部署分布式存储Ceph的Reef版本
官网
前提条件
硬件
本次搭建我们准备3台2c4g的RockyLinux 9.3虚拟机,每台虚拟机除了系统盘60g以外,还单独配置了3块60G的数据盘,整个集群的总容量是 3*3*60g=540g 的磁盘空间,再加上每台主机上的60G系统盘(不参与ceph存储)。
使用了两块网卡ens160和ens224
-
ens160配置了外网IP地址,用于提供Ceph集群对外访问接口。
-
ens224配置集群内部IP地址,用于Ceph集群内部通信。
首先安装好三台虚拟机,都使用最小化安装。我这边三台机器IP地址和主机名分别是: -
10.0.0.32 r1-ceph1
-
10.0.0.33 r1-ceph2
-
10.0.0.34 r1-ceph3
将IP地址和主机名对应关系写到/etc/hosts文件里。
节点硬盘信息如下:
ls /dev/nvme0n*
/dev/nvme0n1 /dev/nvme0n1p1 /dev/nvme0n1p2 /dev/nvme0n2 /dev/nvme0n3 /dev/nvme0n4
网卡配置如下:
r1-ceph1
ens160:10.0.0.32
ens224:192.168.229.32
r1-ceph2
ens160:10.0.0.33
ens224:192.168.229.33
r1-ceph3:
ens160:10.0.0.36
ens224:192.168.229.34
软件
官方推荐cephadm用容器部署

操作系统说明:本次搭建Ceph集群使用的是官方提供的cephadm工具,它也是一个容器化部署的工具
因此它只要求操作系统上具备以下组件:
- Python3
- Systemd
- Podman或者Docker
- 校时服务
- LVM2
基础配置:
- 关闭防火墙
- 关闭SELinux
- 设置好主机名
- 配置好校时服务
- 安装好docker-ce
安装docker
新版本Ceph支持podman和docker作为底层容器的运行时,我们这里使用docker
先配置docker-ce的yum源
cat <<EOF > /etc/yum.repos.d/docker-ce.repo
[docker-ce-stable]
name=Docker CE Stable - \$basearch
baseurl=https://mirrors.aliyun.com/docker-ce/linux/centos/\$releasever/\$basearch/stable
enabled=1
gpgcheck=1
gpgkey=https://mirrors.aliyun.com/docker-ce/linux/centos/gpg
EOF
安装
dnf makecache
dnf install -y docker-ce docker-ce-cli containerd.io
安装docker并启动docker服务
RockyLinux9.3上默认安装了podman,需要将它卸载,在部分极端情况下会出现即使你在参数里指定了使用docker,但是它默认还是使用podman来启动容器。
yum remove podman -y
配置docker
cat <<EOF > /etc/docker/daemon.json
{
"registry-mirrors": [
<配置自己可用的镜像仓库>
],
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "20m",
"max-file": "5"
}
}
EOF
启服务
systemctl restart docker
systemctl enable docker
cephadm命令配置
当前置条件都配置好了以后,就可以开始配置cephadm这个命令行工具了,在RockyLinux9上,自带了Ceph的yum源,因此可以直接安装
因为是安装18版本的,所以是 reef 版本
dnf install centos-release-ceph-reef -y
dnf install cephadm -y
dnf install epel-release -y
dnf install ceph-common -y
yum install ceph-base -y
等命令执行完成后,cephadm和ceph命令行工具就安装好了,cephadm命令行工具是用来做Ceph集群节点管理的,而ceph命令行工具是用来做集群内部组件和服务管理的。
安装完成后,确认两者的版本一样:
$ ceph --version
ceph version 18.2.3 (76424b2fe1bb19c32c52140f39764599abf5e035) reef (stable)
$ cephadm version
cephadm version 18.2.3 (76424b2fe1bb19c32c52140f39764599abf5e035) reef (stable)
安装的时候会自动安装podman,所以还需要再卸载一遍
dnf remove podman -y
集群配置
集群初始化
集群配置时,默认会先使用cephadm bootstrap命令初始化出第一个集群节点,然后在第一个集群节点的基础上扩展出剩下的节点,完成整个集群的构建。
初始化过程中cephadm会下载一个ceph的docker镜像到本地,这个镜像比较大有1.2G,因此为了加快后续节点的启动和部署,可以直接下载我这边导出的镜像直接导入到各个节点即可,这样初始化和后续节点的启动过程就会省掉镜像的下载流程。
可以先拉取镜像
