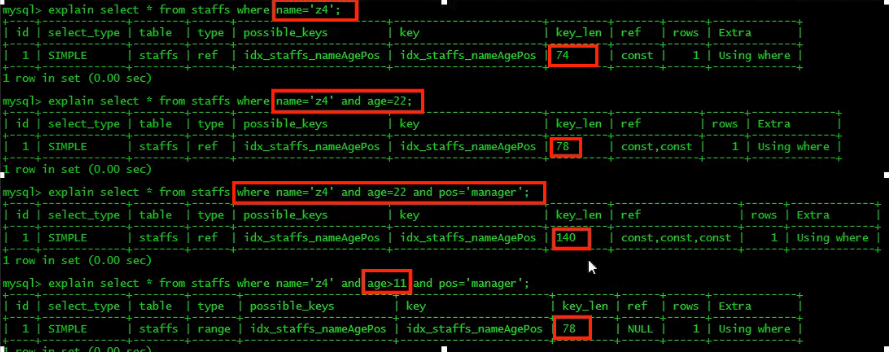
在最后一条查询时可以看出,pos字段的索引失效了。
-
尽量使用索引覆盖(只访问索引的查询(索引列和查询列一致)),减少select*。
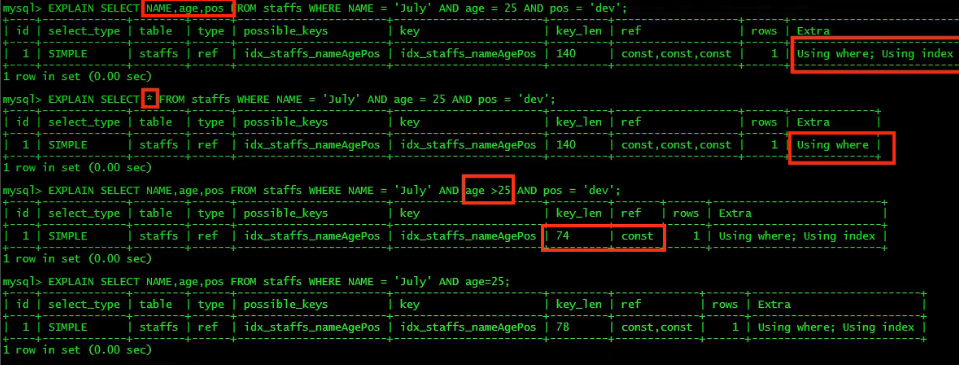
可以看出,如果只访问索引的列,那么extra会出现using index,就是使用索引数据,不需要去查询数据了。
-
MySQL在使用不等于(!=或<>)的时候无法使用索引,会导致全表扫描。
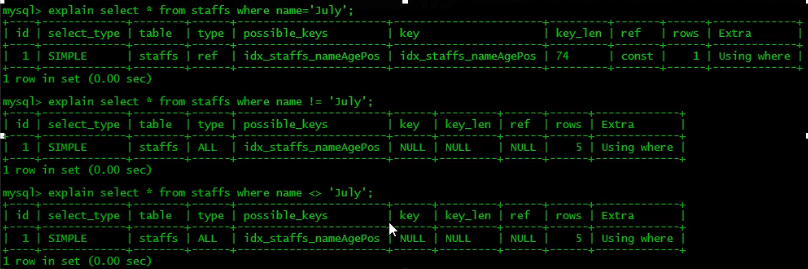
-
is null,is not null 也无法使用索引。

-
like以通配符开头(‘%abc...’)MySQL索引失效,会变成全表扫描。
百分号放后面(‘abc%’)索引不会失效,会变成范围查询,type是range。
-
字符串不加单引号索引失效。

隐式的类型转换会导致索引失效。
-
少用or,用它来连接时会索引失效。
例子

索引分析
创建一个联合索引。
CREATE INDEX idx_nas ON user(name,age,sex);
-
索引字段的顺序在where条件内的顺序可以颠倒,不影响索引的生效,包括使用范围查询时。
select name,age,sex from user where name="张三丰" and age=108 and sex="男";select name,age,sex from user where sex="男" and name="张三丰" and age=108;这两条查询语句使用索引的情况是一致的,但是最好按创建索引的顺序来写,减少数据库的操作。
-
索引有两大功能,索引和排序。
select name,age,sex from user where name="张三丰" order by age;这个sql使用了两个索引,一个name用来查询,一个age用来排序。
select name,age,sex from user where name="张三丰" order by sex;这个sql会出现using filesort,因为中间断开了,因为age字段没使用。
select name,age,sex from user where name="张三丰" order by age asc, sex desc;这个sql会出现using filesort,因为排序的方向不一致,必须同为asc或者同为desc。
-
order by的顺序是不能颠倒的,会出现using filesort。
例如:
select name,age,sex from user where name="张三丰" order by sex, age;有一个例外,如果order by的字段在where条件内就不会出现using filesort。
-
in和exists的使用建议。
select * from A where id in(select id from B);当B表的数据集小于A表的数据集时,用in优于exists;
select * from A where exists (select 1 from B where B.id = A.id);当A表的数据集小于B表的数据集时,用exists优于in;
EXISTS只返回true或者false,因此查询中select 1中的1是任意常量。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号