docker pull quay.io/ceph/ceph:v18
然后初始化
cephadm --docker bootstrap --mon-ip 10.0.0.32 \
--allow-fqdn-hostname \
--cluster-network 192.168.229.0/24 \
--allow-overwrite
参数解释:
- --docker,使用docker作为底层存储引擎,默认是podman,注意这个参数是cephadm命令的参数;
- --mon-ip mon-ip通常指的是第一台机器的对外通信IP地址
- --allow-fqdn-hostname,当主机配置了完整主机名的时候需要这个参数,例如我们这里的r1-ceph1
- --cluster-network 192.168.229/24,设置集群内部组件通信的网络,程序会自动查找每个节点上对应网段的IP地址。
- --allow-overwrite,允许覆盖/etc/ceph目录下旧的配置;
这个命令会执行很多操作,包括:
- 在mon-ip机器上创建出新集群的一个monitor进程和mgr进程,即一个最小化集群所需的基本服务;
- 生成一对SSH密钥,把公钥写入root用户的
~/.ssh/authorized_keys文件和/etc/ceph/ceph.pub文件,方便传输到其他节点; - 创建一个集群的最小化配置到
/etc/ceph/ceph.conf文件中; - 创建一个client.admin用户的管理密钥到
/etc/ceph/ceph.client.admin.keyring文件中; - 给第mon-ip指定的主机添加一个
_admin标签,表示它是一个管理节点(通常只有管理节点才有ceph.conf和ceph.client.admin.keyring文件)
Verifying podman|docker is present...
Verifying lvm2 is present...
Verifying time synchronization is in place...
Unit chronyd.service is enabled and running
Repeating the final host check...
docker (/usr/bin/docker) is present
systemctl is present
lvcreate is present
Unit chronyd.service is enabled and running
Host looks OK
Cluster fsid: 01bc2c22-085f-11ef-84e3-000c29e7a7a8
Verifying IP 10.0.0.32 port 3300 ...
Verifying IP 10.0.0.32 port 6789 ...
Mon IP `10.0.0.32` is in CIDR network `10.0.0.0/24`
Mon IP `10.0.0.32` is in CIDR network `10.0.0.0/24`
Pulling container image quay.io/ceph/ceph:v18...
Ceph version: ceph version 18.2.2 (531c0d11a1c5d39fbfe6aa8a521f023abf3bf3e2) reef (stable)
Extracting ceph user uid/gid from container image...
Creating initial keys...
Creating initial monmap...
Creating mon...
Waiting for mon to start...
Waiting for mon...
mon is available
Assimilating anything we can from ceph.conf...
Generating new minimal ceph.conf...
Restarting the monitor...
Setting public_network to 10.0.0.0/24 in mon config section
Setting cluster_network to 192.168.229.0/24
Wrote config to /etc/ceph/ceph.conf
Wrote keyring to /etc/ceph/ceph.client.admin.keyring
Creating mgr...
Verifying port 0.0.0.0:9283 ...
Verifying port 0.0.0.0:8765 ...
Verifying port 0.0.0.0:8443 ...
Waiting for mgr to start...
Waiting for mgr...
mgr not available, waiting (1/15)...
mgr not available, waiting (2/15)...
mgr not available, waiting (3/15)...
mgr is available
Enabling cephadm module...
Waiting for the mgr to restart...
Waiting for mgr epoch 5...
mgr epoch 5 is available
Setting orchestrator backend to cephadm...
Generating ssh key...
Wrote public SSH key to /etc/ceph/ceph.pub
Adding key to root@localhost authorized_keys...
Adding host r1-ceph1...
Deploying mon service with default placement...
Deploying mgr service with default placement...
Deploying crash service with default placement...
Deploying ceph-exporter service with default placement...
Deploying prometheus service with default placement...
Deploying grafana service with default placement...
Deploying node-exporter service with default placement...
Deploying alertmanager service with default placement...
Enabling the dashboard module...
Waiting for the mgr to restart...
Waiting for mgr epoch 9...
mgr epoch 9 is available
Generating a dashboard self-signed certificate...
Creating initial admin user...
Fetching dashboard port number...
Ceph Dashboard is now available at:
URL: https://r1-ceph1:8443/
User: admin
Password: izmqg6lgtg
Enabling client.admin keyring and conf on hosts with "admin" label
Saving cluster configuration to /var/lib/ceph/01bc2c22-085f-11ef-84e3-000c29e7a7a8/config directory
Enabling autotune for osd_memory_target
You can access the Ceph CLI as following in case of multi-cluster or non-default config:
sudo /usr/sbin/cephadm shell --fsid 01bc2c22-085f-11ef-84e3-000c29e7a7a8 -c /etc/ceph/ceph.conf -k /etc/ceph/ceph.client.admin.keyring
Or, if you are only running a single cluster on this host:
sudo /usr/sbin/cephadm shell
Please consider enabling telemetry to help improve Ceph:
ceph telemetry on
For more information see:
https://docs.ceph.com/en/latest/mgr/telemetry/
Bootstrap complete.
这就表示成功了
就可以访问web界面了
集群初始化完毕后,会提示你创建好了web访问地址和账号密码
Ceph Dashboard is now available at:
URL: https://r1-ceph1:8443/
User: admin
Password: izmqg6lgtg
还可以使用ceph -s命令查看集群的基本状态,正常示例如下:
$ ceph -s
cluster:
id: 01bc2c22-085f-11ef-84e3-000c29e7a7a8
health: HEALTH_WARN
OSD count 0 < osd_pool_default_size 3
services:
mon: 1 daemons, quorum r1-ceph1 (age 70s)
mgr: r1-ceph1.bsistk(active, since 45s)
osd: 0 osds: 0 up, 0 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs:
当前集群的状态因为只有一个节点,还不太正常。添加新节点让它变成一个正常工作的集群。
后面的节点添加和osd添加操作除了可以使用命令行进行外,也可以直接在web界面上添加。
添加新节点
cephadm工具和web界面的管理命令都是通过ssh远程到其他节点上去执行后续的步骤命令,因此我们需要先配置好第一个节点到其他节点的免密登录
(非常重要,不配置会无法添加新节点)
cp /etc/ceph/ceph.pub /etc/ceph/.pub
ssh-copy-id -i /etc/ceph/ r1-ceph2
ssh-copy-id -i /etc/ceph/ r1-ceph3
配置好免密登录后,继续后面的操作
命令行添加
$ ceph orch host add r1-ceph2 10.0.0.33
Added host 'r1-ceph2' with addr '10.0.0.33'
查看添加好的节点
$ ceph orch host ls
HOST ADDR LABELS STATUS
r1-ceph1 10.0.0.32 _admin
r1-ceph2 10.0.0.33
2 hosts in cluster
web界面添加

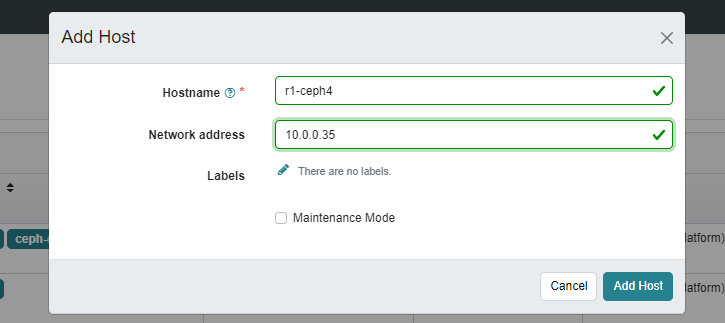
添加完成

添加osd
OSD就是实际负责数据存储的组件,在实际的生产环境中,通常就是我们的单个数据盘。
我们的环境中每个机器有3个数据盘,对应的盘符分别是nvme0n2/snvme0n3/nvme0n4,我们使用ceph命令可以直接看到这些硬盘
$ ceph orch device ls
HOST PATH TYPE DEVICE ID SIZE AVAILABLE REFRESHED REJECT REASONS
r1-ceph1 /dev/nvme0n2 ssd VMware_Virtual_NVMe_Disk_VMware_NVME_0000 60.0G Yes 91s ago
r1-ceph1 /dev/nvme0n3 ssd VMware_Virtual_NVMe_Disk_VMware_NVME_0000 60.0G Yes 91s ago
r1-ceph1 /dev/nvme0n4 ssd VMware_Virtual_NVMe_Disk_VMware_NVME_0000 60.0G Yes 91s ago
r1-ceph2 /dev/nvme0n2 ssd VMware_Virtual_NVMe_Disk_VMware_NVME_0000 60.0G Yes 91s ago
r1-ceph2 /dev/nvme0n3 ssd VMware_Virtual_NVMe_Disk_VMware_NVME_0000 60.0G Yes 91s ago
r1-ceph2 /dev/nvme0n4 ssd VMware_Virtual_NVMe_Disk_VMware_NVME_0000 60.0G Yes 91s ago
r1-ceph3 /dev/nvme0n2 ssd VMware_Virtual_NVMe_Disk_VMware_NVME_0000 60.0G Yes 90s ago
r1-ceph3 /dev/nvme0n3 ssd VMware_Virtual_NVMe_Disk_VMware_NVME_0000 60.0G Yes 90s ago
r1-ceph3 /dev/nvme0n4 ssd VMware_Virtual_NVMe_Disk_VMware_NVME_0000 60.0G Yes 90s ago
可以看到所有可用设备
在web页面查看
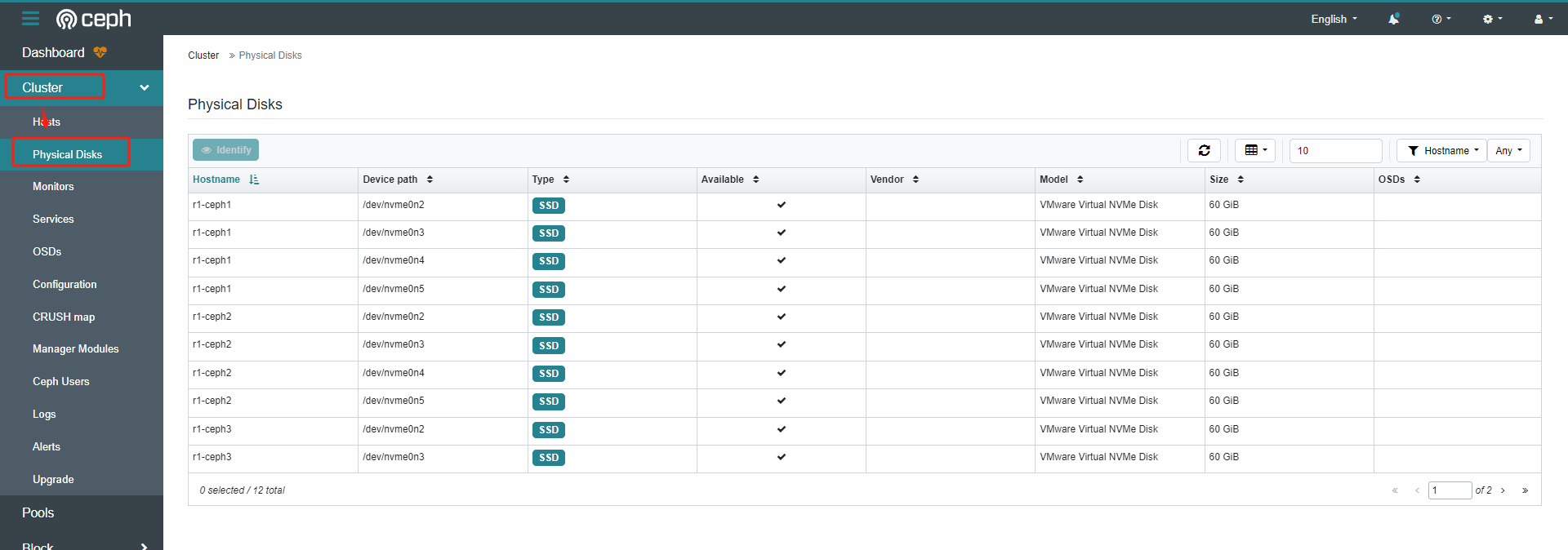
把主机上的硬盘添加为集群中的OSD的命令是:
ceph orch apply osd --all-available-devices
这个命令会一次把所有的硬盘全部加入到集群中,比较适合硬盘比较多的情况,但是这个命令会因为每个节点上程序执行速度的差异,导致OSD的编号完全混乱。
因此在实际的生产中,为了方便管理起见,通常会按顺序添加
一块一块的添加
ceph orch daemon add osd r1-ceph1:/dev/nvme0n2
ceph orch daemon add osd r1-ceph1:/dev/nvme0n3
ceph orch daemon add osd r1-ceph1:/dev/nvme0n4
ceph orch daemon add osd r1-ceph2:/dev/nvme0n2
ceph orch daemon add osd r1-ceph2:/dev/nvme0n3
ceph orch daemon add osd r1-ceph2:/dev/nvme0n4
ceph orch daemon add osd r1-ceph3:/dev/nvme0n2
ceph orch daemon add osd r1-ceph3:/dev/nvme0n3
ceph orch daemon add osd r1-ceph3:/dev/nvme0n4
查看所有osd
$ ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.52734 root default
-3 0.17578 host r1-ceph1
0 ssd 0.05859 osd.0 up 1.00000 1.00000
1 ssd 0.05859 osd.1 up 1.00000 1.00000
2 ssd 0.05859 osd.2 up 1.00000 1.00000
-5 0.17578 host r1-ceph2
3 ssd 0.05859 osd.3 up 1.00000 1.00000
4 ssd 0.05859 osd.4 up 1.00000 1.00000
5 ssd 0.05859 osd.5 up 1.00000 1.00000
-7 0.17578 host r1-ceph3
6 ssd 0.05859 osd.6 up 1.00000 1.00000
7 ssd 0.05859 osd.7 up 1.00000 1.00000
8 ssd 0.05859 osd.8 up 1.00000 1.00000
查看集群状态
$ ceph -s
cluster:
id: 01bc2c22-085f-11ef-84e3-000c29e7a7a8
health: HEALTH_OK
services:
mon: 3 daemons, quorum r1-ceph1,r1-ceph3,r1-ceph2 (age 11m)
mgr: r1-ceph1.bsistk(active, since 10m), standbys: r1-ceph3.bxojey
osd: 9 osds: 9 up (since 33s), 9 in (since 44s)
data:
pools: 1 pools, 1 pgs
objects: 2 objects, 449 KiB
usage: 251 MiB used, 540 GiB / 540 GiB avail
pgs: 1 active+clean
测试就部署成功了,然后就可以使用了
本文来自博客园,作者:厚礼蝎,转载请注明原文链接:https://www.cnblogs.com/guangdelw/p/18757093

 浙公网安备 33010602011771号
浙公网安备 33010602011771号